19.1 Parallel I/O Systems
19.1 Parallel I/O Systems
What do we mean by a "parallel I/O system"? At a high level three characteristics are key:
-
multiple hardware I/O resources on which data will be stored,
-
multiple connections between these I/O resources and compute resources, and
-
high-performance, concurrent access to these I/O resources by numerous compute resources.
Parallel I/O systems get their performance by using multiple I/O resources that are connected to compute resources through multiple I/O paths. Multiple physical I/O devices and paths are required to ensure that the system has enough bandwidth to attain the performance desired. The hardware could consist of nodes with local disks attached via more traditional IP networks, a separate storage area network, or something else entirely; all of these are valid options for parallel I/O systems.
The third characteristic is easily as important as the first two but is considerably more difficult to pin down. Parallel I/O systems should be designed from the bottom up with the assumption that performance is a key attribute and that concurrent access to resources will be commonplace. This characteristic is heavily dependent on the software architecture; the software managing the hardware resources can make or break a parallel I/O system.
Often I/O systems that have multiple connections and hardware devices but don't cater to high-performance concurrent access are called distributed file systems. The software in these systems is tailored to other workloads. Chapter 3 discusses distributed file systems such as NFS.
A parallel file system is simply a component of a parallel I/O system that presents a hierarchical (file- and directory-based) view of data stored in the system. In the next section will see where this component fits into the big picture.
19.1.1 Components of a Parallel I/O Stack
A parallel I/O system includes both the hardware and a number of layers of software, as shown in Figure 19.1. While this chapter really focuses on parallel file systems and PVFS in particular, it is important to understand what other components might be involved and how these work together to provide a reasonable solution to a tricky problem.

Figure 19.1: Parallel I/O System Components
At the lowest level is the I/O hardware, described briefly in Chapter 2. This layer comprises the disks, controllers, and interconnect across which data is moved. Obviously, this hardware determines the maximum raw bandwidth and the minimum latency of the system. The bisection bandwidth (defined in Chapter 4) of the underlying I/O transport is an important measure for determining the possible aggregate bandwidth of the resulting parallel I/O system, just as it is an important measure for the communication network as seen in Chapter 4. At the hardware level, data is usually accessed at the granularity of blocks, either physical disk blocks or logical blocks spread across multiple physical devices, such as in a RAID array.
Above the hardware is the parallel file system. The role of the parallel file system is to manage the data on the storage hardware, to present this data as a directory hierarchy, and to coordinate access to files and directories in a consistent manner. Later in this chapter we'll talk more about what "consistent manner" means, as this is an interesting topic in itself. At this layer the file system typically provides a UNIX-like interface allowing users to access contiguous regions of files. Additional low-level interfaces may also be provided by the file system for higher-performance access.
While some applications still choose to access I/O resources by using a UNIX-like interface, many parallel scientific applications instead choose to use higher-level interfaces. These higher-level interfaces allow for richer I/O description capabilities that enable application programmers to better describe to the underlying system how the application as a whole wants to access storage resources. Furthermore, these interfaces, especially high-level I/O interfaces, provide data abstractions that better match the way scientific applications view data.
Above the parallel file system layer sits the MPI-IO implementation. The MPI-IO interface [46], part of the MPI-2 interface specification, is the standard parallel I/O interface and exists on most parallel computing platforms today. The role of the MPI-IO implementation, in addition to simply providing the API, is to provide optimizations such as collective I/O that are more effectively implemented at this layer. In some sense the job of MPI-IO is to take accesses presented by the user and translate them, as best as possible, into accesses that can be performed efficiently on the underlying parallel file system. This makes the MPI-IO interface the ideal place to leverage file system-specific interfaces transparently to the user. The MPI-IO API is covered in Chapter 9.
The MPI-IO interface is useful from a performance and portability standpoint, but the interface is relatively low level (basic types stored at offsets in a file), while most scientific applications work with more structured data. For this reason many scientific applications choose to use a higher-level API written on top of MPI-IO (e.g., HDF5 [25] or Parallel netCDF [66]). This allows scientists to work with data sets in terms closer to those used in their applications, such as collections of multidimensional variables. These high-level interfaces often provide the same level of performance as using MPI-IO directly. However, one should be aware that in practice the implementation details of some of these systems do sometimes add significant overhead [96].
19.1.2 Access Patterns and Scientific Applications
Applications exhibit all sorts of different access patterns, and these patterns have a significant effect on overall I/O performance. The cat program, for example, accesses blocks of a file starting from beginning to end. This is the ideal pattern of access for most file systems, because many systems can identify this pattern and optimize for it, and the prefetching implemented in many I/O devices also matches with this well. This pattern is seen for a large number of applications, including video and audio streaming, copying of data files, and archiving.
Database systems use I/O resources as another level of memory. In doing so, they tend to access it in very large blocks (contiguous data regions) in an order that the I/O system cannot always predict. However, because the blocks are large and are aligned to match well with the underlying disks, this access pattern can also match well with the I/O system.
Studies tell us that the access patterns seen in scientific applications are significantly different from what we see in these other application domains. Scientific applications are in some sense worst-case scenarios for parallel I/O systems. One such study, the CHARISMA project [79], provides a great deal of insight into the patterns seen in scientific applications. We will extract some of the more important points here.
The CHARISMA project defines sequential access as a pattern where each subsequent access begins at a higher file offset than the point at which the previous access ended. Most of the write-only files were written sequentially by a single process. This behavior was likely because in many applications each process would write out its data to a separate file. This may have been an artifact of poor concurrent write performance on the studied platform. Read-only files were accessed sequentially as well, but regions were often skipped over by processes indicating that multiple processes were somehow dividing up the data. About a third of the files were accessed with a single request.
Figure 19.2 shows an example of a nested-strided access, in this case utilizing three strided patterns in order to access a block of a 3D data set. The study noted that strided access patterns were very common in these applications, with both simple (single) strides and nested strides present. A nested-strided pattern is simply the application of multiple simple-strided patterns, allowing the user to build more complex descriptions of stored data. These patterns arise from applications partitioning structured data such as multidimensional arrays. More recent studies, such as an analysis of the FLASH I/O benchmark [96], support these findings, although in this particular case the strided patterns occur in memory rather than in the file (which is written sequentially) and data from all processes is always written to a single file.
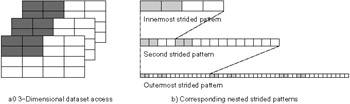
Figure 19.2: Nested-Strided Example
What does all this mean to us? First, it indicates that application programmers really can benefit from the descriptive capabilities available in high-level interfaces. Second, it suggests that the layers below these high-level interfaces should be capable of operating in terms of structured data as well. As we will see in the next section, some parallel file systems fall short in this area.
Because of the differences in access patterns between various applications, I/O solutions that work well for one application may perform poorly for another. This situation encourages us to consider using multiple file systems in the same cluster to fill particular roles. For example, a very reliable distributed file system that might not handle concurrent writes well could be a very useful file system for storing home directories in a large cluster. For smaller clusters NFS might fill this role. On the other hand, a very fast parallel file system with no fault tolerance capabilities might be perfect for storing application data used at run time that is backed up elsewhere. With this in mind, we will now discuss some typical parallel file system architectures with specific examples.







