Catalyst Supervisor and Switch Fabric Redundancy
A question often asked of Cisco is "Where should I have Supervisor redundancy, and where should I not?" Although it seems like a relatively simple question, the answer is not always a simple one. Not all switching platforms support Supervisor redundancy. For example, the option to install redundant supervisors on the Catalyst 4000/4500 series did not become available until the introduction of the 4507R, the "R" signifying redundant. The Catalyst 3750 series creates Supervisor-like redundancy by interconnecting multiple switches to form one logical switching entity. Although Supervisor redundancy has been available since day one on the Catalyst 6000/6500 platforms, the amount of time it takes to failover from the active to the standby supervisor varies depending on the high-availability mode that is configured.
The general rule of thumb for supervisors is to implement redundancy whenever the devices that are attaching to the switch are single connected. For example, a small organization with only a single core switch connecting two other distribution or access switches should implement dual supervisors in the core switch to eliminate a single point of failure. Environments that implement switch redundancy at the distribution and core layers can implement only a single supervisor and rely on failover between switches instead of supervisors. Administrators often implement redundant supervisors or redundant switching solutions, such as the Catalyst 3750 series in the access layer, to avoid a single point of failure.
Catalyst 6500 Supervisor High Availability (Hybrid)
A look at the mechanisms behind Supervisor failover begins with the Catalyst 6500 series. A wide range of Supervisor failover techniques have been used on the Catalyst 6500 series since its introduction. With the introduction of Catalyst OS 5.4(1), a dual Supervisor Catalyst 6500 supports a high-availability mode that synchronizes the supervisor configuration, operating system, and stateful protocol redundancy. The Catalyst 6500 Series can support up to two Supervisor engines in slots 1 and 2 only. One is the active Supervisor engine and the other is the standby Supervisor engine. The active Supervisor engine is the first one to go online and can be confirmed by the "Active" light emitting diode (LED) on the Supervisor engine or by typing the show module command from the Supervisor console. Both Supervisor engines must be the same hardware models for redundancy to operate correctly. This means that if a PFC and MSFC are on a Supervisor IA in slot 1, a PFC and MSFC must be also on a Supervisor Engine IA in slot 2, or if a Supervisor Engine II is in slot 1, a Supervisor Engine II must also be in slot 2. If an active supervisor is taken offline, restarted, or fails, the standby supervisor takes control of the system.
Because high availability was not available until Catalyst OS 5.4(1), it is not enabled by default, but should be enabled whenever supported by compatible software and hardware configurations.
High availability includes stateful protocol redundancy and image versioning. High availability must be enabled via the command line for these features to operate, as shown in Example 11-4.
Example 11-4. Enabling High Availability
SW1> (enable) set system highavailability enable
System high availability enabled.
Many Layer 3 and Layer 4 protocols or features are programmed into the application-specific integrated circuits (ASICs) of the PFC, PFC2, or PFC3 on board the Supervisor engine. Examples include access lists (router and VLAN-based), forwarding tables (MLS cache and CEF tables), IP Phone power and status information, and quality of service (QoS) settings. These protocols are maintained in the protocol database and will continue to be switched in hardware when a Supervisor engine failover occurs.
Stateful Supervisor switchover reduces the time it takes to failover from the active to the standby supervisor to less than 1 second with a Supervisor IA or Supervisor II, and less than 3 seconds with a Supervisor 720. Synchronizing many of the Layer 2, Layer 3, and Layer 4 protocols between the active and standby Supervisor engines makes this possible. In a high-availability configuration, the protocol state database is maintained on each Supervisor engine for all protocols and features requiring high-availability support. Should the active supervisor fail, the standby supervisor becomes active and starts the protocols from the protocol database. Protocol state synchronization is how a redundant Supervisor system can maintain stateful protocol redundancy and achieve a less than 3-second failover.
The protocol state database, illustrated in Figure 11-12, is a repository of up-to-date protocol state information generated by the active supervisor and stored by the standby supervisor. The database contains specific system information including module and port states, VLAN information, nonvolatile RAM (NVRAM) configurations, and various protocol specific data. Both Supervisor engines run a synchronizing operation to allow for transfer of this data. When a database entry is updated on the active Supervisor engine, the synchronizing operation places the update in a first-in, first-out (FIFO) queue. This queue is scheduled to empty periodically for transfer to the standby supervisor. The transfer is a background process and, as such, the update interval varies depending on the number of other active processes in the system. The update interval ranges from 1 to 5 seconds with 2 seconds being an approximate average. The standby Supervisor engine's synchronizing process receives these asynchronous updates and enters them into the protocol state database on the standby Supervisor engine. When the system starts or when a second Supervisor engine is hot-inserted, a global synchronization takes place between the protocol databases to ensure all protocol states are up to date.
Figure 11-12. Supervisor Protocol Database
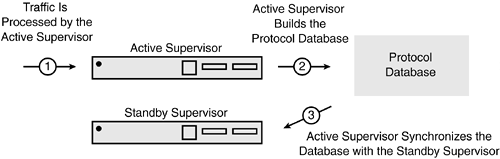
Not all protocols can be synchronized and not all are compatible with the high-availability feature. A feature is considered supported if the state of the feature is synchronized between the active and standby supervisors in the protocol database. A feature is considered compatible if the feature can be used but is not synchronized in the protocol database. A compatible feature must restart when a Supervisor failover occurs. An incompatible feature is simply not supported when high availability is enabled. Table 11-1 lists high-availability support for various features in Catalyst OS.
Supported Features | Compatible Features | Incompatible Features |
|---|---|---|
Common Open Policy Service (COPS) | Accelerated Server Load Balancing (ASLB) | Dynamic VLANs |
Dynamic Trunk Protocol | Cisco Discovery Protocol (CDP) | Generic VLAN Registration Protocol (GVRP) |
Cisco Express Forwarding (CEF) and adjacency tables | GARP Multicast Registration Protocol (GMRP) | Protocol filtering |
Private VLANs | Internet Group Management Protocol (IGMP) snooping | |
Router access control lists (ACLs) | Remote Monitoring (RMON) | |
Multilayer switching (MLS) | Resource Reservation Protocol (RSVP) | |
Port Aggregation Protocol/Link Aggregation Protocol (PAgP/LACP) | Simple Network Management Protocol (SNMP) | |
QoS ACLs and policers | Telnet sessions | |
Switched Port Analyzer (SPAN) | VTP pruning | |
STP | Uplinkfast | |
Trunking | ||
UniDirectional Link Detection (UDLD) protocol | ||
VLAN ACLs | ||
VLAN Trunking Protocol (VTP) | ||
Port Security | ||
802.1X |
For a current list of the features that are supported with the high-availability feature, see the "Configuring Redundancy" chapter of the Cisco Catalyst 6500 Series Software User Guide at Cisco.com.
MSFC High Availability
Because a supervisor reset or failover also resets the MSFC routing engine, various methods were developed to provide high availability to a supervisor with a MSFC, MSFC2, or MSFC3.
Although the Catalyst OS high-availability feature maintains the protocol state between redundant Supervisor engines, a dual MSFC configuration offers high availability via either Dual Router Mode or Single Router Mode. As with the Catalyst OS high-availability feature, Cisco recommends configuring high availability for the MSFCs. Single Router Mode was introduced in Catalyst OS 6.3(1) and IOS 12.1(8)E and is the preferred high-availability mode to configure if the supervisors are running at least those code levels.
Dual Router Mode
Dual Router Mode (DRM) represents the original MSFC high-availability option for dual Supervisor engines with MSFCs. In dual router mode, both MSFCs are active routers on the network. Although both MSFCs are active and can be configured independently, they are not to be used as independent routers. In reality, both MSFCs must have nearly identical configurations to function properly. The importance of requirement in DRM cannot be overstated. Configuration parameters such as interfaces, access lists, policy routing, and so on must be configured exactly the same on both MSFCs. Parameters that cannot be duplicated on a network such as IP addresses and HSRP settings are the only parameters that are configured differently on each MSFC.
The first MSFC to go online is considered the designated router, and the second MSFC is considered the nondesignated router. The MSFC is responsible for programming certain functions of the ASIC hardware on the PFC. In a Supervisor Engine IA system, both the designated router and the nondesignated router are able to program Layer 3 entries into the PFC Netflow table for routing functions. With the Supervisor IIs, only the designated router programs the Layer 3 entries in the PFC2 Cisco Express Forwarding (CEF) table. For both Supervisor Engines IA and II, all router ACLs and multicast shortcuts are programmed from the designated router. If the MSFCs in DRM have different configurations, the forwarding ASICs will be programmed incorrectly, resulting in an unsupported and unreliable configuration.
Failover in DRM relies upon HSRP, which allows the two MSFCs to maintain internal communication and react to an MSFC failover. HSRP on the dual MSFCs is configured in the same way as any two independent routers. Because both MSFCs have independent routing tables, little routing protocol convergence is necessary in the event of an MSFC failure. Using DRM and tuned HSRP timers, MSFC failover can be configured to occur in less than 3 seconds for LAN interfaces, matching the Layer 3 failover of the MSFC with Supervisor engine failover time.
MSFC Configuration Synchronization
Up until the introduction of MSFC Cisco IOS 12.1(3a)E4, MSFC configurations had to be manually synchronized. With 12.1(3a)E4 and later, an MSFC redundancy feature called config-sync is available to simplify the configuration process of dual MSFCs. The config-sync feature does exactly what the name implies; synchronize configuration of dual MSFCs. Both the startup and running configurations between the designated (primary) and nondesignated (secondary) MSFCs are synchronized. When a write memory or copy running-config startup-config command is issued on the designated MSFC, the startup configurations in NVRAM of both MSFCs are updated. Example 11-5 shows the commands needed to enable MSFC high availability with config-sync.
Example 11-5. Enabling High Availability and config-sync
SW1 (config)# redundancy SW1 (config-r)# high-availability SW1 (config-r-ha)# config-sync
When config-sync is used, configuration of the designated MSFC and nondesignated MSFC is done through the command line of the designated MSFC. Configuration of the nondesignated MSFC is accomplished by using the alt parameter. Use of the alt parameter is the only way to configure the nondesignated MSFC while config-sync is enabled. Example 11-6 demonstrates configuring the nondesignated MSFC.
Example 11-6. Configuring the Nondesignated MSFC
SW1 (config-if)# ip address 172.16.197.1 255.255.255.0 alt ip address 172.16.197.2 255.255.255.0 SW1 (config-if)# standby 10 priority 105 alt standby 10 priority 100
The portion of the command listed before the alt keyword applies to the MSFC in slot 1, and the portion of the command listed after the alt keyword applies to the MSFC in slot 2. The config-sync feature is only supported for general IP or IPX configurations; configuration parameters for AppleTalk and DECnet do not have alt keyword options.
In DRM, the Optical Service Module (OSM) or Port Adapters of a FlexWAN module are managed by only the designated MSFC. Prior to enabling the config-sync feature, the WAN interfaces do not show up in the nondesignated MSFC configuration and are not configurable on the nondesignated MSFC. DRM represents the first option for MSFC redundancy. Although this solution is successful at providing stateful Layer 3 failover between MSFCs, it also introduces some complexity into switch administration. The requirement for exact configuration parameters on both MSFCs has been a complicated point for many administrators. As a result of the complexity DRM introduced, a high-availability feature called Single Router Mode was developed.
Single Router Mode
Single Router Mode (SRM) provides a single active MSFC, while placing the secondary MSFC in a standby mode not unlike the standby mode of the secondary supervisor. SRM is now the recommended high-availability configuration for Catalyst 6000/6500 series switches with MSFCs operating in hybrid mode. The minimum software requirements for SRM are Catalyst OS 6.3(1) and Cisco IOS 12.1(8)E2 for the MSFC. SRM improves upon DRM by eliminating the need to configure a nearly identical secondary MSFC, resulting in a simpler configuration process for the administrator because only a single command set is entered from one command line into the active MSFC. (See Example 11-7.)
Example 11-7. Configuring SRM
SW1#config t Enter configuration commands, one per line. End with CNTL/Z. SW1 (config)# redundancy SW1 (config-r)# high-availability SW1 (config-r-ha)# single-router-mode
SRM Operation
In SRM, only the designated router is visible to the network at any given time. The nondesignated router is started and maintains exactly the same configuration as the designated router (the configurations are automatically synchronized when SRM is active). In this mode, the nondesignated router interfaces are kept in a line-down state and are not visible to the network. Routing protocol processes are also created on the nondesignated router, but they do not send or receive updates from the network because all interfaces are down. This is verified from the Catalyst OS command in Example 11-8. Note that both the Supervisor engine and the MSFC in slot 2 are listed as standby.
Example 11-8. Verifying Standby Status with SRM
SW1> (enable) show module
Mod Slot Ports Module-Type Model Sub Status
--- ---- ----- ------------------------- ------------------- --- --------
1 1 2 1000BaseX Supervisor WS-X6K-SUP2-2GE yes ok
15 1 1 Multilayer Switch Feature WS-F6K-MSFC2 no ok
2 2 2 1000BaseX Supervisor WS-X6K-SUP2-2GE yes standby
16 2 1 Multilayer Switch Feature WS-F6K-MSFC2 no standby
If the designated router fails in an SRM configuration, the nondesignated MSFC changes state from nondesignated to designated. The new designated router changes its interface state to link up and begins to build its routing table. It follows that the control plane failover time will be proportional to the routing protocol configuration and complexity. However, Layer 3 forwarding entries exist in the PFC, which are used to forward routed traffic in the hardware path. The high-availability functions of Catalyst OS are used to maintain this forwarding information after a failover, allowing minimal impact to Layer 3 traffic while the Layer 3 routing protocols converge. After the MSFC builds its routing table, the entries in the PFC are updated.
A transition timer feature for SRM on the Supervisor II/PFC2 was introduced in Catalyst OS 12.1(11b)E. This timer configures the time that the new designated router will wait before downloading any new hardware CEF entries to the PFC2. Because of differences in routing convergence times, the default of 120 seconds might not be long enough to allow for complete routing table convergence before programming the PFC2 hardware.
The same IP and Media Access Control (MAC) addresses are used for the designated router, whether or not the MSFC is the designated router. The MSFC chosen as the designated router will communicate its default MAC address to the MSFC that is the nondesignated router. All subsequent interfaces created on the nondesignated router use this MAC address, unless the administrator explicitly configures a different MAC address. On bootup, the two MSFCs perform a "handshake" process, which takes about a minute, before entering SRM mode. It is important to remember to not make configuration changes on the nondesignated router during the handshake process, as shown in Example 11-9.
Example 11-9. Verifying SRM Redundancy
SW1# show redundancy
Designated Router: 1 Non-designated Router: 2
Redundancy Status: designated
Config Sync AdminStatus : enabled
Config Sync RuntimeStatus: enabled
Single Router Mode AdminStatus : enabled
Single Router Mode RuntimeStatus: enabled
Single Router Mode transition timer : 120 seconds
NOTE
For more details about configuring SRM, see section "MSFC Redundancy-Single Router Mode Redundancy" in the Catalyst OS configuration guide at Cisco.com.
Because the Supervisor and MSFC configurations are synchronized as an inherent part of SRM, all Optical Services Modules (OSMs) and FlexWAN WAN modules are supported with redundant Supervisor engines or MSFCs configured for SRM. In failover scenarios, the new designated router takes over ownership of the WAN interfaces as soon as that MSFC becomes the designated router. With SRM enabled, no manual configuration is necessary on the WAN interfaces to support an MSFC failover.
Catalyst 6500 Supervisor High Availability (Native)
Implementing Catalyst native software versus hybrid software has various pros and cons; one disadvantage with native configurations has been the failover time in a high-availability configuration. Although high-availability failover times in hybrid configurations can vary between 1 and 3 seconds, up until very recently, the best failover times in a native configuration have averaged around 30 seconds. Native IOS now supports Stateful Switchover plus Non-Stop Forwarding (SSO + NSF), enabling failover speeds in line with hybrid failover times. In all native IOS high-availability configurations, the redundant supervisor and MSFC are not visible to the network. This section looks at the evolution of router redundancy options beginning with the first, Route Processor Redundancy.
Route Processor Redundancy
Route Processor Redundancy (RPR) was the first high-availability feature offered in a native IOS configuration for the Catalyst 6500 series, enabling an average failover time of approximately 2 minutes. The 2-minute failover time in RPR mode is due to the lack of a completely booted redundant supervisor, and the requirement for line cards to be reset during the failover to the redundant supervisor. As in the hybrid configuration, the supervisor that boots first becomes the active supervisor, while the redundant supervisor is partially booted but not all subsystems (MSFC and PFC) are operational. RPR requires both supervisors to be the same model. Even though the redundant supervisor is not operational, the GigabitEthernet ports on the supervisor are active.
Route Processor Redundancy Plus
Route Processor Redundancy plus (RPR+) improves upon RPR failover times by fully initializing and configuring the redundant supervisor, and eliminating the need to reset each line card during failover. These improvements provide an average failover time of approximately 30 seconds. RPR+ also allows for Online Insertion and Removal (OIR) of Supervisor modules. RPR+ requires both supervisors to be the same model and run the same software version. Example 11-10 shows the commands necessary to configure either RPR or RPR+.
Example 11-10. Configuring RPR or RPR+
SW1#config t Enter configuration commands, one per line. End with CNTL/Z. SW1(config)#redundancy SW1(config-red)#mode ? rpr Route Processor Redundancy rpr-plus Route Processor Redundancy Plus
Single Router Mode with Layer 2 Stateful Switch Over
Single Router Mode with Stateful Switchover (SRM + SSO) was introduced in 12.2(17b)SXA, and provides a 1 to 3 second failover between supervisors. One goal of the 12.1(17b)SXA release was to create feature parity for stateful failover between native and hybrid Catalyst software. While RPR and RPR+ will operate with a Supervisor 1A or Supervisor II, SRM + SSO requires a Supervisor 720. With SRM + SSO, Layer 2 states are synchronized between the PFC3s on the active and standby supervisors, and packet forwarding for hardware switched packets continues while Layer 3 protocols do not maintain state on the MSFC3 and must restart. Example 11-11 shows the configuration of SRM + SSO.
Example 11-11. Configuring SRM with SSO
SW1# config t Enter configuration commands, one per line. End with CNTL/Z. SW1(config)# redundancy SW1(config-red)# mode sso
Catalyst 6500 Switch Fabric Redundancy
In addition to redundant supervisors for the Catalyst 6500, redundant switch fabrics in the form of the SFM or SFM2 may be installed. The Supervisor 720 includes an integrated switch fabric, and as a result, fabric redundancy is provided by redundant installing Supervisor 720s. Unlike with redundant Supervisor 720s, implementing switch fabric redundancy with the SFMs or SFM2s requires no configuration. Switch Fabric modules (SFMs) can be installed in only specific slots depending on the chassis. The SFM in the upper slot will always function as the primary module and the lower slot will always be secondary during normal operation. If the primary is reset, the secondary will take over operation.
Catalyst 4500 Redundancy
Supervisor redundancy on the Catalyst 4500 was introduced with the 4507R chassis, and requires dual Supervisor II+, Supervisor IV, or Supervisor V cards to enable redundancy. As of the writing of this book, the Catalyst 4500 series supports only the features of RPR. No configuration is required to enable RPR; it is enabled by default whenever redundant supervisors are installed. Failover times average around 90 seconds from active to standby supervisor. Unlike the early Catalyst 6500 redundancy modes, no manual config-sync is necessary on the 4500. When a standby supervisor first comes online, its configuration is synchronized to the active supervisor. An optional auto-synch command can be enabled so that changes made to the startup configuration on the active supervisor are automatically synchronized to the standby supervisor.
Catalyst 3750 Redundancy
The Catalyst 3750 switching platform is capable of high availability by design, given the stackable architecture. You can stack and interconnect up to nine switches in a self-healing ring. Failover on the 3750 series is less than 1 second for Layer 2 traffic, and Layer 3 failover takes between 3 and 5 seconds. In a Catalyst 3750 stacked configuration, one switch becomes the stack master based on a well-defined selection process. The selection process can be influenced manually by configuring the mastership priority parameter.
The following rules have been defined to determine which unit within a stack is chosen as the master. When adding switches or merging stacks, the master will be chosen based on the following rules in the order specified. If the first rule does not apply, the second rule is tried, and so on, until an applicable rule is found to select the master:
The stack (or switch) whose master has the higher user-configurable mastership priority.
The stack (or switch) whose master is not using the default configuration.
The stack (or switch) whose master has the higher hardware/software priority (based on switch hardware version and/or software version).
The stack (or switch) whose master has the longest uptime.
The stack (or switch) whose master has the lowest MAC address.
When removing or partitioning stacks, the master will be
The switch that is already master.
The switch that has the higher user-configurable mastership priority.
The switch that has the higher hardware/software priority.
The switch that has the lowest switch number.
Much like an active supervisor in a redundant 6500 Supervisor configuration, it is the stack master's responsibility to build the Layer 3 Forwarding Information Base (FIB) and propagate it to stack members. The stack master propagates its configuration to the entire stack, and all switches will use the same bridge-ID derived from the master's MAC-address block. The stack master has control of the console and the entire stack has single VLAN database and same VTP mode. The stack appears as single entity in Cisco Discovery Protocol (CDP), with the stack master controlling the neighbor table.







