Congestion and Head-of-Line Blocking
Head-of-line blocking occurs whenever traffic waiting to be transmitted prevents or blocks traffic destined elsewhere from being transmitted. Head-of-line blocking occurs most often when multiple high-speed data sources are sending to the same destination. In the earlier shared bus example, the central arbiter used the round-robin service approach to moving traffic from one line card to another. Ports on each line card request access to transmit via a local arbiter. In turn, each line card's local arbiter waits its turn for the central arbiter to grant access to the switching bus. Once access is granted to the transmitting line card, the central arbiter has to wait for the receiving line card to fully receive the frames before servicing the next request in line. The situation is not much different than needing to make a simple deposit at a bank having one teller and many lines, while the person being helped is conducting a complex transaction.
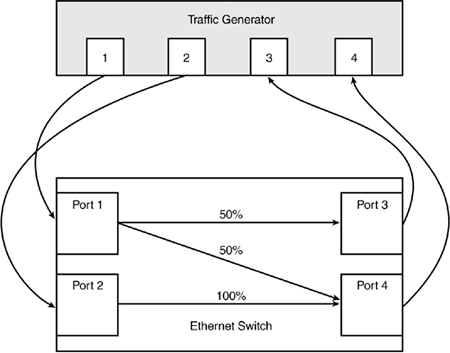
In Figure 2-7, a congestion scenario is created using a traffic generator. Port 1 on the traffic generator is connected to Port 1 on the switch, generating traffic at a 50 percent rate, destined for both Ports 3 and 4. Port 2 on the traffic generator is connected to Port 2 on the switch, generating traffic at a 100 percent rate, destined for only Port 4. This situation creates congestion for traffic destined to be forwarded by Port 4 on the switch because traffic equal to 150 percent of the forwarding capabilities of that port is being sent. Without proper buffering and forwarding algorithms, traffic destined to be transmitted by Port 3 on the switch may have to wait until the congestion on Port 4 clears.
Figure 2-7. Head-of-Line Blocking
Head-of-line blocking can also be experienced with crossbar switch fabrics because many, if not all, line cards have high-speed connections into the switch fabric. Multiple line cards may attempt to create a connection to a line card that is already busy and must wait for the receiving line card to become free before transmitting. In this case, data destined for a different line card that is not busy is blocked by the frames at the head of the line.
Catalyst switches use a number of techniques to prevent head-of-line blocking; one important example is the use of per port buffering. Each port maintains a small ingress buffer and a larger egress buffer. Larger output buffers (64 Kb to 512 k shared) allow frames to be queued for transmit during periods of congestion. During normal operations, only a small input queue is necessary because the switching bus is servicing frames at a very high speed. In addition to queuing during congestion, many models of Catalyst switches are capable of separating frames into different input and output queues, providing preferential treatment or priority queuing for sensitive traffic such as voice. Chapter 8 will discuss queuing in greater detail.







