Purposes of Performance
This section is dedicated to performance management. It identifies various scenarios where performance data can help manage the network more effectively.
As mentioned before, the term "performance monitoring" can be interpreted widely. Our definition covers three aspects: the device, the network, and the service. In fact, device and network performance monitoring are closely related, as we will demonstrate. Therefore, we combine the two in a single section, while service monitoring is such a large domain that we address it separately. This chapter also covers the two key domains that require performance data collection: baselining and fault management.
Device Performance Monitoring
The most obvious area of performance monitoring is directly related to the overall network and individual devices within the network. Sometimes you have the feeling that the network is slow. This "feeling" is supported by the fact that users cannot distinguish between network and server performance. Whether it is the server or the connectivity between the client and the server, usually the network administrator is accused. Consequently, the first task is to monitor the network constantly to prove that the network is doing fine. This might sound strange, but it reflects the reality of many network operators, who are treated as guilty unless proven otherwise.
As the initial step, start monitoring the network for device and link availability. Availability is the measure of time for which the network is available to a user, so it represents the reliability of network components. Another description says availability is the probability that an item of the network is operational at any point in time.
A common formula is:
Availability = MTBF / (MTBF + MTTR)
MTBF is the mean time between failures and describes the time between two consecutive failures. MTTR is the mean time to repair after a failure occurred and answers the question "How long did it take to fix the problem"? Availability is usually defined as a percentage, such as 99 percent or 99.99999 percent. You might think that 99 percent availability sounds like a good result, but considered over one year it means an outage of more than 3.5 days. We take a closer look at the meaning of these numbers in Table 1-7.
| Availability | Downtime Per Year |
|---|---|
| 99.000 percent | 3 days, 15 hours, 36 minutes |
| 99.500 percent | 1 day, 19 hours, 48 minutes |
| 99.900 percent | 8 hours, 46 minutes |
| 99.950 percent | 4 hours, 23 minutes |
| 99.990 percent | 53 minutes |
| 99.999 percent | 5 minutes |
| 99.9999 percent | 30 seconds |
Most network operators try to achieve availability between 99.9 percent and 99.99 percent. From a technical perspective, it is possible to increase this even further, but the price is so high that a solid business case is required as a justification. Trading floors and banking applications are examples of high-availability requirements; the average e-mail server is certainly not. Because these are only general remarks about high availability, we will not cover these concepts in more detail, but instead suggest a book for further study. High Availability Network Fundamentals by Chris Oggerino (Cisco Press, 2001) is a perfect starting point.
Network Element Performance Monitoring
From a device perspective, we are mainly interested in device "health" data, such as overall throughput, per-(sub)interface utilization, response time, CPU load, memory consumption, errors, and so forth. Details about network element performance, such as interface utilization and errors, are provided by the various MIBs, such as MIB-II (RFC 1213), Interfaces-Group-MIB (RFC 2863), and TCP-MIB (RFC 2012).
Calculation of transmission efficiency is related to the number of invalid packets; it measures the error-free traffic on the network and compares the rate of erroneous packets to accurate packets. We measure only ingress transmission efficiency, because a router or switch does not send defect packets intentionally. The required parameters are provided by the Interface MIB (IF-MIB RFC 2863):
ifInErrors— "For packet-oriented interfaces, the number of inbound packets that contained errors preventing them from being deliverable to a higher-layer protocol. For character-oriented or fixed-length interfaces, the number of inbound transmission units that contained errors preventing them from being deliverable to a higher-layer protocol."
ifInUcastPkts— "The number of packets, delivered by this sub-layer to a higher (sub-) layer, which were not addressed to a multicast or broadcast address at this sublayer." These are the unicast packages.
ifInNUcastPkts— "The number of packets, delivered by this sub-layer to a higher (sub-)layer, which were addressed to a multicast or broadcast address at this sub-layer." These are the nonunicast packages (the sum of multicast and broadcast traffic).
transmission efficiency [%] = ΔifInErrors * 100 / (ΔifInErrors + ΔifInUcastPkts + ΔifInNUcastPkt)
The CISCO-IF-EXTENSION-MIB adds details such as cieIfInFramingErrs (misaligned or framing errors), cieIfInOverrunErrs (the receiver ran out of buffers), cieIfInRuntsErrs (too-small packets), and cieIfInGiantsErrs (too-large packets). These counters should be used for in-depth error analysis; if the ifInErrors counter is high, the root cause needs to be identified.
Note
A single SNMP polling cycle of the MIB counters is useless; the delta between two polling cycles provides relevant data!
More details related to device performance can be found in the Cisco Press book Performance and Fault Management.
System and Server Performance Monitoring
Most of the recommendations described for networking devices also apply to server monitoring. The low-level and operation systems functions need to be checked constantly to identify performance issues immediately. In addition to checking these details, you should also monitor the specific services running on the server. Consider a DNS service. It would not satisfy the users to know that the server response time to a ping request is okay if the logical service (DNS in this case) is very slow due to issues that might be caused by other applications running on the same physical hardware.
In the case of system and server monitoring, we make a distinction between low-level service monitoring and high-level service monitoring:
Low-level service monitoring components:
- System: hardware and operating system (OS)
- Network card(s)
- CPU: overall and per system process
- Hard drive disks, disk clusters
- Fan(s)
- Power supply
- Temperature
- OS processes: check if running; restart if necessary
- System uptime
High-level service monitoring components:
- Application processes: check if running; restart if necessary
- Server response time per application
- Optional: Quality of service per application: monitor resources (memory, CPU, network bandwidth) per CoS definition
- Uptime per application
A practical approach is to measure the server performance with the Cisco IP SLA or Cisco NAM card for the Catalyst switch. The NAM leverages the ART MIB and provides a useful set of performance statistics if located in the switch that connects to the server farm. Figure 1-23 shows an ART MIB report. Chapter 5 includes details about the ART MIB.
Figure 1-23. Catalyst 6500 NAM ART Measurement

Network Performance Monitoring
Network connectivity and response time can be monitored with basic tools such as ping and traceroute or with more advanced tools such as Ping-MIB, Cisco IP SLA, external probes, or a monitoring application running at the PC or server. When measuring the network connectivity and response time, we recommended that the administrator monitor connectivity between the network devices and also to the servers. This can avoid finger-pointing between the networking and server departments.
In the context of network performance, we distinguish between the downtime measured by an application and the downtime experienced by a user. If you just monitor network and server availability and do not monitor the actual service (which runs on the physical server), we could measure 100 percent availability, even if this service has an availability of no more than 90 percent. Another example is related to the measurement interval. If the performance monitoring application pings the devices only every 5 minutes, the result could be 100 percent availability, even if there are short outages during the measurement interval. A user would experience these outages and argue that the measurement is inaccurate, even though in this case both parties are right. A similar situation could occur during the night. The user probably sleeps and does not care about the network, while the server is monitoring outages. You can already imagine the challenges of service level definitions and monitoring.
Availability is only one parameter in the area of network monitoring; others are also relevant:
Network response time
Utilization (device, network)
Packet loss
Network throughput/capacity
Network delay
Jitter (delay variation)
Transmission efficiency
Service Monitoring
We started the monitoring approach at the device and network level to ensure basic connectivity. Assuming that the network connectivity and response time are well monitored now, the next step is to monitor the services in the network. This is the right time to discuss the notion of service level management and service level agreements.
From a service perspective, here are significant parameters to monitor:
Service availability
Service delay
Packet loss
Delay variation (jitter)
Mean Opinion Score (MOS) in the case of voice
Key Performance Indicators (KPI)
Key Quality Indicators (KQI)
A good reference for service parameters such as KPI and KQI is the "SLA Management Handbook GB917" from the TeleManagement Forum (TMF).
Service availability measurements require explicit measurement devices or applications, because a clear distinction between server and service is necessary. Imagine a (physical) server operating without any problems, while the (logical) service running on the server has terminated without a notification. Client-based monitoring applications can generate application-specific requests (for example, SAP transactions) to identify if the service is operational and what the response time is.
We briefly discussed this issue in the "System and Server Performance Monitoring" section. We proposed using the Cisco NAM card in connection with the Response Time (ART) MIB, or Cisco IP SLA. IP SLA supports application-specific probe operations, like DNS/DHCP request or web server response time. In a voice over IP (VoIP) environment, IP SLA measures the delay variation (also known as jitter), which is a very important parameter to identify voice quality. Furthermore, it measures the MOS that is essential in Internet telephony, because it provides a numeric measure of the quality of human speech at the destination end of the circuit.
Because Chapter 3 describes the notion of a service, at this point we address this topic only briefly:
Service— A generic definition by Merriam-Webster declares: "A facility supplying some public demand...." More specifically, related to IT, we define a service as a function providing network connectivity or network functionality, such as the Network File System, Network Information Service (NIS), Domain Name Server (DNS), DHCP, FTP, news, finger, NTP, and so on.
Service level— The definition of a certain level of quality (related to specific metrics) in the network with the objective of making the network more predictable and reliable.
Service level agreement (SLA)— A contract between the service provider and the customer that describes the guaranteed performance level of the network or service. Another way of expressing it is "An SLA is the formalization of the quality of the service in a contract between the Customer and the Service Provider."
Service level management— The continuously running cycle of measuring traffic metrics, comparing those metrics to stated goals (such as for performance), and ensuring that the service level meets or exceeds the agreed-upon service levels.
Table 1-8 provides some generic SLA examples.
| Class | SLAs | Application |
|---|---|---|
| Premium | Availability: 99.98/99.998 percent Latency: 50 ms maximum Packet delivery: 100 percent Jitter: 2 ms maximum | Broadcast videoTraditional voice |
| Optimized | Availability: 99.98/99.998 percent Latency: 50 ms maximum Packet delivery: 100 percent Jitter: 10 ms maximum | Compressed video Voice over IP Mixed application Virtual private network |
| Best effort | Availability: 99.98 percent Latency: 50 ms maximum Packet delivery: 99.95 percent | Internet data |
Baselining
Baselining is the process of studying the network, collecting relevant information, storing it, and making the results available for later analysis. A general baseline includes all areas of the network, such as a connectivity diagram, inventory details, device configurations, software versions, device utilization, link bandwidth, and so on. The baselining task should be done on a regular basis, because it can be of great assistance in troubleshooting situations as well as providing supporting analysis for network planning and enhancements. It is also used as the starting point for threshold definitions, which can help identify current network problems and predict future bottlenecks. As a summary, the objective of baselining is to create a knowledge base of the network—and keep it up to date!
Baselining tasks include the following:
Gather device inventory information (physical as well as logical). This can be collected via SNMP or directly from the command-line interface (CLI)—for example, show version, show module, show run, show config all, and others.
Gather statistics (device-, network-, and service-related) at regular intervals.
Document the physical and logical network, and create network maps.
Identify the protocols on your network, including
- Ethernet, Token Ring, ATM
- Routing (RIP, OSPF, EIGRP, BGP, and so on)
- Legacy voice encapsulated in IP (VoIP)
- IP telephony
- QoS (RSVP)
- Multicast
- MPLS/VPN
- Frame Relay
- DLSW
Identify the applications on your network, including
- Web servers
- Mainframe-based applications (IBM SNA)
- Peer-to-peer applications (Kazaa, Morpheus, Grokster, Gnutella, Skype and so on)
- Backup programs
- Instant messaging
Monitor statistics over time, and study traffic flows.
From a performance baselining perspective, we are primarily interested in performance-related subtasks:
Collect network device-specific details:
- CPU utilization
- Memory details (free system memory, amount of flash memory, RAM, etc.)
- Link utilization (ingress and egress traffic)
- Traffic per class of service
- Dropped packets
- Erroneous packets
Gather server- and (optionally) client-related details:
- CPU utilization
- Memory (main memory, virtual memory)
- Disk space
- Operation system process status
- Service and application process status
Gather service-related information:
- Round-trip time
- Packet loss (delay variation—jitter)
- MOS (if applicable)
The collected baseline details are usually stored in a database so that relevant reports can be generated later. The next step is to define reporting requirements. Which level of detail do you need? Which level of granularity is required? These questions can be answered by looking at the specific types of applications that generated the traffic for the baseline. For example, you need a finer level of granularity for troubleshooting than for trending. If capacity planning includes QoS, the relevant QoS parameters need to be collected, which might not be required if the data is collected for computing the amount to charge back per department. Based on the demands of the particular use case, you can define polling intervals and the granularity of the data collection. Five-minute intervals are in most cases sufficient for baselining, so to start polling devices every 5 minutes. In a large network, this can create a nontrivial amount of overhead traffic. You can avoid this by creating different polling groups (that is, poll core devices every 5 minutes, distribution level devices every 10 minutes, and access devices every 15 minutes, for example).
Over time, you realize that the amount of collected data becomes huge, so you want to aggregate older data. This depicts the compromise between data granularity and storage capacity. For example, you could combine the original 5-minute interval collection into a 30- or 60-minute interval. The informational RFC 1857 proposes guidelines for the aggregation interval:
Over a 24-hour period, aggregate data to 15-minute intervals. Aggregate three 5-minute raw data samples into one 15-minute interval, which results in a reduction of 33 percent.
Over a 1-month period, aggregate data to 1-hour intervals. Aggregate four 15-minute data sets into a 1-hour period, thereby reducing the data by 25 percent.
Over a 1-year period, aggregate data to 1-day intervals. Aggregate 24 1-hour data sets into one, resulting in a 4.2 percent reduction. Comparing the 5-minute raw data collections with the 1-year aggregation, a reduction by the factor 3 * 4 * 24 = 288, or 0.35 percent takes place.
So far, you have collected performance statistics from the elements in the network and stored them in an archive or database. The next chapter shows that baselining is a foundation for effective fault management.
Fault Management
In addition to the close linkage between performance and accounting, we also recognize a strong association between performance and fault management. Figure 1-5 illustrated this, and we want to elaborate on its concepts. Remember that the objective of performance monitoring is collecting statistics from devices, networks, and services, and displaying them in various forms to the user. Performance management extends this approach and includes active modifications of the network to reconstitute the expected performance level. Note that an additional step should occur between the recognition of a deviation and the remedy—notifying the fault application of the abnormality. One could argue that a deviation is not a fault at all, but it is certainly an indicator of some form of abnormal behavior that should be examined further. This is the reason for sending a notification toward the fault application. At a high level, we can distinguish between two different fault events:
State change (device, network, or service failure; outage; or restart)
Performance deviation
Notifications about state changes are sent by devices proactively. As a result, a state change occurs at the application (for example, network map, event list, and so on). A state change from operational to nonoperational usually indicates an outage, while the opposite indicates either a recovery from a failure or the activation of a backup procedure. Therefore, events categorized under "state change (a)" require as much attention as events according to "performance deviation (b)." An example is the activation of an ISDN backup link when the primary DSL connection fails. Assuming the DSL connection has a flat rate, the ISDN link is probably charged per time interval and can result in a drastically increased monthly invoice. This would indicate a poorly designed fault management system, if only the invoice at the end of the month can indicate this situation.
Performance deviation events are much more closely linked to performance management than fault management. The challenge is to identify a deviation from "normal," because you need some history indicators to define what "normal" is for a specific network at a specific time. To achieve this, baselining is required, as explained in the preceding section. If the current measurement values exceed a predefined threshold above or below the expected value, a performance event is generated.
We will now analyze the performance baseline to understand the traffic flows in the network and to define appropriate thresholds for traffic or application guarantees. Thresholding is the process of specifying triggers on traffic patterns or situations and generating events when such situations occur.
We define two classes of thresholds:
Discrete thresholds— Boolean objects with two values (yes/no, true/false, 0/1) that define the transition from one state to another.
Examples: Link up/down, interface operational/failed, or service available/unavailable. Boolean operators are either true or false and can easily be correlated; for instance:
Symptoms: A specific service is unavailable and the physical link to the server that provides this service is down.
Action: Check the link before checking the service.
Continuous thresholds— Apply to continuous data sets and can optionally include time. In this case we need to define an absolute or relative threshold and generate an event whenever this value is exceeded.
Example: The number of erroneous packets as a percentage of total traffic.
The thresholding technique can be enhanced by adding a hysteresis function to reduce the volume of generated events. In this case, only one positive event is sent when the value exceeds the upper threshold, but no further events are sent until the lower threshold has been reached and one negative event is sent. This helps reduce the volume of events drastically without reducing the level of relevant information.
Figure 1-24 shows a response-time hysteresis function with a rising threshold of 100 ms and a falling threshold of 50 ms. In this example, a response time between 50 and 100 ms is considered normal, and a response time above 100 ms is critical and generates an alert. After the alert has occurred, the state remains critical until the response time drops to 50 ms. Alternatively, you could set both the upper and lower threshold to 100 ms to get immediate notification if the response time drops below 100 ms; however, this would remove the hysteresis function.
Figure 1-24. Defining Reaction Conditions
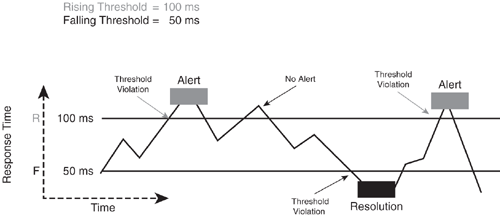
Statistical analysis can be visualized in a plot chart to identify normal and abnormal behavior. It is a good practice to start with a "soft" or lower threshold instead of too tight a value to avoid alert storms. Thresholds can be adjusted by taking a successive approach, which adjusts the values over time to closely match the normal behavior and identify abnormalities.
You can define thresholds at the NMS system by polling the device performance data and checking it against the thresholds. Alternatively, you can set thresholds directly at the device level and notify the NMS application proactively if a threshold has been exceeded. The first approach is the classic solution in which NMS frameworks such as HP OpenView, IBM Tivoli, CA Unicenter, and so on discover and poll all devices in the network. The second approach requires more intelligence at the device level and has additional resource requirements (memory and CPU). But it can help reduce network management traffic on the network, because only status polling and event notification between the NMS server and the device are required. The RMON-MIB, Event-MIB, and Cisco IP SLA (CISCO-RTTMON-MIB) can provide this functionality.
Which thresholds are relevant for your network? Almost every network administrator is searching for generic answers, only to discover that he or she has to find an individual answer to this question. Very few generic thresholds can be applied across all networks; thus, in most cases, defining thresholds is a task for the operator. For example, Cisco suggests that the average CPU load should not exceed 60 percent so that enough performance is available for sudden events such as routing protocol recalculations. However, you could argue that by purchasing a "full" CPU, you could expect a much higher utilization, and therefore define a threshold of 95 percent. Best practice suggests taking a more conservative approach to increase network availability.
Generic threshold recommendations for Cisco routers and switches are as follows:
Total CPU utilization over 5 min
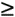 60 percent (CISCO-PROCESS-MIB)
60 percent (CISCO-PROCESS-MIB)Free memory pool
25 percent (CISCO-MEMORY-POOL-MIB)Round-trip time between two devices
150 ms (CISCO-RTTMON-MIB)Jitter between two devices
10 ms (CISCO-RTTMON-MIB)DNS response time
2 sec (CISCO-RTTMON-MIB)DHCP request time
10 sec (CISCO-RTTMON-MIB)
With a performance baseline in place and threshold definitions applied, we will identify a more sophisticated feature called "deviation from normal." This function adds "intelligence" to the performance baseline collection by defining and analyzing network performance metrics over a timeline. For instance, if you identify link utilization above 90 percent as a critical situation, you can also ask at what time this is a particular problem. On a Monday morning, when every user downloads e-mails, updates virus definitions, or performs a backup, it can be acceptable to utilize the network almost completely, especially from an economical perspective. If the same situation occurs on a Saturday evening, you should think twice. The limitation of defining thresholds is that they are fixed and cannot be easily adjusted in a timely fashion. We can also avoid defining multiple simultaneous thresholds in a simple step. In this case, a performance management application should keep a baseline per hour and day and constantly compare the current data with the historical data. In a situation where the average CPU utilization of a specific device is expected to be about 30 percent, a "deviation from normal" function would generate an alarm if the current CPU utilization were far greater than 30 percent or far less than 30 percent, because both situations could indicate a serious issue. A high CPU utilization could indicate an attack on the network, and a very low CPU utilization could point to a misconfiguration in the network.
The following four steps summarize the necessary tasks for fault management:
Step 1. | Define thresholds on core devices and services. |
Step 2. | Predict future network behavior, and identify potential problem areas and bottlenecks. |
Step 3. | Develop a what-if analysis methodology to speed up troubleshooting. |
Step 4. | Implement a change control process that specifies that network modifications need to be documented and planned in advance (maintenance window). |
Notice that input from the sections on accounting and performance monitoring can provide relevant input to a fault application.







