Collection Infrastructure: How to Collect Data Records
This section describes the infrastructure required to collect accounting and performance data. The infrastructure consists of metering devices collecting data records, collection and mediation devices mediating data sets, and application servers generating business information, such as performance and service level reports, security analysis, and usage-based billing.
Pull Versus Push Model
The first consideration is the location where data records are stored immediately after generation at the meter. With the push model, records are not stored at the devices or are kept there for only a short time, until the device pushes them toward a collection server. NetFlow is an example of the push model, in which the device aggregates packets into flows and exports them regularly. SNMP notifications deploy the push model, based on the assumption that changes at the device level should be communicated in a proactive manner. Therefore, when a relevant event occurs at the device, a notification is generated toward the management station. In contrast to this, with the pull model, collection details are stored at the device until an external instance, such as a network management server, requests that they be sent.
MIBs, such as the BGP Policy Accounting MIB, IP accounting MIB, and IP SLA MIB (CISCO-RTTMON-MIB), are examples of pull technology, where the device constantly updates the counters while the NMS application is responsible for regular collection.
Both methods have pros and cons. An advantage of the push model is the event-driven aspect, which means that data is sent only if an event occurs. The pull model requires constant data retrieval, even if no event occurs at the device, because the device status can be identified only by polling.
Figure 2-24 provides a schematic view of the collection infrastructure, starting at the device level and continuing from the mediation layer up to the application layer. It illustrates that the push and pull models are not limited to the meter, but apply at the upper layers as well. At the element level, multiple metering instances can work in parallel, and aggregation is optional. The aggregation and exporting processes can be applied per instance or can be combined, for the pull model as well as the push model.
Figure 2-24. Collection Infrastructure

Event-Based Model
Instead of selecting between pull and push, a more practical approach is to create a solution in which the two models come together. The event-based model is the most effective combination of the push and pull model. It builds on the advanced metering functionalities of the network element and combines them with the intelligence of the network management application. Here are some examples:
By defining SNMP MIB thresholds for CPU utilization, interface utilization, link errors, and more, the network element monitors its status continuously. If a threshold is exceeded, a notification is pushed to the NMS application, which can start pulling for more details from the various MIB objects at the network element. After resolving the issue, the process returns to the initial state. Note that some server polling is required to check if the network element is alive. In the case of a power outage or system crash, no alarms can be pushed from the device to the management system. In the described scenario, management traffic between the network element and the server is greatly reduced, but at the price of less information received the management station. A good compromise is to retrieve performance statistics from the network elements at least once per hour for baselining and other purposes.
The Cisco IP SLA feature implements an event-based model as a trigger for operations. You can define IP SLA operations that are performed under normal circumstances, configure thresholds, and specify an additional probe operation that is performed only if the threshold is exceed. The management application can retrieve the results from both the normal operation and the additional operation for further analysis. For example, a router performs RTT operations, and if a threshold is exceeded, additional jitter probes are initiated. As soon as RTT values are back to normal, no further jitter tests are performed.
A configuration change at the network element can trigger a notification to the provisioning system (push). When receiving the message, the application can retrieve the new configuration (pull), determine if the configuration changes are accepted, or overwrite them by pushing a new configuration to the device.
A monitoring system can pull information from a network element's NetFlow MIB to inspect the summary of current traffic flows, such as total number of flows, top talkers, average flow size, and others. If any of these values passes a threshold at the application server, it can enable NetFlow export at the device, which then starts pushing all flow records to the collection server for further inspection. After traffic conditions return to normal, NetFlow export can be disabled, and the monitoring of the NetFlow MIB continues.
Export Protocols
For the description of the export protocols, Table 2-25 documents the structure that has been applied.
| Overview | Description |
|---|---|
| Connection mode, congestion handling, reliability | Discussion about the connection mode (connection-oriented versus connectionless) and its built-in congestion and reliability mechanisms |
| Send and retrieve frequency | Description of send and receive frequency depending on the protocol characteristics (push versus pull mode) |
When setting up a connection-oriented session, the status of the session is known to both parties at any time during the conversation. This is achieved by implementing status messages (keepalives), acknowledgments, and potentially retries if datagrams got lost. When the connection is disrupted, the sender and receiver notify it and can reestablish it. The Transmission Control Protocol (TCP) is an example of a connection-oriented protocol with mechanisms to identify congestion in the network and react accordingly.
Connectionless sessions avoid the overhead of keepalives, acknowledgments, and retries, and consequently have a higher throughput rate, at the price of less reliability. When the connection is lost, data is sent into "the dark," without the sender's being aware of it. This can become an issue for the network infrastructure if a sender keeps transmitting large traffic sets, even if the network cannot transport the traffic any longer, resulting in dropped traffic or congested networks. User Datagram Protocol (UDP) is an example of a connectionless protocol without congestion handling.
A solution in between the two extremes is using congestion-aware protocols, which avoid the overhead of TCP but add mechanisms to identify network congestion situations and adopt the sending rate accordingly. Stream Control Transmission Protocol (SCTP) is an example in this category.
The reporting frequency depends on the mode: push or pull.
For push mode, the sending frequency depends on the technology as well. SNMP notifications are sent immediately upon occurrence of an event, while NetFlow uses a combination of triggers.
The retrieval frequency of the pull mode is configured at the management server; it determines how often data is retrieved from the network elements. The memory strategy at the network element for pull mode can be implemented in three ways:
In case of detailed accounting records, overwrite the oldest records when the maximum number of entries is reached.
Wrap the counters when they reach the maximum value (for example, SNMP interface counters).
Stop adding new entries before the existing ones have been retrieved or erased.
SNMP
SNMP illustrates how to combine the pull and push models effectively. Most MIBs consider the majority of information gathered relevant but not critical—for example, interface counters, system up time, the routing table, and so on. These data sets are stored in the device memory and can be retrieved from a network management application by SNMP polling; this is a pull approach. A subset of the information gathered by the device is classified as critical information. This is sent to the management station without waiting for a request to send; in SNMP terminology, this is called a notification, which applies to the push model. Note that the SNMP notification can be sent in an unacknowledged way (the trap) or in an acknowledged way (the inform). Examples of default notifications are device warm-start or cold-start and interface up or down. A subset of MIB data exists that can be considered critical, but it has no default notifications assigned—for example, CPU monitoring or a change in the device configuration. For increased flexibility, the operator can define thresholds for MIB variables, and a specific notification is generated after a threshold is exceeded.
Connection Mode, Congestion Handling, and Reliability
SNMP datagrams are transported over UDP, which is a connectionless and unreliable transport protocol. Timers and retries are implemented to reduce the effects, but a valid concern is not losing relevant information in notifications on the way from the device to the management station. By default, the notifications are sent as a trap, which is an unacknowledged message. This reliability concern is addressed by SNMP "informs," which were introduced in SNMP version 2c. Instead of a "fire and forget" approach, the device sends a notification to the NMS server and requires an acknowledgment. If the acknowledgment is not received within a certain amount of time, the message gets sent again—three times by default. SNMP has no concept of congestion handling.
Send and Retrieve Frequency
The retrieval frequency depends very much on the traffic volume that is processed by the network element. In the past, SNMP MIB counters were implemented as 32-bit integers only. 64-bit counters are required in today's high-speed environments to avoid rapid counter rollover. RFC 2863, Evolution of the Interfaces Group of MIB-II, defines the relationship between interface speed and counter size:
ifSpeed
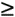 20 Mbps: 32-bit byte and packet counters
20 Mbps: 32-bit byte and packet countersifSpeed > 20 Mbps and ifSpeed < 650 Mbps: 32-bit packet counters and 64-bit byte counters
ifSpeed
650 Mbps: 64-bit byte and packet counters
RFC 2863 also provides an example:
"A 10-Mbps stream of back-to-back, full-size packets causes ifInOctets to wrap in just over 57 minutes; at 100 Mbps, the minimum wrap time is 5.7 minutes, and at 1 Gbps, the minimum is 34 seconds."
The sending frequency is not relevant, because the occurrence of critical events cannot be determined in advance, and SNMP notifications are sent immediately after an event occurs.
A disadvantage of SNMP is the time scale of information. Depending on the implementation, counters are updated in intervals of seconds or tens of seconds. In general, polling faster than every 30 seconds implies that the results might be inaccurate.
NetFlow
Historically, Cisco NetFlow has incorporated the push model, in which the devices send records periodically to the collection server, up to multiple times per second at fully utilized high-end devices. The alternative of storing all accounting records at the device would require a large amount of memory; therefore, the push model was chosen.
An alternative is the NetFlow MIB, which does not collect individual flow records. Instead, it keeps summary details, such as Top-N active flows, flows with the largest number of packets, and some flow-specific details, such as AS numbers. The MIB is based on the pull model, so an application has to request the data export explicitly.
These two cases of NetFlow make it clear that one accounting technology can implement both the push and pull models in parallel, based on different requirements.
Connection Mode, Congestion Handling, and Reliability
Histprically, he NetFlow export was based on the UDP protocols and as a result is connectionless. Performance was the main reason for choosing UDP, because a NetFlow-enabled high-end network element can fully utilize an OC-3 link with NetFlow data records. UDP has no mechanism for congestion handling. This results in the best practice of placing a collection server close to the NetFlow devices and assigns a dedicated interface for the export if possible. The only reliability function is a sequence number in the export datagrams: collection applications can interpret the number, calculate the number of lost flows, and notify the administrator.
NetFlow version 9 offers the flexibility to choose another protocol than UDP: SCTP-PR (Partially Reliable SCTP). Historically, reliability has been directly related to the connection approach. For example, TCP implements a fully reliable mode, and UDP chooses the unreliable mode. SCTP introduces a paradigm shift and offers three different modes of reliability: fully reliable, partially reliable, and unreliable. Applications can choose which model fits best, potentially changing the modes dynamically under different circumstances, but still using the same transport protocol.
Note that reliability can also be increased by exporting to two different collection servers, which is a feature that NetFlow supports.
Send and Retrieve Frequency
For NetFlow, the send frequency is actually the exporting frequency of the push model that NetFlow deploys. Two timers and two extra conditions determine when flow entries are exported from the cache:
Active flows timeout (the default is 30 minutes)
Inactive flows timeout (the default is 15 seconds)
Transport is completed (TCP FIN or RST)
The flow cache has become full
This means that long-lasting flows are terminated after 30 minutes, the flow records get pushed to the collector, and new cache entries are created. "Transport completed" applies only to TCP flows, where the session termination can be identified by checking either the finish (FIN) or reset (RST) bit in the TCP header. Alternatively, inactive UDP flows are terminated almost immediately, after 15 seconds by default. If the flow cache is almost full and not enough memory is available for new entries, the network element starts exporting flows more aggressively to free up memory resources.
FTP
Another illustration of the pull model is to store data in the device flash memory and retrieve it using File Transfer Protocol (FTP) afterwards. An example is system-logging messages, which provide error and debug messages generated by the router. These messages can be stored in a router's memory buffer instead of being sent to an NMS station via syslog or SNMP, which could lead to lost messages due to the unreliable nature of UDP. The drawbacks of this mechanism are that older messages are overwritten by new messages when the buffer is full and that all logging messages are erased when the router reboots. An alternative is to write messages to the router's flash card, which provides persistent data storage when the router reboots. An example is the "syslog writing to flash feature" in Cisco IOS, which enables system logging messages to be saved on the router's flash disk. A server retrieves these messages by executing a copy command on the router, which then pushes the log files through FTP to the server. Potentially, this method could be implemented for all MIB variables to store data persistently.
Connection Mode, Congestion Handling, and Reliability
FTP uses TCP as the transport protocol. TCP was covered earlier in this chapter.
Authentication, Authorization, and Accounting (AAA) Architecture
Accounting is a relevant part of the AAA architecture, as defined by the IETF in RFCs 2905, 3127, and 3539. Authentication, Authorization, and Accounting (AAA) was developed to identify users who connect to the network or administrators who perform operations on network elements. The AAA architecture requires at least one NAS, which can be a router with dial-in interfaces to authenticate external users' access to the network. Or it can be any core router or switch with AAA client functionality to authenticate network operators' access to devices. To increase scalability and manageability, the user profiles should be defined at a central AAA server (RADIUS, TACACS+, Diameter) and not on each NAS.
Connection Mode, Congestion Handling, and Reliability
AAA builds on three protocols: RADIUS, TACACS+, and Diameter. Diameter is the next generation of AAA, specified by the IETF (RFC 3588, Diameter Based Protocol). It is based on RADIUS, but it offers additional functions and extensibility, such as reliable data transfer over TCP and SCTP, failover, extended error handling, and improved security features such as IPsec and TLS. Although RADIUS and TACACS+ were developed to address dialup and terminal server access, Diameter also supports new access technologies, such as DSL and roaming support for mobile wireless environments.
Send and Retrieve Frequency
AAA deploys a push model, in which messages from the NAS get sent to the AAA server based on events such as user connects or disconnects. Accounting records are sent at the end of the user session but can optionally be sent regularly. The IOS command aaa accounting update causes an interim accounting record to be sent to the accounting server whenever there is new accounting information to report.
Note
Configuring the NAS to send periodic accounting updates can cause heavy congestion when many users are logged into the network.
Network Design for the Collection Infrastructure
With a good understanding of the push and pull concepts, the next step is to identify how to transfer the collected data sets from the network elements to the collection server. One approach is to leverage the existing infrastructure that transports the users' traffic. This is also referred to as in-band management; it's certainly the easiest and cheapest option. You should be aware of the limitations, such as consuming user bandwidth for administrative purposes, and the vulnerability of the management traffic to attacks or modifications from the user community. An alternative is to set up a dedicated infrastructure for management purposes; this is also called the Data Communication Network (DCN). A good analogy for this is a dedicated traffic lane for buses, taxis, and emergency vehicles, which offers "bandwidth" independently of the normal traffic. Related to networks, this concept is known as out-of-band (OOB) management; it uses either a dedicated network infrastructure (DCN) or a logical network on top of the shared infrastructure. The dedicated infrastructure can be a simple dial connection to a terminal server in a remote location, which connects to the terminal ports of the equipment, or the Cadillac solution with separate LAN and WAN connections. Benefits are the reliable bandwidth and throughput under all circumstances and the security enhancements of shielding the management traffic from users. Best practices recommend the use of OOB infrastructure whenever possible.
A compromise is to set up a dedicated VLAN or VPN for management purposes. In this case, the common infrastructure is leveraged for user traffic and network management operations, but the traffic types cannot interfere with each other. In this case, defining quality-of-service classes is strongly recommended, to keep management traffic from being delayed or dropped under congestion situations.
Communication Concepts
After defining the transport infrastructure, communication concepts between the metering device and the receiver of the performance and accounting records need to be identified. The following communication concepts exist:
Unicast (one to one)
Multicast (one to many)
Broadcast (one to all)
Communication bus (a combination of unicast, multicast, and broadcast)
Unicast communication is applied in case of a central NMS server scenario, in which network elements communicate with a central server. Because a single server is also a single point of failure, a backup server concept should be implemented. Although this increases availability, it also requires the device to send the records to both servers—either continuously or by checking the availability of the primary server and by sending traffic to the backup server only if the primary server is unavailable. An alternative to exporting data twice is to send it to a multicast address so that the export device does not need to inspect to which server the records need to be sent. For completeness, it should be mentioned that broadcasting the messages to every device in the network is not recommended!
A relatively new concept introduces a communication bus for data exchange, also referred to as the publish and subscribe bus. All communication partners are connected to the bus and have a special listener component installed that monitors messages on the bus. Messages are classified into specific categories and are broadcast on the bus. To receive a message, you subscribe to one or multiple categories. The benefit of this approach is that the sender does not need to know anything about the receiver, which makes the integration of new applications easier. Imagine you have a communication bus in place, and you plan to deploy a billing application. Without a bus concept in place, you have to configure all devices and some of the existing management applications to send information to the new billing application. Now you only need to enable the collection of accounting records at the device level and have the billing application register for accounting records. Note that the broadcast concept of a bus architecture is not designed for bulk data transfer, because the bus interconnects multiple senders and receivers. In most cases the large number of accounting records only needs to be transferred between the collection device and the collection application. For example, exchanging RADIUS records over the bus is acceptable, while exchanging all NetFlow records from multiple devices over the bus is not appropriate. The bus communication is limited to a LAN environment (broadcast domain) and can be extended across WAN connections by point-to-point software adapters.
Figure 2-25 illustrates the one-to-one, one-to-many, and many-to-many communication methods. Collection server 1 has a one-to-one relationship with mediation device 1, and collection server 2 has a one-to-many relationship with mediation device 1 and the backup meditation server. Both mediation devices and all application servers use the publish and subscribe bus for many-to-many communication.
Figure 2-25. Communication Concepts

Collection Server Concepts
The next instance to consider is the collection server. Distinguishing the various processing steps provides a better understanding of the overall collection. After metering at the device level, data records are either sent to a collection server (push model) or retrieved by the server (pull model). Collecting device MIB information via SNMP is an example of the pull model. Waiting for a device to push NetFlow records to the collecting server is an illustration of the push model. In both cases, post-processing is required to transform data sets into useful business information. Collection also includes monitoring the received packets for completeness. For example, NetFlow includes a flow counter that helps the collection server identify lost datagrams. The post-processing functions are described in the next chapter. For now, the focus is on the collection part only. In summary, the collection server performs the following tasks:
Data retrieval (pull or push)
Monitoring the retrieved records and identifying lost data record loss between the device and the collection server (if the protocol supports it)
Basic filtering functions (for example, filter all network management traffic) (optional)
Threshold monitoring (optional)
Data record formatting
Data record storage
Placing the Collection Server (Centralized, Distributed)
A significant task is identifying how many collection servers are required and where in the network to place them. In a small or medium network, it can be sufficient to have one or two central servers and collect all accounting and performance records at these central instances. This eases the administration but increases the network load, because all records are transferred from the devices to the servers. Alternatively, distributing servers in the network reduces the transmitted traffic, because it gets sent after processing. Best practice suggests a central design if only a small number of (central) network elements collect data records and the traffic overhead is low to medium. In case of a NetFlow deployment at multiple network elements with high-speed interfaces, a distributed model is appropriate. You should calculate the estimated amount of generated accounting and performance data before selecting the central or distributed concept. If you want to monitor the traffic flows through the core of your network, it is sufficient to export the data records from the core devices to a central server. In case of usage-based billing, distributed collectors at the main remote locations are probably a better solution than deploying a central server. Figure 2-26 shows the collection server placement for these examples. In this case, the CEs export to the local collector in each PoP, and the PEs export to the central collector. The billing application collects data records from the three local collectors, and the core planning application server connects to only the central server.
Figure 2-26. Central and Local Collection Servers

In a distributed environment, as illustrated in Figure 2-26, the hierarchy concept becomes relevant. A different scenario is for all devices in each PoP (CEs and PEs) to export to the local collector, which then sends aggregated data sets to the central collection server. An application server would communicate with only the highest level in the hierarchy, which is the central server in Figure 2-26. Although these two examples describe the push model, the same concept can be applied to the pull model, where distributed management servers collect (pull) data from the local devices and provide preprocessed data sets for the central application. Introducing a hierarchy increases scalability. If you want to increase the reliability, consider pushing data records to two collection servers (for example, NetFlow records or SNMP traps), but be aware of the impact this has on the network and device performance.
Note
In a distributed server environment, with or without a hierarchy, the synchronization of servers is important. This relates to time synchronization (NTP) as well as data set synchronization between the local and central servers.
Real-Time Requirements
In most cases, performance and accounting records do not have to be collected in real time, especially when accounting records are gathered for a monthly invoice. Identifying performance peaks is more time-critical but still does not require per-second precision. A completely different scenario occurs in a prepaid environment. If a user pays upfront for a voice call or Internet access at a wireless hotspot, these scenarios demand real-time measurement. This can be deployed on a time basis so that the NAS disconnects the user when the budget expires. The complexity increases if the requirements are deployed based on traffic volume, where real-time processing of packets or flow records is mandatory. This is a difficult task, which explains why most business implementations today only apply real-time accounting over time, not volume. Real-time collection is also required by security monitoring applications, such as detecting denial-of-service (DoS) attacks. Most attacks occur during a relatively small window of time; therefore, the data sets should be available to the security application almost immediately after generation.
Connection Mode, Congestion Handling, and Reliability
For real-time requirements, some form of a connection-oriented session between the server and the network element has to be established. A constant status check (keepalive) might be enough, as long as it guarantees that a connection loss can be detected immediately. Especially in case of metering for DoS attacks, congestion management and reliability are necessary to keep the network and services operational. In a prepaid environment, the reliability of the collection infrastructure is directly related to profit generation—or profit loss.
Send and Retrieve Frequency
The send frequency in real-time environments mostly depends on the business case. If the requirements demand 1-minute exactness, the retrieval frequency needs to be less than 1 minute. This might also call for a modification of the timers in the different technologies. The default active timer in NetFlow is 30 minutes; it would have to be reduced. The same applies for polling of SNMP counters from the management application, which occurs more frequently in real-time environments.







