Advanced Features
The following features describe enhanced reporting functionality, such as scheduling, statistics, history collection, working with thresholds, and using enhanced object tracking for automated actions.
Scheduling
You define IP SLA operations using two steps:
Step 1. | Configure the explicit test packet parameters, such as packet size, packet interval, destination address, and so on. |
Step 2. | Define the operational parameters, including start time, lifetime, recurring operations, and so on. An operation can start immediately or start at a certain month, day, and hour. An alternative is to use the pending option to set the operation to start later. This is also used when an operation is a reaction (threshold) operation waiting to be triggered. |
Normal scheduling of IP SLA operations lets you schedule one operation at a time. If no start time is configured, the operation starts immediately, which is no problem if an operation is defined and activated by an operator using the CLI. The situation changes if multiple operations are defined without a specific start time and the network element reloads. Imagine that you have defined 1000 operations at one device with an immediate start. After a reboot, all operations start immediately. This results in a CPU spike at the device and potentially a sudden burst of IP SLA test traffic in the network. Neither of these effects is beneficial to accurate network measurements.
As a workaround, three IP SLA features were introduced to solve the issue:
Recurring Function
Multiple Operation Scheduling
Random Scheduling
Recurring Function
The Recurring Function allows you to define an operation's exact start time. For example, you could start a DHCP operation at 8 a.m. every day. However, if you have large networks with thousands of IP SLA operations on which to monitor network performance, scheduling each operation individually is time-consuming and inefficient.
The following example tests reachability of the DNS server every day at 7 a.m. When combined with the "trap option" of the threshold reaction feature, the network operators are alerted in case of an issue and have a chance to fix it before the majority of users arrive.
Router(config)# ip sla 9 Router(config-ip-sla)# dns dns.cisco.com Router(config)# ip sla schedule 9 recurring start-time 07:00:00
Multiple Operation Scheduling
The Multiple Operation Scheduling feature offers, using a single CLI command or the CISCO-RTTMON-MIB, the option to schedule multiple IP SLA operations to run at evenly distributed times over a specified period. A reboot of the router does not affect the scheduling functionality. The following parameters can be configured for the Multiple Operation Scheduling:
Group operation number defines the group configuration or group schedule number of the IP SLA operation to be scheduled. The IP SLA operations must be configured before they can be scheduled as a group.
Operation ID numbers defines the list of operation IDs to be scheduled in an operation group.
Schedule period defines the amount of time for which the operation group is scheduled.
Age out specifies how long the operation is kept in memory when it is not actively collecting information (the default is indefinitely).
Frequency sets the period of time that passes before the operation group is started again (repeated). The frequency statement on the group schedule rewrites the operation frequency of all operations belonging to the group. Note that if the group frequency is not specified (this is optional), the frequency is assumed to be equal to the "schedule period" parameter.
Life configures the total amount of time for the operation to collect information. The operation can be configured to run indefinitely (the default is 1 hour).
Start time sets the starting time for the operation; this can be immediately or an absolute start time.
The Multiple Operation Scheduling functionality plans the maximum number of possible operations. However, this functionality skips IP SLA operations that are already running or those that are not configured. The total number of operations is calculated based on the number of operations specified in the command, irrespective of the number of operations that are missing or already running. Besides keeping multiple operations from starting at exactly the same time after a reboot, another benefit of the Multiple Operation Scheduling function is the equal distribution interval, which offers more consistent monitoring coverage. To illustrate this scenario, consider configuring 60 operations to start at the same 1-minute interval over a 1-hour period. Each operation tests connectivity to a different remote site and runs for 30 seconds, so it tests the reachability within the network once every hour. If all operations start at the same time, connectivity is tested only during the first 30 seconds of every hour for the whole network. If a network failure occurs after all 60 operations have completed, and the network is restored before the operations are due to start again, this failure is not detected by any of the 60 operations. However, if the 60 operations are distributed equally at 1-minute intervals over a 1-hour period, you test connectivity to one site each minute. This increases the chances of detecting a major network outage, because operations are running continuously, and not all tests are performed at the same time.
Note
You cannot use the Multiple Operation Scheduling feature in conjunction with the Recurring Function.
The following example schedules all operations from 1 to 11 to be equally distributed every 120 seconds. This means that each new operation starts 12 seconds after the previous one. The group scheduling is repeated every 10 minutes. Note that if individual operations had a frequency configured, this value is overwritten with the new frequency of 120 seconds.
Router(config)#ip sla group schedule 1 1-11 schedule-period 120 frequency 600 start-time now life forever Router # show ip sla group schedule 1 Group Entry Number: 1 Probes to be scheduled: 1-11 Total number of probes: 11 Schedule period: 120 Mode: even Group operation frequency: 600 Status of entry (SNMP RowStatus): Active Next Scheduled Start Time: Start Time already passed Life (seconds): Forever Entry Ageout (seconds): never
Random Scheduling
The Random Scheduling feature offers more randomness in the operation schedule. The Multiple Operation Scheduling feature imposes a frequency for the operations belonging to the group. If by chance this frequency perfectly matches the repetition of particular traffic patterns or network behavior (such as traffic load and queue full), the observed metrics might be biased. With the IP SLAs Random Scheduler feature, you can schedule multiple IP SLAs operations to begin at random intervals uniformly distributed over a specified duration of time and to restart at uniformly distributed random frequencies within a specified frequency range. Therefore, the Random Scheduling improves the statistical metrics for assessing network performance.
The following example schedules all operations from 1 to 11 to be equally distributed on a first schedule period of 120 seconds. This means that each new operation starts 12 seconds after the previous one. After the initial schedule, each operation chooses a random interval upon every invocation of the probe, over the interval 540 to 660 seconds (9 to 11 minutes).
Router(config)#ip sla group schedule 1 1-11 schedule-period 120 frequency range 540-660 start-time now life forever Router# show ip sla group schedule 1 Group Entry Number: 1 Probes to be scheduled: 1-11 Total number of probes: 11 Schedule period: 120 Mode: random Group operation frequency: 540-660 Status of entry (SNMP RowStatus): Active Next Scheduled Start Time: Start Time already passed Life (seconds): Forever Entry Ageout (seconds): never
Distribution of Statistics
IP SLA provides a variety of operations that can meter very specific performance monitoring details. Although it is useful to have a large number of detailed metrics, this also leads to the challenge of storing the data records at the device. Storing every result of each operation would require large amounts of memory and additional network bandwidth for exporting them. Currently, operations results are stored at the device and retrieved via a pull model, which can be CLI (Telnet or scripts) or SNMP. An important concept to reduce memory consumption is to aggregate the collected performance metrics. Instead of keeping results of all test packets, only those values used for statistical performance analysis are stored. Consider the response time results: from an SLA perspective, you are probably interested in the minimum and maximum value and a distribution curve. In addition, you want to collect the sum of completion times to calculate the mean value and the sum of the squares of completion times to calculate the standard deviation. Ideally, the percentile collection would be a desirable output; however, IP SLA does not yet provide this.
The distribution of statistics feature offers a statistical distribution of response times, which can be thought of as a set of counters that hold the results of test packets. The operator defines a number of response time buckets, IP SLA aggregates the individual results into these buckets, and the result is a response-time distribution curve. Each bucket holds a counter for the number of completed operations that fall into that specific time interval. For example, if the distribution interval is 20 ms and the number of buckets is three, the following buckets are defined:
Bucket A = < 20 ms
Bucket B = 20 to 40 ms
Bucket C = >40 ms
Assuming that five operations are performed with response times of 10 ms, 15 ms, 30 ms, 40 ms, and 80 ms, the counters are incremented as follows: bucket A = 2 (10 and 15 ms), bucket B = 2 (30 and 40 ms), and bucket C = 1 (80 ms).
Note
Statistics distribution collection is supported for the ICMP Echo, ICMP PathEcho, UDP Echo, VoIP UDP Jitter, TCP Connect, DNS, and DLSW+ operations. By default, the statistics distribution is kept for the last 2 hours. Note that the history collection feature, described in the next section, lets you change this default value.
Several statistics can be collected:
Number of statistic distribution buckets sets the number of buckets or statistical distributions kept during the operation's lifetime. Size is the number of buckets that contain data counts for their intervals. This applies to the following operations: ICMP Echo and PathEcho, UDP Echo, TCP Connect, DNS, and DLSw+.
Statistical distribution interval sets the time interval for each statistical distribution. This applies to the following operations: ICMP Echo and PathEcho, UDP Echo, TCP Connect, DNS, and DLSw+.
Number of statistic paths collects statistical distributions for multiple paths between source and destination. The size parameter specifies the number of paths for which statistical distribution buckets are maintained per hour for each operation. This applies to the ICMP PathEcho operation only.
Table 11-2 illustrates the assignment of multiple samples into the defined buckets (in this case, buckets are defined in increments of 20 milliseconds) and the resulting total number of items per bucket.
| Response Time | Response Time Buckets | ||||||
|---|---|---|---|---|---|---|---|
| 0–20 | >20 to 40 | >40 to 60 | >60 to 80 | >80 to 100 | >100 to 120 | >120 | |
| 63 | 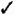 | ||||||
| 47 | | ||||||
| 19 | | ||||||
| 181 | | ||||||
| 96 | | ||||||
| 29 | | ||||||
| 101 | | ||||||
| 55 | | ||||||
| 91 | | ||||||
| 103 | | ||||||
| 66 | | ||||||
| 82 | | ||||||
| 41 | | ||||||
| Number of Entries | 1 | 1 | 3 | 2 | 3 | 2 | 1 |
The following example displays the configuration of a udpEcho operation type, for which the distribution of statistics feature is enabled. Similar to Table 11-2, the distribution contains seven buckets, and the distribution interval is kept to its default value of 20 ms.
Router(config)# ip sla 1 Router(config-ip-sla)# udp-echo 10.48.71.7 65000 source-ip 10.48.71.24 Router(config-ip-sla-udp)# distributions-of-statistics-kept 7 Router(config)# ip sla schedule 1 life forever start-time now Router# show ip sla statistics aggregated detail Captured Statistics Entry = Entry number StartT = Start time of entry (hundredths of seconds) Pth = Path index Hop = Hop in path index Dst = Time distribution index Comps = Operations completed OvrTh = Operations completed over thresholds SumCmp = Sum of RTT (milliseconds) SumCmp2L = Sum of RTT squared low 32 bits (milliseconds) SumCmp2H = Sum of RTT squared high 32 bits (milliseconds) TMax = RTT maximum (milliseconds) TMin = RTT minimum (milliseconds) Entry StartT Pth Hop Dst Comps OvrTh SumCmp SumCmp2L SumCmp2H TMax TMin 1 4951858 1 1 1 28 0 82 382 0 11 1 1 4951858 1 1 2 0 0 0 0 0 0 0 1 4951858 1 1 3 0 0 0 0 0 0 0 1 4951858 1 1 4 0 0 0 0 0 0 0 1 4951858 1 1 5 0 0 0 0 0 0 0 1 4951858 1 1 6 0 0 0 0 0 0 0 1 4951858 1 1 7 0 0 0 0 0 0 0
From the show ip sla statistics aggregated detail output, the conclusion is that the first bucket (from 0 to 20 ms) contains all the test-packet results. Note that Dst, referenced by the Time distribution index, basically refers to the bucket number.
History Collection
In addition to gathering aggregated statistics, IP SLA can store the exact results from previous operations. This is useful for troubleshooting purposes to identify when a performance degradation or network outage occurred. With history collection enabled, IP SLA stores data samples for a given operation; these samples are called history data and are stored in buckets. Each bucket contains one or more history entries from the operation. By default, history data is not collected. Instead, the result of every operation is added to the aggregated statistics buckets, as described in the section "Distribution of Statistics."
Related to history is the concept of lives. A life is defined as an operation's lifetime, and entries related to the life are stored. A maximum number of buckets can be configured for each life. When the number of buckets reaches the limit, no further history for this life is stored. The valid range is from 1 to 100, with a default of 100 buckets. Each time IP SLA starts or restarts an operation, a new bucket is created until either the number of history buckets matches the maximum size or the operation's lifetime expires. History buckets wrap, which means that the oldest entry is overwritten by the newest entry.
History collection is supported by the following operations: ICMP Echo, ICMP PathEcho, UDP Echo, TCP Connect, DNS, and DLSW+. In case of UDP PathEcho, an entry is created for each hop along the path that the operation takes to reach its destination. History collection is not supported for HTTP and UDP Jitter because of the large data volume required for these operations.
Starting with IOS 12.2(11)T, history enhancements were added to IP SLA, where the operator can specify the compilation interval and number of groups of data to be collected and stored in buckets. The purpose of the history feature is to compare current network performance with a configurable compilation interval. For example, if you configure 96 buckets, each containing 15 minutes (900 seconds) of aggregated measurements, you can store 24 hours of performance information: 24 hours * (60/15 minutes) = 96:
Router(config)# ip sla 1 Router(config-ip-sla)# udp-echo 10.48.71.7 65000 source-ip 10.48.71.24 Router(config-ip-sla-udp)# history enhanced interval 900 buckets 96
Enhanced history is supported for TCP Connect, UDP Jitter, Frame Relay, and ATM operations only. In the case of Frame Relay and ATM, the default bucket settings are 15 minutes with a total of 100 buckets. The operator cannot modify these defaults. The IP SLA Jitter operation does not support history of statistics because of the large amount of collected data. Enhanced history statistics do not include voice scores.
Note
Collecting history increases memory usage. Collect history only for troubleshooting and analysis purposes. For measuring performance metrics, use the statistics collection function.
A proposal to overcome the memory limitations for both statistics and history collection is to use the IPFIX protocol as an export mechanism. This would add a push model to IP SLA, where the device sends ("pushes") the data records to a collection server. This could increase the level of collected details, especially for history collection, and could offer IP SLA a similar flexibility of exporting functions as NetFlow has today. Right now, IP SLA supports only the pull model, in which data is stored locally and retrieved from an NMS system.
Thresholds and Notifications
IP SLA supports threshold monitoring to react to certain network conditions; this includes the capability to trigger SNMP notifications based on defined thresholds. For example, if IP SLA measures too much jitter on a connection, it can generate a notification to a network management system. This allows proactive network monitoring instead of constantly polling the MIB. Especially when gathering the IP SLA performance statistics primarily for fault management purposes, threshold monitoring can decrease the time to identify violation of SLA parameters and at the same time reduce SNMP polling significantly. Threshold conditions can define an upper and lower threshold value as a hysteresis function, so a notification is sent only once when crossing the threshold. Figure 11-7 shows the result of an RTT operation with upper (100-ms) and lower (50-ms) thresholds defined and shows when events are generated.
Figure 11-7. IP SLA Hysteresis Function

In addition to sending a notification, a threshold violation can activate another IP SLA operation for further analysis. For example, an additional operation can be initiated for troubleshooting. An example would be to run a basic ICMP Echo operation to measure RTT every 5 minutes and, in case of a threshold violation, to start additional ICMP Path Jitter operations for troubleshooting purposes. If the measured value drops below the defined threshold, the additional operation is stopped. You can configure multiple thresholds for the same operation. For example, you could configure a VoIP UDP Jitter operation and define a one-way delay threshold, and additionally configure a MOS threshold for the same operation.
IP SLA reactions are defined in the following sequence:
Step 1. | Configure the monitored elements (connection loss, timeout, RTT, jitter, packet loss, MOS). Thresholds can be defined for the following parameters:
|
Step 2. | Configure the threshold violation types (immediate, consecutive, x of y, averaged). |
Step 3. | Specify the reaction event (none, trap, trigger, trap and trigger). |
Threshold violation defines the trigger or combination of events that activate an action. IP SLA supports the following triggers:
Immediate triggers an event immediately when the value for a reaction type (such as response time) exceeds the upper threshold value or falls below the lower threshold value, or when a timeout, connection loss, or verify error event occurs.
Consecutive generates an event after a violation takes place a number (n) of times consecutively. For example, this type would be used to configure an action to occur after a timeout is repeated three times, or when the RTT exceeds the upper threshold value n times. The default value is n = 5.
x of y triggers an event after a number (x) of violations within another number (y) of operations. The default value for x and y is 5. Example: generate an event if the jitter exceeds 30 ms for 10 (x) times during 100 (y) UDP Jitter operations.
Average triggers an event when the averaged totals of a value for a number (n) of operations exceeds the specified upper threshold value or falls below the lower threshold value. This function avoids alarming for peak values, because only the average value of a number of operations is monitored. The default value for n is 5.
The reaction event specifies the action type to be taken when a threshold is breached. Four options exist:
None— No action is taken.
Trap only— Sends an SNMP trap when the specified violation type occurs.
Trigger only— Transits one or more predefined operations from pending" to "active" when the violation conditions are met. Each activated operation continues until its life expires. A triggered operation must finish its life before it can be triggered again.
Trap and trigger— Triggers an SNMP trap and starts another IP SLA operation.
In addition to generating SNMP traps (with the rttMonNotification notification), IP SLA can generate system logging (Syslog) messages when the reaction threshold is crossed for criteria such as packet loss (unidirectional), jitter (unidirectional), and MOS. These logging messages can then be forwarded to the NMS as Syslog messages or SNMP notifications.
The threshold and notifications concept was enhanced even further with Enhanced Object Tracking for IP SLA, which is described in the next section.
The following example configures a jitter operation for which a trap is fired immediately after the maximum negative delay from source to destination crosses the maximum value of 10 ms and the minimum value of 2 ms:
Router(config)# ip sla 2 Router(config-ip-sla)# jitter 10.48.71.7 430 Router(config)#ip sla reaction-configuration 2 react maxOfNegativeDS threshold-value 10 2 threshold-type immediate action-type trapOnly Router(config)# snmp-server enable traps rtr Router# show ip sla reaction-configuration Entry number: 2 Index: 1 Reaction: maxOfNegativeDS Threshold Type: Immediate Rising: 10 Falling: 2 Threshold CountX: 5 Threshold CountY: 5 Action Type: Trap only
The following example measures the RTT toward the destination 10.10.10.10 with an ICMP Echo message. Whenever three consecutive results exceed the value of 100 ms, not only is a trap fired, but operation number 6 is started. Operation 6 measures the RTT for each hop of the path, allowing faster troubleshooting of the bottleneck.
Router(config)# ip sla 5 Router(config-ip-sla)# icmp-echo 10.10.10.10 Router(config)#ip sla reaction-configuration 5 react rtt threshold-value 100 20 threshold-type consecutive action-type trapAndTrigger Router(config)# ip sla reaction-trigger 5 6 Router(config)# ip sla 6 Router(config-ip-sla)# path-echo 10.10.10.10 Router(config)#snmp-server enable traps rtr Router# show ip sla reaction-configuration 5 Entry number: 5 Index: 1 Reaction: rtt Threshold Type: Consecutive Rising (milliseconds): 100 Falling (milliseconds): 20 Threshold CountX: 5 Threshold CountY: 5 Action Type: Trap and trigger Router#show ip sla reaction-trigger 5 Entry number: 5 Target Entry Number: 6 Status of Entry (SNMP RowStatus): active Operational State: pending
Enhanced Object Tracking for IP SLA
Enhanced object tracking for IP SLA is a new feature introduced in Cisco IOS Software Releases 12.3(4)T and 12.2(25)S. It creates a link between performance monitoring and routing protocols, directly at the network element. In the past, the only relationship between the IP SLA monitoring results and routing decisions in the network existed at the NMS application level. If a certain network connection did not perform according to the SLA definitions, a performance management application could have modified a router's forwarding table. Because this is a complex approach, it was not widely deployed. Enhanced Object Tracking (sometimes called EOT) solves this issue right at the network element. It allows the tracking of state and reachability of IP SLA operations and allows the insertion or deletion of static routes, depending on the state of the tracked object.
Before Enhanced Object Tracking was introduced, only HSRP had a simple tracking mechanism that allowed tracking the interface state. If the interface's line-protocol state went down, the router's HSRP priority was reduced, allowing another HSRP router with a higher priority to become active. Although this mechanism is effective for link-down situations, it cannot be used in conjunction with performance monitoring. The Enhanced Object Tracking feature overcomes this limitation by providing complete separation between the tracked objects and the initiated action when an object state changes. Although it offers more functionality than just IP SLA support, because of this book's focus, the other tracking features are not described here. The results of IP SLA operations can be used to change routing decisions for so-called "first-hop routing protocols" (FHRP), such as Hot Standby Router Protocol (HSRP), Virtual Router Redundancy Protocol (VRRP), and Gateway Load-Balancing Protocol (GLBP). These protocols can register and track objects with the tracking service, and each can take different actions when the state of an object changes. A unique number, specified by using the tracking command-line interface in IOS, identifies each tracked object. Client processes use this number to track a specific object. The tracking service periodically polls the objects and notes any value changes; these changes are communicated to interested clients, either immediately or after a specified delay. The object values are reported as either up or down. Every IP SLA operation maintains an operation return-code value, which is interpreted by the tracking process. Examples of return codes are OK, OverThreshold, and specific operation values. Two aspects of an IP SLA operation can be state and reachability, where the difference between the two relates to the OverThreshold return code. Table 11-3 shows the state and reachability aspects of IP SLA operations that can be tracked.
| Tracking | Return Code | Tracking State |
|---|---|---|
| State | OKNot OK (everything else) | UpDown |
| Reachability | OK, OverThresholdNot OK (everything else) | UpDown |
Figure 11-8 illustrates using Enhanced Object Tracking in a network.
Figure 11-8. IP SLA Enhanced Object Tracking

The customer site on the left is connected to the ISP. For redundancy reasons, two routers are grouped with HSRP. An SLA is defined for connectivity, delay, and jitter between the customer site and the data server site. In this setup, a hardware or link failure at R1 would result in a switchover to R2 and vice versa; this is the basic HSRP function. In addition, two IP SLA operations are defined to measure the SLA in conjunction with Enhanced Object Tracking. If one IP SLA operation returns a threshold violation, Enhanced Object Tracking influences the local HSRP priority, which in turn switches the traffic via the alternate router.
In other words, the result of the IP SLA operation influences the HSRP process to select the exit router with the well-performing link toward the data center. This is an interesting fault management scenario as well. If one link is disabled (for connectivity or performance reasons), a notification should be sent to the central fault management application, and the operator can start the troubleshooting process immediately. This avoids outages and increases a service's uptime.
In the following example, EOT object 100 tracks the result of operation 1, which runs an icmp-echo to the server address 10.10.10.100. If operation 1 changes its status, which indicates that reachability to the data center is lost, HSRP on R1 decrements its priority by 10. As a consequence, R2 is chosen as the default gateway for the customer site.
R1(config)# ip sla 1 R1(config-ip-sla)# icmp-echo 10.10.10.100 R1(config)# ip sla schedule 1 start-time now life forever R1(config)# track 100 rtr 1 state R1(config)# interface FastEthernet0/0 R1(config-if)# standby 1 ip 10.10.10.10 R1(config-if)# standby 1 priority 105 R1(config-if)# standby 1 preempt R1(config-if)# standby 1 track 100 decrement 10







