Metering Methods: How to Collect Data Records
With a clear definition of what to collect and who the user is, the question of how to collect data records becomes relevant. Common terms are meter and metering. The term meter describes a measuring process, even though a more precise definition is required for accounting purposes. The definition of meter used in this book describes the measurement function in the network element or in a dedicated measurement device. Metering is the process of collecting and optionally preprocessing usage data records at devices in the network. These devices can be either network elements with integrated metering functionality or a dedicated measurement device ("black box") that is specifically designed as a meter.
The following details need to be considered for metering:
Meter placement, at the device interface or the central processor
Unidirectional or bidirectional collection
Collection accuracy
Granularity, which means aggregating packets into flows or aggregating multiple meters into a single value
Collection algorithm, which means inspecting every packet with a full collection, or only some packets with sampling
Inspecting the packet content for selection with filtering
Adding details to the collected data sets, such as time stamps and checksums
Export details, such as protocols, frequency, compression, and security
Active Versus Passive Monitoring
You can distinguish between two major monitoring concepts:
Passive monitoring— Also referred to as "collecting observed traffic," this form of monitoring does not affect the user traffic, because it listens to only the packets that pass the meter. Examples of passive monitoring functions are SNMP, RMON, Application Response Time (ART) MIB, packet-capturing devices (sniffer), and Cisco NetFlow Services.
Active monitoring— Introduces the concept of generating synthetic traffic, which is performed by a meter that consists of two instances. The first part creates monitoring traffic, and the second part collects these packets on arrival and measures them.
Note that both instances can be implemented in the same device or at two different devices.
A simple example of an active test is to set up a phone call to check if the destination's phone bell is operational. The Cisco IP SLA feature is an instantiation of active measurement. The main argument for passive monitoring is the bias-free measurement, while active monitoring always influences the measurement results. On the other hand, active measurements are easily implemented, whereas some passive measurements, such as the ART MIB, increase the implementation complexity. Table 2-16 summarizes the pros and cons of both approaches. Best practice suggests combining active and passive measurements to get the best of both worlds.
| Active Monitoring | Passive Monitoring | |
|---|---|---|
| Advantages | Identifies issues and bottlenecks in the network before users experience a service degradation, or even before a service is in place.
Measures application-specific parameters and per traffic class (DSCP). Easy to implement and deploy. | Directly monitors the user traffic.
No interference with live traffic. Most accurate for application traffic on a specific link. |
| Disadvantages | It is difficult to define the right parameters to simulate realistic traffic. The result is only an approximation of the real traffic.
Increases the network load. Influences the results by injecting traffic into the measured traffic. | Continuous measurement is required to avoid missing traffic types that are not present on the network during a short measurement interval. Full collection can lead to overload situations; therefore, sampling is a requirement. |
Passive Monitoring Concepts
Passive monitoring concepts are categorized into two groups:
Full collection— Accounts all packets and performs various operations afterwards.
Partial collection— Applies sampling or filtering to select only some packets for inspection.
In both cases, you can store either packets or flows, which leads to the definition of the two terms. Packets refer to individual instances, without identifying a relationship between them. Flows consist of packets related to each other—for example, because they belong to an exclusive data session between a client and a server.
A major distinguisher between different passive monitoring techniques is the unidirectional versus bidirectional type of collection. Unidirectional concepts, such as Cisco NetFlow, collect traffic in one direction only, resulting in multiple collection records (for example: record 1 is source 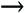 destination; record 2 is destination source). These have to be consolidated afterwards. Other technologies, such as RMON and the ART MIB, measure traffic in both directions and directly aggregate the results at the meter. At first glance, the bidirectional method seems more practical. Unfortunately, it cannot be applied in networks with asymmetric routing (which means that the return traffic takes a different route) or load sharing across multiple devices.
destination; record 2 is destination source). These have to be consolidated afterwards. Other technologies, such as RMON and the ART MIB, measure traffic in both directions and directly aggregate the results at the meter. At first glance, the bidirectional method seems more practical. Unfortunately, it cannot be applied in networks with asymmetric routing (which means that the return traffic takes a different route) or load sharing across multiple devices.
Full Collection
Full collection processes every packet and therefore guarantees that the output of the metering process is always exactly equal to the data passing the network element. Accuracy is the main advantage of a full collection! Major disadvantages are the large number of generated data records and the performance overhead caused by the collection. Full collection concepts are implemented for packet collection as well as flow collection. Various collection technologies have different performance impacts. For example, updating the device's SNMP interface counters consumes fewer resources than collecting NetFlow records. A clear distinguisher between various collection methods is the ability to differentiate applications in the data records. For example, SNMP interface counters collect only the total number of packets. They do not identify a relationship between packets of a type of application, which is also called stateful collection. Stateful collection identifies the associations between packets that belong to the same session (such as ftp file transfer) and does it bidirectionally: from source to destination and destination to source. In the case of TCP sessions, NetFlow implements a partly stateful flow collection, because flows are identified by start (SYN) and stop (FIN or RST) flags. It is not completely stateful, because no bidirectional correlation exists. Another full collection technique is the ART MIB, which is an extension of RMON and proposes a transactional method. Instead of the stateless collecting approach taken by RMON, ART identifies the start of a session, creates an entry for this transaction, and monitors the network for the associated return packet. The elapsed time between the initial packet and the response is measured and stored in the MIB. ART can identify all TCP applications as well as two protocols on top of UDP: NFS and SNMP.
Partial Collection
The increasing speed of interface technologies forced the development of alternative technologies to a full collection—for example, filtering and sampling. Today, Fast Ethernet is the default interface speed for a PC, whereas workgroup switches have multigigabit uplinks and optical WAN links that drastically increase transmission capabilities. To avoid CPU and memory resource exhaustion in the network elements and to avoid overloading the collection infrastructure, new sampling concepts are required. In the future, full collection methods such as NetFlow will not be scalable for high classification techniques; instead, they will require dedicated devices. For network elements, the proposed solution is to focus on sampling techniques, which is the reason for the in-depth analysis of sampling techniques in this book. Using sampling techniques for billing introduces a paradigm change, compared to the legacy world of SS7. Instead of applying "Don't forward traffic if you can't bill it," the new paradigm can be described as "First, forward traffic as fast as possible and apply billing as the second instance."
The definition of sampling used in this book is as follows:
Sampling is the technology of selecting a subset (the samples) of the total data set in the network, typically for accounting purposes, with the aim that the subset reflects most accurately the characteristics of the original traffic.
Another analogy would be a puzzle. How many pieces do you need until you can identify the full picture that the puzzle depicts? You have probably done this, so you know that not all pieces are required. Sampling in this case means assembling just enough puzzle pieces to envision the big picture. Therefore, the idea is to select only "important" packets and ignore "unimportant" packets. If you want to relate this to the puzzle analogy, you need to collect only those puzzle pieces that shape the object enough so that you can recognize the full picture.
Filtering Versus Sampling
An alternative technique to sampling is filtering, which applies deterministic operations based on the packet content. Whereas sampling can depend on the packet's position in time, space, or a random function, filtering is always a deterministic operation.
The definition of filtering used in this book is as follows:
Filtering is a deterministic operation that differentiates packets with specific characteristics from packets without these properties.
To follow the puzzle example, you apply a filter when you select all border pieces first. The filter criterion in this case would be "Select pieces only if one side has a straight line." After building the frame, you would probably select significant middle pieces with contrast and pictures, not pieces that are completely blue, such as those from the sky or the ocean. Figure 2-7 demonstrates the results of sampling and filtering.
Figure 2-7. Parent and Child Populations
Two terms are commonly used in the area of sampling and filtering:
Parent population describes the original data set from which samples are taken.
Child population describes the remaining data set after sampling, which is the sample.
The objective of sampling is to have the child population represent the parent population characteristics as exactly as possible; otherwise, the collection is biased and most likely of less use.
Sampling Methods
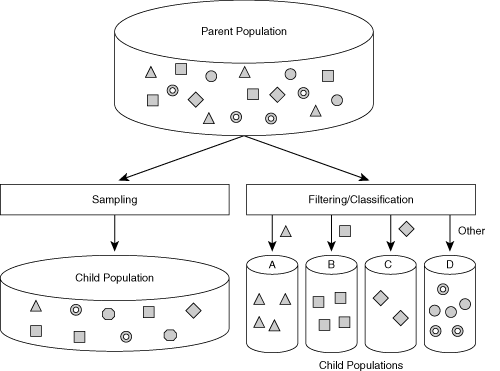
Shifting the focus back to the networking environment, it is advantageous to leverage sampling, especially on high-speed interfaces of the networking devices. The sampling process selects a subset of packets by either applying deterministic functions to the packet position in time or space or applying a random process. Deterministic sampling selects every nth packet or packets every n seconds, for example. An example of random sampling is selecting one out of 100 packets based on a random algorithm or a packet every 5 ms. Figure 2-8 illustrates random and deterministic packet sampling.
Figure 2-8. Deterministic and Random Sampling
Sampling compared to a full collection provides advantages for the metering device, the network that transports the data sets, and the application that processes the data afterwards:
Meter— Sampling increases the scalability to collect traffic at high-speed interfaces. Processing all packets becomes increasingly difficult.
Transport network— Sampling can reduce the data export from the meter to the collection server.
Application— A smaller data set reduces the required processing power at the mediation and application server.
After deciding to sample traffic, consider the sampling rate and the required accuracy, which is also called the confidence interval. If the sampling rate is too low (which means undersampling), the child population is less accurate as required by the confidence interval and does not correctly represent the parent population traffic received at the device. If the sampling rate is too high (oversampling), you consume more resources than necessary to get the required accuracy. For a better understanding of the different sampling techniques, the following structure applies in this chapter.
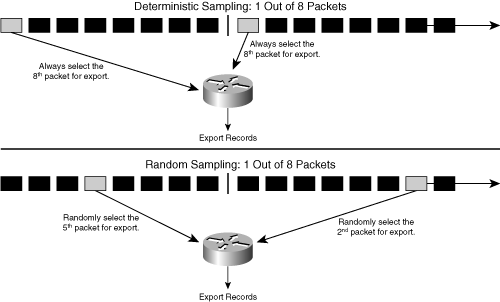
A relevant concept is the sampling strategy, such as deterministic (or systematic) and random (or pseudo-random, probabilistic) sampling. Deterministic sampling involves the risk of biasing the results if a periodic repetition occurs in the traffic that exactly matches the sampling rate or a multiple of it, as illustrated in Figure 2-9. Biasing reduces the match of the child and parent population and is counterproductive to the objective of an accurate matching between the two. Unfortunately, a periodic repetition of events in the observed traffic might not be known in advance, so a criterion for a "good" sampling algorithm is to have a good mixture of packets, and that is the starting point to consider random sampling. In other words, the deterministic sampling model is sufficient when the observed traffic does not contain any repetitions, which typically applies at high-speed interfaces. Random sampling is slightly more complex than deterministic sampling, because it implies the generation of the random numbers. However, random sampling increases the probability for the child population to be closer to the parent population, specifically in case of repetitions in the observed traffic. Best practice recommends using random sampling.
Figure 2-9. Examples of Deterministic and Random Packet Sampling
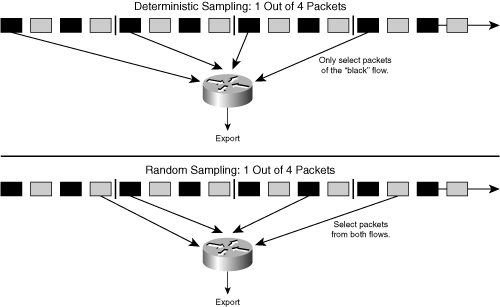
A number of research publications address this topic; consequently, it is sufficient to have just a simple example, as illustrated in Figure 2-9. In this case, traffic consists of two flows, and packets from each flow arrive in round-robin order. In the case of deterministic sampling 1-in-4, packets from only one flow are selected for processing, and random sampling "catches" packets from both flows. The reason is that the inverse of the sampling rate (4) is a multiple of the traffic repetition (2).
Another concept is packet sampling versus flow sampling, which applies for both random and systematic sampling:
Packet sampling selects packets according to an algorithm and may combine multiple packets into a flow. In this case, flows are created based on the subset of packets that were collected from the sampling instance. In other words, packet sampling occurs first and is optionally followed by flow aggregation.
Flow sampling takes a different approach. It starts with a selection of all packets and applies algorithms to merge them into flows, which results in a full collection of the original traffic (or parent population). Afterwards, flow entries in the cache are sampled either randomly or systematically, based on criteria such as largest flows, shortest flows, flow duration, and so on. In other words, aggregating packets into flows happens first, followed by flow sampling.
Even though packet and flow sampling are described separately, both techniques can be applied in conjunction. For example, you could sample packets first and then sample the aggregated flows afterwards to export only a subset of the total number of flows.
Deterministic Sampling
The first algorithm to examine is deterministic sampling, also known as periodic or systematic sampling. This sampling algorithm can be systematic count-based (for example, sample every 100th packet), systematic time-based (such as sample every 10 ms), or systematic size-based (select only packets whose length meets a certain criterion, such as 100 bytes).
These schemes are easy to implement and sufficient for applications such as performance management that require less accuracy than applications such as billing, which have high accuracy requirements. A valid concern related to the systematic approach is the dynamic nature of the traffic, which for a given confidence interval may result in inaccurate undersampling or excessive oversampling under changing traffic conditions. In general, the higher you sample, the better the results are, but there is no need for overachieving the confidence interval that you defined originally. Unfortunately, no mathematical model exists to describe deterministic sampling, which means that there is no mathematical proof that deterministic sampling is not biased. Empirical observations have shown that in high-speed network environments, the traffic is sufficiently mixed so that no repetitions of any kind exist. Consequently, there is no risk of biasing by always selecting the same type of traffic in the parent population, if by chance the sampling rate is a multiple of the traffic repetition rate. However, to be on the safe side, you should not select random sampling techniques for applications such as usage-based billing.
Deterministic Packet Sampling: 1 in N
Also known as periodic fix-interval sampling, it is a relatively simple count-based algorithm that allows the selection of one packet out of every N packets. You configure a value for N in the meter. Then you multiply the volume of the accounting records at the collection server by the same factor, N, to get the estimated total traffic volume. This is useful for network baselining and traffic analysis, even though the accuracy cannot be determined exactly and the results might be biased.
Example: N = 100
Result: sample packets 100, 200, 300, 400, 500, ...
Effective sampling rate: 1 percent
Note that NetFlow supports deterministic packet sampling, but it calls the feature "systematic packet sampling."
Note
For more details on Sampled NetFlow, refer to http://www.cisco.com/univercd/cc/td/doc/product/software/ios120/120newft/120limit/120s/120s11/12s_sanf.htm. xxx
The 1 in N packet sampling scheme can be extended to collect multiple adjacent packets at each collection interval. In this case, the interval length defines the total number of packets sampled per interval, while the trigger for the operation is still counter-based. Collecting a number of contiguous packets increases the probability of collecting more than one packet of a given flow. Two parameters define the operation:
The packet-interval parameter is the denominator of the ratio (1/N) of packets sampled. For instance, setting a packet interval of 100, one packet out of every 100 will be sampled.
The interval-length statement defines the number of samples following the initial trigger event, such as collecting the following three packets.
Example: packet-interval = 100, interval-length = 3
Result: sample packets 100, 101, 102, 200, 201, 202, 300, 301, 302, ...
Effective sampling rate: 3 percent
Deterministic Time-Based Packet Sampling
The schemes described so far use the packet position (also known as "spatial") as the trigger to start the sampling process. Alternatively, a trigger can be a clock or timer, which initiates the selection in time intervals, such as every 100 ms. The stop trigger can also be a timer function, such as one that collects all traffic during an interval of 5 ms. Because you cannot determine in advance how much traffic occurs at the meter during the measurement time interval, three situations are possible:
The accuracy of the child population matches the defined confidence interval; in this case, the sampling rate is correct.
The accuracy of the child population is lower than required, which means that additional samples would be necessary to match the confidence interval. Undersampling describes the situation in which not enough samples are available to offer the required accuracy.
The accuracy of the child population is higher than required, which means that more samples are selected than needed to match the confidence interval. Oversampling describes the situation in which a smaller number of samples still provides a correct result.
Figure 2-10 illustrates this effect. The solid bars represent required sampling, and the open bars show oversampling. Undersampling is illustrated by the encircled arrows.
Figure 2-10. Time-Based Packet Sampling: Oversampling Compared to Undersampling
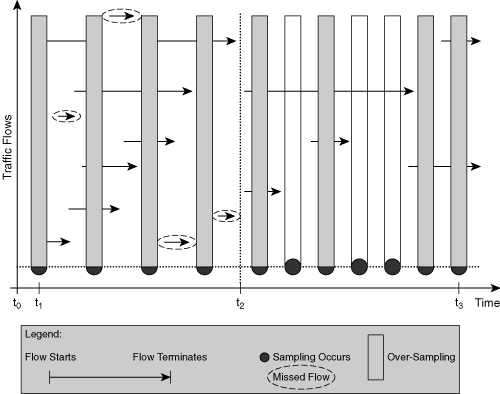
In the specific example of Figure 2-10, traffic is considered as flows or unidirectional conversations, which have a define start and stop time, and the goal is to identify the occurrence of each individual flow. Packets are collected at fixed time intervals, indicated by the bullets and vertical bar. Note that the figure explains a conceptual sampling scenario; it does not describe how packet sampling is implemented. For example, do not assume that four flows are captured in parallel.
During interval t1 – t2, undersampling occurs because not all flows are collected. The missed ones are encircled by the dotted lines. To solve this problem, you need to increase the sampling interval. In interval t2 – t3, oversampling takes place, and more traffic is collected than required to gather all flows (redundant sampling points marked with a pattern). In this case, you could decrease the sampling interval without loosing a flow. Best practice suggests that the selected sampling rate should be a compromise between these two extremes. To avoid empty collections and to gather at least a minimum number of samples, an alternative approach is to combine the time-based start trigger with a packet counter (N) or a content-based function. In that case, you start the collection every n ms but do not stop unless N packets are collected. Afterwards the meter idles for n seconds and starts again. Instead of collecting N packets in a row when the trigger starts, the meter can select those N packets by applying some random selection, or even by applying a filter to match certain traffic criteria.
In the example in Figure 2-10, it is possible to identify over- and undersampling and therefore define the "right" sampling interval. In reality, there is no perfect answer for how to derive an appropriate sampling rate from a given confidence interval, or how to compute an appropriate confidence interval for a given application. This makes it hard to identify the "right" sampling rate.
Deterministic Size-Based Sampling
A different deterministic approach is to collect packets or flows based on their size. From a monitoring perspective, you can be interested in analyzing the traffic's packet size to draw conclusions from the packet size for specific applications, such as security monitoring, or for general planning purposes.
Instead of reporting the exact size per packet, a simple aggregation approach is to define buckets of packet size at the device and aggregate packets into these buckets. This aggregation provides statistics about the packet size distribution but does not supply additional traffic details, such as source or destination. A benefit of this method is the simplicity, because only three collection buckets need to be implemented. Here's an example of the different packet size buckets:
Packet size < 64 bytes
Packet size between 64 and 200 bytes
Packet size between 201 and 500 bytes
Packet size between 501 and 1000 bytes
Packet size > 1000 bytes
The size-based sampling concept can also be applied to the size of a flow, which can be the total number of packets for a flow or the total number of bytes for a flow.
Previously, we defined a flow as an aggregation of packets with common key fields, such as source or destination IP address. The flow size is indeed a relevant indicator of communication characteristics in the network, as you will see in the following examples. A huge number of very small packets can indicate a security attack. Instant-messaging communication usually generates a constant number of small packets; the same applies for IP telephony. File transfer sessions use the maximum packet size and transmit a large volume in a short time period.
Note
An interesting article on the subject of Internet traffic is "Understanding Internet Traffic Streams: Dragonflies and Tortoises" by N. Brownlee and KC Claffy (http://www.caida.org/outreach/papers/2002/Dragonflies/cnit.pdf).
Size-based flow sampling works as follows: during time interval T, all packets are aggregated into flows. At the end of interval T, size-based flow sampling selects only flow records with a large volume for export, either in number of packets or in number of bytes. This method reduces the number of data sets exported from the meter to the collection server and trims the required processing cycles at the meter, because only a subset of entries from the cache are exported. Tables 2-17 and 2-18 describe size-based flow sampling. Both tables contain flow entries; the major difference is the sequence of the flow entries. Table 2-17 shows a flow table, where flows are added based on their creation time. Table 2-18 displays the same entries, but this time sorted by the flow size (number of packets). Consider a function that lets you select the Top-N entries, where you define a packet size threshold (such as number of packets) and export only those flows above the threshold. For Table 2-18, a threshold of 10,000 packets would result in exporting flow entry numbers 995 and 4.
| Flow Entry | IP Source Address | IP Destination Address | Packets | TOS | Source AS | Destination AS |
|---|---|---|---|---|---|---|
| 1 | 10.1.1.1 | 10.2.2.2 | 5327 | 160 | 13123 | 5617 |
| 2 | 1.2.3.4 | 1.1.1.1 | 294 | 176 | 13123 | 3320 |
| 3 | 10.61.96.101 | 171.69.2.78 | 15 | 0 | 0 | 5617 |
| 4 | 171.69.2.78 | 10.61.96.101 | 10382 | 0 | 13123 | 3215 |
| 5 | 144.254.71.181 | 10.1.1.3 | 816 | 13123 | 1668 | |
| ... | ||||||
| 995 | 10.2.1.5 | 10.64.30.123 | 290675 | 176 | 13123 | 7018 |
| 996 | 144.210.17.180 | 171.71.180.91 | 8410 | 0 | 21344 | 5617 |
| 997 | 10.1.1.1 | 10.2.2.2 | 481 | 160 | 13123 | 22909 |
| ... |
| Flow Entry | IP Source Address | IP Destination Address | Packets | TOS | Source AS | Destination AS |
|---|---|---|---|---|---|---|
| 995 | 10.2.1.5 | 10.64.30.123 | 290675 | 176 | 13123 | 7018 |
| 4 | 171.69.2.78 | 10.61.96.101 | 10382 | 0 | 13123 | 3215 |
| 996 | 144.210.17.180 | 171.71.180.91 | 8410 | 0 | 21344 | 5617 |
| 1 | 10.1.1.1 | 10.2.2.2 | 5327 | 160 | 13123 | 5617 |
| 5 | 144.254.71.181 | 10.1.1.3 | 816 | 13123 | 1668 | |
| 997 | 10.1.1.1 | 10.2.2.2 | 481 | 160 | 13123 | 22909 |
| 2 | 1.2.3.4 | 1.1.1.1 | 294 | 176 | 13123 | 3320 |
| 3 | 10.61.96.101 | 171.69.2.78 | 15 | 0 | 0 | 5617 |
Random Sampling
A valid concern of deterministic sampling is the potential biasing of the collection results. Related to sampling, the objective for the child population is to represent the parent population accurately. The term "random sampling" implies that for a finite quantity each member has the same chance of being selected. The random samples should be representative of the entire parent population. Algorithms that meet this requirement are also called pseudo-random-number generators. From a mathematical perspective, random sampling can be represented in a model, whereas deterministic sampling can only be investigated in an empirical manner. This is the main reason for the selection of random sampling versus deterministic sampling in all situations where determination of the accuracy is relevant.
Random Packet Sampling
In this sampling mode, an average of 1-out-of-N sequential packets are randomly selected for processing (where N is a user-configurable integer parameter), ultimately providing information on 100/N percent(s) of total traffic. The notation 1:N is used to describe sampling of 1-out-of-N packets. For example, if a random sampling of 1:100 is configured, the algorithm randomly selects one packet out of each 100 sequential packets, providing information on 1 percent of the total traffic. Figure 2-11 illustrates 1-out-of-N sampling with a sampling interval of N = 5, so a random selection of one packet within a set of five packets takes place. Cisco NetFlow implements random sampling; it is called Random Sampled NetFlow.
Figure 2-11. Random Packet Sampling: 1-out-of-N Sampling
Note
For more details on Random Sampled NetFlow, check http://www.cisco.com/en/US/products/sw/iosswrel/ps5207/products_feature_guide09186a00801a7618.html.
A modified version of the 1-out-of-N sampling is n-out-of-N mode. It is similar to random 1-out-of-N sampling just described, except this time, not just a single packet gets collected, but several packets. If you configure n = 100 and N = 10,000, you randomly sample 100 nonconsecutive packets at random positions within the 10,000 packets.
Random Flow Sampling
In contrast to random packet sampling, where the random factor applies to the packet selection, random flow sampling takes a different approach. The meter aggregates the observed traffic into flows, based on the defined key aggregation fields, such as source or destination address, port number, or device interface. This aggregation step can be applied to all packets, in case of a full collection, or can be applied after packet sampling. Random flow sampling is accomplished afterwards, where not all flows are exported, but only a subset of flows, based on the random factor. Instead of defining a random factor for packets, you define a factor for 1-out-of-N flows. Figure 2-12 illustrates the four steps of random flow sampling:
1. | Collect every packet or alternatively sample packets first. |
2. | Aggregate packets into flows, and create entries in the flow table. |
3. | Randomly select a number of flow entries from the table. |
4. | Export only the selected flow entries, and clear the table. |
Figure 2-12. Random Flow Sampling
Probabilistic Packet Sampling
Probabilistic sampling describes a method in which the likelihood of an element's selection is defined in advance. For example, if you toss a coin and select a packet if only the coin shows heads, the selection chance is 1 out of 2. If you cast a die and select a packet if one dot is displayed, chances are 1 out of 6 that a packet will get chosen. Probabilistic sampling can be further divided into a uniform and nonuniform version.
Uniform probabilistic sampling uses a random selection process, as described with the coin and dice examples, and is independent of the packet's content. An example of uniform probabilistic sampling addresses flow sampling: Most of the time you want to export the flows with a high volume because these are the most important ones. The solution is to export all large flow records with a high probability, while the small flow records are exported with a low probability, such as proportional to the flow record volume.
Nonuniform probabilistic sampling does not use a random function for packet selection; instead, it uses function based on the packet position or packet content. The idea behind it is to weight the sampling probabilities to increase the likelihood of collecting rare but relevant packets. Imagine that you want to select routing protocol updates to identify changes to the paths in your network. Compared to user traffic, these packets represent a minority of the total traffic but are important to meet your objective.
Stratified Sampling
For the sake of completeness, the theoretical aspects of stratified sampling are highlighted next. Stratified sampling takes the variations of the parent population into account and applies a grouping function before applying sampling. Stratification is the method of grouping members from the parent population with common criteria into homogeneous subgroups first; these groups are called strata. The benefit is that a lower sampling rate per strata is sufficient to achieve the same level of accuracy. For example, if a sampling rate of 1 out 10 is required to achieve a certain confidence interval, after grouping by strata, the same goal could be achieved by a sampling rate of 1 out of 20. The key to successful stratification is to find a criterion that will return a stratification gain.
Two requirements are relevant for the selection process:
Comprehensiveness— Every element gets selected; none can be excluded.
Mutual exclusiveness— Every element has to be assigned to exactly one group (stratum).
Referring to Figure 2-7, child populations A, B, C, and D are taken from the parent population and are grouped according to their characteristics. After the packets are grouped, sampling techniques are performed on each stratum individually, which means that different sampling algorithms can be applied in parallel. Stratification also achieves the same confidence interval with a lower sampling rate.
A practical illustration is first to classify traffic per application (such as HTTP, FTP, Telnet, peer-to-peer, and management traffic) and then sample per group (stratum). This method is useful to correct the allocation of variances in the parent population.
For example, the volume of web-based traffic on a link is 10 times the amount of Telnet traffic. Assuming that you want to sample packets, the child population should contain the same volume of HTTP and Telnet packets, possibly for packet content analysis. If you apply sampling across the mixed traffic, a higher sampling rate is required to select enough Telnet packets, due to their small occurrence, while a lower sampling rate would be sufficient for HTTP. If you group (stratify) the traffic first into a stratum of HTTP packets and then into a stratum of Telnet packets, the same sampling rate can be applied to both groups.
Filtering at the Network Element
Filtering is another method to reduce the number of collection records at the meter. Filters are deterministic operations performed on the packet content, such as match/mask to identify packets for collection. This implies that the packet selection is never based on a criterion such as packet position (time or sequence) or a random process in the first place.
Three steps are applied for filtering. As the first step, you define "interesting" packets, which are the selection criterion for the collection process. One example is to filter packets based on selected IP or MPLS fields; another example is filtering based on the packet's QoS parameters. A final example is the matching of IPv4 and IPv6 header types that provide the operator with adequate information during the transition phase from IPv4 to IPv6. A practical implementation for selecting packets is the use of Access Control List (ACL) match statements. Step 2 selects either full packet collection or sampling operations. Step 3 exports packets immediately or aggregates them into flows before exporting. Figure 2-13 shows the various alternatives and combinations of filtering and sampling.
Figure 2-13. Packet Selection Options
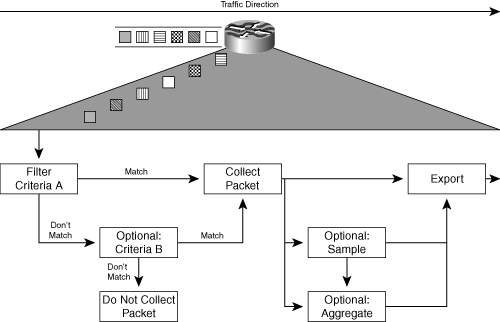
The combination of filtering and sampling is a very efficient approach to dealing with the increasing traffic volume in the networks. Instead of choosing between full collection and sampling, you can apply the preferred methodology based on traffic types. If a network already has service classes defined, these classes can act as the traffic distinguisher for collecting accounting and performance data records. Figure 2-14 shows three different traffic classes:
Priority traffic— A network operator requires detailed accounting records from the priority traffic for billing purposes, so a full collection is configured.
Business traffic— Business traffic needs to be monitored closely to validate SLAs, but it is not charged, so a sampling rate of 100 is acceptable.
Best-effort traffic— The best-effort traffic class is provided without any SLA; therefore, a basic collection with a sampling rate of 1000 is adequate.
Figure 2-14. Combining Filtering and Sampling
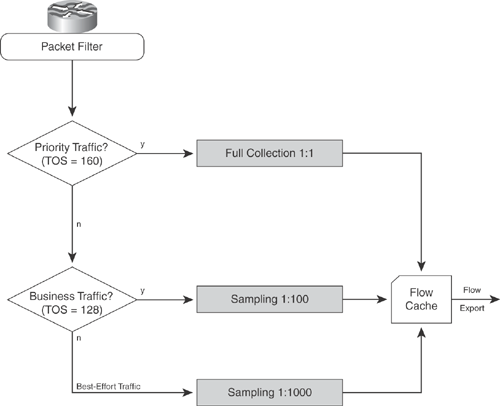
These requirements can be fulfilled by deploying a combination of filtering and sampling.
A sophisticated design is to continuously collect all packets under normal circumstances and apply sampling and filtering during "special" situations, such as very high utilization or security attacks. During a DoS attack, it is critical to collect detailed traces of the specific portion of the traffic that is related to the attack, such as if a significant fraction of the traffic has the same destination address.
Note that NetFlow supports input filtering mechanisms, under the name "input filters."
Filters described so far take actions on the packet content. An alternative are filters based on the router's state. For instance, a violated ACL can trigger a collection of flows for a security analysis. Alternatively, traffic that matches a certain BGP AS number or range of AS numbers can be metered, while traffic from other AS numbers is not metered.
Active Monitoring Concepts
Whereas passive collection methods are based on the concept of not affecting the live traffic on the network, active monitoring applies the exact opposite paradigm. Specific synthetic traffic is generated and the results are collected to indirectly measure the performance of a device, the network, or a service. This section describes how to generate and meter synthetic traffic.
Certain conditions are to be met when actively measuring the network and creating test traffic:
The characteristics of the user traffic must be represented, such as packet size and QoS parameters.
The ratio of test traffic compared to the total capacity is required to be relatively low. Best practices suggest a maximum of 1 percent test traffic compared to production traffic.
Test traffic must not be blocked by security instances, such as ACLs, firewalls, or proxies.
Devices must treat the test traffic exactly like any other traffic (for example, a router must not process test traffic in s&







