Data Collection Details: What to Collect
This chapter defines the data collection methodology by asking those questions that are relevant for accounting or performance management projects:
What type of information to collect?
What level of detail is required in the data records?
How to meter the data records (metering is the process of collecting and optionally preprocessing usage data records at devices)?
Where to collect the data records?
How to collect the data records?
How to process the data records?
How to ensure data authenticity and integrity?
This chapter addresses all the questions you should ask yourself throughout your project's evolution. The methodology explained in this chapter is well suited for both performance and accounting projects. More proof, if more is needed, is that the A and P in the acronym FCAPS (Fault, Configuration, Accounting, Performance, and Security) are closely related. Every accounting and/or performance project requires an answer to the what, who, how, and where questions. This chapter helps you answer all the questions, one by one, almost like a checklist.
Chapter 1, "Understanding the Need for Accounting and Performance Management," described the different applications in the accounting and performance management domains. Some distinguishers helped categorize accounting versus performance applications; however, a clear overlap exists between the two domains! Start classifying your project per application type: Are you solving a network monitoring issue, a capacity planning issue, a security issue, or a network performance issue? The answer is important, even if the questions in this chapter are almost identical for all applications types, because based on the application type you can already deduce a couple of answers.
This chapter sets up the theoretical foundations for the rest of the book. For the sake of clarity, a few references to the capabilities of the different Cisco accounting and performance features (SNMP, RMON, NetFlow, IP SLA, BGP Policy Accounting, and so on) illustrate the theory.
However, the goal of this chapter is not to delve into the technical specifications of the Cisco accounting and performance features. The next chapters cover each feature in detail.
When starting a project, the temptation is to try to solve all the problems at once. For example, while collecting some generic accounting records for capacity planning, why not try to reuse the information for security and billing purposes. Or why not try to augment the capacity planning records with some extra billing and security information? Although this is a legitimate goal, it is better to divide and conquer. The methodology, or list of questions described in this chapter, should be answered for each application type, at least with the first four questions:
What to collect?
Who is the user?
How to meter?
Where to collect?
As a second step, you analyze the common denominator(s) between the different application requirements. Can you meter the traffic so that the data records contain the types of data for all the application types? Can you centralize the collection for all the application types? After a trade-off analysis, a single accounting mechanism can potentially collect all the required information. However, at first glance, this is not obvious.
Finally, after you've answered the questions in the checklist, the answers will help you discover the required accounting and/or performance mechanisms adapted to your project. They will point you to one or two accounting features. The next chapters cover the technical details of these features. After a technical comparison, you can select and implement the most appropriate feature.
The Multi-Router Traffic Grapher (MRTG) and Round-Robin Database (RRDtool) are freely available tools under the terms of the GNU General Public License. MRTG, widely used throughout the industry, monitors and graphs the evolution of SNMP MIB variables and displays the traffic load on network links and devices. MRTG generates HTML pages containing graphical images that provide a near-real-time visual representation of this traffic. The RRDtool, considered a reimplementation of MRTG's graphing and logging features, stores the data in a very compact way and presents useful graphs after processing the data.
Figure 2-1 shows a typical monitoring graph generated with the RRDtool. This particular graph displays the bit rates received on and transmitted out of one interface, respectively using the ifInOctets and ifOutOctets MIB variables from the interfaces group MIB (RFC 2863).
Figure 2-1. Interface Counter Collection with MRTG

The most basic function of performance management is the collection of the interface utilization. Even if the interpretation of the results is useful for some link capacity planning, and if the graph visualization helps during troubleshooting, the usability is still limited. No traffic classification is possible, the link view limitation applies as opposed to a network-wide view, the image is updated every 5 minutes, and so on.
At the other extreme of the accounting granularity, the Cisco NetFlow solution analyzes the packets received on an interface to classify them into flows and then exports the flow records to a NetFlow collector. Flows consist of packets related to each other—for example, because they belong to an exclusive data session between a client and a server.
NetFlow version 9 defines a flow in RFC 3954, Cisco Systems NetFlow Services Export Version 9:
"An IP Flow, also called a Flow, is defined as a set of IP packets passing an Observation Point in the network during a certain time interval. All packets that belong to a particular Flow have a set of common properties derived from the data contained in the packet and from the packet treatment at the Observation Point."
Packet accounting, as opposed to flow accounting, refers to individual packets, without identifying a relationship between each other. An aggregation is a whole-part relationship, where individual components form a larger whole. A flow is always an aggregation, even though you can define an almost unlimited number of aggregation schemes. Aggregation scheme examples are the combination of all packets with the same criteria:
IP address (source and/or destination)
Layer 4 port number (source or destination)
Type of service field (ToS, DSCP)
BGP Autonomous System number (source and/or destination)
Figure 2-2 shows the details of the NetFlow version 5 flow records. The goal here is not to explain NetFlow in depth, because that is covered in Chapter 7, "NetFlow." Instead, you'll see what level of detail you can potentially collect in terms of types of data. Note that the Remote Monitoring (RMON) MIB, which offers a level of detail almost similar to NetFlow (IP addresses, application port number, and so on), is also a very detailed accounting feature.
Figure 2-2. NetFlow Version 5 Flow Export Format

The question of what to collect? finally translates into "Which types of data are required for my project?" Do you need only some MIB interface counters? Alternatively, do you need to export NetFlow records for very detailed accounting reports? In most cases, the answer is between these two extremes. After you understand the principles of accounting and performance management (see Chapter 1), what to collect? is the next question. This question is not as simple as it seems! The answer depends on the translation from the problem space into a detailed technical analysis of the problem. The best way to proceed is to take an empty sheet of paper and draw the report you want. The column titles of your report are the most important information. Assume that your report requires the notions of user, application, volume, and time. For now, keep the generic names. In this chapter you will discover which types of data are required. For example, the user can be represented by a MAC address, an IP address, a subnet, a virtual private network (VPN), an interface index, and so on.
While sketching your report, you will quickly conclude that you need to break down the task into several subquestions about what to collect:
What are the keys?
What are the values?
What are the required versus nice-to-have types of data?
What Are the Keys?
The key is a data field that creates a unique entry in the report. The keys define the granularity of the classification: the more keys, the better the level of detail. For example, if you want to monitor the volume per interface, the report needs to contain the interface as a key. On top of that, if you want to monitor the application types in the network, the report also needs to contain the application's destination port as a key. Furthermore, if you want to monitor the top talkers in the network, you require two extra keys: one for the source and one for the destination address. However, ensure that the addition of flow keys does not come at the cost of resource consumption, as discussed in the section "What Are the Required Versus Nice-to-Have Types of Data?"
Cisco NetFlow services use a combination of different types of data as keys to define a flow:
IP source address
IP destination address
Source port
Destination port
Protocol field
ToS field
Input or output (sub)interface
Multiprotocol Label Switching (MPLS) label
Other criteria
Note
The first seven data types in the list are the default key for NetFlow.
What Are the Values?
The value does not create a unique entry in the report, as a key would do. Instead, it augments the record with extra information. Volume is a typical example, expressed in number of bytes and/or number of packets. Other potential useful values are the observed time of the record, round-trip time (RTT), jitter, and so on.
The distinction between values and keys is comprehensible for some types of data, such as volume, which is always a value. However, for some types of data, the key or value selection depends on whether the type of data content is constant in the predefined report. If you collect a certain type of data as a key, does the content remain the same across all entries? It also depends on whether you want the flexibility to report on those different instances, assuming that the type of data content differs in the predefined classification.
The following sections provide some examples for distiguishing keys and values.
Value Versus Key Example: DiffServ Code Point
In this example, the question is "Should the DiffServ Code Point (DSCP) type of data be classified as a value or a key?"
If all incoming traffic contains the same DSCP, or if the incoming traffic contains different DSCPs but you want to report only one value of it (for example, the DSCP's first observed value), you need a report like the one shown in Table 2-1.
| Number of Packets (Value) | Ingress DSCP (Value) |
|---|---|
| 100 | 1 |
Alternatively, if you want to monitor the different ingress DSCPs of the packets arriving at the network element, define the ingress DSCP as a key. Table 2-2 shows an example with two DSCP values: 1 and 2.
| Number of Packets (Value) | Ingress DSCP (Key) |
|---|---|
| 50 | 1 |
| 50 | 2 |
If the network element executes recoloring—that is, if the network element rewrites the egress DSCP—you would potentially want to report the egress DSCP. Whether the egress DSCP is a key or a value in that case depends on the context.
If there is one-to-one matching between the ingress DSCP traffic and the egress DSCP traffic, and if the ingress DSCP value is already a key, you might report the egress DSCP as a value. Table 2-3 shows an example of all ingress traffic with a DSCP value of 1 recolored to 2 and all ingress traffic with a DSCP value of 2 recolored to 3 at the egress interface.
| Number of Packets (Value) | Ingress DSCP (Key) | Egress DSCP (Value) |
|---|---|---|
| 50 | 1 | 2 |
| 50 | 2 | 3 |
If you want to monitor all data records with the different instances of ingress and egress DSCPs, specify both the ingress and egress DSCP as keys. Table 2-4 shows the type of report to expect in case of two DSCP instances.
| Number of Packets (Value) | Ingress DSCP (Key) | Egress DSCP (Key) |
|---|---|---|
| 25 | 1 | 1 |
| 25 | 1 | 2 |
| 25 | 2 | 1 |
| 25 | 2 | 2 |
If you want to distinguish your data records per application, you need the application as a type of data in your report. Should you request the application type to be a key or a value in this case? Again, it depends. If DSCP characterizes the application type, the application is a value. Table 2-5 shows an example of a report in which all VPN traffic has an ingress DSCP setting of 2, and all FTP traffic has an ingress DSCP setting of 1.
| Number of Packets (Value) | Ingress DSCP (Key) | Application Type (Value) |
|---|---|---|
| 50 | 1 | FTP |
| 50 | 2 | VPN |
Alternatively, if different Classes of Service (CoS) are defined in the network, even for the same application type, reporting the DSCP as a key allows the breakdown of application per CoS.
Table 2-6 shows the example of a report in which VPN traffic contains an ingress DSCP setting of 2 or 3 and FTP traffic contains an ingress DSCP setting of 1 or 2.
| Number of Packets (Value) | Ingress DSCP (Key) | Application (Key) |
|---|---|---|
| 25 | 1 | FTP |
| 25 | 2 | FTP |
| 25 | 2 | VPN |
| 25 | 3 | VPN |
Value Versus Key Example: BGP Autonomous System Path
If you want to report the BGP autonomous systems (AS) to which your network traffic is destined, you define the BGP destination AS as a key. On top of that, you might want to add the BGP AS path taken to reach the final destination. In that case, you define the AS path as a value in your record. For a dual-homed network, which connects to two different service providers, you can distinguish the traffic sent via one ISP versus the traffic sent to the other: the solution is to specify the AS path as a key. In that case, two distinct data records are created if the AS path is different, even if all the other parameters of the data record are similar.
The network shown in Figure 2-3 serves as the basis of the examples. The traffic goes from AS1 to AS2 and AS3, and the router in AS1 is the point of observation. Table 2-7 displays the different data record possibilities when the AS path is a value, and Table 2-8 reports the AS path as a key. Note that two different AS paths are possible when the AS path is a value (see Table 2-7). The selection depends on the metering process. The AS path reported is the value of either the first or last metered traffic. In both cases, the metering process reports only one value.
Figure 2-3. BGP Autonomous System Path

| Destination AS DSCP (Key) | AS Path (Value) | Volume (Value) |
|---|---|---|
| AS2 | AS1-AS2 | 100 |
| AS3 | AS1-AS4-AS3 or AS1-AS5-AS3 | 100 |
| Destination AS DSCP (Key) | AS Path (Key) | Volume (Value) |
|---|---|---|
| AS2 | AS1-AS2 | 100 |
| AS3 | AS1-AS4-AS3 | 50 |
| AS3 | AS1-AS5-AS3 | 50 |
What Are the Required Versus Nice-to-Have Types of Data?
The accounting application types described and classified in Chapter 1 require some volume estimation, such as number of bytes or number of packets. However, only one type of data is sufficient in most cases—either packets or bytes. For example, most billing applications express the volume in terms of bytes, not packets. It might be nice for a billing application to report the number of packets, which is the point of this section. You need to clearly draw the line between "required" and "nice-to-have" types of data. In the billing example, the volume in bytes is required, because the user pays proportionally to the volume, whereas the number of packets is a nice-to-have parameter. On the other hand, a security application requires the volume in both bytes and packets. The ratio of packets to bytes gives useful hints about types of attacks: an attack composed of many small packets to block a server (typically a SYN flood attack), or an attack composed of huge packets to saturate a link.
Within the nice-to-have types of data, you should clearly differentiate the values and the keys, because the implications are different. Maintaining a value such as the number of packets in a flow, on top of the number of bytes, is an easy task for the network element as well as for the network management systems. However, if an additional nice-to-have key is added, the consequences might be significant:
Increased CPU on the network element as more data records are classified and processed
Memory impact on the network element as more data records are maintained
Higher bandwidth requirements between the network element and the management system to transfer the data records
More data records processed and maintained by the network management system
Keys define the granularity of the collection: the more keys, the greater the level of detail, at the price of additional resource consumption.
Data Types List
All types of data relate to the notion of device, network, or service. The types of data are any keys that classify the traffic in a report, or any values that augment the data record.
Therefore, there is not a complete list of types of data. However, several categories of types of data exist:
Packet header fields— The types of data, as defined in NetFlow services: source IP address, destination IP address, source TCP/UDP port, destination TCP/UDP port, DSCP, input interface, and so on. You can extend this definition to any additional header parameters of other protocols. For example, a monitoring application might want to observe the traffic per Frame Relay Data Link Connection Identifier (DLCI), per ATM Permanent Virtual Circuit (PVC), or per Data Link Switching (DLSw) circuit, and so on.
Characteristics of the packet itself— For example, the number of MPLS labels in the stack, the interpacket delay in case of active measurement, the packet length, the number of unicast IP addresses versus multicast IP addresses versus broadcast IP addresses, and so on.
Fields derived from packet treatment at the device— For example, the Interior Gateway Protocol (IGP) or BGP next hop, the output interface, the one-way delay, the round-trip delay, the flow packet loss, the flow jitter, and so on.
As a final note on the types of data, you see that these three categories combine fields from both passive monitoring and active probing. The answer to what to collect does not require this distinction! The section "Metering Methods: How to Collect Data Records" compares the arguments in favor of active probing and passive monitoring.
Example: Application Monitoring
Considering what to collect requires a fresh start on an empty sheet of paper. Your next task is to fill in the columns of what to report. The generic term "application type" will certainly be a column title, along with "volume of traffic." Even though "what to collect for application monitoring" is the right question, a different formulation of the same question will help. That is, "How are the application types differentiated in the network?"
The Internet Assigned Numbers Authority (IANA) provides the answer to the question about the IP protocol number, as shown in Table 2-9.
| Protocol # | Keyword | Protocol | Reference |
|---|---|---|---|
| 1 | ICMP | Internet Control Message Protocol | RFC 792 |
| 2 | IGMP | Internet Group Management Protocol | RFC 1112 |
| 6 | TCP | Transmission Control Protocol | RFC 793 |
| 17 | UDP | User Datagram Protocol | RFC 768 |
| ... |
However, it is not enough to classify the traffic by the protocol type, because the application port numbers also differentiate the application types: the well-known port numbers (0 to 1023), the IANA registered port numbers (1024 to 49151), or the dynamic and/or private ports (49152 to 65535). In addition to the IP protocol, another flow key is required: the application port number.
The well-known ports, shown in Table 2-10, are assigned by the IANA. On most systems, they can be used only by system (or root) processes or by programs executed by privileged users. The registered ports are listed by the IANA. On most systems they can be used by ordinary user processes or programs executed by ordinary users. The IANA registers these ports as a convenience to the community.
| Port # Transport Protocol | Keyword | Protocol | Reference |
|---|---|---|---|
| 20/tcp | FTP-data | File transfer | RFC 414 |
| 20/udp | FTP-data | File transfer | RFC 414 |
| 21/tcp | FTP-control | File transfer | RFC 414 |
| 21/udp | FTP-control | File transfer | RFC 414 |
| 23/tcp | telnet | Telnet | RFC 854 |
| 23/udp | telnet | Telnet | RFC 854 |
| 80/tcp | http | World Wide Web | RFC 2616 |
| 80/udp | http | World Wide Web | RFC 2616 |
| ... |
Some applications use dynamic and/or private port numbers, negotiated during connection establishment. Stateful inspection is required for classification of such applications. Stateful inspection, also known as dynamic packet filtering, is the ability to discover data connections and examine the header information plus the packet's contents up to the application layer. A simple approach to identifying such applications can be applied if there is a finite number of associated source or destination addresses in the network. The Cisco Unified Messaging application (Unity) is an example in this case. It uses dynamic ports, but as there are usually only a few Unity servers on the network—in this special case—they can be identified by their IP address.
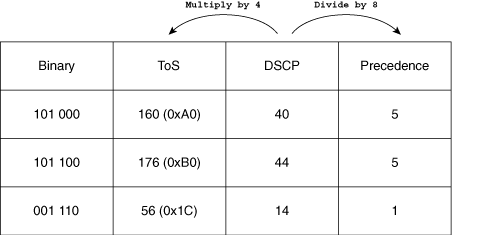
In another situation it can be sufficient to just use the CoS classification as a flow key. If applications are identified by CoS, you can use the 3 precedence bits (from P0 to P2 in Figure 2-4), the 6 DSCP bits (from D0 to D5 in Figure 2-4), or the 4 ToS bits (from T0 to T3 in Figure 2-4), depending on your CoS configuration in the network. Examples such as voice and videoconferencing (IPVC) are identifiable via the ToS value. Figure 2-4 shows the relationship between the three types of data, and Figure 2-5 shows the conversion mechanism between the three types of data.
Figure 2-4. Relationship Between the Precedence, ToS, and DSCP Bits
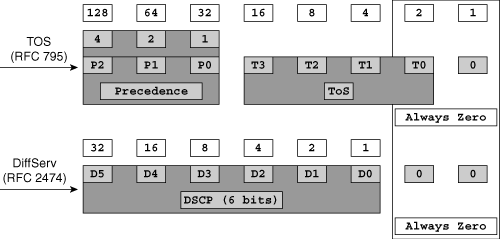
Figure 2-5. Conversion Mechanism Between the ToS, Precedence, and DSCP Bits
The destination IP address, used as a key, may classify additional application types. For example, by looking at the traffic with a multicast IP address, you classify the video traffic in your network (assuming that the only multicast traffic in your network is video). Another example is to monitor all traffic destined for the Domain Name System (DNS) server, which lets you quantify the volume of DNS traffic.
In some cases where you cannot distinguish the application by any of the keys already discussed, you might need deeper packet inspection. The subport classification is also a potential flow key for application type distinction. For example:
HTTP— Uniform Resource Locator (URL) with a specific file.
Multipurpose Internet Mail Extension (MIME)— MIME extends the format of Internet mail to allow non-US-ASCII text messages, nontext messages, multipart message bodies, and non-US-ASCII information in message headers. Note that MIME types are also used in HTTP to mark different types of web documents.
Citrix applications— Traffic based on published application names.
The Cisco Network-Based Application Recognition (NBAR) feature provides deeper packet inspection capabilities.
As a summary of the different flow keys available to distinguish the application type, Table 2-11 shows some typical applications and describes the ways to identify them.
| Application/Protocol | Identification |
|---|---|
| VoIP | UDP TOS = 5 |
| IP Video Conferencing | TOS = 4 |
| H323 | TCP port = 1719, 1720 and TOS = 3 |
| Multicast | Class D address |
For the traffic volume, you need to decide which type of data is most appropriate, unless you choose to keep both the number of bytes and the number of packets.
The notion of volume implies the notion of time granularity. Do you require a report every half hour or every hour? As a result, the collection server has records with a 30-minute or 60-minute granularity, and the volume of identical flow records is cumulated over the selected time interval. An alternate option is for each data record to contain time information, which implies that each data record must contain the absolute time of its metering. Note that, depending on the metering procedure, a data record may contain two absolute timestamps: one for the data record start, and one for the data record end.
As the conclusion of this example, you have to determine the generic terms of your defined report (such as application, volume, time), and the specific types of data required. Throughout this example, you have answered the question "How can you classify the different applications in your network?"
Example: Traffic Matrix
You learned in Chapter 1 introduced the core traffic matrix, a table that provides the traffic volumes between origin and destination in a network, which is useful for network-wide capacity planning and traffic engineering.
What are the keys and values to generate a core traffic matrix similar to Table 1-5? The report contains the entry point, the exit point, and the volume in bytes. The entry and exit points are keys, and the bytes number is a value, as shown in Table 2-12.
| Entry Point (Key) | Exit Point (Key) | Bytes Number (Value) |
|---|---|---|
| Rome | Paris | X |
| Rome | Munich | Y |
| London | Munich | Z |
| ... |
You can classify the entry point by
A router— The key is then the router from which the data records are retrieved.
A Point of Presence (PoP)— The key is a group of routers from which the data records are retrieved, because a PoP is composed of several routers.
A router's interface— The key is the interface index (ifIndex).
The exit point classification depends on the routing protocol running in the network:
If the core network runs MPLS, the Forwarding Equivalent Class (FEC) associated with the top label classifies the core's exit point.
If the core network is a pure IP network, the BGP next hop classifies the core's exit point.
Chapter 1 also explained that the external traffic matrix is useful to look at the influence of the BGP peering selection for your network-wide capacity planning.
The external traffic matrix, such as the core traffic matrix, offers the traffic volumes between the source and destination in the network. However, the external traffic matrix contains more details, because it augments the core traffic matrix with the source and destination ISPs information.
To generate an external traffic matrix similar to Table 1-5, you declare the entry and exit points as keys, the source and destination ISPs as other keys, and the volume in bytes as a value, as shown in Table 2-13.
| Entry Point (Key) | Exit Point (Key) | Source ISP (Key) | Destination ISP (Key) | Bytes Number (Value) |
|---|---|---|---|---|
| Rome | Paris | ISP-A | ISP-1 | X |
| Rome | Paris | ISP-A | ISP-2 | Y |
| Rome | Paris | ISP-B | ISP-1 | Z |
| ... |
You can classify the destination ISPs by
The AS of your BGP next hop— The next AS in the AS path, or, in other words, the BGP AS of your neighbor
The destination BGP AS— The last item of the AS path.
Equivalent logic would apply to the source ISP.
Example: SLA Monitoring
A typical ISP Service Level Agreement (SLA) contains the maximum values of the round-trip time, the packet loss, and the jitter across the network, as shown in Table 1-8. Those maximum values depend on the level of services. The three characteristics of the traffic are defined as values. What is/are the key(s), then? The measurement points in the network define the keys. Even if a table such as Table 1-8 will never show the measurement points, the ISP has to define the report shown in Table 2-14. The key will then be a specific router in a PoP, a dedicated router to perform the IP SLA operations in a PoP (also called a shadow router), customer premises equipment, and so on. Curiously, the measurement points are often "forgotten" in SLA marketing messages; however, they are essential to determine how the ISP meters its SLAs.
| Measurement Point (Key) | Round-Trip Time (Value) | Packet Loss (Value) | Jitter (Value) |
|---|---|---|---|
| router-1 | 50 ms | 0 | 1 ms |
| ... | ... | ... | ... |
From a conceptual point of view, reporting the ISP's possible SLAs or reporting the VoIP call quality via active probing are two scenarios that would need exactly the same keys and values. The only difference is in the definition of the measurement point, where VoIP monitoring would impose the measurement point to be an IP phone, the network element (potentially the one to which the IP phone is connected), a passive measurement device in the network, or the VoIP telephony server.







