3.1 Application Domains Explained
To ensure application and operating system security and stability, it is necessary to isolate concurrently executing applications from each other. Application isolation ensures that one application cannot purposefully or inadvertently modify the memory, or access the resources owned by another. Traditionally, operating systems isolate applications by running each application in its own process, and providing each process with its own virtual memory space and resource handles. Memory references are associated with a single process, and therefore code cannot obtain a reference that affects the memory of another process. Code cannot access objects in other processes directly and must use some intermediate communications mechanism, such as a remote procedure call or a proxy in order to invoke methods.
3.1.1 Application Isolation in the .NET Framework
Application isolation in the .NET Framework is very different from traditional application environments. Before the CLR loads an assembly, it verifies that the assembly contains only type-safe code. Type safety guarantees that the code does not perform illegal operations, access memory directly, or try to access type members incorrectly. If an assembly fails the verification process, the CLR will refuse to load it and will throw an exception. We discuss the verification of assemblies further in Chapter 4.
Loading Non-Type-Safe CodeIt is possible to load non-type-safe code into the CLR; however, that undermines the application isolation and security mechanisms provided by the CLR. Because every assembly is running in a single process, code that directly manipulates the memory of the containing process does not only modify the memory used by other application assemblies, but it can also modify the memory used by the CLR and the .NET class library. A piece of poorly written software could accidentally overwrite blocks of memory used by other applications. Even worse, a well-written piece of malicious code could use pointers to change data critical to the operation of the CLR. Only highly trusted code from a verifiable source should be granted the permission to load non-type-safe code and only when specific needs demand. We will discuss this more in Chapter 7, when we talk about code-access security permissions. |
The fact that code is type-safe allows the CLR to load many assemblies into the same operating system process without the risk of those assemblies crashing or corrupting each other. This solves many code stability issues and enables the CLR to use application domainsa lightweight alternative to processesto ensure application isolation. Application domains are logical containers within the CLR that provide an isolation boundary between type-safe assemblies equivalent to that provided by processes for native applications.
|

The relationship between a process, the CLR, application domains, and assemblies is illustrated in Figure 3-1. Three assemblies have been loaded into the first application domain and one assembly into the second. As yet, no assemblies have been loaded into the third application domain.
Figure 3-1. The relationship between a process, the CLR, application domains, and assemblies
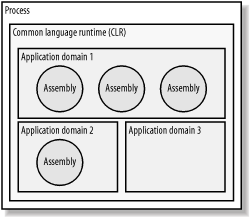
By isolating at the assembly level, .NET provides a fine-grained level of control over the isolation of your applications. Not only can you isolate entire applications from each other, but you can also isolate individual parts (assemblies) from the rest of your application. This is particularly useful if your application provides for extensibility using plug-ins or dynamically loadable modules that are of questionable quality, origin, or intent (for example, Internet Explorer, which allows .NET controls to be downloaded and run from web sites).
3.1.2 Application Domain and Assembly Management
The CLR provides an execution environment for managed code, but a runtime hostat least written partially in native codeis required to load the CLR before it can execute your managed code. When the CLR is loaded, it automatically creates a default application domain. However, the runtime host usually determines when and if additional application domains are created. Runtime hosts are free to use different application domain strategies to suit their application execution model and security requirements. Although it is possible to create custom runtime hosts, the three you will encounter most frequently are those supplied with the .NET Framework:
The ASP.NET runtime uses a single CLR that runs all ASP.NET web applications; each web application is loaded into a separate application domain.
Internet Explorer uses a single CLR that executes all downloaded controls. An application domain is created for each web site from which controls are downloaded; all controls from the same site run in a single application domain.
The CLR used to execute commands run from the operating system shell creates a single application domain that the executable assembly and all referenced assemblies are loaded to.
When the CLR loads an assembly, it usually loads it to the same application domain as the code that referenced it. As mentioned, the runtime host may create a separate application domain in which to load the assembly. It is also possible for application code with the appropriate permissions to create application domains and to load assemblies into those application domains. This allows application code to take direct control of isolating specific assemblies, and provides a mechanism through which code can unload assemblies. It is not possible to unload an individual assembly once it is loaded; however, it is possible to unload an entire application domain, which unloads all the assemblies loaded in to it.
3.1.3 Assembly Isolation with Application Domains
Code loaded into one application domain has no direct access to code loaded into other application domains. While it is possible for code to enumerate the assemblies and types loaded into its own application domain, instantiate those types, and invoke object methods, it is not possible for code to perform these actions in a remote application domain without first obtaining a reference to the remote domain. Only the creator of an application domain or code running in an application domain can obtain a reference to a domain; it is not possible for managed code to enumerate the application domains that exist in the CLR. Because all code is type-safe and guaranteed not to perform direct memory access, it cannot break through this isolation to access directly the code or data of an assembly in another application domain, even though they are loaded in the same process.
|
3.1.4 Application Domains and Runtime Security
Application domains play a key role in the operation and enforcement of runtime security. Runtime security is a large and complex topic, which we explore fully in Part II of this book. In the following sections, we provide a summary of the relationship between application domains and each aspect of runtime security.
3.1.4.1 Assembly evidence and identity
When you load an assembly into an application domain, you can specify additional evidence to apply to the assembly. The CLR uses evidence to determine an identity for an assembly, from which it determines the permissions to grant to the assembly. The permissions granted to an assembly control the actions and resources that are accessible to the code contained in the assembly. By changing an assembly's evidence, you change its identity, which can radically change the permissions granted to it by the CLR. We demonstrate how to modify the evidence of an assembly in Chapter 6.
3.1.4.2 Application domain evidence and identity
When you create an application domain, you can assign evidence to it. As with assemblies, evidence gives application domains an identity from which the CLR derives a set of permissions. When code tries to perform a protected operation, the CLR checks not only the permissions granted to the assembly in which the code is contained, but also the application domain in which the code is running. There is more to this process, but the key point to remember is that the permission of an application domain restricts the capabilities of the code running in it. This is a powerful feature, especially when loading and executing code from untrusted sources. We discuss how to assign evidence to application domains in Chapter 6, and describe the effect an application domain's permissions have on the code in Chapter 8.
3.1.4.3 Application domains and security policy
The CLR uses a set of configurable rules (security policy) to provide a mapping between an assembly's evidence and the set of permissions granted to it when it is loaded. Security policy is divided into four layers, or policy levels: enterprise, machine, user, and application domain. Each layer is evaluated in order from highest (enterprise) to lowest (application domain), with each layer further restricting the permissions that are granted by the previous layer; lower layers are never able to grant more permissions than those granted by higher layers. The highest three layers (enterprise, machine, and user) are statically configured using administrative tools and stored in configuration files. Application domain policy is defined programmatically, allowing you to set security policy at runtime instead of relying on statically defined security policy only. We discuss application domain security policy in Chapter 8.
3.1.4.4 Role-based security
Although code-access security solves many of the long-standing security issues surrounding the use of mobile code, it does not remove the need for the more familiar role-based security mechanisms. The .NET framework also contains support for role-based security. When code attempts to perform actions, it does so in the context of a principal. A principal represents the identity of the active user and any roles (user groups) to which the user belongs. By default, the application domain through which a thread runs defines the principal on whose behalf the thread acts. We discuss role-based security in Chapter 10.
3.1.4.5 Application domains and isolated storage
.NET provides a facility named isolated storage, which provides a managed storage area for .NET applications to write user and application state information. Isolated storage provides a relatively safe area where applications can write data without being granted access to important resources such as the hard drive and the Windows registry. Isolated storage also ensures that one application cannot access another applications data. The mechanism used to protect one application's data from another is based on the identity of the assembly and the application domain in which the assembly is loaded. We discuss isolated storage in Chapter 11.
3.1.5 Application Domains and Application Configuration
The configuration of an application domain determines how the CLR loads assemblies into the application domain and provides important configuration information that controls the runtime operation of the loaded assemblies. This means that an assembly loaded into one application domain can operate very differently than the same assembly loaded into another application domain. An application domain's configuration controls the following behavior, which can have major consequences for application security if used inappropriately.
Depending on the mechanism used to load an assembly, the CLR will search for it in different places. These usually include the directory from which the executing assembly was loaded and the global assembly cache, which we discussed in Chapter 2. Using application domain configuration, it is possible to specify additional locations where the CLR will look for assemblies to load. If configured incorrectly, code could have the ability to load assemblies to which it should not have access or could even attempt to load the wrong assembly inadvertently.
Application domain configuration defines the name and location of the configuration file used by assemblies that are loaded into it. Depending on the use an application makes of configuration files, specifying a different one can fundamentally change the application's behavior. This setting is particularly important if the application uses a configuration file as a source of security-related information, such as the authentication or authorization mechanisms to use, or which cryptographic algorithms to use to encrypt data.
Consult the .NET Framework SDK documentation for specifics on how to configure these application domain settings.







