Managing File Systems and Disk Space
Managing File Systems and Disk Space
File systems in Red Hat Linux are organized in a hierarchy, beginning from root (/) and continuing downward in a structure of directories and subdirectories. As an administrator of a Red Hat Linux system, it is your duty to make sure that all the disk drives that represent your file system are available to the users of the computer. It is also your job to make sure there is enough disk space in the right places in the file system for users to store what they need.
File systems are organized differently in Linux than they are in MS Windows operating systems. Instead of drive letters (for example, A:, B:, C:) for each local disk, network file system, CD-ROM, or other type of storage medium, everything fits neatly into the directory structure. It is up to an administrator to create a mount point in the file system and then connect the disk to that point in the file system.
| Cross-Reference? |
Chapter 2 provides instructions for using Disk Druid to configure disk partitions. Chapter 4 describes how the Linux file system is organized. |
The organization of your file system begins when you install Linux. Part of the installation process is to divide your hard disk (or disks) into partitions. Those partitions can then be assigned to:
-
A part of the Linux file system,
-
Swap space for Linux, or
-
Other file system types (perhaps containing other bootable operating systems)
For our purposes, I want to focus on partitions that are used for the Linux file system. To see what partitions are currently set up on your hard disk, use the fdisk command as follows:
# fdisk –l Disk /dev/hda: 40.0 GB, 40020664320 255 heads, 63 sectors/track, 4825 cylinders Units = cylinders of 16065 * 512 bytes = 8225280 bytes Device Boot Start End Blocks Id System /dev/hda1 * 1 13 104 b Win95 FAT32 /dev/hda2 84 89 48195 83 Linux /dev/hda3 90 522 3478072+ 83 Linux /dev/hda4 523 554 257040 5 Extended /dev/hda5 523 554 257008+ 82 Linux swap
This output shows the disk partitioning for a computer able to run both Red Hat Linux and Microsoft Windows. You can see that the Linux partition on /dev/hda3 has most of the space available for data. There is a Windows partition (/dev/hda1) and a Linux swap partition (/dev/hda5). There is also a small /boot partition (46MB) on /dev/hda2. In this case, the root partition for Linux has 3.3GB of disk space and resides on /dev/hda3.
Next, to see what partitions are actually being used for your Linux system, you can use the mount command (with no options). The mount command can show you which of the available disk partitions are actually mounted and where they are mounted.
# mount /dev/hda3 on / type ext3 (rw) /dev/hda2 on /boot type ext3 (rw) /dev/hda1 on /mnt/win type vfat (rw) none on /proc type proc (rw) none on /dev/pts type devpts (rw,gid=5,mode=620) /dev/cdrom on /mnt/cdrom type iso9660 (ro,nosuid,nodev)
| Note? |
You may notice that /proc, /dev/pts, and other entries not relating to a partition are shown as file systems. This is because they represent different file system types (proc and devpts, respectively). The word none, however, indicates that they are not associated with a separate partition. |
The mounted Linux partitions in this case are /dev/hda2, which provides space for the /boot directory (which contains data for booting Linux), and /dev/hda3, which provides space for the rest of the Linux file system beginning from the root directory (/). This particular system also contains a Windows partition that was mounted in the /mnt/win directory and a CD that was mounted in its standard place: /mnt/cdrom. (With most GUI interfaces, the CD is typically mounted automatically when you insert it.)
After the word type, you can see the type of file system contained on the device. (See the description of different file system types later in this chapter.) Particularly on larger Linux systems, you may have multiple partitions for several reasons:
-
Multiple hard disks — You may have several hard disks available to your users. In that case you would have to mount each disk (and possibly several partitions from each disk) in different locations in your file system.
-
Protecting different parts of the file system — If you have many users on a system, and the users consume all of the file system space, the entire system can fail. For example, there may be no place for temporary files to be copied (so the programs writing to temporary files may fail), and incoming mail may fail to be written to mail boxes. With multiple mounted partitions, if one partition runs out, others can continue to work.
-
Backups — There are some fast ways to back up data from your computer that involve copying the entire image of a disk or partition. If you want to restore that partition later, you can simply copy it back (bit-by-bit) to a hard disk. With smaller partitions, this approach can be done fairly efficiently.
-
Protecting from disk failure — If one disk (or part of one disk) fails, by having multiple partitions mounted on your file system, you may be able to continue working and just fix the one disk that fails.
When a disk partition is mounted on the file system, all directories and subdirectories below that mount point are then stored on that partition. So, for example, if you were to mount one partition on / and one on /usr, everything below the /usr mount point would be stored on the second partition while everything else would be stored on the first partition. If you then mounted another partition on /usr/local, everything below that mount point would be on the third partition, while everything else below /usr would be on the second partition.
| Tip? |
What if a remote file system is unmounted from your computer, and you go to save a file in that mount point directory? What happens is that you will write the file to that directory and it will be stored on your local hard disk. When the remote file system is remounted, however, the file you saved will seem to disappear. To get the file back, you will have to unmount the remote file system (causing the file to reappear), move the file to another location, remount the file system, and copy the file back there. |
Mount points that are often mentioned as being candidates for separate partitions include /, /boot, /home, /usr, and /var. The root file system (/) is the catchall for directories that aren't in other mount points. The root file system's mount point (/) is the only one that is required. The /boot directory holds the images needed to boot the operating system. The /home file systems is where all the user accounts are typically stored. Applications and documentation are stored in /usr. Below the /var mount point is where log files, temporary files, server files (Web, FTP, and so on), and lock files are stored (that is, items that need disk space for your computer's applications to keep running).
| Cross-Reference? |
See Chapter 2 for further information on partitioning techniques. |
The fact that multiple partitions are mounted on your file system is invisible to people using your Linux system. The only times they will care will be if a partition runs out of space or if they need to save or use information from a particular device (such as a floppy disk or remote file system). Of course, any user can check this by typing the mount command.
Mounting file systems
Most of your hard disks are mounted automatically for you. When you installed Red Hat Linux, you were asked to create partitions and indicate the mount points for those partitions. When you boot Red Hat Linux, all Linux partitions should be mounted. For that reason, this section focuses mostly on how to mount other types of devices so that they become part of your Red Hat Linux file system.
Besides being able to mount other types of devices, you can also use mount to mount other kinds of file systems on your Linux system. This means that you can store files from other operating systems or use file systems that are appropriate for certain kinds of activities (such as writing large block sizes). The most common use of this feature for the average Linux user, however, is to allow that user to obtain and work with files from floppy disks or CD-ROMs.
Supported file systems
To see file system types that are currently in use on your system, type cat /proc/filesystems. The following file system types are supported in Linux:
-
befs — This is the file system used by the BeOS operating system.
-
ext3 — The ext file systems are the most common file systems used with Linux. The ext3 file system was new for Red Hat Linux 7.2 and is the default file system type. The root file system (/) must be ext3, ext2, or minux. The ext3 file system is also referred to as the Third Extended file system. The ext3 file system includes journaling features that improve a file system's ability to recover from crashes, as compared to ext2 file systems.
-
ext2 — The default file system type for previous versions of Red Hat Linux. Features are the same as ext3, except that ext2 doesn't include journaling features.
-
ext — This is the first version of ext3. It is not used very often anymore.
-
iso9660 — This file system evolved from the High Sierra file system (which was the original standard used on CD-ROM). Extensions to the High Sierra standard (called Rock Ridge extensions), allow iso9660 file systems to support long filenames and UNIX-style information (such as file permissions, ownership, and links).
-
kafs — This is the AFS client file system. It is used in distributed computing environments to share files with Linux, Windows, and Macintosh clients.
-
minix — This is the Minix file system type, used originally with the Minix version of UNIX. It only supports filenames of up to 30 characters.
-
msdos — This is an MS-DOS file system. You can use this type to mount floppy disks that come from Microsoft operating systems.
-
umsdos — This is an MS-DOS file system with extensions to allow features that are similar to UNIX (including long filenames).
-
proc — This is not a real file system, but rather a file-system interface to the Linux kernel. You probably won't do anything special to set up a proc file system. However, the /proc mount point should be a proc file system. Many utilities rely on /proc to gain access to Linux kernel information.
-
reiserfs — This is the ReiserFS journaled file system.
-
swap — This is used for swap partitions. Swap areas are used to temporarily hold data when RAM is currently used up. Data is swapped to the swap area, then returned to RAM when it is needed again.
-
nfs — This is the Network File System (NFS) type of file system. File systems mounted from another computer on your network use this type of file system.
Cross-Reference? Information on using NFS to export and share file systems over a network is contained in Chapter 18.
-
hpfs — This file system is used to do read-only mounts of an OS/2 HPFS file system.
-
ncpfs — This relates to Novell NetWare file systems. NetWare file systems can be mounted over a network.
Cross-Reference? For information on using NetWare file systems over a network, see the section on setting up a file server in Chapter 18.
-
ntfs — This is the Windows NT file system. It is supported as a read-only file system (so that you can mount and copy files from it). Read-write support is available, but not built into the kernel by default and is considered unreliable (some say, dangerous).
-
affs — This file system is used with Amiga computers.
-
ufs — This file system is popular on Sun Microsystems operating systems (i.e., Solaris and SunOS).
-
xenix — This was added to be compatible with Xenix file systems (one of the first PC versions of UNIX). The system is obsolete and will probably be removed eventually.
-
xiafs — This file system supports long filenames and larger inodes than file systems such as minux.
-
coherent — This is the file system type used with Coherent or System V files. Like the xenix file system type, it will be removed at some time in the future.
Using the fstab file to define mountable file systems
The hard disks on your local computer and the remote file systems you use every day are probably set up to automatically mount when you boot Linux. The definitions for which of these file systems are mounted are contained in the /etc/fstab file. Here's an example of an /etc/fstab file:
LABEL=/ / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 /dev/fd0 /mnt/floppy auto noauto,owner 0 0 none /proc proc defaults 0 0 /dev/hda5 swap swap defaults 0 0 /dev/cdrom /mnt/cdrom iso9660 noauto,owner,kudzu,ro 0 0 /dev/hda1 /mnt/win vfat noauto 0 0
All file systems listed in this file are mounted at boot time, except for those set to noauto in the fourth field. In this example, the root (/) and boot (/boot) hard disk partitions are mounted at boot time, along with the /proc and /dev/pts file systems (which are not associated with particular devices). The floppy disk (/dev/fd0) and CD-ROM drives (/dev/cdrom) are not mounted at boot time. Definitions are put in the fstab file for floppy and CD-ROM drives so that they can be mounted in the future (as described later).
I also added one additional line for /dev/hda1, which allows me to mount the Windows (vfat) partition on my computer so I don't have to always boot Windows to get at the files on my Windows partition.
| Note? |
To access the Windows partition described above, I must first create the mount point (by typing mkdir /mnt/win). I can then mount it when I choose by typing (as root) mount /mnt/win |
You find the following in each field of the fstab file:
-
Field 1 — The name of the device representing the file system. The word none is often placed in this field for file systems (such as /proc and /dev/pts) that are not associated with special devices. Notice that this field can now include the LABEL option. Using LABEL, you can indicate a universally unique identifier (UUID) or volume label instead of a device name. The advantage to this approach is that, since the partition is identified by volume name, you can move a volume to a different device name and not have to change the fstab file.
-
Field 2 — The mount point in the file system. The file system contains all data from the mount point down the directory tree structure, unless another file system is mounted at some point beneath it.
-
Field 3 — The file system type. Valid file system types are described in the "Supported file systems" section earlier in this chapter.
-
Field 4 — Options to the mount command. In the preceding example, the noauto option prevents the indicated file system from being mounted at boot time. Also, ro says to mount the file system read-only (which is reasonable for a CD-ROM player). Commas must separate options. See the mount command manual page (under the -o option) for information on other supported options.
Tip? Normally, only the root user is allowed to mount a file system using the mount command. However, to allow any user to mount a file system (such as a file system on a floppy disk), you could add the user option to Field 4 of /etc/fstab.
-
Field 5 — The number in this field indicates whether or not the indicated file system needs to be dumped. A number 1 assumes that the file system needs to be dumped. A number 2 assumes that the file system doesn't need to be dumped.
-
Field 6 — The number in this field indicates whether or not the indicated file system needs to be checked with fsck. A number 1 assumes that the file system needs to be checked. A number 2 assumes that the file system doesn't need to be checked.
If you want to add an additional local disk or an additional partition, you can create an entry for the disk or partition in the /etc/fstab file. To get instructions on how to add entries for an NFS file system, see Chapter 18.
Using the mount command to mount file systems
Your Red Hat Linux system automatically runs mount -a (mount all file systems) each time you boot. For that reason, you would typically only use the mount command for special situations. In particular, the average user or administrator uses mount in two ways:
-
To display the disks, partitions, and remote file systems that are currently mounted.
-
To temporarily mount a file system.
Any user can type the mount command (with no options) to see what file systems are currently mounted on the local Linux system. The following is an example of the mount command. It shows a single hard disk partition (/dev/hda1) containing the root (/) file system, and proc and devpts file system types mounted on /proc and /dev, respectively. The last entry shows a floppy disk, formatted with a standard Linux file system (ext3) mounted on the /mnt/floppy directory.
$ mount /dev/hda3 on / type ext3 (rw) none on /proc type proc (rw) /dev/hda2 on /boot type ext3 (rw) none on /dev/pts type devpts (rw,gid=5,mode=0620) /dev/fd0 on /mnt/floppy type ext3 (rw)
The most common devices to mount by hand are your floppy disk and your CD-ROM. However, depending on the type of desktop you are using, CD-ROMs and floppy disks may be mounted for you automatically when you insert them. (In some cases, the autorun program may also run automatically. For example, autorun may start a CD music player or software package installer to handle the data on the medium.)
If you want to mount a file system manually, however, the /etc/fstab file helps make it simple to mount a floppy disk or a CD-ROM. In some cases, you can use the mount command with a single option to indicate what you want to mount, and information is taken from the /etc/fstab file to fill in the other options. Entries probably already in your /etc/fstab file let you do these quick mounts in the following two cases:
-
CD-ROM — If you are mounting a CD-ROM that is in the standard ISO 9960 format (as most software CD-ROMs are), you can mount that CD-ROM by placing it in your CD-ROM drive and typing the following:
# mount /mnt/cdrom
By default, your CD-ROM is mounted on the /mnt/cdrom directory. (The file system type, device name, and other options are filled in automatically.) To see the contents, type cd /mnt/cdrom, then type ls. Files from the CD-ROM's root directory will be displayed.
-
Floppy Disk — If you are mounting a floppy disk that is in the standard Linux file system format (ext3), you can mount that floppy disk by inserting it in your floppy drive and typing the following:
# mount /mnt/floppy
The file system type (ext3), device (/dev/fd0), and mount options are filled in from the /etc/fstab file. You should be able to change to the floppy disk directory (cd /mnt/floppy) and list the contents of the floppy's top directory (ls).
Note? In both of the two previous cases, you could give the device name (/dev/cdrom or /dev/fd0, respectively) instead of the mount point directory to get the same results.
Of course, it is possible that you may get floppy disks you want to use that are in all formats. Someone may give you a floppy containing files from a Microsoft operating system (in MS-DOS format). Or you may get a file from another UNIX system. In those cases, you can fill in your own options, instead of relying on options from the /etc/fstab file. In some cases, Linux autodetects that the floppy disk contains an MS-DOS (or Windows vfat) file system and mount it properly without additional arguments. However, if it doesn't, here is an example of how to mount a floppy containing MS-DOS files:
# mount -t msdos /dev/fd0 /mnt/floppy
This shows the basic format of the mount command you would use to mount a floppy disk. You could change the msdos to any other supported file system type (described earlier in this chapter) to mount a floppy of that type. Instead of using floppy drive A: (/dev/fd0), you could use drive B: (/dev/fd1) or any other accessible drive. Instead of mounting on /mnt/floppy, you could create any other directory and mount the floppy there.
Here are some other useful options you could add along with the mount command:
-
-t auto — If you aren't sure exactly what type of file system is contained on the floppy disk (or other medium you are mounting), use the -t auto option to indicate the file system type. The mount command will query the disk to try to guess what type of data it contains.
-
-r — If you don't want to make changes to the mounted file system (or can't because it is a read-only medium), use this option when you mount it. This will mount it read-only.
-
-w — This mounts the file system with read/write permission.
Some options to mount are available only for a specific file system type. See the mount manual page for those and other useful options.
Using the umount command to unmount a file system
When you are done using a temporary file system, or you want to unmount a permanent file system temporarily, you can use the umount command. This command detaches the file system from its mount point in your Red Hat Linux file system. To use umount, you can give it either a directory name or a device name. For example:
# umount /mnt/floppy
This unmounts the device (probably /dev/fd0) from the mount point /mnt/floppy. You could also have done this using the form:
# umount /dev/fd0
In general, it's better to use the directory name,.because the umount will fail if the device is mounted in more than one location.
If you get a message that the "device is busy," the umount request has failed. The reason is that either a process has a file open on the device or that a you have a shell open with a directory on the device as a current directory. Stop the processes or change to a directory outside of the device you are trying to unmount for the umount request to succeed.
An alternative for unmounting a busy device is the -l option. With umount -l (a lazy unmount), the unmount happens as soon as the device is no longer busy. To unmount a remote NFS file system that is no longer available (for example, the server went down), you can use the umount -f option to forcibly unmount the NFS file system.
Using the mkfs command to create a file system
It is possible to create a file system, for any supported file system type, on a disk or partition that you choose. This is done with the mkfs command. While this is most useful for creating file systems on hard disk partitions, you can create file systems on floppy disks or re-writable CDs as well.
Here is an example of using mkfs to create a file system on a floppy disk:
# mkfs -t ext3 /dev/fd0 mke2fs 1.34, (25-Jul-2003) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) 184 inodes, 1440 blocks 72 blocks (5.00%) reserved for the super user First data block=1 1 block group 8192 blocks per group, 8192 fragments per group 184 inodes per group Writing inode tables: done Filesystem too small for a jounal Writing superblocks and filesystem accounting information: done The filesystem will be automatically checked every 32 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
You can see the statistics that are output with the formatting done by the mkfs command. The number of inodes and block created are output. Likewise, the number of blocks per group and fragments per group are also output. You could now mount this file system (mount /mnt/floppy), change to it as your current directory (cd /mnt/floppy), and create files on it as you please.
Adding a hard disk
Adding a new hard disk to your computer so that it can be used by Linux requires a combination of steps described in previous sections. The general steps are as follows:
-
Install the hard disk hardware.
-
Identify the partitions on the new hard disk.
-
Create the file systems on the new hard disk.
-
Mount the file systems.
The easiest way to add a hard disk to Linux is to have the entire hard disk devoted to a single Linux partition. You can have multiple partitions, however, and assign them each to different types of file systems and different mount points, if you like. The procedure below describes how to add a hard disk containing a single Linux partition. Along the way, however, it also notes which steps you need to repeat to have multiple file systems with multiple mount points.
| Note? |
This procedure assumes that Red Hat Linux is already installed and working on the computer. If this is not the case, follow the instructions for adding a hard disk on your current operating system. Later, when you install Red Hat Linux, you can identify this disk when you are asked to partition your hard disk(s). |
-
Install the hard disk into your computer. Follow the manufacturer's instructions for physically installing and connecting the new hard disk. If, presumably, this is a second hard disk, you may need to change jumpers on the hard disk unit itself to have it operate as a slave hard disk. You may also need to change the BIOS settings.
-
Boot your computer to Red Hat Linux.
-
Determine the device name for the hard disk. As root user from a shell, type:
# dmesg | less
From the output, look for an indication that the new hard disk was found. For example, if it is a second IDE hard disk, you should see hdb: in the output. For a second SCSI drive, you should see sdb: instead. Be sure you identify the right disk or you will erase all the data from disks you probably want to keep!
-
Use the fdisk command to create partitions on the new disk. For example, if you are formatting the second IDE disk (hdb), you could type the following:
# fdisk /dev/hdb1
-
If the disk had existing partitions on it, you can change or delete those partitions now. Or, you can simply reformat the whole disk to blow everything away. Use p to view all partitions and d to delete a partition.
-
To create a new partition, type the following:
n
You are asked to choose an extended or primary partition.
-
To choose a primary partition, type the following:
p
You are asked the partition number.
-
If you are creating the first partition (or for only one partition), type the number one:
1
You are asked to enter the first cylinder number (with one being the default).
-
To begin at the second cylinder, type the number two as follows:
2
You are asked to enter the last cylinder.
-
If you are using the entire hard disk, use the last cylinder number shown. Otherwise, choose the ending cylinder number or indicate how many MB the partition should have.
-
To create more partitions on the hard disk, repeat the previous five steps for each partition.
-
Type w to write changes to the hard disk. At this point, you should be back at the shell.
-
To make a file system on the new disk partition, use the mkfs command. By default, this command creates an ext2 file system, which is useable by Linux. To create an ext2 file system on the first partition of the second hard disk, type the following:
# mkfs -t ext3 /dev/hdb1
If you created multiple partitions, repeat this step for each partition (such as /dev/hdb2, /dev/hdb3, and so on).
Tip? If you don't use -t ext3 as shown above, an ext2 file system is created by default. Use other commands, or options to this command, to create other file system types. For example, use mkfs.vfat to create a VFAT file system, mkfs.bfs for BFS, mkfs.minix for Minix, mkfs.msdos for DOS, or mkfs.reiserfs for Reiser file system type. The tune2fs command, described later in this section, can be used to change an ext2 file system to an ext3 file system.
-
Once the file system is created, you can have the partition permanently mounted by editing the /etc/fstab and adding the new partition. Here is an example of a line you might add to that file:
/dev/hdb1 /abc ext3 defaults 1 1
In this example, the partition (/dev/hdb1) is mounted on the /abc directory as an ext3 file system. The defaults keyword causes the partition to be mounted at boot time. The numbers 1 1 cause the disk to be checked for errors. Add one line like the one shown above for each partition you created.
-
Create the mount point. For example, to mount the partition on /abc (as shown in the previous step), type the following:
# mkdir /abc
Create your other mount points if you created multiple partitions. The next time you boot Red Hat Linux, the partition will be automatically mounted on the /abc directory, as will any other partitions you added.
Once you have created the file systems on your partitions, a nice tool for adjusting those file systems is the tune2fs command. Using tune2fs, you can change volume labels, how often the file system is checked, and error behavior. You can also use tune2fs to change an ext2 file system to an ext3 file system so the file system can use journaling. For example:
# tune2fs -j /dev/hdb1 tune2fs 1.34, (25-Jul-2003) Creating journal inode: done This filesystem will be automatically checked every 38 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
By adding the -j option to tune2fs, you can change either the journal size or attach the file system to an external journal block device. After you have used tune2fs to change your file system type, you probably need to correct your /etc/fstab file to include changing the file system type from ext2 to ext3.
Using RAID disks
RAID (Redundant Arrays of Independent Disks) is used to spread the data used on a computer across multiple disks, while appearing to the operating system as if it is dealing with a single disk partition. Using the different RAID specifications, you can achieve the following advantages:
-
Improved disk performance — RAID0 uses a feature called striping, where data is striped across multiple RAID partitions. Striping can improve disk performance by spreading the hits on a computer's file system across multiple partitions, which are presumably on multiple hard disks.
-
Mirroring — RAID1 uses partitions from multiple hard disks as mirrors. That way, if one of the partitions becomes corrupted or the hard disk goes down, the data exists on a partition from another disk because it has continuously maintained an exact mirror image of the original partition.
-
Parity — Although striping can improve performance, it can increase the chance of data loss, since any hard-disk crash in the array can potentially cause the entire RAID device to fail. Using a feature called parity, information about the layout of the striped data is kept so that data can be reconstructed if one of the disks in the array crashes. RAID3, 4, and 5 implement different levels of parity.
During installation of Red Hat Linux, you can use the Disk Druid window to create RAID0, RAID1, and RAID5 disk arrays. The following procedures describe how to set up RAID disks during installation.
Before you begin creating RAID partitions when you install Red Hat Linux, you will probably want to start with a computer that has two or more hard disks. The reason is that, if you don't have multiple hard disks, you won't get the performance gains that come from spreading the hits on your computer among multiple disks. Likewise, mirroring will be ineffective if all RAID partitions are on the same disk, because the failure of a single hard disk would still potentially cause the mirrored partitions to fail as well.
For example, you might begin with 30GB of free disk space on your first hard disk (/dev/hda) and 30GB of free disk space on your second hard disk (/dev/hdb). During the Red Hat Linux installation procedure, select to partition your disk with Disk Druid. Then follow the procedure that follows:
-
From the Disk Setup (Disk Druid) window, click the RAID button. A RAID Options window appears.
-
Select Create a Software RAID Partition, and click OK. The Add Partition window appears.
-
With Software RAID selected as the File System Type, choose the drive you want to create the partition on and choose the size (in megabytes). Then click OK.
-
Repeat steps 2 and 3 (presumably creating software RAID partitions on different hard disks until you have created all the RAID partitions you want to use).
-
Click the RAID button again. Select Create a RAID Device [default=/dev/md0] and click OK. The Make RAID Device window appears, as shown in Figure 10-4.
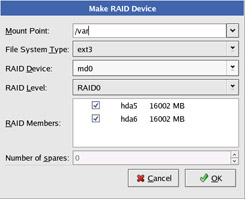
Figure 10-4: Join multiple RAID partitions to form a single RAID device. -
You need to select the following information about your RAID device and click OK:
-
Mount Point — The point in the file system associated with the RAID device. You might be creating the RAID device for a part of the file system for which you expect there to be a lot of hits on the hard disk (such as the /var partition).
-
File System Type — For a regular Linux partition, choose ext3. You can also select LVM, swap, or VFAT as the file system type.
-
RAID Device — The first RAID device is typically md0 (for /dev/md0).
-
RAID Level — Allowable RAID levels are RAID0, RAID1, and RAID5. RAID0 is for striping (essentially dividing the RAID device into stripes across RAID partitions you have selected). RAID1 is for mirroring so that the data is duplicated across all RAID partitions. RAID5 is for parity, so there is always one backup disk if a disk goes bad. You need at least three RAID partitions to use RAID5.
-
RAID Members — From the RAID partitions you created, select which ones are going to be members of the RAID device you are creating.
-
Number of spares — Select how many spares are available to the RAID device.
-
The new RAID Device should appear on the Disk Setup (Disk Druid) window. Click Next to continue with installation.
Once installation is complete, you can check your RAID devices by using a variety of tools that come with Red Hat Linux. Commands for working with RAID partitions come in the raidtools package. Using raidtools commands, you can list and reconfigure your RAID partitions.
Checking system space
Running out of disk space on your computer is not a happy situation. Using tools that come with Red Hat Linux, you can keep track of how much disk space has been used on your computer, and you can keep an eye on users who consume a lot of disk space.
Displaying system space with df
You can display the space available in your file systems using the df command. To see the amount of space available on all of the mounted file systems on your Linux computer, type df with no options:
$ df Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda3 30645460 2958356 26130408 11% / /dev/hda2 46668 8340 35919 19% /boot /dev/fd0 1412 13 1327 1% /mnt/floppy
The output here shows the space available on the hard disk partition mounted on the root partition (/dev/hda1), /boot partition (/dev/hda2), and the floppy disk mounted on the /mnt/floppy directory (/dev/fd0). Disk space is shown in 1K blocks. To produce output in a more human-readable form, use the -h option as follows:
$ df -h Filesystem Size Used Avail Use% Mounted on /dev/hda3 29G 2.9G 24G 11% / /dev/hda2 46M 8.2M 25M 19% /boot /dev/fd0 1.4M 13k 1.2M 1% /mnt/floppy
With the df -h option, output appears in a friendlier megabyte or gigabyte listing. Other options with df let you:
-
Print only file systems of a particular type (-t type)
-
Exclude file systems of a particular type (-x type)
-
Include file systems that have no space, such as /proc and /dev/pts (-a)
-
List only available and used inodes (-i)
-
Display disk space in certain block sizes (--block-size=#)
Checking disk usage with du
To find out how much space is being consumed by a particular directory (and its subdirectories), you can use the du command. With no options, du lists all directories below the current directory, along with the space consumed by each directory. At the end, du produces total disk space used within that directory structure.
The du command is a good way to check how much space is being used by a particular user (du /home/user1) or in a particular file system partition (du /var). By default, disk space is displayed in 1K block sizes. To make the output more friendly (in kilobytes, megabytes, and gigabytes), use the -h option as follows:
$ du -h /home/jake 114k /home/jake/httpd/stuff 234k /home/jake/httpd 137k /home/jake/uucp/data 701k /home/jake/uucp 1.0M /home/jake
The output shows the disk space used in each directory under the home directory of the user named jake (/home/jake). Disk space consumed is shown in kilobytes (k) and megabytes (M). The total space consumed by /home/jake is shown on the last line.
Finding disk consumption with find
The find command is a great way to find file consumption of your hard disk using a variety of criteria. You can get a good idea of where disk space can be recovered by finding files that are over a certain size or were created by a particular person.
| Note? |
You must be root user to run this command effectively, unless you are just checking your personal files. |
In the following example, the find command searches the root file system (/) for any files owned by the user named jake (-user jake) and prints the filenames. The output of the find command is then listed with a long listing in size order (ls -ldS). Finally that output is sent to the file /tmp/jake. When you read the file /tmp/jake, you will find all of the files that are owned by the user jake, listed in size order. Here is the command line:
# find / -user jake -print -xdev | xargs ls -ldS > /tmp/jake
| Tip? |
The -xdev option prevents file systems other than the selected file system from being searched. This is a good way to cut out a lot of junk that may be output from the /proc file system. It could also keep large remotely mounted file systems from being searched. |
The next example is similar to the previous one, except that instead of looking for a user's files, this command line looks for files that are larger than 100 kilobytes (-size 100k):
# find / -size 100k -print -xdev | xargs ls -ldS > /tmp/size
You can save yourself a lot of disk space by just removing some of the largest files that are no longer needed. Open the /tmp/size file in this example and large files are sorted by size.







