Detecting DoS Attacks
A wide variety of DoS attacks can occur. The most common DoS attacks use UDP echos (Fraggle), ICMP echo and echo replies (Smurf), and TCP (TCP SYN flooding). However, you never should assume that the DoS attack that you are experiencing falls under one of these three types: Some do not fall under these categories.
Common Attacks
One of the most common DoS attacks is the Smurf attack, which I covered in Chapter 7, "Basic Access Lists." (Chapter 7 also covered how to use ACLs to deal with the Smurf attack.) In a Smurf attack, the attacker sends a flood of ICMP messages to a reflector or sets of reflectors, with the source IP address in the ICMP echo messages spoofed. The hacker changes these addresses to the address of the actual victim device or devices. The reflectors then innocently reply to the echo messages, inadvertently sending the replies to the victim. In many cases, the source address is a directed broadcast address, allowing the attack to target a network segment instead of a specific host. Based on this information, if you see a large number of ICMP echo replies coming into your network, you probably are experiencing a Smurf attack, or at least a derivative of this kind of attack. Likewise, if you are seeing a large number of packets coming into your network with a directed broadcast address, this would indicate that you are under attack. One method of preventing this is to use the no ip directed-broadcast command on your router's interfaces. I discussed this command in Chapter 4, "Disabling Unnecessary Services."
The Fraggle DoS attack is similar to the Smurf attack, except that Fraggle uses UDP echo and echo reply messages instead of ICMP messages. Because UDP echos typically are filtered, Fraggle typically has a less likelihood of having the same impact that Smurf does (I discussed in Chapter 4 how to defeat a Fraggle attack by configuring the no service tcp-small-servers and no service udp small-servers commands).
The other common attack is a TCP SYN flood attack, in which an attacker tries to overwhelm one or more TCP services running on a machine. The attacker executes this attack by sending a flood of TCP SYN segments to the victim. In most cases, the hacker forges the source address to hide his tracks or possibly to create another DoS attack against a second victim. Therefore, when the server receives the TCP SYNs and tries to complete the three-way handshake, the process fails: The server sends a SYN/ACK response to a bogus or invalid address and, therefore, never gets the final ACK reply in the three-way handshake. During this period, resources are tied up on the server for each of these half-open (commonly called embryonic) connections. Because this kind of attack typically is targeted at a specific machine, when you experience a slowing of your server that offers TCP services, such as an e-mail, web, or FTP server, or if one of these servers crashes or halts, this might indicate that it was (and possibly still is) the victim of a TCP SYN flood attack.
Symptoms of Attacks
When your router is experiencing a DoS attack (including worm attacks), either one directed at the router or one in which the router is a transit device, you can look for the following to help you confirm your hunches:
Your router is seeing an unusually high number of ARP requests.
Your NAT/PAT address-translation tables have a large number of entries.
Your router's IP Input, ARP Input, IP Cache Ager, and CEF processes are using abnormally high amounts of memory.
Your router's ARP, IP Input, CEF, and IPC processes are running at a much higher CPU utilization rate.
TIP
The following sections discuss various methods for detecting and tracing DoS attacks. However, one of the best solutions for detecting DoS attacks is to use an IDS solution. A good IDS solution should tell you exactly the kind of DoS attack that you are facing.
Examining CPU Utilization to Detect DoS Attacks
In any DoS attack situation, the network symptoms that you see typically will be common, such as high CPU utilization on your devices or a high number of certain kinds of packets. Therefore, one of the first things you want to do is to log into your perimeter routers and firewalls and examine their CPU utilization.
On a Cisco router, use the show processes cpu command to examine the router's CPU utilization, as shown in Example 17-1.
Example 17-1. Using the show processes cpu Command
Router# show processes cpu CPU utilization for five seconds: 92%/34%; one minute: 90%; five minutes: 45% PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process 1 0 1 0 0.00% 0.00% 0.00% 0 Chunk Manager 2 0 294 0 0.00% 0.00% 0.00% 0 Load Meter 3 7532 2365 3184 0.00% 0.00% 0.24% 0 Exec 4 0 13 0 0.00% 0.00% 0.00% 0 DHCPD Timer 5 800 156 5128 0.00% 0.02% 0.03% 0 Check heaps 6 0 1 0 0.00% 0.00% 0.00% 0 Pool Manager <--output omitted-->
The shaded line is what you should focus on. Three statistics are listed here:
CPU utilization for five seconds? This is the CPU utilization on the router for the last 5 seconds. The number after the slash (/) is the percentage of CPU time spent at the interrupt level. During an interrupt, the CPU must handle the functions for the process instead of an interface or a specific ASIC (application-specific integrated circuit).
One minute? This is the CPU utilization of the router over the past minute.
Five minutes? This is the CPU utilization of the router over the past 5 minutes.
In Example 17-1, the 5-second utilization is 92 percent and the 1-minute utilization is 90 percent. Notice that the 5-minute utilization is only 45 percent. This probably indicates a brief spike in traffic. If all three of these are at a higher number than normal and are close together in values, such as 75 or 95 percent (depending on your router's baseline, of course), this could indicate a DoS attack. In this situation, you should look at other things on your router to determine whether this is just an anomaly in traffic conditions or a DoS attack.
A derivation of the show processes cpu command is the addition of the history parameter. This command displays, in an ASCII graphical format, the total CPU usage of the router over 1 minute, 1 hour, and 72 hours. Example 17-2 shows an example of the use of this command.
Example 17-2. Using the show processes cpu history Command
Router# show processes cpu history
<-- One minute output omitted -->
6665776865756676676666667667677676766666766767767666566667
6378016198993513709771991443732358689932740858269643922613
100
90
80 ** * * * * * * *
70 * * ****# * ** ***** *** **** ****** * *** *** *
60 #***##*##*#***#####*#*###*****#*###*#*#*##*#*#**#*##*****
50 #########################################################*
40 ##########################################################
30 ##########################################################
20 ##########################################################
10 ##########################################################
0....5....1....1....2....2....3....3....4....4....5....5....
0 5 0 5 0 5 0 5 0 5
CPU% per minute (last 60 minutes)
* = maximum CPU% # = average CPU%
<-- 72-hour output omitted -->
In Example 17-2, the Y-axis of the graph represents CPU utilization, and the X-axis represents the increment period. In this example, I omitted the output for the 1-minute and 72-hour output and listed only the hour output.
The maximum usage, represented by a *, is measured and recorded every second (this is displayed at the very top of a vertical entry). The average usage is measured over a period of 1 second and is represented by a #.
The very top of the graph lists the actual CPU utilization for the 1-minute interval, which fluctuated between 60 and 80 percent utilization.
For worm attacks, examine the following information in the output of the show process cpu command: ARP, IP Input, CEF, and IPC processes. Also examine the following information in the output of the show processes memory command: IP Input, ARP Input, IP Cache Ager, and CEF processes.
NOTE
Of course, looking at the CPU utilization during a DoS attack assumes that you have captured a history of CPU utilization baselines during normal traffic conditions. If you do not have this information and your CPU utilization is running at 75 percent, this might be a normal condition for your router. Therefore, you periodically should gather statistical information about your router, including CPU utilization and the bandwidth utilization on each of its interfaces. This will help you determine whether something abnormal, such as a DoS attack, is directed at your router or is flowing through your router. Also, if your CPU utilization is running at 100 percent because of a severe DoS or worm attack, your router might reload itself. Therefore, you also should check to see if your router periodically is reloading, which could indicate that you are under attack.
Using ACLs to Detect DoS Attacks
One of the most common tools used to detect DoS attacks is ACLs. This is especially true of your perimeter routers and router firewalls because these devices already have ACLs in place to filter traffic. As I mentioned in Chapter 7, you always want to include a deny ip any any statement in your ACL at the end. This is not necessary to drop traffic, but it does have the router keep statistics on the number of matches on this statement. This can be useful in determining whether a DoS attack is occurring.
ACL Counters
The first thing you should do is clear the counters for your ACL with the following command:
Router# clear access-list counters [ACL_#_or_name]
After this, view the ACL in question with the show access-lists or show ip access-list commands. Example 17-3 shows sample output from the show access-list command.
Example 17-3. Displaying the Counters for ACL Statement Matches
Router# clear access-list counters 100 Router# show access-list 100 Extended IP access list 100 <--output omitted--> deny ip any any (3183 matches) Router# Router# show access-list 100 Extended IP access list 100 <--output omitted--> deny ip any any (7225 matches)
Notice in this example that, after I cleared the ACL counters for ACL 100 and then viewed the ACL the first time (right after clearing the ACL counters), the match on the deny ip any any statement is 3183, which is relatively high for just a couple of seconds between executing the two commands. Right after executing the first show command, I re-executed it. Notice that in the second or two between the execution of the two commands, the number of matches more than doubled. In this example, I was sending a flood of ICMP packets from three devices to one victim device.
Here are some important things to keep in mind about using ACLs to detect a DoS attack:
In this example, I assumed that the traffic being dropped was the DoS attack. You also need to examine the matches on permit entries because your ACL might be permitting the DoS attack, such as a TCP SYN flood. Again, a good baseline of this information should assist you in determining whether a DoS attack is occurring. In other words, you should have gathered ACL statistics in normal traffic periods, and then you can use this to make a comparison.
Remember that because you are using extended ACLs, you can specify the IP protocol, source and destination addresses, and protocol information, such as TCP and UDP port numbers as well as ICMP message types. This enables you to be as specific as possible in determining a match.
If the ACL in question is applied to multiple interfaces, remember that the ACL counters are an aggregate of all of the matches on all interfaces on which the ACL has been activated. In this situation, you might want to have a separate named/numbered ACL for each interface.
Specific ACL Entries
Of course, the problem with the previous examination is that you can see that your router is dropping a flood of traffic, but you do not see what traffic the router is dropping. For example, if you do not want to allow any type of ICMP traffic, or even if you want to permit only certain kinds of ICMP traffic, put in the appropriate ACL entries so that, minimally, you can see ACL statistics on matches. Refer to Figure 17-1 for an example. Here, no echo messages should be allowed into the network, and only echo replies to the management station are allowed.
Figure 17-1. ACL Example
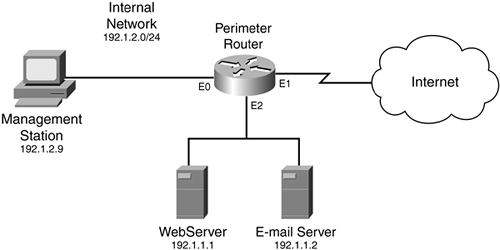
Example 17-4 shows a basic ACL example for this network.
Example 17-4. A Basic ACL Example
Router(config)# remark Insert other ACL statements here Router(config)# access-list 100 deny ip any 192.1.1.0 0.0.0.0 (1) Router(config)# access-list 100 deny ip any 192.1.1.255 0.0.0.0 Router(config)# access-list 100 deny ip any 192.1.2.0 0.0.0.0 Router(config)# access-list 100 deny ip any 192.1.2.255 0.0.0.0 Router(config)# access-list 100 permit icmp any (2) host 192.1.2.9 echo-reply Router(config)# access-list 100 deny icmp any any echo (3) Router(config)# access-list 100 deny icmp any any echo-reply (4) Router(config)# access-list 100 deny udp any any eq echo (5) Router(config)# access-list 100 deny udp any eq echo any (6) Router(config)# access-list 100 permit tcp any (7) host 192.1.1.1 eq 80 established Router(config)# access-list 100 permit tcp any (8) host 192.1.1.1 eq 80 Router(config)# access-list 100 permit tcp any (9) host 192.1.1.2 eq 25 established Router(config)# access-list 100 permit tcp any (10) host 192.1.1.2 eq 25 Router(config)# remark Insert other ACL statements here Router(config)# access-list 100 deny ip any any Router(config)# interface ethernet1 Router(config-if)# ip access-group 100 in
This example not only sets up filtering, but it also has specific entries that can be used to detect four DoS attacks: directed broadcast attacks (Statement 1), which are used by many types of DoS attacks; a Smurf attack (Statements 2, 3, and 4); a Fraggle attack (Statements 5 and 6), and TCP SYN floods (Statements 7 and 8):
For a Smurf attack, if the entries in Statements 2 or 4 are increasing rapidly, this indicates that Smurf reflectors are attacking you (you are the victim). If you are the reflector, you will see entries in Statement 3 rapidly increasing. This is especially true if you do not configure the group of statements in Statement 1. However, to determine this, you would need to enable logging for the ICMP ACL statements, which I discuss in the next section.
For a Fraggle, attack, if the entries in Statement 5 are increasing, this indicates that you are the victim; a large number of matches against Statement 6 indicates that you are the reflector.
For a TCP SYN flood attack, you will see the number of matches against Statements 8 and 10 increasing many times over normal baseline numbers. What is unusual about these two ACL statements is that they are normal ACL statements allowing traffic to the e-mail and web servers. However, remember that the Cisco IOS keeps track of the number of matches on all statements, so a large increase in the number of matches for either of these two servers could indicate a TCP SYN flood attack. Because there are many types of TCP flood attacks, using various TCP flags, Statements 7 and 9 look at the other TCP flags for an abnormal number of other TCP messages.
Also, the statements under Statement 1 block traffic sent to the network and directed broadcast addresses of the internal network. These addresses are commonly used in DoS attacks. By having specific entries in your ACL, you can use the show access-lists command to determine more easily whether a DoS attack is occurring.
ACL Logging
The main limit of the statistics from the show access-lists and show ip access-list commands is that they can show you that a high number of hits are occurring against one or a few ACL statements, but this does not tell you who the attacker (or the victim, in some cases) is. One option is to use the log or log-input parameters at the end of the ACL statements in question. As you recall from Chapter 7, the main difference between these two commands is that the log-input parameter displays the input interface of the received packet and the Layer 2 source address in the packet.
CAUTION
In either situation, remember that using either of these two parameters disables CEF switching, which seriously impacts the performance of the router. Therefore, use the log function to pinpoint the attack, including the victim and the attacker, and then remove the log or log-input parameters from your ACL statement(s).
Smurf Example
For example, assume that the router in Figure 17-1 is under a Smurf attack. When you examine the router's ACL, you notice the output in Example 17-5.
Example 17-5. Using the show access-list to Pinpoint a Smurf Attack
Router# show access-list 100 Extended IP access list 100 <--output omitted--> permit icmp any host 192.1.2.9 echo-reply (15 matches) deny icmp any any echo (1038 matches) deny icmp any any echo-reply (238482 matches) deny udp any any eq echo deny udp any eq echo any <--output omitted-->
As you can see in Example 17-5, an inordinate number of ICMP echo reply messages is being denied (remember that only the management station is allowed to ping and receive replies).
To determine the problem, you would modify the ACL statement for the dropped ICMP packets by changing ACL Statement 4 in Example 17-4 to this:
Router(config)# access-list 100 deny icmp any any echo reply log-input
In this situation, I probably would disable logging to the console but enable logging to the internal buffer (this is discussed in Chapter 18, "Logging Events." Therefore, when there is an inordinate number of log messages, the console interface will not be overwhelmed.
Given the Smurf attack in the example, here is a snippet of the output produced by log messages from a match on the ACL statement:
%SEC-6-IPACCESSLOGDP: list 100 denied icmp 201.1.1.1 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 201.1.1.2 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 201.1.1.9 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 205.8.8.7 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 200.1.1.37 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 201.1.1.1 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 205.8.8.32 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet %SEC-6-IPACCESSLOGDP: list 100 denied icmp 201.1.1.81 (Ethernet1) -> 192.1.1.1 (0/0), 1 packet
In this example, a single host is being attacked: 192.1.1.1. Also notice that most of the ICMP traffic is coming from two networks: 201.1.1.0/24 and 205.8.8.0/24. By using the IANA Whois database (http://www.iana.org), you should be able to see who these addresses belong to. It is important to point out that in a Smurf attack, these are probably not the actual attacker devices, but Smurf reflectors (with Smurf, it is very unlikely that the attacker would use his own address as a source, unless he is a script kiddie). However, at least you have a starting point and should be able to contact the ISPs or administrators who are responsible for these networks so that they can take the appropriate action.
Keep the following items in mind when using logging with ACLs:
Enabling logging with ACLs can have a small- to medium-size impact on your router, depending on its model. Therefore, I recommend that you be careful using the logging function on routers that are running at 80 percent utilization or higher?especially with ACLs on high-speed interfaces.
Depending on the version of the Cisco IOS running on your router, logging might affect the switching mode that the router must use to implement the logging function.
If you are seeing matches against ACL entries in the show access-list command, but you are not seeing any entries actually being logged (you have added the log parameter to the ACL statement), try clearing the route cache to force packets to be process-switched. Of course, this can cause a lot of traffic to be dropped on a very busy router when it is in the process of rebuilding the cache. To get around this specific problem, use a router that supports CEF.
ACL logging does not display every packet that matches an ACL entry. Instead, you will see at least the first packet on a match for a session and then packets at periodic intervals. The Cisco IOS uses rate limiting to prevent logging from overloading the router's CPU. It is important to remember that you will not see all packets that match an ACL statement when you have logging enabled.
During a Smurf attack that involves multiple reflectors, the amount of logging information might be overwhelming. In this instance, set up a separate ACL statement that matches on a single reflector and logging for only this reflector. Typically, this will be multiple devices from a single network, so use an ACL that matched on all of these devices. This helps you determine all of the devices in one reflector site.
TIP
Be as specific as possible in your ACL statements when looking for the DoS attack. Use the log-input parameter so that you can see the interface where the attack is coming from. If the router's interface is a multiaccess interface, this information also will include the MAC address of the next-hop router; use the show ip arp MAC_address command to see the router's IP address.
NOTE
The purpose of this section on ACLs was to give you a basic understanding of how to track down the type of DoS attack. Obviously, you can add or modify ACL entries to determine the kind of DoS attack you are experiencing.
Damage Limitations
The attacker in a DoS attack wants to affect bandwidth and service levels, so your first concern should be preventing this traffic from traversing your ISP links. You could set up an ACL on your perimeter routers to block this traffic, but this stops it only from entering your network; it does not prevent it from traversing your ISP links.
In this situation, you need to contact your ISP and explain the situation. Hopefully they also will investigate the problem on their end and either set up a temporary ACL filter to block the offending traffic or set up rate limiting to reduce the effect that the DoS attack will have. As I mentioned, this should be a temporary filter: When the attack has been mitigated, these measures should be removed.
Finding the Attacker
When you are the victim of a DoS attack, tracking down the actual attack, as well as the perpetrator, can be a difficult and stressful task. Remember that the source addresses in a DoS attack typically are forged and, therefore, are not very helpful in finding the actual attacker. Therefore, finding the attacker typically must be done on a hop-by-hop basis, tracing the attack from one router to the next until you finally arrive at the source of the attack. As you saw in the "Using ACLs to Detect DoS Attacks" section, this requires administrators possibly to add ACL entries and/or add logging to specific ACL entries, which can be a complex process. And because the path of the attack might take you back through multiple ISPs, you typically must involve law-enforcement agencies to get the kind of cooperation from ISPs and network administrators that might be necessary to perform this kind of trace.
The Trace Process
Tracing DoS attacks is a straightforward process. In this subsection and the following ones, I discuss the use of ACLs to perform the trace process. However, other options, such as NetFlow, can be used as well. I discuss NetFlow after discussing ACLs.
Remember that the source address in the packet probably is spoofed, so you cannot assume anything about the location of the attacker. Therefore, you have your work cut out for you: The actual trace process requires you to trace back, router by router, to the real source of the attack. Figure 17-2 illustrates this process. In this example, the e-mail server (192.1.1.1) is under a DoS attack. The first thing that you would do is to log into RouterA, which I am assuming is the router directly connected to the same segment as the e-mail server. Remember that the DoS attack might be internal, not external, to the network. From here, you would determine which interface the attack is coming from, log into the next-hop router, and perform the same process, tracing this back eventually to the hacker himself.
Figure 17-2. Tracing Example

Trace Problems
In a Smurf attack, in which reflectors are used to instigate the attack against a victim, it is fairly easy to determine who the reflectors are. However, when you have found the reflectors, tracing the attack back to the originator of the attack is difficult, if not impossible, because it must be done on a hop-by-hop basis, probably through many different ISPs. Given this tedious process, you face the following problems when tracking down the attacker who instigated the DoS attack:
Because multiple administrators and networks typically are involved in the trace-back process, it becomes a tedious and slow process tracing back the attack to the real source. Even an unintelligent hacker knows that you will attempt to trace his attack; therefore, the hacker limits the duration of the DoS attack, which might not give you enough time to trace the attack.
If the attack goes through multiple networks or ISPs, and possibly even through different countries, getting the appropriate assistance could be difficult.
The attack might be coming from multiple sources, as in a Smurf attack. With a Smurf attack, you need to trace the attack back to each reflector and then, from each reflector, trace the attack back to the real source or sources of the attack.
The attack might be perpetrated from a hacked computer that was compromised by the hacker. Therefore, finding the actual perpetrator might be impossible unless the hacked computer has detailed logs of unauthorized access to it.
When you actually track down the DoS attacker, you will face legal and political issues trying to sue for damages in a civil action. You will need detailed proof of the attack to bring criminal actions against the attacker?and this can be very difficult if the attacker is in a different country.
NOTE
Given these problems, you should realize that, in most cases, you will not be able to find the attacker who instigated a DoS attack. Therefore, you should pick your battles. In most cases, you will want to use tools to limit the effect of a DoS attack and attempt to trace back attacks only when they are severe enough to prevent your company from operating or reaching its business goals. Also, if the trace involves multiple companies and ISPs, you typically must get law-enforcement agencies involved to get the information necessary to find the attacker.
Using NetFlow to Detect DoS Attacks
One of the problems of using the log or log-input parameters with ACL statements is that it is very process-intensive for the router to handle the logging function. Cisco provides another solution, called NetFlow switching. NetFlow enables you to capture statistics of flows traveling through your router. It is a transparent switching method that requires you only to enable it. Unlike ACLs with logging, NetFlow is a switching technology that has much less of an impact on the router. As with ACL logging, you can export NetFlow information to a server, to be examined in more depth.
NetFlow Overview
NetFlow switching is a network-layer switching method that switches packets at high speeds and captures statistics for traffic analysis. It is supported on IP and IP-encapsulated traffic types over a variety of interfaces, including interfaces with input ACLs.
NOTE
NetFlow is not supported on ISL trunk interfaces, ATM and Frame Relay interfaces if more than one input ACL is used, and ATM LANE interfaces.
Cisco developed NetFlow switching to provide the following benefits:
Processing of ACL statements with little performance penalty (at least, compared to many other switching modes)
Billing for bandwidth usage in corporate and ISP networks
Capturing of traffic for network management and capacity planning
NetFlow uses flows to identify traffic. A flow is basically a unidirectional session based on the following fields in an IP packet: IP protocol, source and destination IP address, type of service, source and destination port numbers for TCP and UDP flows, and input interface. When NetFlow identifies a new flow, an entry is added to the NetFlow cache. This entry then is used to switch packets and to perform ACL checking.
NetFlow Configuration
Enabling NetFlow is a simple process. You can use many optional parameters to create a more efficient capturing process for traffic statistics. However, I focus on only the basics of enabling NetFlow, exporting NetFlow statistics, and examining the statistics.
Enabling NetFlow
Enabling NetFlow is done on your router's interface(s). When using it to track down DoS attacks, I recommend that you enable it on an interface or interfaces of your router where you think the source of the DoS attack is originating. Here is the basic configuration to enable NetFlow:
Router(config)# interface type [slot_#/]port_# Router(config-if)# ip route-cache flow
The ip route-cache flow command enables NetFlow switching on a router's interface. If you have a Cisco router that supports distributed switching, such as the 7500 with RSP and VIP modules, you need to execute one more command on the router's interface:
Router(config-if)# ip route-cache distributed
This command enables distributed switching with NetFlow.
Exporting NetFlow Data
Optionally, you can export NetFlow statistical data to an external device that supports NetFlow data imports. After you set up the export function, NetFlow information is exported every time a flow expires. A few products on the market, including one from Cisco, can be used to decipher the exported information. You then can use the NetFlow statistical information to generate traffic-analysis reports and graphs. To enable export of NetFlow information, use the following command:
Router(config)# ip flow-export IP_address UDP_port_# [version 5]
With the ip flow-export command, you must specify the IP address of the NetFlow server, as well as the UDP port number used on the server. There are two versions of NetFlow: version 1 and 5. Version 1 is the default if no version number is specified. To export information to a NetFlow server that supports version 5, you must specify the version number in the command. One advantage that version 5 has over version 1 is that version 5 includes a sequence number in each segment. UDP is unreliable, so there is a chance that the NetFlow server will not receive some exported NetFlow packets. Using the sequence number in version 5 allows the NetFlow server to verify that it received all of the NetFlow segments or determine that some are missing.
Examining and Clearing NetFlow Statistics
After you have set up NetFlow, use the show ip cache flow command to examine the flows and their statistics:
Router# show ip cache [prefix mask] [type number] [verbose] flow
The prefix mask option displays entries in the cache that match the prefix and subnet mask, limiting your output. Likewise, you can list the specific interface, displaying only the flows for that interface. Example 17-6 displays the output of this command:
Example 17-6. Using the show ip cache flow Command
Router# show ip cache flow IP packet size distribution (33 total packets): (1) 1?32 64 96 128 160 192 224 256 288 320 352 384 416 448 480 000 000 000 1.00 000 000 000 000 000 000 000 000 000 000 000 512 544 576 1024 1536 2048 2560 3072 3584 4096 4608 000 000 000 000 000 000 000 000 000 000 000 IP Flow Switching Cache, 4358208 bytes (2) 1 active, 65535 inactive, 3 added 68 ager polls, 0 flow alloc failures Active flows timeout in 30 minutes Inactive flows timeout in 15 seconds last clearing of statistics never Proto Total Flows Packets Bytes Packets Active(Sec) Idle(Sec) (3) ----- Flows /Sec /Flow /Pkt /Sec /Flow /Flow ICMP 3 0.0 4 100 0.0 0.0 14.1 Total 3 0.0 4 100 0.0 0.0 14.1 SrcIf SrcIPaddress DstIf DstIPaddress Pr SrcP DstP Pkts (4) Et1 200.1.1.1 Et0 192.1.1.1 01 0000 0800 5
Here is an explanation of the information in Example 17-6, with reference to the numbering on the right side. Statement 1 displays the percentage of the distribution of packets based on their size. Notice that 100 percent of the packets are in the 128-byte range.
Statement 2 displays some general statistics about NetFlow switching, such as the total number of bytes that the cache table is using, as well as the number of active flows. Also notice that the NetFlow statistics have not been cleared since NetFlow was configured or the router was booted. To clear the flow statistics, use the clear ip flow stats command.
Statement 3 displays a section on protocol statistics. Table 17-1 describes these fields. Statement 4 displays the actual flows. Table 17-2 describes these fields.
Field | Description |
|---|---|
Proto | IP protocol name or number, such as ICMP |
Total Flows | Total number of flows for this protocol since the statistics last were cleared |
Flows/Sec | Average number of flows for the protocol per second for this summary period |
Bytes/Pkt | Average number of bytes for the packets associated with this protocol for this summary period |
Packets/Sec | Average number of packets per second for this summary period |
Active(Sec)/Flow | Total of all the seconds from the first to last packets of an expired flow, or total flows for this protocol in the summary period |
Idle(Sec)/Flow | Total idle time of all seconds since the last packet for this protocol in the summary period |
Field | Description |
|---|---|
SrcIf | The interface that the packet was received on |
SrcIPaddress | The source IP address in the packet |
DstIf | The interface that the packet was sent out of |
DstIPAddress | The destination address in the packet |
Pr | The IP protocol number (1 is ICMP) |
SrcP | In hexadecimal, the source port number |
DstP | In hexadecimal, the destination port number |
Pkts | The number of packets for this flow |
NOTE
It is important to point out that the port number information in the output of the show ip cache flow command is in hexadecimal. Keep this in mind when looking for particular flows in the cache.
NetFlow and DoS Attacks
Now that you have a basic understanding of how to set up NetFlow and examine its statistics, this section looks at how to use this information to your advantage when trying to determine whether you are experiencing a DoS attack. The next few sections show some examples of different Worm and DoS attacks.
TIP
When you are under a heavy DoS attack, I highly recommend that you use NetFlow instead of ACL logging, to help determine the kind of DoS attack as well as information about where the attack is coming from. If you use ACL logging, there is a chance that the overhead that this adds to your router will overwhelm it, possibly causing it to crash.
W32.Blaster Worm
If you are experiencing high CPU utilization on your router, as well as packet drops on your input interfaces, you might have an infestation of the W32.Blaster worm or one of its derivatives. The W32.Blaster worm appears as UDP traffic on port 69 with high volumes of traffic on ports 135 and 4444. The worm propagates using valid file-sharing ports, such as TFTP and TCP port 135, which is the Microsoft RPC protocol, and Kerberos authentication (TCP port 4444). Blocking these ports can prevent its spread.
Example 17-7 shows a simple example of searching for the W32.Blaster Worm infection/attack, based on the network shown previously in Figure 17-1.
Example 17-7. Using NetFlow to Track Down the W32.Blaster Worms
Router# show ip cache flow | include 0087
SrcIf SrcIPaddress DstIf DstIPaddress Pr SrcP DstP Pkts
Et2 192.1.1.1 Et0 192.1.2.7 06 0B88 0087 1
Et2 192.1.1.1 Et0 192.1.2.9 06 0BF8 0087 1
Et2 192.1.1.1 Et0 192.1.2.23 06 0E80 0087 1
Et2 192.1.1.1 Et0 192.1.2.37 06 0CB0 0087 1
Et2 192.1.1.1 Et0 192.1.2.88 06 0C90 0087 1
Notice one interesting thing about the show command that I executed: You can use the vertical bar (|) and the include parameter to display only the results that match the string that you enter after this parameter. Port 0087, in hexadecimal, is 135 in decimal. To look for TFTP, use the hexadecimal number of 0045; for Kerberos authentication, use 115c.
In the previous output, notice that one device, 192.1.1.1, which is the DMZ web server, is scanning other internal devices using protocol 06 (TCP) with a DstP of 0087 (135?Microsoft RPC). With this information and the number of random port 135 connections it is trying to make to internal devices, you definitely should check out your web server.
TIP
Before beginning, you first should clear the NetFlow statistics and then continually examine the statistics to look for incrementing patterns. This is true for all DoS attacks.
Code Red Worm
At least three variations of the Code Red worm exist. All versions exploit a security vulnerability in the Microsoft IIS web server product by sending a specially formed URI to port 80 on a vulnerable system. Upon a successful attack, the worm replaces the web page of the IIS server with graffiti. In version 1 of the worm, an infected device did one of the following:
Scanned random IP addresses and passed the infection to other devices
Launched a DoS attack against 198.137.240.91, which used to be www.whitehouse.gov
One problem with the version 1 worm was that it did not use truly random addresses in its scan process; version 2 does. Version 2 also does not use the hard-coded IP address of the White House's web server; it uses a DNS name and does a DNS lookup to find the address. Both worms suffer the same deficiency: They do not check to see if the devices that they are scanning and trying to infect already are subverted.
Many Cisco products were affected by the amount of traffic that this worm generated. For example, the CSS 11000 content switches, under a heavy worm infestation, experienced memory-allocation errors that required them to be rebooted. Likewise, the 600 DSL routers stopped forwarding traffic until they also were rebooted. Cisco has introduced code fixes for all of its products that experienced problems dealing with this worm.
Because the worm uses a common port, detecting it is slightly more difficult. However, using NetFlow makes your task much easier. Because Code Red spreads itself by looking for vulnerabilities in IIS, you should examine NetFlow information and look for a TCP destination port of 80 (which is 0050 in hexadecimal). The network shown previously in Figure 17-1 illustrates this in Example 17-8.
Example 17-8. Using NetFlow to Track Down the Code Red Worms
Router# show ip cache flow | include 0050 SrcIf SrcIPaddress DstIf DstIPaddress Pr SrcP DstP Pkts Et2 192.1.1.1 Et0 192.1.2.3 06 0F9E 0050 1 Et2 192.1.1.1 Et0 192.1.2.9 06 0456 0050 2 Et2 192.1.1.1 Et0 192.1.2.21 06 3001 0050 2 Et2 192.1.1.1 Et0 192.1.2.37 06 B305 0050 1 Et2 192.1.1.1 Et0 192.1.2.38 06 0EEF 0050 1 Et2 192.1.1.1 Et0 192.1.2.88 06 0E75 0050 1 Et2 192.1.1.1 Et0 192.1.2.104 06 1134 0050 2
As you can see in this example, there are a few HTTP requests from the web server in the DMZ to internal addresses. If you see an abnormally high number of HTTP requests with the same source address, or if the source address is a web server itself, as is the case here, you have a problem. In this example, the DMZ web server has been attacked successfully and is attempting to spread itself to internal devices.
Smurf Attack
As mentioned throughout this book, the Smurf attack is one of the most common types of DoS attacks because of its simplicity in implementing it on a hacker's behalf. As with worms, you can use NetFlow to track the reflectors and possibly the source(s) of the attack. Example 17-9 shows an example, based on the network shown in Figure 17-1.
Example 17-9. Using NetFlow to Track Down Smurf Attacks
Router# show ip cache flow | include 0000 SrcIf SrcIPaddress DstIf DstIPaddress Pr SrcP DstP Pkts Et1 201.1.1.1 Et2 192.1.1.1 01 0000 0000 49K Et1 201.1.1.17 Et2 192.1.1.1 01 0000 0000 50K Et1 201.1.1.39 Et2 192.1.1.1 01 0000 0000 51K Et1 201.1.1.104 Et2 192.1.1.1 01 0000 0000 48K Et1 205.8.8.8 Et2 192.1.1.1 01 0000 0000 31K Et1 205.8.8.39 Et2 192.1.1.1 01 0000 0000 30K
As you can see in this example, two networks seem to be set up as reflectors, attacking the web server on the DMZ (192.1.1.1). Based on this information, you can contact your ISP and the administrators of these networks to take corrective action.
TIP
Besides using NetFlow for tracking down specific attacks, some people at Ohio State University have developed a quick-and-dirty set of tools that uses NetFlow records to detect network and host intrusions. More information about this nifty project can be found at http://www.usenix.org/publications/login/1999-9/osu.html.







