3.7 Technical Background
The following sections take a closer look at the design of eXist's indexing and storage architecture. We start with a brief discussion of conventional approaches to query execution and the problems they face when processing queries on large collections of XML documents. Second, we examine the numbering scheme used by eXist to identify nodes in index files. We then provide details on the concrete implementation of the storage and indexing components. Finally, we explain how the query engine uses the information collected in index files to process XPath expressions.
3.7.1 Approaches to Query Execution
XML query languages like XPath or XQuery use regular path expressions to navigate the logical structure of XML documents. Following a conventional approach, an XPath processor typically uses some kind of top-down or bottom-up tree traversal to evaluate regular path expressions. For example, the Open Source XPath engine Jaxen is based on a generalized tree-walking model, providing an abstraction for different APIs like DOM, DOM4J, or JDOM.
Despite the clean design supported by these tree-traversal based approaches, they become very inefficient for large document collections. For example, consider an XPath expression selecting all sections in a large collection of books whose title contains the string "XML":
/book//section[ contains(title, 'XML' )]
In a conventional top-down approach, the XPath processor has to follow every child path beginning at book to check for potential section descendants. This implies walking every element in the document tree below the document's root node book, because there is no way to determine the possible location of section descendants in advance.
While computing costs for traversing the document tree are acceptable as long as the document is completely contained in the machine's main memory, performance will suffer if the document's node tree has been stored in some persistent storage. A great number of nodes not being section elements have to be loaded just to test for their names and types. As a result, a lot of disk I/O is generated. Additionally, the whole procedure has to be repeated for every single document in the collection, which is unacceptable for very large collections.
Thus some kind of index structure is needed to efficiently process regular path expressions on large, unconstrained document collections. To speed up query execution, the query engine should be able to evaluate certain types of expressions just using the information provided in the index. Other types of expressions will still require a tree traversal, which is comparable to a full-table scan in a relational database system.
Consider a simple path expression like "//ACT/TITLE" to retrieve the titles for all acts in the play. To evaluate this expression, an indexing scheme should provide two major features: First, instead of traversing all elements in the document to find ACT elements, the query processor should be able to retrieve the location of all ACT and TITLE nodes in the document tree by a fast index lookup. This can be done, for example, by mapping element names to a list of references that point to the corresponding DOM nodes in the storage file.
However, knowing the position of potential ancestor and descendant nodes alone is not sufficient to determine the ancestor-descendant relationship between a pair of nodes. Thus, as a second requirement, the information contained in the index should support quick identification of relationships between nodes to resolve ancestor-descendant path steps.
3.7.2 Indexing Scheme
Several indexing schemes for XML documents have been proposed by recent research (Lee et al. 1996; Shin et al. 1998; Li and Moon 2001; Zhang et al. 2001). The approach taken by the eXist project has been inspired by these contributions. eXist's indexing system uses a numbering scheme to identify XML nodes and determine relationships between nodes in the document tree. A numbering scheme assigns numeric identifiers to each node in the document?for example, by traversing the document tree in level-order or pre-order. The generated identifiers are then used in indexes as references to the actual nodes. In eXist, all XML nodes are internally represented by a pair of document and node identifiers. Much of the query processing can be done by just using these two identifiers, which will be shown in the next section. Thus eXist will not load the actual DOM node unless it is really required to do so.
How does the numbering scheme work? For example, a numbering scheme might use the start and end position of a node in the document to identify nodes. Start and end positions might be defined by counting word numbers from the beginning of the document. A scheme based on this idea has been described in Zhang et al. (Zhang et al. 2001; see also Srivastava et al. 2002). According to this proposal, an element is identified by the 3-tuple (document ID, start position:end position, nesting level). Using these 3-tuples, ancestor-descendant relationships can be determined by the proposition: A node x with 3-tuple (D1, S1:E1, L1) is a descendant of a node y with 3-tuple (D2, S2: E2, L2) if and only if D1 = D2; S1 < S2 and E2 < E1. However, the 3-tuple identifiers generated by this numbering scheme consume a lot of space in the index.
eXist's indexing scheme has been inspired by another proposal, contributed by Lee et al. (Lee et al. 1996; see also Shin et al. 1998). It models the document tree as a complete k-ary tree, where k is equal to the maximum number of child nodes of an element in the tree structure. This implies that every nonleaf node in the tree is supposed to have exactly the same number of children. An identifier is assigned to each node by traversing the tree in level-order. For any node having less than k children, virtual child nodes are inserted to fill the gap. This means that some identifiers are wasted to balance the tree into a complete k-ary tree. Figure 3.2 shows the identifiers assigned to the nodes of a very simple XML document.
Figure 3.2. Level-Order Numbering Scheme
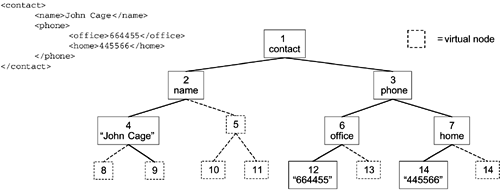
The generated identifier has a number of important properties: From a given identifier, we are always able to calculate the ID of its parent, sibling, and (possibly virtual) child nodes.
Implementing the corresponding W3C DOM methods for each node type is straightforward. For example, to get the parent of a given node, we simply calculate the parent identifier, which is then used to retrieve the actual parent node by an index lookup. All axes of navigation are supported as required by W3C DOM methods. This significantly reduces the storage size of a single node in the XML store: We don't need to store soft or hard links to parent, sibling, or child nodes with the DOM node object, because this information is implicitly contained in the generated identifier. Thus an element node will occupy between 4 and 8 bytes in eXist's XML node store?depending on the number of attributes.
Yet the completeness constraint imposes a major restriction on the maximum size of a document to be indexed. In practice, many documents contain more nodes in some distinct subtree of the document than in others. For example, a typical article will have a limited number of top-level elements like chapters and sections, while the majority of nodes consists of paragraphs and text nodes located below the top-level elements. In a worst case scenario, where a single node at some deeply structured level of the document node hierarchy has a maximum of child nodes, a large number of virtual nodes has to be inserted at all tree levels to satisfy the completeness constraint, so the assigned identifiers grow very fast even for small documents. For example, the identifiers generated by a complete 10-ary tree with height 10 will not fit into a 4-byte integer.
To overcome the limitations imposed by level-order numbering, we decided to partially drop the completeness constraint in favor of an alternating numbering scheme. The document is no longer viewed as a complete k-ary tree. Instead we recompute the number of children each node may have for every level of the tree and store this information in a simple array in the document object. Thus the completeness constraint is replaced by the following proposition:
For two nodes x and y of a tree, size(x) = size(y) if level(x) = level(y), where size(n) is the number of children of a node n and level(m) is the length of the path from the root node of the tree to m.
In other words, two nodes will have the same number of (possibly virtual) children if they are located on the same level of the tree. This approach accounts for the fact that typical documents will have a larger number of nodes at some lower level of the document tree while there are fewer elements at the top level of the hierarchy. Changing k at a deeper level of the node tree?for example, by inserting a new node?has no effect on nodes at higher levels. The document size limit is raised considerably to enable indexing of much larger documents. Figure 3.3 shows the numeric identifiers generated by eXist for the document used in Figure 3.2.
Figure 3.3. Alternating Level-Order Numbering Scheme
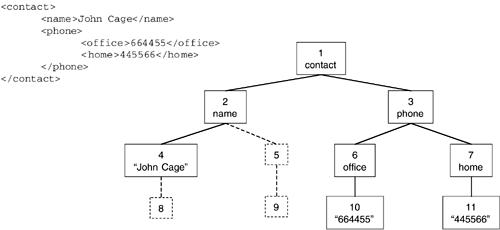
Using an alternating numbering scheme does not affect the general properties of identifiers as described previously: From a given identifier, we are still able to compute parent, sibling, or child node identifiers using the additional information on tree-level-arity stored in the document object.
To have enough spare IDs for worst case scenarios and later document updates, eXist uses 8-byte Java long integers for identifiers.
3.7.3 Index and Storage Implementation
Index organization might be compared to the traditional inverted index that represents a common data structure in many information retrieval systems. An inverted index is typically used to associate a word or phrase with the set of documents in which it has been found and the exact position where it occurred (Salton and McGill 1983).
Contrary to traditional information retrieval systems, an XML database needs to know the position and structure of nodes. Thus, instead of simply storing word positions, eXist uses the generated node identifiers to keep track of node occurrences. Additionally, to support the structured query facilities provided by XML query languages, different index structures are needed. Currently, eXist uses four index files at the core of the native XML storage backend:
dom.dbx collects DOM nodes in a paged file and associates node identifiers to the actual nodes.
collections.dbx manages the collection hierarchy.
elements.dbx indexes elements and attributes.
words.dbx keeps track of word occurrences and is used by the full-text search extensions.
Index implementation is quite straightforward. Basically, all indexes are based on B+-tree classes originally written by the former dbXML (now Xindice) project. To achieve better performance, many changes have been made to the original code?for example, to provide efficient page-buffering and locking mechanisms.
Node identifiers are mapped to the corresponding DOM nodes in the XML data store (dom.dbx). The XML data store represents the central component of eXist's native storage architecture. It consists of a single paged file in which all document nodes are stored according to the DOM. The data store is backed by a multiroot B+-tree in the same file to associate a node identifier to the node's storage address in the data section (see Figure 3.4). The storage address consists of the page number and the offset of the node inside the page. To save storage space, only top-level elements are added to the B+-tree. Other nodes are found by traversing the nearest available ancestor node.
Figure 3.4. XML Data Store Organization
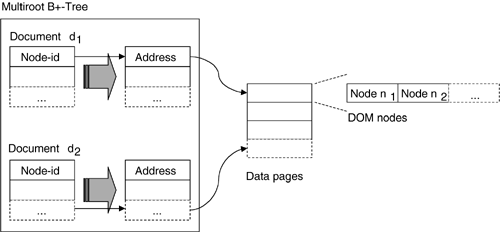
Ordered sequential access to the nodes in a document will speed up a number of tasks, such as serializing a document or fragment from the internal data model into its XML representation. Thus nodes are stored in document order. Additionally, the indexer tries to use subsequent physical data pages for all nodes belonging to the same document.
Only a single initial index lookup is required to serialize a document or document fragment. eXist's serializer will generate a stream of SAX events by sequentially walking nodes in document order, beginning at the fragment's root node. Thus any XML tool implementing SAX may be used to post-process the generated SAX stream?for example, to pretty-print the XML code or apply XSLT transformations on the server side.
The index file elements.dbx maps element and attribute names to node identifiers (see Figure 3.5). Each entry in the index consists of a key?being a pair of <collection id, name id>?and an array value containing an ordered list of document IDs and node IDs, which correspond to elements and attributes matching the qualified name in the key. To find, for example, all chapters in a collection of books, the query engine will need a single index lookup to retrieve the complete set of node IDs pointing to chapter elements.
Figure 3.5. Index Organization for Elements and Attributes
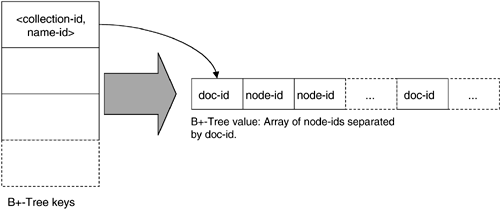
Organizing index entries by entire collections might seem inefficient at first sight. However, we have learned from earlier versions of eXist that using <document id, name id> pairs for keys leads to decreasing performance for collections containing a larger number (>5,000) of rather small (<50KB) documents. Filtering out those nodes that do not match the input document set for a query yields a much better overall performance. As a result, splitting large collections containing more than a few thousand documents into smaller subcollections is recommended.
Finally, the file words.dbx corresponds to a traditional inverted index as found in many IR (Information Retrieval) systems. By default, it indexes all text nodes and attribute values by tokenizing text into keywords. In words.dbx, the extracted keywords are mapped to an ordered list of document and node IDs. The file follows the same structure as elements.dbx, using <collection id, keyword> pairs for keys. Each entry in the ordered list points to the text or attribute node where the keyword occurred.
It is possible to exclude distinct parts of a given document type from full-text indexing or switch it off completely.
3.7.4 Query Language Processing
Given the index structures presented previously, we are able to access distinct nodes by their node IDs and retrieve a list of node identifiers for a given qualified node name or the set of text or attribute nodes containing a specified keyword. The DBBroker interface has method definitions for each of these tasks.
However, we have not yet explained how the query engine could use the provided methods to efficiently evaluate path expressions. eXist's query processor will first decompose a given regular path expression into a chain of basic steps. For example, the XPath expression /PLAY//SPEECH[ SPEAKER=' HAMLET' ] is logically split into subexpressions as shown in Figure 3.6.
Figure 3.6. Decomposition of Path Expression
![]()
To process the first subexpression, the query processor will load the root elements (PLAY) for all documents in the input document set. Second, the set of SPEECH elements is retrieved for the input documents via an index lookup from file elements.dbx. Now we have two node sets containing potential ancestors and descendants for each of the documents in question.
To find all nodes from the SPEECH node set being descendants of nodes in the PLAY node set, an ancestor-descendant path join algorithm is applied to the two sets. Several path join algorithms have been proposed by recent research (Li and Moon 2001; Srivastava et al. 2002; Zhang et al. 2001). eXist's algorithm differs from the proposed algorithms due to differences in the numbering schemes.
We will not discuss the algorithm in depth here. Basically, a node set in eXist is a list of <document id, node id> pairs, ordered by document ID and node ID. The algorithm takes the set of potential ancestor nodes and the set of descendant nodes as input. It recursively replaces all node identifiers in the descendant set with their parent's node ID and loops through the two sets to find equal pairs of nodes. If a matching pair is found, it is added to the resulting node set.
The result returned by the algorithm will become the context node set for the next subexpression in the chain. So the resulting node set for the expression PLAY//SPEECH becomes the ancestor node set for the expression SPEECH[SPEAKER], while the results generated by evaluating the predicate expression SPEAKER="HAMLET" represent the descendant node set.
To evaluate the subexpressions PLAY//SPEECH and SPEECH[SPEAKER], eXist does not need access to the actual DOM nodes in the XML store. Both expressions are entirely processed on the basis of the numeric identifiers provided in the index file. The path join algorithm determines ancestor-descendant relationships for all candidate nodes in all documents in one single step. Since node sets are implemented using simple Java arrays, execution times for the path join algorithm are very short. More than 90 percent of the overall query execution time is spent for index lookups.
Yet to process the equality operator in the predicate subexpression SPEAKER="HAMLET", the query engine will have to load the real DOM nodes from storage to determine their value and compare it to the literal string argument. Since a node's value may be distributed over many descendant nodes, the engine has to do a conventional tree traversal, beginning at the subexpression's context node (SPEAKER).
If we replace the equality operator with one of eXist's full-text operators or functions, the preceding query will perform a magnitude faster. For example, we may reformulate the query as follows:
/PLAY//SPEECH[ SPEAKER |= ' hamlet ghost' ]
Since the exact match query expression has been replaced by an expression based on keywords, the query engine is now able to use the inverted index to look up the keywords "hamlet" and "ghost" and obtains node identifiers for all text nodes containing the search term. Second, if there are multiple search terms, the retrieved node sets are merged by generating the union (for the &= operator and near function) or intersection set (for the |= operator). Finally, the resulting set of text nodes is joined with the context node set (SPEAKER) by applying an ancestor-descendant path join as explained previously. While the equality operator, as well as standard XPath functions like contains, requires eXist to perform a complete scan over the contents of every node in the context node set, the full-text search extensions rely entirely on information stored in the index.
Replacing exact match query expressions by equivalent expressions using full-text operators and functions will be easily possible for many queries addressing human users. For example, to find all items in a bibliographic database written by a certain author, we would typically use an XPath query like
//rdf:Description[ dc:creator="Heidegger, Martin"]
Query execution time will be relatively slow. However, it is very likely that a keyword-based query would find the same or even more true matches while being much faster. For the preceding query, we could replace the equality comparison by a call to the near function:
//rdf:Description[ near(dc:creator, "heidegger martin")]
3.7.5 Query Performance
Table 3.1 shows experimental results for a data set containing movie reviews. We compared overall query execution times for a query set using standard XPath expressions with corresponding queries using eXist's full-text query extensions. Both sets of queries were equivalent in that they will generate the same number of hits. Table 3.1 shows the standard XPath queries.
Additionally, we compared these results with those of another Open Source query engine (Jaxen, see http://www.jaxen.org), which is based on conventional tree traversals. For this experiment, Jaxen has been running on top of eXist's persistent DOM, using standard DOM methods for traversing the document tree.
The data set contained 39.15MB of raw XML data, distributed over 5,000 documents taken from a movie database. Document size varied from 500 bytes to 50KB. We formulated queries for randomly selected documents that might typically be of interest to potential users. The experiment was conducted on a PC with an AMD Athlon 4 processor with 1,400MHz and 256MB memory. Execution times for retrieving the actual results have not been included. They merely depend on the performance of eXist's serializer and are approximately the same for all tested approaches.
The results show that eXist's query engine outperforms the tree-traversal based approach by an order of magnitude. As expected, search expressions using the full-text index perform much better than corresponding queries based on standard XPath.
In a second experiment, the complete set of 5,000 documents was split into 10 subcollections, each containing 500 documents. To test the scalability of eXist, we added one more subcollection to the database for each test sequence and computed performance metrics for both sets of queries. Figure 3.7 shows average query execution times for eXist.
Figure 3.7. Average Query Execution Times by Source Data Size
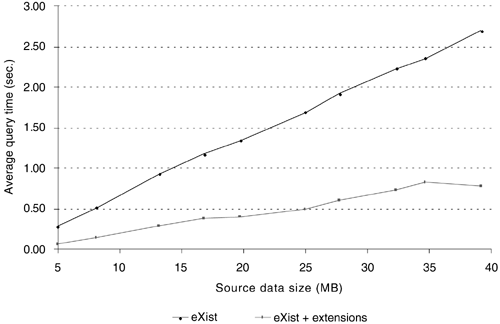
We observe that query execution times increase linearly with increasing source data size. This indicates the linear scalability of eXist's indexing, storage, and querying architecture.
| Top |







