8.4 Creating the Database
In order to store XML data in this fashion, we need tables that reflect the abstract structure of the DOM, with the added information required by the Nested Sets Model. We need one or more tables in which to store information about the node, such as its type, its x and y coordinates, any attributes, and its name (which may include a namespace) or its content (in the case of a text or CDATA node). We need to be mindful of the possible contents of each type of node; an element node will have a name and may have a namespace and/or a list of attributes (treated as name/value pairs), whereas a text leaf just has text content. Furthermore, since we want to build a repository for more than one document, we need a table to store some information about the documents (at the very least, a unique document ID), and rows in the node table will need to hold a reference to the document to which they belong (we could construct a multidocument repository as if it were one large XML document, comprising many smaller documents, but for many applications the overhead of maintaining the x, y coordinates would probably prove too costly).
8.4.1 The Physical Data Model
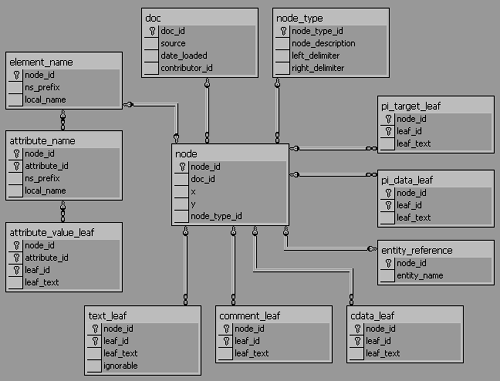
In this section we will walk through the database creation script create_xml-rep_db.sql. But before we begin, let's take a look at the physical data model shown in Figure 8.3. There are 12 tables in all; one (node_type) is a lookup table that defines the different types of nodes we will be storing. The remaining 11 tables will store information regarding the nodes, attributes, and leaves for each XML document we import. The x and y values (respectively, the left and right Nested Sets coordinates) for each node will be stored in the node table.
Figure 8.3. The Physical Data Model for the XML Repository
The first step in building the database tables is to create a new database called "xmlrep". Next, we need to create a login called "xmlrep_user" (we will use this later to connect to the repository). This is shown in Listing 8.2.
Listing 8.2 Create xmlrep_user
-- Create a login (arguments: user-id, password, default-db, language) IF NOT EXISTS (SELECT * FROM master.dbo.syslogins WHERE loginname = 'xmlrep_user') EXEC sp_addlogin 'xmlrep_user', 'fishcakes', 'xmlrep', 'British' GO -- Grant access for the user to this database EXEC sp_grantdbaccess 'xmlrep_user', 'xmlrep_user' GO
8.4.2 Creating User-Defined Data Types
Some user-defined data types will be useful, both for the tables and for the stored procedures we will create later to access them. (If we want to change the lengths of the various varchar fields, then this is our opportunity to do it.) This is shown in Listing 8.3.
Listing 8.3 Create User-Defined Types
EXEC sp_addtype 't_attribute_name', 'VARCHAR(50)', 'NOT NULL' EXEC sp_addtype 't_doc_id', 'NUMERIC(6,0)', 'NOT NULL' EXEC sp_addtype 't_element_name', 'VARCHAR(50)', 'NOT NULL' EXEC sp_addtype 't_entity_ref', 'VARCHAR(50)', 'NOT NULL' EXEC sp_addtype 't_leaf_id', 'TINYINT', 'NULL' EXEC sp_addtype 't_leaf_text', 'VARCHAR(255)', 'NULL' EXEC sp_addtype 't_node_type_id', 'TINYINT', 'NOT NULL' EXEC sp_addtype 't_node_id', 'NUMERIC(10,0)', 'NOT NULL' EXEC sp_addtype 't_ns_prefix', 'VARCHAR(25)', 'NOT NULL' EXEC sp_addtype 't_seq_no', 'TINYINT', 'NOT NULL' EXEC sp_addtype 't_source', 'VARCHAR(255)', 'NULL' EXEC sp_addtype 't_user_id', 'VARCHAR(50)', 'NULL' EXEC sp_addtype 't_xpath_maxlen', 'VARCHAR (1000)', 'NOT NULL' EXEC sp_addtype 't_xy_index', 'INT', 'NOT NULL' GO
8.4.3 Creating the Tables
As for the tables, let's start by creating the node_type lookup table and populate it with some data. The node_type table needs to contain the types of nodes that can appear, each of which has a numerical ID (node_type_id) and a human-readable description (node_description); the two remaining columns (left_delimiter and right_delimiter) store the characters that come before and after a node of the specified type (respectively); for example, a CDATA section starts with "<![CDATA[" and finishes with "]]>". The code is shown in Listing 8.4.
Listing 8.4 Create node_type Lookup Table
-- Create lookup table CREATE TABLE dbo.node_type ( node_type_id t_node_type_id NOT NULL, node_description VARCHAR(50) NOT NULL, left_delimiter VARCHAR(9) NOT NULL, right_delimiter VARCHAR(9) NOT NULL, CONSTRAINT PK_nt PRIMARY KEY CLUSTERED (node_type_id), CONSTRAINT IX_nt UNIQUE NONCLUSTERED (node_description)) GO -- Insert data INSERT INTO node_type VALUES (1, 'ELEMENT', '<', '>'); INSERT INTO node_type VALUES (3, 'TEXT_NODE', '', ''); INSERT INTO node_type VALUES (4, 'CDATA_SECTION_NODE', '<![CDATA[', ']]>'); INSERT INTO node_type VALUES (5, 'ENTITY_REFERENCE_NODE', '&', ';'); INSERT INTO node_type VALUES (7, 'PROCESSING_INSTRUCTION_NODE', '<?', '?>'); INSERT INTO node_type VALUES (8, 'COMMENT_NODE', '<!--', '-->'); INSERT INTO node_type VALUES (9, 'DOCUMENT_NODE', '', ''); GO
The doc table stores the unique doc_id and some metadata, the name of the source document (source), the date it was loaded (date_loaded), and a reference to the user who loaded it (contributor_id). This is shown in Listing 8.5.
Listing 8.5 Create doc Table
CREATE TABLE dbo.doc ( doc_id t_doc_id IDENTITY (1, 1) NOT NULL, source t_source NOT NULL, date_loaded DATETIME NOT NULL, contributor_id t_user_id NOT NULL, CONSTRAINT PK_d PRIMARY KEY CLUSTERED (doc_id)) GO
The node table (see Listing 8.6) will be the hub of most database activity?every node of every document stored in the repository will have an entry here. Each node will be assigned an arbitrary node_id (for performance reasons, this unique identity will be designated as the primary key for the table) and x and y coordinates. Each node will have a reference (doc_id) to the containing document and a type (node_type_id).
Why not make doc_id and x a combination primary key (since these two columns uniquely identify a node in a document)? Well, since many database management systems sort (or "cluster") data according to the primary key, we will be introducing a large overhead in managing this table (with resulting performance and data contention side effects) in the event that nodes are created, moved, or destroyed, since each of these activities could involve changes to the x coordinates of many nodes. The use of an arbitrary unique identifier (node_id, in this case) will allow nodes to be added and manipulated rapidly, without incurring the expense of resorting any entries (although there will be a performance hit from maintenance to the index IX_n).
Listing 8.6 Create node Table
CREATE TABLE dbo.node (
node_id t_node_id IDENTITY (1, 1) NOT NULL,
doc_id t_doc_id NOT NULL,
x t_xy_index NOT NULL,
y t_xy_index NULL,
node_type_id t_node_type_id NOT NULL,
CONSTRAINT PK_n PRIMARY KEY CLUSTERED (node_id),
CONSTRAINT IX_n UNIQUE NONCLUSTERED (doc_id, x),
CONSTRAINT FK_n_d FOREIGN KEY (doc_id)
REFERENCES dbo.doc (doc_id),
CONSTRAINT FK_n_nt FOREIGN KEY (node_type_id)
REFERENCES dbo.node_type (node_type_id))
GO
If a given node is an element, there will be an entry in the element_name table (see Listing 8.7), which again has node_id as its primary key. Each element may have a namespace prefix (ns_prefix) and will certainly have a name (local_name). In common with many of the other tables, the node_id column is a foreign key reference back to the node_id in the node table.
Listing 8.7 Create element_name Table
CREATE TABLE dbo.element_name (
node_id t_node_id NOT NULL,
ns_prefix t_ns_prefix NULL,
local_name t_element_name NOT NULL,
CONSTRAINT PK_en PRIMARY KEY CLUSTERED (node_id),
CONSTRAINT FK_en_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
The XML specification permits very long element names and namespace prefixes, which creates a problem for storage in some RDBMSs (in some systems, character fields are restricted to 255 characters). We could store these items as linked lists of text fields (indeed, we will use this technique later for handling text and CDATA), but for the purposes of this demonstration (and to make querying simpler), we will make a restriction on the lengths of these fields (their lengths are determined by the user types t_element_name and t_ns_prefix, respectively).
An element may have one or more attributes (e.g., <p align="center">, where p is the element name, align is an attribute name, and center is the value). In the DOM, an attribute is treated as a special type of node. However, since attributes are anchored to the containing element and have different properties to other nodes (e.g., we cannot have an element with two attributes of the same qualified name), we will not store attribute information in the node table. Attribute names are stored in the attribute_name table (see Listing 8.8); each entry is uniquely identified by the node_id of the containing element and an arbitrary attribute_id. The namespace prefix (if any) is stored in ns_prefix, and the name is stored in local_name.
Listing 8.8 Create attribute_name Table
CREATE TABLE dbo.attribute_name (
node_id t_node_id NOT NULL,
attribute_id t_seq_no NOT NULL,
ns_prefix t_ns_prefix NULL,
local_name t_attribute_name NOT NULL,
CONSTRAINT PK_an PRIMARY KEY CLUSTERED (node_id, attribute_id),
CONSTRAINT FK_ann_en FOREIGN KEY (node_id)
REFERENCES dbo.element_name (node_id))
GO
The attribute_value_leaf table (see Listing 8.9) follows the same pattern, but since attribute values are often long, we need to allow for any length. This can be achieved in some RDBMSs with a very long (or unbounded) varchar column, but since we want to make our solution as portable as possible, we can achieve the same effect by creating a list of finite length varchar fields.
Listing 8.9 Create attribute_value_leaf Table
CREATE TABLE dbo.attribute_value_leaf (
node_id t_node_id NOT NULL,
attribute_id t_seq_no NOT NULL,
leaf_id t_leaf_id NOT NULL,
leaf_text t_leaf_text NOT NULL,
CONSTRAINT PK_avl PRIMARY KEY CLUSTERED (node_id, attribute_id, leaf_id),
CONSTRAINT FK_avl_an FOREIGN KEY (node_id, attribute_id)
REFERENCES dbo.attribute_name (node_id, attribute_id))
GO
If the length of the attribute value exceeds the length of the leaf_text column, a new row is added for the overspill and given a sequential leaf_id, and so on, until the whole of the value has been accommodated. To rebuild the value, a query will have to select all rows from attribute_value_leaf for a given node_id and attribute_id, order them by leaf_id, and pass the result set back to a function that knits the leaves back together.
The contents of text nodes are stored in text_leaf (see Listing 8.10), again with a leaf_id to determine the sequence order of the chunks into which the content was split in the event that it was too large for the leaf_text column. Since some XML applications make the distinction between textual content that is ignorable (such as whitespace and carriage returns, that may have been included for readability) and that is not ignorable (anything else), we will have an ignorable column to store a flag to indicate this situation.
Listing 8.10 Create text_leaf Table
CREATE TABLE dbo.text_leaf (
node_id t_node_id NOT NULL,
leaf_id t_leaf_id NOT NULL,
leaf_text t_leaf_text NOT NULL,
ignorable BIT NOT NULL,
CONSTRAINT PK_tl PRIMARY KEY CLUSTERED (node_id, leaf_id),
CONSTRAINT FK_tl_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
Processing instructions consist of a reference to the target application followed by data, separated by whitespace. Since the target and the data may be long, we will store them with the same leafing mechanism, in pi_target_leaf and pi_data_leaf, respectively. These tables are shown in Listing 8.11.
Listing 8.11 Create pi_target_leaf and pi_data_leaf Tables
CREATE TABLE dbo.pi_target_leaf (
node_id t_node_id NOT NULL,
leaf_id t_leaf_id NOT NULL,
leaf_text t_leaf_text NOT NULL,
CONSTRAINT PK_pitl PRIMARY KEY CLUSTERED (node_id, leaf_id),
CONSTRAINT FK_pitl_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
CREATE TABLE dbo.pi_data_leaf (
node_id t_node_id NOT NULL,
leaf_id t_leaf_id NOT NULL,
leaf_text t_leaf_text NOT NULL,
CONSTRAINT PK_pidl PRIMARY KEY CLUSTERED (node_id, leaf_id),
CONSTRAINT FK_pidl_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
Entity references (unparsed) are generally short, so a simple entity_reference table?with just a node_id and leaf_text column?will suffice. This is shown in Listing 8.12.
Listing 8.12 Create entity_reference Table
CREATE TABLE dbo.entity_reference (
node_id t_node_id NOT NULL,
entity_name t_entity_ref NOT NULL,
CONSTRAINT PK_er PRIMARY KEY CLUSTERED (node_id),
CONSTRAINT FK_er_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
The remaining tables, comment_leaf (for XML comments) and cdata_leaf (for CDATA sections), will doubtless need to store large amounts of information, and hence we will revert to a leafing mechanism for these. These tables are shown in Listing 8.13.
Listing 8.13 Create comment_leaf and cdata_leaf Tables
CREATE TABLE dbo.comment_leaf (
node_id t_node_id NOT NULL,
leaf_id t_leaf_id NOT NULL,
leaf_text t_leaf_text NOT NULL,
CONSTRAINT PK_col PRIMARY KEY CLUSTERED (node_id, leaf_id),
CONSTRAINT FK_col_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
CREATE TABLE dbo.cdata_leaf (
node_id t_node_id NOT NULL,
leaf_id t_leaf_id NOT NULL,
leaf_text t_leaf_text NOT NULL,
CONSTRAINT PK_cdl PRIMARY KEY CLUSTERED (node_id, leaf_id),
CONSTRAINT FK_cdl_n FOREIGN KEY (node_id)
REFERENCES dbo.node (node_id))
GO
It will have become obvious that a number of assumptions and restrictions have been introduced (the reader is invited to make such changes as are necessary to meet their particular requirements). For documents with a large amount of mixed content, or with substantial CDATA sections, these last two tables shown in Listing 8.13 could have a text column instead of numerous varchar leaves. An RDBMS will store text as a linked list of (for example) 2K data pages, so some sort of optimization analysis is recommended.
Finally, we will need to set the permissions for the user, as shown in Listing 8.14.
Listing 8.14 Grant Permissions
-- Grant permissions to the repository user(s) GRANT SELECT ON node_type TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON attribute_name TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON attribute_value_leaf TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON cdata_leaf TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON comment_leaf TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON doc TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON element_name TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON entity_reference TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON node TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON pi_data_leaf TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON pi_target_leaf TO xmlrep_user GRANT SELECT, INSERT, UPDATE, DELETE ON text_leaf TO xmlrep_user GO
The stored procedures in Listing 8.15 will be useful for error checking later; they return the leaf size (the length of t_leaf_text), the maximum element name length (t_element_name), the maximum namespace prefix length (t_ns_prefix) and the maximum entity name length (t_entity_ref).
Listing 8.15 Stored Procedures for Error Checking
CREATE PROCEDURE dbo.leafSize AS SELECT length AS value FROM systypes WHERE name = 't_leaf_text' GO CREATE PROCEDURE dbo.elementNameLength AS SELECT length AS value FROM systypes WHERE name = 't_element_name' GO CREATE PROCEDURE dbo.nsPrefixLength AS SELECT length AS value FROM systypes WHERE name = 't_ns_prefix' GO CREATE PROCEDURE dbo.entityRefLength AS SELECT length AS value FROM systypes WHERE name = 't_entity_ref' GO GRANT EXECUTE ON dbo.leafSize TO xmlrep_user GRANT EXECUTE ON dbo.elementNameLength TO xmlrep_user GRANT EXECUTE ON dbo.nsPrefixLength TO xmlrep_user GRANT EXECUTE ON dbo.entityRefLength TO xmlrep_user GO
Time for a quick recap: Thus far, we have decided on a suitable database model, consisting of a DOM-style node tree in which the nodes are labeled according to the Nested Sets Model (to allow for easy navigation and retrieval). We have built the database, populated the lookup table, built some useful stored procedures, created a user, and set the permissions.
8.4.4 Serializing a Document out of the Repository
In order to reconstruct an XML file from this repository, we will need a stored procedure to pull all the data together from the tables. Essentially, this will involve a large union query over all the tables. This procedure also needs to include the bits of character data that delimit the various components of XML (for example, angle brackets around element names). We also need to ensure that everything is returned in the correct order (this involves a bit more effort than just sorting by values of x, as we will see). The procedure can take up to three arguments: the ID of the document, the x value of the node at which to start (allowing us to retrieve a fragment of the document rather than the whole; if this argument is not supplied, the procedure serializes the whole document), and an optional flag that will cause some additional attributes to be included for each element (the x and y coordinates, and the node_id). This is shown in Listing 8.16.
Listing 8.16 Create rep_serialise_nodes Procedure
CREATE PROCEDURE dbo.rep_serialise_nodes
@doc_id t_doc_id,
@start_x t_xy_index = 1,
@incl_xy BIT = 0
AS
BEGIN
-- Get the y coordinate of the start node
DECLARE @start_y t_xy_index
SELECT @start_y = y
FROM node
WHERE doc_id = @doc_id
AND x = @start_x
-- Get the x coordinate of the first element
-- (we may be starting with the document node)
DECLARE @first_el t_xy_index
SELECT @first_el = MIN(x)
FROM node
WHERE doc_id = @doc_id
AND node_type_id = 1
AND x >= @start_x
-- Rebuild the document:
-- Start with the left delimiter for the type of node
SELECT n.x AS seq_no_1,
1 AS seq_no_2,
0 AS seq_no_3,
0 AS seq_no_4,
0 AS seq_no_5,
t.left_delimiter AS parsed_text
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND t.left_delimiter > ''
AND n.x >= @start_x
AND n.x < @start_y
UNION
-- Element names (each prefixed with namespace reference, if any)
SELECT n.x, 2, 0, 0, 0, ISNULL(e.ns_prefix + ':', '') +
e.local_name
FROM element_name e,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = e.node_id
UNION
-- If user requested optional attributes, need to declare the 'xmlrep' namespace at the
 root element
SELECT n.x, 3, 0, 0, 1, ' xmlns:repository="http://www.rgedwards.com/" '
FROM node n
WHERE n.doc_id = @doc_id
AND n.x = @first_el
AND @incl_xy = 1
UNION
-- Optional attributes describing node coordinates (elements only)
SELECT n.x, 3, 0, 1, 1,
' ' + 'repository:x="' + CONVERT(VARCHAR(11), x)
+ '" repository:y="' + CONVERT(VARCHAR(11), n.y)
+ '" repository:nodeID="' + CONVERT(VARCHAR(11), n.node_id) + '"'
FROM node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_type_id = 1 -- ELEMENT
AND @incl_xy = 1
UNION
-- Attribute name (each prefixed with namespace reference, if any)
-- followed by equal sign and opening quote
SELECT n.x, 3, a.attribute_id, 1, 0,
' ' + ISNULL(a.ns_prefix + ':', '') + a.local_name + '="'
FROM attribute_name a,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = a.node_id
UNION
-- Attribute value
SELECT n.x, 3, a.attribute_id, 2, a.leaf_id, a.leaf_text
FROM attribute_value_leaf a,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = a.node_id
UNION
-- Closing quote after attribute value
SELECT n.x, 3, a.attribute_id, 3, 0, '"'
FROM attribute_name a,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = a.node_id
UNION
-- Text leaves
SELECT n.x, 4, 0, 0, x.leaf_id, x.leaf_text
FROM text_leaf x,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = x.node_id
UNION
-- Comment leaves
SELECT n.x, 5, 0, 0, c.leaf_id, c.leaf_text
FROM comment_leaf c,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = c.node_id
UNION
-- Processing instruction target leaves
SELECT n.x, 6, 0, 1, p.leaf_id, p.leaf_text
FROM pi_target_leaf p,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = p.node_id
UNION
-- Space after PI target leaves (if there are data leaves)
SELECT n.x, 6, 0, 2, p.leaf_id, ' '
FROM pi_data_leaf p,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND p.leaf_id = 1
AND n.node_id = p.node_id
UNION
-- Processing instruction data leaves
SELECT n.x, 6, 0, 3, p.leaf_id, p.leaf_text
FROM pi_data_leaf p,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = p.node_id
UNION
-- CDATA leaves
SELECT n.x, 7, 0, 0, c.leaf_id, c.leaf_text
FROM cdata_leaf c,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = c.node_id
UNION
-- Entity references
SELECT n.x, 8, 0, 0, 0, e.entity_name
FROM entity_reference e,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = e.node_id
UNION
-- Right delimiter
SELECT n.x, 9, 0, 0, 0, t.right_delimiter
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND t.right_delimiter > ''
AND n.x >= @start_x AND n.x < @start_y
UNION
-- Left braces for closing tags (elements only)
SELECT n.y, 10, 0, 0, 0, t.left_delimiter + '/'
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND n.node_type_id = 1 -- ELEMENT
AND t.left_delimiter > ''
AND n.x >= @start_x AND n.x < @start_y
UNION
-- Element name leaves
SELECT n.y, 10, 0, 3, 0,
ISNULL(e.ns_prefix + ':', '') + e.local_name
FROM node n,
element_name e
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = e.node_id
UNION
-- Right braces for closing tags (elements only)
SELECT n.y, 10, 0, 4, 0, t.right_delimiter
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND n.node_type_id = 1 -- ELEMENT
AND t.right_delimiter > ''
AND n.x >= @start_x AND n.x < @start_y
-- Correct order for concatenation
ORDER BY seq_no_1, seq_no_2, seq_no_3, seq_no_4, seq_no_5
END
GO
GRANT EXECUTE ON dbo.rep_serialise_nodes TO xmlrep_user
GO
root element
SELECT n.x, 3, 0, 0, 1, ' xmlns:repository="http://www.rgedwards.com/" '
FROM node n
WHERE n.doc_id = @doc_id
AND n.x = @first_el
AND @incl_xy = 1
UNION
-- Optional attributes describing node coordinates (elements only)
SELECT n.x, 3, 0, 1, 1,
' ' + 'repository:x="' + CONVERT(VARCHAR(11), x)
+ '" repository:y="' + CONVERT(VARCHAR(11), n.y)
+ '" repository:nodeID="' + CONVERT(VARCHAR(11), n.node_id) + '"'
FROM node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_type_id = 1 -- ELEMENT
AND @incl_xy = 1
UNION
-- Attribute name (each prefixed with namespace reference, if any)
-- followed by equal sign and opening quote
SELECT n.x, 3, a.attribute_id, 1, 0,
' ' + ISNULL(a.ns_prefix + ':', '') + a.local_name + '="'
FROM attribute_name a,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = a.node_id
UNION
-- Attribute value
SELECT n.x, 3, a.attribute_id, 2, a.leaf_id, a.leaf_text
FROM attribute_value_leaf a,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = a.node_id
UNION
-- Closing quote after attribute value
SELECT n.x, 3, a.attribute_id, 3, 0, '"'
FROM attribute_name a,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = a.node_id
UNION
-- Text leaves
SELECT n.x, 4, 0, 0, x.leaf_id, x.leaf_text
FROM text_leaf x,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = x.node_id
UNION
-- Comment leaves
SELECT n.x, 5, 0, 0, c.leaf_id, c.leaf_text
FROM comment_leaf c,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = c.node_id
UNION
-- Processing instruction target leaves
SELECT n.x, 6, 0, 1, p.leaf_id, p.leaf_text
FROM pi_target_leaf p,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = p.node_id
UNION
-- Space after PI target leaves (if there are data leaves)
SELECT n.x, 6, 0, 2, p.leaf_id, ' '
FROM pi_data_leaf p,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND p.leaf_id = 1
AND n.node_id = p.node_id
UNION
-- Processing instruction data leaves
SELECT n.x, 6, 0, 3, p.leaf_id, p.leaf_text
FROM pi_data_leaf p,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = p.node_id
UNION
-- CDATA leaves
SELECT n.x, 7, 0, 0, c.leaf_id, c.leaf_text
FROM cdata_leaf c,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = c.node_id
UNION
-- Entity references
SELECT n.x, 8, 0, 0, 0, e.entity_name
FROM entity_reference e,
node n
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = e.node_id
UNION
-- Right delimiter
SELECT n.x, 9, 0, 0, 0, t.right_delimiter
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND t.right_delimiter > ''
AND n.x >= @start_x AND n.x < @start_y
UNION
-- Left braces for closing tags (elements only)
SELECT n.y, 10, 0, 0, 0, t.left_delimiter + '/'
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND n.node_type_id = 1 -- ELEMENT
AND t.left_delimiter > ''
AND n.x >= @start_x AND n.x < @start_y
UNION
-- Element name leaves
SELECT n.y, 10, 0, 3, 0,
ISNULL(e.ns_prefix + ':', '') + e.local_name
FROM node n,
element_name e
WHERE n.doc_id = @doc_id
AND n.x >= @start_x AND n.x < @start_y
AND n.node_id = e.node_id
UNION
-- Right braces for closing tags (elements only)
SELECT n.y, 10, 0, 4, 0, t.right_delimiter
FROM node n,
node_type t
WHERE n.doc_id = @doc_id
AND n.node_type_id = t.node_type_id
AND n.node_type_id = 1 -- ELEMENT
AND t.right_delimiter > ''
AND n.x >= @start_x AND n.x < @start_y
-- Correct order for concatenation
ORDER BY seq_no_1, seq_no_2, seq_no_3, seq_no_4, seq_no_5
END
GO
GRANT EXECUTE ON dbo.rep_serialise_nodes TO xmlrep_user
GO
8.4.5 Building an XML Document Manually
As a test, consider the following XML document (hello-world.xml):
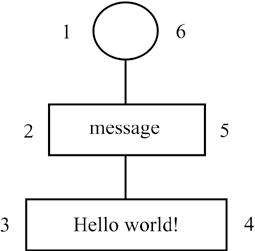
<message author="me">Hello world!</message>
A node tree representation for this document is shown in Figure 8.4; the unlabeled node at the top is the document node.
Figure 8.4. The "Hello world!" Example as a Node Tree
We can create this XML document manually in the repository as shown in Listing 8.17 (the script is in hello-world-xml.sql); later on we will create a Java class that will upload XML files automatically, but for now this will serve to illustrate the processes involved.
Listing 8.17 "Hello world!" Example
-- Declare some variables
DECLARE @doc_id t_doc_id
DECLARE @node_id t_node_id
-- Insert a row into the doc table and get the unique doc_id
INSERT INTO doc (contributor_id) VALUES ('your-name');
SELECT @doc_id = @@IDENTITY;
-- Create the document node (node type = 9)
INSERT INTO node (doc_id, x, y, node_type_id) VALUES (@doc_id, 1, 6, 9);
-- Create the node for the root element and get the unique node_id
INSERT INTO node (doc_id, x, y, node_type_id) VALUES (@doc_id, 2, 5, 1);
SELECT @node_id = @@IDENTITY;
-- Set the element name for the root element
INSERT INTO element_name (node_id, local_name) VALUES (@node_id, 'message');
-- Set the name and value for the attribute ('author') of the root element
INSERT INTO attribute_name (node_id, attribute_id, local_name) VALUES (@node_id, 1,
'author');
INSERT INTO attribute_value_leaf (node_id, attribute_id, leaf_id, leaf_text) VALUES (
@node_id, 1, 1, 'me');
-- Create the text node (node type = 3) and get the unique node_id
INSERT INTO node (doc_id, x, y, node_type_id) VALUES (@doc_id, 3, 4, 3);
SELECT @node_id = @@IDENTITY;
-- Create the text content
INSERT INTO text_leaf (node_id, leaf_id, leaf_text, ignorable) VALUES (@node_id, 1,
'Hello world!', 0);
If we execute the rep_serialise_nodes stored procedure for this laboriously hand-crafted document, we get the results shown in Listing 8.18.
Listing 8.18 Results from rep_serialise_nodes Procedure
seq_no_1 seq_no_2 seq_no_3 seq_no_4 seq_no_5 parsed_text -------- -------- -------- -------- -------- ------------ 2 1 0 0 0 < 2 2 0 0 0 message 2 3 1 1 0 author=" 2 3 1 2 1 me 2 3 1 3 0 " 2 9 0 0 0 > 3 4 0 0 1 Hello world! 5 10 0 0 0 </ 5 10 0 3 0 message 5 10 0 4 0 > (10 row(s) affected)
The sequence numbers can be discarded?they were there only to allow the procedure to sort the text items into the correct order?and the parsed_text column needs to be stitched back together (we will create a Java class to do this for us later), but this simple demonstration indicates the capabilities of the database we have created.
| Top |







