8.3 The Data Model
The data model we will use for the database tables is based loosely on the W3C's Document Object Model (DOM). Briefly put, the DOM represents an XML document as a node tree, with a top-level document node supporting a tree of nodes (representing elements) and leaves (representing text, CDATA, entity references, processing instructions, and comments). Like the DOM, our data model will need to support namespaces, must maintain the distinction between elements and attributes, and should be able to accommodate text and CDATA content of any length.
Listing 8.1 shows an example XML document (in this case a WML file designed to be displayed on a WAP-enabled mobile device), and Figure 8.1 shows the corresponding DOM; note that a document node is above the root element <wml>. For simplicity, attributes have not been shown in the diagram, text leaves are represented by a graphic, and whitespace (consisting of carriage returns and spaces for indentation) has been ignored.
Listing 8.1 Example XML Document
<?xml version="1.0"?> <wml> <card id="cFirst" title="First card" newcontext="true"> <p align="center"> <img src="/images/logo.wbmp" alt="Logo" align="middle"/> <br/> Content of the first card. </p> <p> <a href="#cSecond">Next card</a> </p> </card> <card id="cSecond" title="Second card"> <p align="center"> Content of the second card. </p> </card> </wml>
Figure 8.1. Example XML Document Represented as a Node Tree
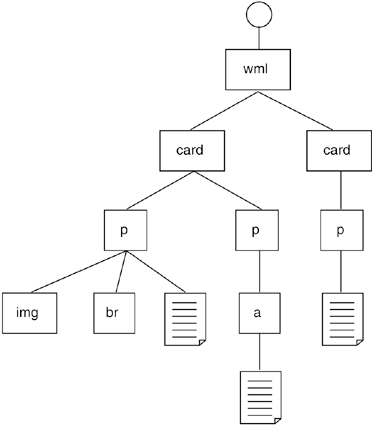
The W3C's DOM specifications (Levels 1, 2, and 3) detail the methods and interfaces that are required of a "DOM-compliant" application. These methods are largely concerned with the creation, querying, and manipulation of nodes, and the DOM provides a rich interface for interacting with XML document content.
Most DOM applications create DOM representations of XML documents in memory, which allows for rapid access but creates a limitation on the size of documents that may be considered; this problem becomes even more significant in a Web services environment in which multiple users or agents may be carrying out DOM manipulations simultaneously. Clearly, if an XML database can provide a DOM-compliant API, then the problem of memory limitations can be avoided almost entirely; despite the increased latency (since calls to DOM methods will require round trips to the database, rather than in-memory computations), this situation will be substantially more scalable as we consider large documents in multiuser environments. The system described in this chapter could easily be extended to provide full DOM compliance and hence provide a migration path for applications that are starting to feel the pinch of memory limitations.
8.3.1 DOM Storage in Relational Databases
So how can we create a DOM representation of an XML document in a relational database, and is it possible to do so in a way that will be able to offer reasonable performance? Since the DOM is a node tree, we can learn much from the SQL experts who have tackled the issue of storing trees in relational databases. The two most common approaches are known (in Joe Celko's terminology [Celko 2000]) as the Adjacency List Model and the Nested Sets Model. The former does not store child order?not a problem for some trees (such as a hierarchical view of the components of an electric toaster), but this model is clearly incompatible with XML, in which elements are ordered?we cannot arbitrarily change the order of paragraphs in an XHTML document, for example. Another problem of the Adjacency List Model is that it is costly to recreate the original tree, as it typically involves a recursive "walk" over the entire node set, since (typically) each node only knows about its parent.
8.3.2 The Nested Sets Model
Fortunately, the second approach, the Nested Sets Model, turns out to be an almost perfect match for XML; in fact, we might say that XML is an ideal serialization syntax for Nested Sets data. In the Nested Sets Model, each node is stored with two integer coordinates (we will call them x and y, representing left and right), which allow us to preserve order and a sense of location in the hierarchy. These coordinates are assigned at the time of storage (or creation) by walking the node tree from top-down and from left to right, numbering as we go. Figure 8.2 shows the previous node tree with the nodes numbered in accordance with the Nested Sets Model.
Figure 8.2. Sample Node Tree, with Nested Sets Coordinates
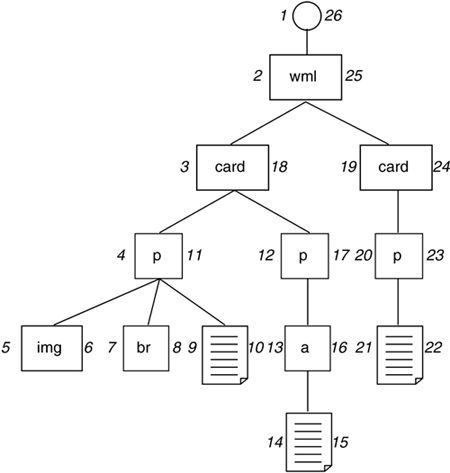
This two-coordinate system provides simple methods for navigation and structure elucidation, for example:
The next sibling (x', y') of any given node (x, y) has x' = y + 1.
The first child (x', y') of any given node (x, y) has x' = x + 1.
The descendant nodes (x', y') of a given node (x, y) have x , x' , y and x , y' , y.
The ancestor nodes (x', y') of a given node (x, y) have x' < x > y' and x' , y . y'.
The parent node of (x, y) has the largest x' in the set defined by x' , x . y'.
This labeling scheme clearly facilitates the rapid serialization of documents (or fragments thereof), at the expense of relabeling parts of the document when new nodes are added or shuffled around.
| Top |







