5.3 Current Architecture and Technology
This section contains general XML support architecture and technology/function in current and near term DB2 XML-enabled data management products. The section is organized so that common/shared function is covered first. Additional information integration function is covered later.
5.3.1 Shared Architecture and Technology
This section contains the shared architecture and technology of XML-related function provided in DB2 Universal Database and information integration offerings. The three key shared areas of function are the DB2 XML Extender, SQL/XML support, and Web service support.
XML data typically originates outside the DBMS (it can also be generated from within the database through composition functions) from a variety of locations including the file system, from a message system such as MQSeries or Web services, or from any other mechanism that will put XML data into memory. From there it is ingested into the database and stored in one of several ways, the principal ones are XML Column and XML Collection (described later in this chapter). Once stored in the database, applications can interact with the data using any combination of XML Extender-specific extensions to the DBMS or SQL/XML-standard extensions to the SQL language.
5.3.2 XML Extender Architecture
The focal point for much of IBM relational database XML function is the XML Extender. It provides the ability to store and access XML documents, to generate XML documents from existing relational data, and to insert rows into relational tables from XML documents. The XML Extender provides data types, functions, and stored procedures to manage XML data in DB2. The XML Extender is available for use with DB2 for z/OS and OS/390, DB2 for iSeries, and DB2 Universal Database for Linux, Unix, and Windows. The overall architecture of the XML Extender is shown in Figure 5.2.
Figure 5.2. XML Extender
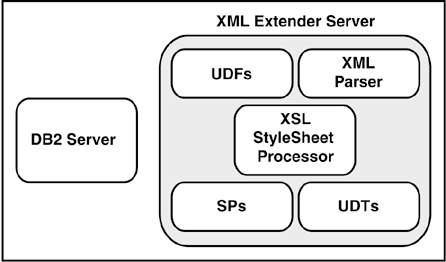
The XML Extender architecture provides
XML object storage and processing support for DB2 and information integration technology offerings.
XML application request support. XML Extender user-defined functions (UDFs) and user-defined types (UDTs) provide function for document access, indexing, shredding, searching, and processing.
XML documents can be stored in several ways. The storage options are shown in Figure 5.3.
Figure 5.3. XML Storage Options in DB2
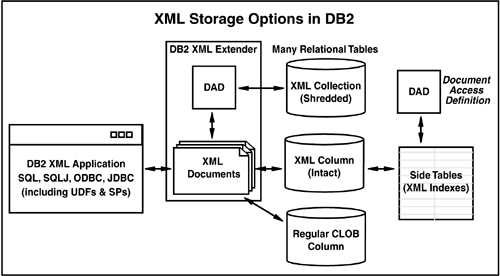
XML documents stored with the XML Extender can be stored intact in a relational column (XML Column support), stored as fragments (i.e., shredded) in a collection of tables (XML Collection), or stored as files linked from the DBMS (in that case, the database simply serves as an XML index and points to the external documents). You can also store XML documents as Character Large Objects (CLOBs).
Storing documents intact in XML Columns makes sense when the entire document must be maintained and be retrievable. It is also useful when update operations are minimal. Storing documents in a collection of tables (shredding) makes sense when fragments are subject to frequent update. Side tables are used for two reasons: as a method to improve performance for operations on XML column data and as a system for maintaining pointers to XML documents not stored in the data management system. Combinations of these approaches can also be used.
5.3.3 XML Extender Technology
The XML Extender architecture provides functional support for typical application requirements, such as storing, accessing, and retrieving XML data. Figure 5.4 provides an overview of data movement operations.
Figure 5.4. XML Column and XML Collection
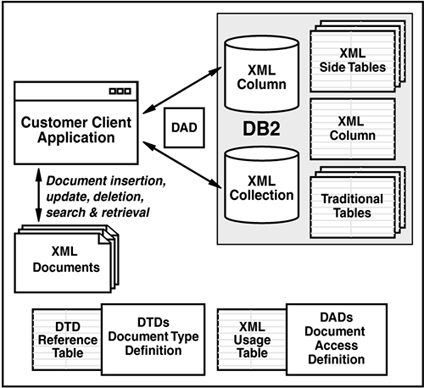
As stated earlier, the XML Extender offers two key storage models: XML Columns and XML Collections. Additional detail on related functions is provided below.
XML Columns
Storing XML data in relational columns is made possible through specific types and functions. The types are
XMLVarchar: Allows small XML documents to be stored as column data
XMLCLOB: Similar, but for large XML documents
XMLFile: A special type used to associate or link data in a relational column within the database to an XML document stored outside the database
From an application perspective, use of XML Columns is recommended when XML documents already exist and/or when there is a need to store XML documents in their entirety. XML data stored in XML Columns can be easily searched and updated. UDFs are supplied for operations on the element nodes in the XML documents. The XML Extender uses the XPath W3C recommendation for locating elements and attributes. The XML Columns approach is useful for documents frequently read but infrequently updated. This approach is also optimal when it is known which elements will be of interest because it is possible to replicate key elements to side tables to dramatically speed access to specific elements. An example is shown in Figure 5.5.
Figure 5.5. Side Table Example
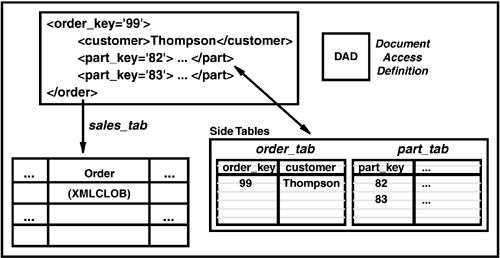
Data Access Definition (DAD) Files
A data access definition (DAD) file is used for both XML Column and XML Collection approaches to define the "mapping" between XML document elements/attributes and relational column data. A DAD file is used for column data when mapping from side tables to XML documents. It is also used for Collection data when composing or decomposing XML documents. Here is a quick example of an XML column DAD for storing an XML document:
<?xml version="1.0"?><!DOCTYPE DAD SYSTEM
"c:\dxx\dtd\dad.dtd"><DAD> <dtdid>Order.dtd</dtdid>
<validation>YES</validation> <Xcolumn>
<table name="order"><column name="customer_num"
type="Integer" path="/Order/Customer" multi_occurrence="NO">
</column></table></Xcolumn></DAD>
DAD files are also used for composing documents. One way to compose a document is to use an XML Collection SQL Node Mapping DAD. Listing 5.1 provides an example.
Listing 5.1 SQL Node Mapping
<?xml version="1.0"?>
<!DOCTYPE DAD SYSTEM "c:\dxx\dtd\dad.dtd">
<DAD>
<validation>NO</validation>
<Xcollection>
<SQL_stmt>select book_id, price_date, price_text from book_table ORDER BY book_id</
 SQL_stmt>
<prolog>?xml version="1.0"?</prolog>
<doctype>!DOCTYPE book SYSTEM "c:\dtd\book.dtd"</doctype>
<root_node>
<element_node name="book">
<attribute_node name="id">
<column name="book_id"/>
</attribute_node>
<element_node name="price">
<attribute_node name="date">
<column name="price_date"/>
</attribute_node>
<text_node><column name="price_text"/></text_node>
</element_node>
</element_node>
</root_node>
</Xcollection>
</DAD>
SQL_stmt>
<prolog>?xml version="1.0"?</prolog>
<doctype>!DOCTYPE book SYSTEM "c:\dtd\book.dtd"</doctype>
<root_node>
<element_node name="book">
<attribute_node name="id">
<column name="book_id"/>
</attribute_node>
<element_node name="price">
<attribute_node name="date">
<column name="price_date"/>
</attribute_node>
<text_node><column name="price_text"/></text_node>
</element_node>
</element_node>
</root_node>
</Xcollection>
</DAD>
The mapping information in the DAD file is used to define a map between an XML document and the data in Table 5.1. The hierarchical view of the map is shown in Figure 5.6.
Figure 5.6. Hierarchical View of Map
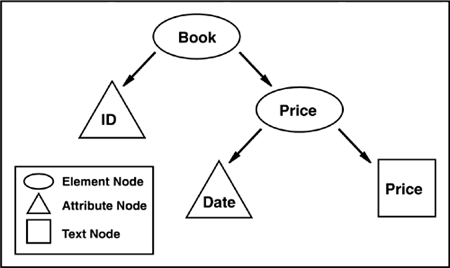
XML Collections
An XML collection approach is used when the goal is to break down documents into small relational table sets of untagged data or when it is necessary to generate XML documents from a particular set of relational column data. It is also useful when updates to small sections of documents (or small documents in their entirety) are required and when update performance is important. XML documents are composed from relational columns by using a DAD file to define the publishing map (relational to XML). You can use an SQL node DAD or an RDB node DAD to compose documents. Listing 5.2 provides an example of an RDB node DAD mapping document. It shows how to compose an XML document from a simple relational table (personal_table) that contains six columns.
Listing 5.2 RDB Node DAD
<?xml version="1.0"?>
<!DOCTYPE DAD SYSTEM "c:\dxx\dtd\dad.dtd">
<DAD>
<dtdid>personal_dtd</dtdid>
<validation>NO</validation>
<Xcollection>
<prolog>?xml version="1.0"?</prolog>
<doctype>!DOCTYPE personal SYSTEM "personal.dtd"</doctype>
<root_node>
<element_node name="personnel" multi_occurrence="NO" >
<RDB_node>
<table name="personal_table" />
</RDB_node>
<element_node name="person">
<attribute_node name ="id">
<RDB_node>
<table name="personal_table"/>
<column name="person_id" type="varchar(32)" />
</RDB_node>
</attribute_node>
<attribute_node name="contr">
<RDB_node>
<table name="personal_table"/>
<column name="person_contractor" type="varchar(32)" />
</RDB_node>
</attribute_node>
<attribute_node name="salary">
<RDB_node>
<table name="personal_table"/>
<column name="person_salary" type="varchar(32)" />
</RDB_node>
</attribute_node>
<element_node name="name">
<element_node name="family">
<text_node>
<RDB_node>
<table name="personal_table"/>
<column name="person_family" type="varchar(32)"/>
</RDB_node>
</text_node>
</element_node>
<element_node name="given">
<text_node>
<RDB_node>
<table name="personal_table"/>
<column name="person_given" type="varchar(32)"/>
</RDB_node>
</text_node>
</element_node>
</element_node>
<element_node name="email">
<text_node>
<RDB_node>
<table name="personal_table"/>
<column name="person_email" type="varchar(32)" />
</RDB_node>
</text_node>
</element_node>
</element_node>
</element_node>
</root_node>
</Xcollection>
</DAD>
5.3.4 Using Both XML Collections and XML Columns
Sometimes using both storage approaches makes sense. For example, consider an insurance claim. From a legal perspective, the entire document and each version of the document must be stored for recall upon demand. Additionally, a given document could have key fields and metadata that would be useful to query and in some cases update. For example, the current state of a claim (e.g., open, working, closed) will require updates. Additionally, an application developer might need to index the document using side tables so that document searches are completed quickly. Shredding the original claim document into smaller fragments could have value when you need to send a specific and consistent piece of the original document to drive follow-on business processes, such as claims follow-up, billing, analysis for fraud, and so on.
5.3.5 Transforming XML Data
The transformation is provided through XSL and XML Style Sheet Transformation (XSLT) support. The most common functional requirement is to publish SQL or shredded XML as displayed HTML or transformed XML suitable for Web services. The steps to do this are
Transform relational data to XML through use of a DAD file.
Transform XML to HTML or another XML dialect with an XSL style sheet.
A simple example is shown in Figure 5.7.
Figure 5.7. Transformation Example
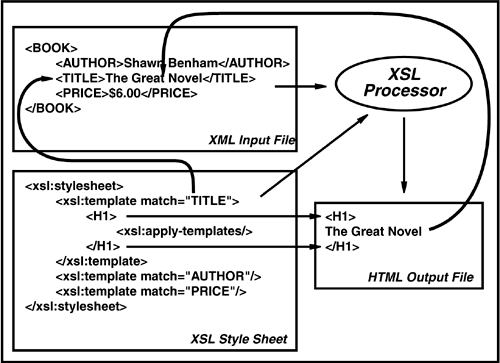
Regarding step 2, a common need is to take XML and transform it to an inter-company standard format (which is common when one company purchases another) to support enterprise application integration (EAI) requirements or external standard formats (for business-to-business applications). XSL is extremely powerful and allows for element restructure, element change, and the ability to generate new results from an existing XML data set. XSL transforms are supported with UDFs delivered with the XML Extender.
5.3.6 Searching, Parsing, and Validating XML Data
XPath statements are used to locate portions within an XML document. The XML Extender supports a subset of the XPath standard (for finding elements and attributes). You do not need another parser to go through a document to find specific information. There is a restriction: You must parse entire XML documents, not shredded documents.
The XML Extender also provides support for XML Schema and provides a UDF for validating XML documents with named schemas. This support can be used to verify documents built from previously shredded XML source or new XML documents built directly from relational data.
5.3.7 XML Extender Federated Support
The XML Extender supports federated environments. XML documents can be transparently composed from one or many data sources with a single SQL statement. With DB2, the DB2 family and Informix IDS data sources can be used for composing or decomposing XML documents. With additional information integration function, you can extend these capabilities to include non-DB2 data sources.
5.3.8 SQL/XML Support Architecture
DB2 SQL/XML support is of interest to developers familiar with SQL who are attempting to build new XML data applications or who want to extend existing SQL applications so that XML fragments can be requested from relational data. The data model purposely reflects current SQL application development models because many enterprise tools are designed for developing SQL applications and a great deal of SQL development expertise is in the data management community.
Initial work on the SQL/XML standard focused on publishing relational data in XML fragments suitable for standalone results or embedding in application generated XML documents. To generate the fragments, you use constructor functions. The functions provide considerable flexibility to the application developer, allowing a variety of ways to build the XML fragment. For example, you could use the XMLATTRIBUTES function to map columns to XML attributes. You would use the XMLAGG function to generate a sequence of XML values.
The implementation in DB2 is at a system function level?it is not a set of UDFs like the XML Extender. SQL/XML data generation and function are undertaken within the engine. Data source access and processing are pushed down when possible to the local database manager and can be pushed down to other DB2 database managers (e.g., distributed, z/OS, iSeries) when a federated query is executed. The overall architecture is shown in Figure 5.8.
Figure 5.8. SQL/XML Architecture
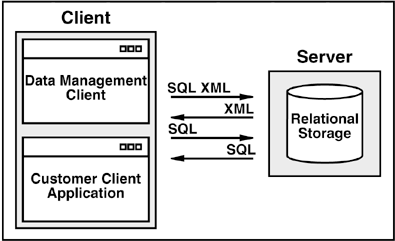
The output from SQL/XML queries is XML fragments. No schema is generated with the result set so validation of results must be done by the calling application (the results might be embedded into a larger document, and an existing schema could be used for validation). The current implementation relies on a new internal data type (XML).
SQL/XML functions are available for use over DB2 federated systems and can transparently generate XML from data stored in DB2, non-DB2 data sources (more on that later), and nonrelational data. Developers can expect
Compensation for data sources that don't provide capability to publish their data as XML documents
Pushdown support, whenever possible, for better performance, to data sources (such as DB2 for z/OS) that provide similar functionality
5.3.9 SQL/XML Support Technology
IBM SQL/XML support is provided just like any other SQL support as callable SQL/XML publishing functions. The statements are documented in the DB2 SQL Reference, but here are a few usage notes and examples:
XMLATTRIBUTES: Provides mapping from columns to attributes of an XML element.
XMLELEMENT: Provides mapping from columns to XML content. It can be used to generate nested elements.
XMLAGG: Used to generate a sequence of values. It is used most often in the context of a JOIN statement.
XML2CLOB: A mandatory statement that converts XML results into CLOB data. This is how the implementation ensures that the calling application can process the results.
The following section contains examples of SQL/XML statements. The examples are similar to those documented in the standards document (Melton 2002).
If you wanted to view a table (i.e., Table 5.2) as an XML fragment, you could use the SQL statement shown in Listing 5.3.
|
Name |
Dept |
Hire_Date |
|---|---|---|
|
John |
Shipping |
2001-10-10 |
|
Mark |
Accounting |
1999-04-01 |
Listing 5.3 SQL/XML Statement 1
SELECT XML2CLOB(XMLELEMENT(NAME "Employees",
XMLAGG(XMLELEMENT(NAME "Emp", XMLATTRIBUTES(name),
XMLELEMENT(NAME "Dept", Dept),
XMLELEMENT(NAME "Hire_date", Hire_date)))))
FROM employees
Listing 5.4 Result from SQL/XML Statement 1
<EMPLOYEES> <EMP NAME="John"> <DEPT>Shipping</DEPT> <HIRE_DATE>2001-10-10</HIRE_DATE> </EMP> <EMP NAME="MARK"> <DEPT>Accounting</DEPT> <HIRE_DATE>1999-04-01</HIRE_DATE> </EMP> </EMPLOYEES>
SQL/XML works well with information integration federated functionality. For example, customers can generate an XML fragment describing a customer where the information is stored in Oracle and DB2 tables. A sample set of statements and results could look like those shown in Listing 5.5.
Listing 5.5 SQL/XML Statement 2
SELECT XML2CLOB(XMLELEMENT(NAME "customer",
XMLATTRIBUTES(c.id),
XMLELEMENT(NAME "name", c.name),
XMLELEMENT(NAME "porders",
SELECT XMLAGG(XMLELEMENT(NAME "porder",
XMLATTRIBUTES(p.id, p.acctID as "acct"),
XMLELEMENT(NAME "date", p.date))
ORDER BY p.id)
FROM ora_purchaseOrder p WHERE p.custid = c.id))))
FROM db2_customer c
The output for Listing 5.5 could look like Listing 5.6.
Listing 5.6 Result from SQL/XML Statement 2
<CUSTOMER ID="C1"><NAME>John Doe </NAME>
<PORDERS>
<PORDER ID="P01" ACCT="A1">
<DATE>2001-10-10</DATE>
</PORDER>
<PORDER ID="P02" ACCT="A2">
<DATE>1991-11-17</DATE>
</PORDER>
</PORDERS>
</CUSTOMER>
Another way to use XMLELEMENT is shown in Listing 5.7, which contains nested results and an example of concatenated data. To produce an XML element named Emp for each employee, with nested elements for the employee's full name and the date the employee was hired, issue:
Listing 5.7 SQL/XML Statement 3
SELECT e.empno, varchar (XML2CLOB(XMLELEMENT(NAME "EMP",
XMLELEMENT(NAME "name", e.firstname CONCAT' 'CONCAT e.lastname),
XMLELEMENT(NAME "hiredate", e.hiredate))),82)
AS "result" FROM employee e
Listing 5.7 could produce the result shown in Listing 5.8.
Listing 5.8 SQL/XML Statement 3
000010 <EMP><NAME>CHRISTINE HAAS</NAME><HIREDATE>1965-01-01</HIREDATE></EMP> 000020 <EMP><NAME>MICHAEL THOMPSON</NAME><HIREDATE>1973-10-10</HIREDATE></EMP> 000030 <EMP><NAME>SALLY KWAN</NAME><HIREDATE>1975-04- 05</HIREDATE></EMP> 000050 <EMP><NAME>JOHN GEYER</NAME><HIREDATE>1949-08- 17</HIREDATE></EMP> 000060 <EMP><NAME>IRVING STERN</NAME><HIREDATE>1973-09- 14</HIREDATE></EMP> 000070 <EMP><NAME>EVA PULASKI</NAME><HIREDATE>1980-09- 30</HIREDATE></EMP> ...
In all cases, note the use of the XML2CLOB statement to convert generated or existing XML to a CLOB data type so that SQL applications can process it. Over time, expect the depreciation of the DB2 XML2CLOB statement as the SQL/XML standard progresses. Some final notes:
The implementation handles the mapping of SQL names to XML names.
Invalid characters (in the context of XML) are processed, ensuring that SQL identifiers are mapped cleanly to XML names.
5.3.10 Data Management Web Services Architecture
IBM provides an extremely flexible architecture and a large selection of products and downloadable tools for creating data management Web services. From a DB2 perspective, three general levels of complexity should be considered when defining how database Web services will be created and the tools and approaches that you will need:
Simple SQL statements executed on relational data in an existing DB2 database. If all you need is the ability to run a SELECT statement that returns a predictable result to successfully host a new or existing application as a Web service, the requirements are an existing relational database client/server infrastructure, network support, and a Web application server. You should also consider using the WORF (Web Services Object Runtime Framework) unless you want to hand-code the Web Services Description Language (WSDL) document, database access code, and so on.
Moderately complex operations. In this case, you should also make use of the WORF tools provided with DB2 and the WebSphere Studio Application Developer product. The WORF provides the ability to:
Consume DADX files. These files define a Web service using a set of operations that are defined by SQL statements and, optionally, DB2 XML Extender DAD files.
Generate WSDL documents.
Automatically generate test pages.
XML document or data-centric operations requiring access to XML Collections and/or SQL update operations on XML Columns. In this case, you should also use the DB2 XML Extender.
All three approaches can be used to support internal EAI and external (business-to-business?B2B, business-to-customer?B2C) Web service requests. If you were considering the XML document approach to Web services, the overall implementation architecture could look like Figure 5.9.
Figure 5.9. Web Services Architecture
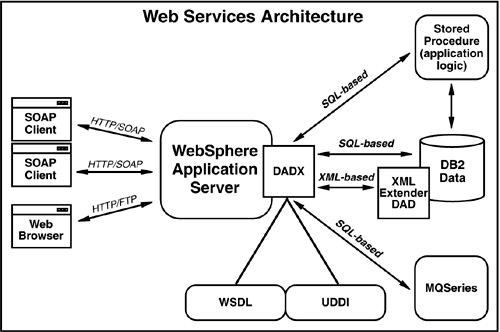
5.3.11 Data Management Web Services Technology
DADX file consumption and the generation of WSDL documents are the key technologies provided with the WORF and the focus area for defining a Web service that makes use of existing database application function. The starting point in the cycle is creating a DADX file that defines what a Web service can do and contains the statements that perform database operations. A simple DADX file is shown in Listing 5.9.
Listing 5.9 A Simple DADX File
<?xml version="1.0" encoding="UTF-8"?> <DADX xmlns="http://schemas.ibm.com/db2/dxx/dadx"> <operation name="somerandomSELECT"> <query> <SQL_query> SELECT * FROM newzoobabies </SQL_query> </query> </operation> </DADX>
In Listing 5.9, the file defines a Web service that on demand executes a query returning data from the relational table "newzoobabies" (perhaps indicating any new arrivals at the local zoo). In this case the returned data is tagged XML.
Web services, and DADX files, can be much more complex and be a part of large-scale B2C and B2B solutions involving complex operations that make use of more than one Web service. DADX files support runtime variable input as needed to better define a service or to make better reuse of services.
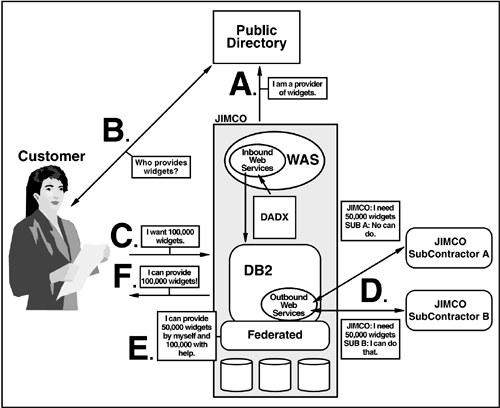
For example, consider a situation where a customer needs 100,000 widgets. The customer sends out a SOAP-based message with the above constraints to a public directory and finds an entry for the company JIMCO that is a provider of widgets. Next, the customer sends a request to JIMCO. This B2C situation is quite straightforward on the surface: JIMCO either has what is specified or not. But consider an extension of this scenario from the JIMCO perspective. Even if one company cannot meet the entire contract by itself, there are ways to get the work done?for example, if JIMCO has a defined set of relationships with subcontractors that can be dynamically called on demand as work peaks are experienced by JIMCO. The true goal, then, is to make sure JIMCO can not only query its own capacity to meet the customer needs, it can use a federated query to consider its own and subcontractor capacity at the same time and provide a unified statement of "can or cannot do" to the original customer. To accomplish the above, the application must support a combination of in-bound Web services and a federated query across local capacity information and defined subcontractor capacity information accessed with UDFs that call a defined set of B2B out-bound Web services. The overall view of this approach is shown in Figure 5.10.
Figure 5.10. JIMCO Example
Previously, you saw a DADX file containing a simple SQL query. The scenario after that DADX file described a more complex situation that would require even more SQL operations. DADX files, however, can also be used with the XML Extender?they are not limited to pure SQL and relational operations. DADX files can be used with XML Extender DAD files to generate or store XML documents. The following DADX file example shows one potential approach for generating an XML document.
Listing 5.10 DADX File for Use with XML Extender DAD File
<?xml version="1.0"?>
<DADX xmlns="http://schemas.ibm.com/db2/dxx/dadx"
xmlns="http://www.w3.org/2001/XMLSchema">
<wsdl:documentation
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns="http://www.w3.org/1999/xhtml">
Provides queries for part order information at myco.com.
See
<a href="../documentation/PartOrders.html"
target="_top">PartOrders.html</a>
for more information.
</wsdl:documentation>
<operation name="findAll">
<wsdl:documentation
xmlns="http://schemas.xmlsoap.org/wsdl/">
Returns all the orders with their complete details.
</wsdl:documentation>
<retrieveXML>
<DAD_ref>
getstart_xcollection.dad
</DAD_ref>
<no_override/>
</retrieveXML>
</operation>
</DADX>
This DADX references a specific operation, <retrieveXML> which is used to generate XML documents. Within that element, the <DAD_ref> element specifies the name of the DAD file that contains the mapping information required to generate the XML document.
5.3.12 Information Integration-Specific Architecture and Technology
This section covers the architecture and technology of XML-related database function specific to DB2 information integration technology. Information integration refers to the IBM technology infrastructure for integrating structured, semi-structured, and unstructured data. The primary topics for this section are heterogeneous federated data operations (mentioned previously in the SQL/XML section) and access and support for unstructured data sources.
Heterogeneous Federated Data Access and Application Support
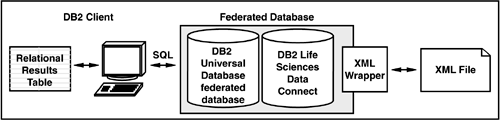
IBM federated functionality provides access to and powerful application support for XML, relational, and industry-specific (such as life sciences) data types. DB2 Universal Database for Linux, Unix, and Windows provides the overall federated base function set and access to DB2 family and Informix Dynamic Server data. IBM's information integration portfolio includes the base federation layer from DB2 and extends the data types you can access to include XML, other relational types (such as Oracle, Microsoft, and Sybase), and additional formats. Figure 5.11 shows the overall architecture from an XML perspective.
Figure 5.11. Overall Architecture for a Single Additional XML Data Source
The use of this technology in the context of XML ranges from:
Simple data access (use an XML wrapper, a defined data source connector and mapping structure, to enable relational engine access to XML data sources)
Complex distributed requests ranging across multiple data sources (one or more being XML, one or more being relational, one or more being something else, or a mix)
XML application support includes
Local joins of table data in multiple relational databases for use as real-time input to Web service definitions or data input.
Greatly enhanced SQL/XML query results gathered from local and remote (DB2 and other relational) data stores that result in a single XML fragment reflecting a single view of all accessible sources in a single unit of work. An example was included earlier in the SQL/XML section.
Business process integration support. For example, using XML, relational, and life sciences data source wrappers (BLAST, as an example) to support requests for the aggregation of results across data types (relational, multivendor) and special-purpose vertical industry data.
In addition to planned information integration product functionality, there are related program downloads of interest to XML application developers. For example, out on alphaworks (http://www.alphaworks.ibm.com/) there is a package called the XML Wrapper Generator. It helps integrate XML data sources. Specifically, the tool can load XML schema files and then graphically map the XML schema to a relational schema. Using the tool GUI, a developer can customize the map. Once the map is complete, the tool can automatically generate DDL statements (mentioned below) required to make the XML data source visible to a federated server. SQL queries can then be executed against the XML data source.
Setting up a database for federated operations involves the creation and definition of wrappers for each accessed type (CREATE WRAPPER), registering data servers (CREATE SERVER), and identifying data server tables (a combination of CREATE NICKNAME statements and potentially several CREATE FEDERATED VIEW statements where the view is a compilation of several nicknames that describe an XML document). For life sciences data, some additional steps are related to setting up access (BLAST data, for example, requires an active daemon executable to be available to handle requests for BLAST data).
Access and Support for Unstructured Data
Support for accessing and managing unstructured or partially structured data is a valuable component for both information integration and standard XML database applications. At an architectural level, the IBM Content Management and Enterprise Information Portal offerings (and planned functions) provide
Scalability to handle the massive amounts of data often required for collections of unstructured text, structured text, binary format, and semi-structured documents
Federated access to unstructured content
An integration services layer. From a technology perspective, the Enterprise Information Portal extends available text services to include:
Standard text operation (search, aggregate, workflow) support useful for extracting information from XML and unstructured text documents
Workflow support
Text mining support
The text mining services, for example, can crawl and organize large volumes of unstructured information. Mined text can be indexed, categorized, and summarized as needed for additional search and/or analysis. Results can be fed to structured data stores for additional analysis as part of generalized federated query analysis or directly staged feeds for use by EAI applications. In conjunction with the XML Extender, final results can be transformed to XML for use as externalized application feeds to drive B2B or B2C activity based on staged XML data flows between partners (WSDL, creation, for example) or to customers.
| Top |







