7.5 Providing Relational Views over XML
In many cases, data will be sent to the database server in the form of an XML message that needs to be integrated with the relational data after optionally performing some business logic over the data inside a stored procedure on the server. This requires programmatic access to the XML data from within a stored procedure. Unfortunately, neither the DOM nor SAX provides a well-suited surface API for dealing with XML data in a relational context. Instead the new API needs to provide a relational view over the XML data?that is, it needs to allow the SQL programmer to shred an XML message into different relational views.
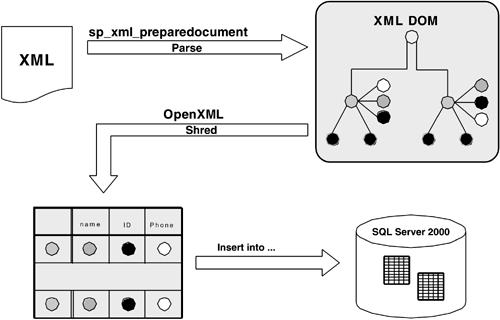
SQL Server 2000 provides such a rowset mechanism over XML by means of the OpenXML rowset provider (see Figure 7.3). OpenXML provides two kinds of rowset views over the XML data: the edge table view and the shredded rowset view. The edge table view provides the parent-child hierarchy and all the other relevant information of each node in the XML document in form of a self-referential rowset. The shredded rowset view utilizes an XPath expression (the row pattern) to identify the nodes in the XML document tree that will map to rows and uses a relative XPath expression (the column pattern) for identifying the nodes that provide the values for each column. The OpenXML rowset provider can appear anywhere in an SQL expression where a rowset can appear as a data source. In particular, it can appear in the FROM clause of any selection.
Figure 7.3. Open XML Processing Model
In order to have access to some of the implicit meta information in the tree such as hierarchy and sibling information, a column pattern can also be a so-called meta property of the node selected by the row pattern. Examples of such meta properties are @mp:id that provides the node ID (the namespace prefix mp binds to a namespace that is recognized by OpenXML as providing the meta properties), @mp:parentid that provides the node ID of the parent node, @mp:prev that provides the node ID of the previous sibling, and the special metaproperty @mp:xmltext that deals with unknown open content (the so-called overflow).
The following presents the syntax of the OpenXML rowset provider ([ ] denote optional parts, | denotes alternatives):
OpenXML(hdoc, RowPattern [, Flag] ) [ WITH SchemaDeclaration | TableName]
The hdoc parameter is a handle to the XML document that has been previously parsed with the built-in stored procedure sp_xml_preparedocument. RowPattern is any valid XPath expression that identifies the rows or, in case of the edge table view, the roots of the trees to be returned. The optional Flag parameter can be used to designate default attribute- or element-centric column patterns in the shredded rowset view. If the WITH clause is omitted, an edge table view is generated; otherwise, the explicitly specified schema declaration or the implicitly through TableName-given rowset schema is used to define the exposed structure of the shredded rowset view. A schema declaration has the following form:
(ColumnName1 ColumnType1 [ ColPattern1], ColumnName2 ColumnType2 [ ColPattern2], . . .)
The ColumnName provides the name of the column, ColumnType the relational datatype exposed by the rowset view, and ColumnPattern the optional column pattern (if no value is given, the default mapping indicated with the flag parameter is applied). Note that XML data types are automatically coerced to the indicated SQL data types.
For example, the T-SQL fragment in Listing 7.7 parses a hierarchical Customer-Order XML document and uses the rowset views to load the customer and order data into their corresponding relational tables.
Listing 7.7 T-SQL Fragment
create procedure Load_CustOrd (@xmldoc ntext)
as
declare @h int
-- Parse document
exec sp_xml_preparedocument @h output, @xmldoc
-- Load the Customer data, note the use of the attribute-centric
-- default mapping and the name of the table in the WITH clause
insert into Customers
select * from OpenXML(@h, '/loaddoc/Customer') with Customers
-- Load the Order data. Since we need to get the customer id from the
-- parent element, we need to give the explicit schema declaration and
-- use the element-centric default for the rest.
insert into Orders(OrderID, CustomerID, OrderDate)
select *
from OpenXML(@h, '/loaddoc/Customer/Order', 2)
with (
oid int,
customerid nvarchar(10) '../@CustomerID',
OrderDate datetime)
-- Remove the parsed document from the temp space
exec sp_xml_removedocument @h
go
-- Now load some data
exec Load_CustOrd N'<loaddoc>
<Customer CustomerID="NEWC1" ContactName="Joe Doe"
CompanyName="Foo Inc.">
<Order>
<oid>1</oid>
<OrderDate>2000-01-01T11:59:59</OrderDate>
</Order>
</Customer>
<Customer CustomerID="NEWC2" ContactName="Jane Doe"
CompanyName="Bar Inc.">
<Order>
<oid>2</oid>
<OrderDate>2000-12-31T11:59:59</OrderDate>
</Order>
<Order>
<oid>3</oid>
<OrderDate>2001-01-01T08:00:00</OrderDate>
</Order>
</Customer>
</loaddoc>'
One of the advantages of this rowset-oriented API for XML data is that it leverages the existing relational model for use with XML and provides a mechanism for updating a database with data in XML format. Utilizing XML in conjunction with OpenXML enables multirow updates with a single stored procedure call and multitable updates by exploiting the XML hierarchy. In addition, it allows the formulation of queries that join existing tables with the provided XML data.
One disadvantage is that it internally uses a materialized DOM representation and thus does not scale to large (more than 100KB) XML documents due to the memory requirements. Thus, for loading large XML documents, the bulk load facility described shortly should be used.
| Top |







