10.2 A Brief Molecular Biology Background
One does not have to delve deeply to appreciate the intricacies, complexity, and interrelatedness of biological systems. A good place to start for those who do not have a background in genetics and molecular biology is the free publication "Primer on Molecular Genetics" published June 1992 by the U.S. Department of Energy. This publication is available online at http://www.ornl.gov/hgmis/publicat/primer/toc.html. Two other Internet sources are http://www.ornl.gov/hgmis/publicat/primer/intro.html and http://www.ornl.gov/hgmis/toc_expand.html#alpha. (Much of the overview in this section is drawn from the "Primer on Molecular Genetics.")
Life uses a quaternary, as opposed to binary, system to encode the entire blueprint of every living organism on earth. This quaternary system is our DNA (deoxyribonucleic acid). Inside almost every cell of the trillions of cells that make up a human being lies a nucleus that contains 23 pairs of chromosomes. The chromosomes are made up of long strands of DNA. Figure 10.1 depicts the chromosomes and the familiar double helix DNA structure.
Figure 10.1. Chromosome and DNA Structure. Illustrated by James Direen.
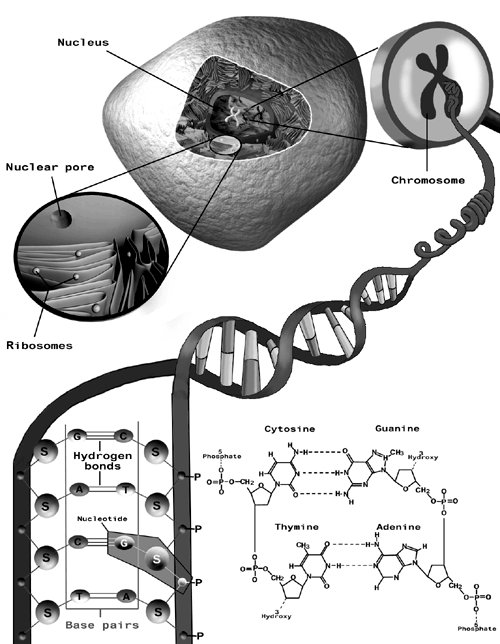
The complete set of instructions for making up an organism is called its genome. DNA is constructed from a set of four base molecules: Adenine (A), Cytosine (C), Guanine (G), and Thymine (T). This is our quaternary code. These molecules are attached to a deoxyribose sugar-phosphate backbone. A backbone section with one base molecule, A, C, G, or T, is called a nucleotide. A key thing to note is that base molecules are attached to each other; these are called base pairs. The A and T bases have a double hydrogen bond, and the C and G bases have a triple hydrogen bond. Because of the molecular sizes and the bond structure only an A and a T will mate across from each other on a DNA strand, and only a C and a G will mate with each other. Viewing one half of a DNA strand, we may have any order of A, C, G, and Ts. Information is contained in the ordering of the A, C, G, and T bases. The opposite side of the DNA will always consist of the complement base structure. The complementary structure is very important in cell division (mitosis) when the DNA must make a copy of itself to go with the new cell. The complementary structure is also used when the DNA code is read or transcribed in order to make proteins.
The quaternary code of DNA defines the structure of all the proteins made and used in a given organism. The central dogma of molecular genetics defines how proteins are made from the information contained in the DNA. A section of DNA that codes for a protein is called a gene. Of the over 3 billion base pairs that make up the human genome, only approximately 10 percent of the nucleotides is code for proteins. The function of the other 90 percent of the DNA is in question at this time. The 10 percent of the DNA that codes for proteins is broken up into 30,000 to 40,000 genes. The exact number of genes, location of the genes, and function of the genes in the human genetic code are still hot areas of research.
Proteins are very large molecules or polypeptides made up of long chains of building blocks called amino acids. Twenty different amino acids are used in the construction of proteins. Proteins are used in almost every aspect of a living organism.
Life is a chemical process involving thousands of different reactions occurring in an organized manner. These reactions are called metabolic reactions and almost all of them are catalyzed by enzymes. Enzymes are proteins that are used to catalyze chemical reactions in our bodies. There are complex molecular machines made up of large protein complexes within cells. DNA polymerase, used to read or transcribe the DNA, is an example of a molecular machine. Ribosomes are another example of molecular machines; they are used in the process of making proteins. Proteins are also used in the chemical signaling processes in the body. Hormones such as insulin are utilized in chemical signaling. Insulin is a protein that controls the sugar or glucose usage in our bodies. Proteins are used as basic structural building blocks such as collagen fibres used in tendons or alpha-keratin in hair. The point is, wherever we look within a living organism, proteins are involved.
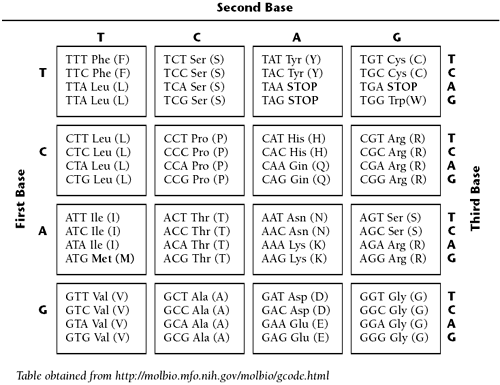
There are 20 amino acids from which to choose to make up the long chains that result in proteins. The DNA contains the code to define the sequence of amino acids that make up a given protein. It takes three nucleotides to code for one amino acid. Two nucleotides would only code for 42 or 16 possible things. Three nucleotides would code for 43 or 64 possible things, and since there are only 20 amino acids, there is redundancy in the coding. Each group of three nucleotides is called a codon.
Table 10.1 is the Genetic Code Table. It maps each codon to its corresponding amino acid. The amino acids are shown with both their three-letter abbreviation and their single-letter abbreviation. For instance, the codon ATG maps to the amino acid Methionine, Met or M.
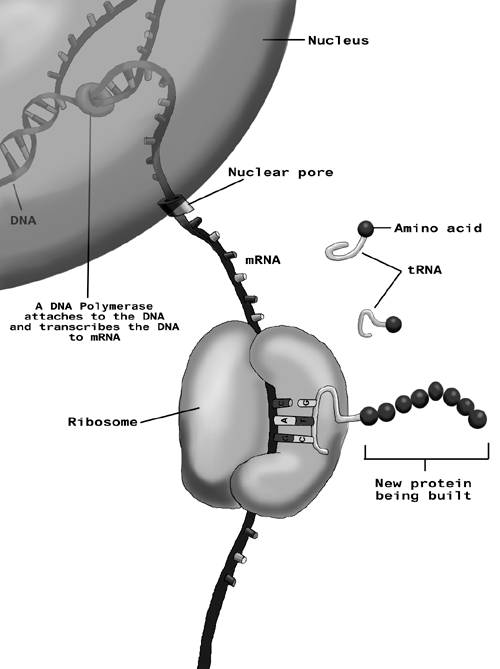
To make proteins from DNA instructions, there is an intermediate messenger RNA (ribonucleic acid). The mRNA is created by a process called transcription when a particular gene is being expressed. DNA polymerase is involved in this transcription process. The mRNA then moves out of the nucleus of the cell into the cytoplasm. Ribosomes attach to the mRNA and are responsible for building proteins from the information contained in the mRNA. This process is called translation; the mRNA is translated into amino acid sequences. Transfer RNA (tRNA) in the cell are responsible for bringing the correct amino acid to the ribosome for building the proteins.
As can be seen from the diagram in Figure 10.2, the tRNA have a complementary anti-codon that matches a section of the mRNA. Start and stop codons help get the translation process started and terminated.
Figure 10.2. DNA to Proteins. Illustrated by James Direen.
Hopefully the information in this section has given the reader enough basic molecular biology to make the rest of this chapter more intelligible. It is also hoped that this little snippet of biology entices one to delve deeper into this fascinating and rapidly growing field.
Table 10.1. Genetic Code Table
| Top |







