18.4 Benchmark Queries
In creating the data set above, we make it possible to tease apart data with different characteristics and to issue queries with well-controlled yet vastly differing data access patterns. We are more interested in evaluating the cost of individual pieces of core query functionality than in evaluating the composite performance of application-level queries. Knowing the costs of individual basic operations, we can estimate the cost of any complex query by just adding up relevant piecewise costs (keeping in mind the pipelined nature of evaluation, and the changes in sizes of intermediate results when operators are pipelined).
One clean way to decompose complex queries is by means of algebra. While the benchmark is not tied to any particular algebra, we find it useful to refer to queries as "selection queries," "join queries," and the like, to clearly indicate the functionality of each query. A complex query that involves many of these simple operations can take time that varies monotonically with the time required for these simple components.
In the following sections, we describe each of these different types of queries in detail. In these queries, the types of the nodes are assumed to be BaseType (eNest nodes) unless specified otherwise.
18.4.1 Selection
Relational selection identifies the tuples that satisfy a given predicate over its attri-butes. XML selection is both more complex and more important because of the tree structure. Consider a query, against a popular bibliographic database, that seeks books, published in the year 2002, by an author with name including the string "Bernstein". This apparently straightforward selection query involves matches in the database to a four-node "query pattern," with predicates associated with each of these four (namely book, year, author, and name). Once a match has been found for this pattern, we may be interested in returning only the book element, all the nodes that participated in the match, or various other possibilities. We attempt to orga-nize the various sources of complexity in the following sections.
Returned Structure
In a relation, once a tuple is selected, the tuple is returned. In XML, as we saw in the example above, once an element is selected, one may return the element, as well as some structure related to the element, such as the subtree rooted at the element. Query performance can be significantly affected by how the data are stored and when the returned result is materialized.
To understand the role of returned structure in query performance, we use the query, selecting all elements with aSixtyFour = 2. The selectivity of this query is 1/64 (1.6%).
This query is run in the following cases:
QR1: Return only the elements in question, not including any subelements
QR2: Return the elements and all their immediate children
QR3: Return the entire subtree rooted at the elements
QR4: Return the elements and their selected descendants with aFour = 1
The remaining queries in the benchmark simply return the unique identifier attributes of the selected nodes (aUnique1 for eNest and aRef for eOccasional), except when explicitly specified otherwise. This design choice ensures that the cost of producing the final result is a small portion of the query execution cost.
Simple Selection
Even XML queries involving only one element and a single predicate can show considerable diversity. We examine the effect of this single selection predicate in this set of queries.
Exact Match Attribute Value Selection
Selection based on the value of a string attribute.
QS1. Low selectivity: Select nodes with aString = "Sing a song of oneB4". Selectivity is 0.8%.
QS2. High selectivity: Select nodes with aString = "Sing a song of oneB1". Selectivity is 6.3%.
Selection based on the value of an integer attribute.
We reproduce the same selectivities as in the string attribute case.
QS3. Low selectivity: Select nodes with aLevel = 10. Selectivity is 0.7%.
QS4. High selectivity: Select nodes with aLevel = 13. Selectivity is 6.0%.
Selection on range values.
QS5: Select nodes with aSixtyFour between 5 and 8. Selectivity is 6.3%.
Selection with sorting.
QS6: Select nodes with aLevel = 13 and have the returned nodes sorted by aSixtyFour attribute. Selectivity is 6.0%.
Multiple-attribute selection.
QS7: Select nodes with attributes aSixteen = 1 and aFour = 1. Selectivity is 1.6%.
Element Name Selection
QS8: Select nodes with the element name eOccasional. Selectivity is 1.6%.
Order-Based Selection
QS9: Select the second child of every node with aLevel = 7. Selectivity is 0.4%.
QS10: Select the second child of every node with aLevel = 9. Selectivity is 0.4%.
Since the fraction of nodes in these two queries is the same, the performance difference between queries QS9 and QS10 is likely to be on account of fanout.
Element Content Selection
QS11: Select OccasionalType nodes that have "oneB4" in the element content. Selectivity is 0.2%.
QS12: Select nodes that have "oneB4" as a substring of element content. Selectivity is 12.5%.
String Distance Selection
QS13. Low selectivity: Select all nodes with element content that the distance between keyword"oneB5" and keyword "twenty" is not more than four. Selectivity is 0.8%.
QS14. High selectivity: Select all nodes with element content that the distance between keyword "oneB2" and keyword "twenty" is not more than four. Selectivity is 6.3%.
Structural Selection
Selection in XML is often based on patterns. Queries should be constructed to consider multinode patterns of various sorts and selectivities. These patterns often have "conditional selectivity." Consider a simple two-node selection pattern. Given that one of the nodes has been identified, the selectivity of the second node in the pattern can differ from its selectivity in the database as a whole. Similar dependencies between different attributes in a relation could exist, thereby affecting the selectivity of a multiattribute predicate. Conditional selectivity is complicated in XML because different attributes may not be in the same element, but rather in different elements that are structurally related.
In this section, all queries return only the root of the selection pattern, unless otherwise specified.
Parent-Child Selection
QS15. Medium selectivity of both parent and child: Select nodes with aLevel = 13 that have a child with aSixteen = 3. Selectivity is approximately 0.7%.
QS16. High selectivity of parent and low selectivity of child: Select nodes with aLevel = 15 that have a child with aSixtyFour = 3. Selectivity is approximately 0.7%.
QS17. Low selectivity of parent and high selectivity of child: Select nodes with aLevel = 11 that have a child with aFour = 3. Selectivity is approximately 0.7%.
Order-Sensitive Parent-Child Selection
QS18. Local ordering: Select the second element below each element with aFour = 1 if that second element also has aFour = 1. Selectivity is 3.1%.
QS19. Global ordering: Select the second element with aFour = 1 below any element with aSixtyFour = 1. This query returns at most one element, whereas the previous query returns one for each parent.
QS20. Reverse ordering: Among the children with aSixteen = 1 of the parent element with aLevel = 13, select the last child. Selectivity is 0.7%.
Ancestor-Descendant Selection
QS21. Medium selectivity of both ancestor and descendant: Select nodes with aLevel = 13 that have a descendant with aSixteen = 3. Selectivity is 3.5%.
QS22. High selectivity of ancestor and low selectivity of descendant: Select nodes with aLevel = 15 that have a descendant with aSixtyFour = 3.Selectivity is 0.7%.
QS23. Low selectivity of ancestor and high selectivity of descendant: Select nodes with aLevel = 11 that have a descendant with aFour = 3. Selectivity is 1.5%.
Ancestor Nesting in Ancestor-Descendant Selection
In the ancestor-descendant queries above (QS21?QS23), ancestors are never nested below other ancestors. To test the performance of queries when ancestors are recursively nested below other ancestors, we have three other ancestor-descendant queries. These queries are variants of QS21?QS23.
QS24. Medium selectivity of both ancestor and descendant: Select nodes with aSixteen = 3 that have a descendant with aSixteen = 5.
QS25. High selectivity of ancestor and low selectivity of descendant: Select nodes with aFour = 3 that have a descendant with aSixtyFour = 3.
QS26. Low selectivity of ancestor and high selectivity of descendant: Select nodes with aSixtyFour = 9 that have a descendant with aFour = 3.
The overall selectivities of these queries (QS24?QS26) cannot be the same as that of the "equivalent" unnested queries (QS21?QS23) for two situations. First, the same descendants can now have multiple ancestors they match, and second, the number of candidate descendants is different (fewer) since the ancestor predicate can be satisfied by nodes at any level. These two situations may not necessarily cancel each other out. We focus on the local predicate selectivities and keep these the same for all of these queries (as well as for the parent-child queries considered before).
QS27: Similar to query QS26, but return both the root node and the descendant node of the selection pattern. Thus, the returned structure is a pair of nodes with an inclusion relationship between them.
Complex Pattern Selection
Complex pattern matches are common in XML databases, and in this section, we introduce a number of chain and twig queries that we use in this benchmark. Figure 18.1 shows an example of each of these types of queries.
Figure 18.1. Samples of Chain and Twig Queries
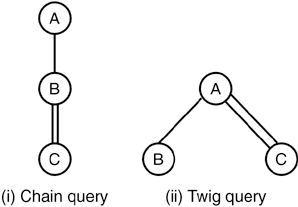
In the figure, each node represents a predicate such as an element tag name predicate, an attribute value predicate, or an element content match predicate. A structural parent-child relationship in the query is shown by a single line, and an ancestor-descendant relationship is represented by a double-edged line. The chain query shown in (i) finds all nodes that match the condition A, such that there is a child node that matches the condition B, such that some descendant of the child node matches the condition C. The twig query shown in (ii) matches all nodes that satisfy the condition A, and have a child node that satisfies the condition B, and also has a descendant node that satisfies the condition C.
We use the following complex queries in our benchmark.
Parent-Child Complex Pattern Selection
QS28. One chain query with three parent-child joins with the selectivity pattern: high-low-low-high: The query is to test the choice of join order in evaluating a complex query. To achieve the desired selectivities, we use the following predicates: aFour = 3, aSixteen = 3, aSixteen = 5, and aLevel = 16.
QS29. One twig query with two parent-child selection (low-high, low-low): Select parent nodes with aLevel = 11 (low selectivity) that have a child with aFour = 3 (high selectivity) and another child with aSixtyFour = 3 (low selectivity).
QS30. One twig query with two parent-child selection (high-low, high-low): Select parent nodes with aFour = 1 (high selectivity) that have a child with aLevel = 11 (low selectivity) and another child with aSixtyFour = 3 (low selectivity).
Ancestor-Descendant Complex Pattern Selection
QS31?QS33: Repeat queries QS28?QS30 but using ancestor-descendant in place of parent-child.
QS34. One twig query with one parent-child selection and one ancestor-descendant selection: Select nodes with aFour = 1 that have a child of nodes with aLevel = 11 and a descendant with aSixtyFour = 3.
Negated Selection
QS35: Find all BaseType elements below which do not contain an OccasionalType element.
18.4.2 Value-Based Join
A value-based join involves comparing values at two different nodes that need not be related structurally. In computing the value-based joins, one would naturally expect both nodes participating in the join to be returned. As such, the return structure is a tree per join-pair. Each tree has a join-node as the root, and two children, one corresponding to each element participating in the join.
QJ1. Low selectivity: Select nodes with aSixtyFour = 2 and join with themselves based on the equality of aUnique1 attribute. The selectivity of this query is approximately 1.6%.
QJ2. High selectivity: Select nodes based on aSixteen = 2 and join with themselves based on the equality of aUnique1 attribute. The selectivity of this query is approximately 6.3%.
18.4.3 Pointer-Based Join
The difference between these following queries and the join queries based on values QJ1?QJ2 is that references that can be specified in the DTD or XML Schema may be optimized with logical OIDs in some XML databases.
QJ3. Low selectivity: Select all OccasionalType nodes that point to a node with aSixtyFour = 3. Selectivity is 0.02%.
QJ4. High selectivity: Select all OccasionalType nodes that point to a node with aFour = 3. Selectivity is 0.4%.
Both of these pointer-based joins are semi-join queries. The returned elements are only the eOccasional nodes, not the nodes pointed to.
18.4.4 Aggregation
Aggregate queries are very important for data-warehousing applications. In XML, aggregation also has richer possibilities due to the structure. These are explored in the next set of queries.
QA1. Value aggregation: Compute the average value for the aSixtyFour attribute of all nodes at level 15. Note that about 1/4 of all nodes are at level 15. The number of returned nodes is 1.
QA2. Value aggregation with group by: Group nodes by level. Compute the average value of the aSixtyFour attribute of all nodes at each level. The return structure is a tree, with a dummy root and a child for each group. Each leaf (child) node has one attribute for the level and one attribute for the average value. The number of returned trees is 16.
QA3. Value aggregate selection: Select elements that have at least two occurrences of keyword "oneB1" in their content. Selectivity is 0.3%.
QA4. Structural aggregation. Among the nodes at level 11, find the node(s) with the largest fanout. 1/64 of the nodes are at level 11. Selectivity is 0.02%.
QA5. Structural aggregate selection: Select elements that have at least two children that satisfy aFour = 1. Selectivity is 3.1%.
QA6. Structural exploration: For each node at level 7 (have aLevel = 7, determine the height of the subtree rooted at this node. Selectivity is 0.4%. Other functionalities, such as casting, also can be significant performance factors for engines that need to convert data types. However, in this benchmark, we focus on testing the core functionality of the XML engines.
18.4.5 Updates
QU1. Point Insert: Insert a new node BaseType node below the node with aUnique1 = 10102. The new node has attributes identical to its parent, except for aUnique1, which is set to some new large, unique value.
QU2. Point Delete: Delete the node with aUnique1 = 10102 and transfer all its children to its parent.
QU3. Bulk Insert: Insert a new BaseType node below each node with aSixtyFour = 1. Each new node has attributes identical to its parent, except for aUnique1, which is set to some new large, unique value.
QU4. Bulk Delete: Delete all leaf nodes with aSixteen = 3.
QU5. Bulk Load: Load the original data set from a (set of) document(s).
QU6. Bulk Reconstruction: Return a set of documents, one for each subtree rooted at level 11 (have aLevel = 11) and with a child of type eOccasional.
QU7. Restructuring: For a node u of type eOccasional, let v be the parent of u, and w be the parent of v in the database. For each such node u, make u a direct child of w in the same position as v, and place v (along with the subtree rooted at v) under u.
| Top |







