19.3 Databases for Storing XML Documents
Although XML documents are text only and thus can easily be stored in files, they are so-called semi-structured data, which need to be accessed via the structure. (Semi-structured data have been intensively studied by Abiteboul et al. (Abiteboul et al. 2000)). It is therefore worthwhile to draw upon database technologies for their storage and retrieval. In doing so, the XML document structure has to be mapped to the database schema, which is required by every database management system. The structure of XML documents does not correspond to any schema model of the widely used database approaches and therefore has led, on the one hand, to extensive studies of the necessary transformation and, on the other hand, to the implementation of so-called native XML databases.
19.3.1 Relational Databases
The storing of XML documents in relational databases means describing hierarchical, tree-type structures with relations. In the object-oriented world, the DOM builds the basis for these structures. But it is just the relational database approach that poses the question whether we should build on an object model. We will therefore point to two alternative data models for XML documents, the so-called edge approach applied by D. Florescu and D. Kossman (Florescu and Kossmann 1999b) and XRel developed by M. Yoshikawa et al. (Yoshikawa et al. 2001).
A Simple Nontyped DOM Implementation
By using the DOM, these tree-type structures have already been transformed into trees by the implementation classes of the DOM interfaces. Two associations form the tree: the childNodes and the parentNode association. The childNodes association is multivalued, which leads to a one-to-many relationship between nodes. We have to reverse this relationship to meet the relational database constraint that does not allow composed attribute values. But the parentNode association already defines the reverse relationship.
The value of the parentNode field of a table entry identifies the superordinate element that is defined by its own table entry. The elements are, however, no longer unique as soon as they are removed from the context of the XML document. Therefore, every element receives a unique identification number that is also used as the key of its table entry. The identification numbers also allow us to store the sequence of the subordinate elements. For example, the identification number of firstname is smaller than the identification number of lastname. Table 19.1 shows the unique element table for the XML document of our example in Listing 19.2. Personnel is the topmost element with ID 1; it has no parent. Professor has ID 2 and is contained in personnel, which is its parent with ID 1. Name is contained in professor, firstname and lastname are contained in name, course is contained in professor, and title and description are contained in course with ID 6.
The actual contents of an XML document refer from the CDATASection table to entries in the element table. In this way a link is established between the CDATASection table and the element table that we can create using a foreign key in the field parentNode. Moreover, each row in the CDATASection table possesses an identification number as a key and a value stored in the field data. Table 19.2 shows the text contents of the XML document in Listing 19.2. For example, Sissi, the first name of a professor, points to entry firstname with ID 4 in the element table.
The attribute table contains the specific fields of the Attr node?value and specified, an identification number for the sequence and, in the field parentNode, the identification number of the element to which it is defined as the foreign key. Table 19.3 shows the entries for the example in Listing 19.2. PersonnelNo with value 0802 belongs to the entry professor with ID 2 in the element table.
In addition to the attribute values, the actual contents of the XML document are stored in the data fields of the records in the CDATASection table. The values of this field can, however, vary randomly in size, from short strings to page-long texts. A differentiation can take place by means of different tables: Short strings are stored in a string table; long texts in a text table. Both tables then replace the CDATASection table. Tables 19.4 and 19.5 show this once again for the example in Listing 19.2.
|
ID |
data |
parentNode |
|---|---|---|
|
1 |
Sissi |
4 |
|
2 |
Closs |
5 |
|
3 |
Document structuring with SGML |
7 |
|
4 |
In this course . . . |
8 |
|
ID |
Name |
value |
specified |
parentNode |
|---|---|---|---|---|
|
1 |
personnelNo |
0802 |
null |
2 |
|
2 |
courseNo |
TR1234 |
null |
6 |
If we want to extract a text from the database, either we need the special support of the database manufacturer who, as in the case of Oracle, has complemented its database with the SQL construct Connect-By for the extraction of hierarchical structures. Or, starting at the root, we can use an SQL instruction for every element, similar to a recursive descent into the DOM tree. A construct like Connect-By is not offered by all manufacturers of relational databases. The second solution requires database access for every subelement. The typed implementation of the DOM could be an improvement.
|
ID |
data |
parentNode |
|---|---|---|
|
1 |
Sissi |
4 |
|
2 |
Closs |
5 |
|
3 |
Document Structuring with SGML |
7 |
|
ID |
data |
parentNode |
|---|---|---|
|
1 |
In this course . . . |
8 |
The Typed DOM Implementation
The typed implementation of the DOM defines a class for every element and stores the class instances in a table of the same name. The nesting of elements, which is realized by composition, also has to take place by means of an identification number. These form the key for the entries. They must, however, be unique throughout all special element tables. The values of the parentNode fields are no longer foreign keys, as they would have to refer to the same table. However, two entries of a specific element table, as elements in an XML document, can be included in two different superordinate elements.
The elements of the example document in Listing 19.2 require the definition of eight tables, as shown in Table 19.6. The attribute and CDATASection tables and the string and text tables remain the same as with the nontyped DOM approach.
It is obvious that for a highly structured XML document many tables with few entries result. Extracting an XML document takes place by joining all element tables to a single table. This must be expressed by an SQL query. Beginning with the table of the root element, it selects the value for tagname in two tables at a time when the value of the ID field of the first table is identical to the value of the parentNode field of the second table.
The creation of this Select statement requires knowledge of the document structure. The structure is, however, reflected only in the names of the tables. As the tables are not linked to each other via the foreign key, the nesting of the elements is also not expressed in the database schema. The advantages of the typing?the validation of the document using the database and the metadata for the structure of the document?are not present with relational databases. But the advantage remains that parts of the documents can be accessed via element names.
|
Personnel |
Professor |
Name |
Firstname |
Lastname |
Course |
Title |
Description |
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
ID |
parent Node |
ID |
parent Node |
ID |
parent Node |
ID |
parent Node |
ID |
parent Node |
ID |
parent Node |
ID |
parent Node |
ID |
parent Node |
|
1 |
null |
2 |
1 |
3 |
2 |
4 |
3 |
5 |
3 |
6 |
2 |
7 |
6 |
8 |
6 |
19.3.2 Object-Oriented Databases
Object-oriented databases are the natural storage technology for the DOM. They store DOM trees without having to map the objects and their relations to other data concepts. Because they are based on a schema, as relational database systems are, the implementation variants of the DOM are reflected in the schema and have to be weighed against each other.
With the typed implementation, the specialized element classes complement the schema, and the names of the elements and their nested data are stored as metadata in the database. This can be advantageous when an application wants to validate a document using the database schema or wants to obtain information about the structure of the documents. Accessing subelements of an element also takes place via named references directly from the element and is therefore fast. With the nontyped implementation, subelements are instances in the childNodes set and have to be searched for. The class extents in object-oriented databases also bring an advantage in speed. They collect all references to the instances of a class and thus offer direct access to them. Using these, all course elements, for example, can be extracted from an XML document.
The typed compositions between the classes can, however, also be a great hindrance. If we want to extract the complete XML document again, which corresponds to running through the complete DOM tree, we do not take the typed access path but have to visit the nontyped nodes of the childNodes sets.
Modifications of the DTD also have a disadvantageous effect. Object-oriented database systems do indeed allow a dynamic customization of the schema. However, as this represents the document structure, a modification can lead to invalid documents that follow the original DTD.
These disadvantages speak in favor of the nontyped implementation of the DOM that optimally supports the running through of a DOM tree to the complete output of an XML document. Quick access to the child nodes of an element node can however be achieved by an indexing of the node set. Object-oriented database systems provide a means of indexing. In this way, indices to the attribute nodeName and to the ordering number of the child nodes can compensate for the speed differences of the different implementations.
To summarize, there is the attempt to represent hierarchical data by mapping XML documents on the schema of the various database models. This fact suggests the examination of a further type of database whose data can be organized hierarchically: the directory server.
19.3.3 Directory Servers
Although hardly discussed, directory servers could be another interesting database approach for storing XML documents. Usually, they store huge quantities of simply structured data like personnel or inventory data of a company and allow very fast read access but significantly worse write access of the data. Another important feature is the existence of a tree?the so-called directory information tree?as a means of organizing the data.
Directory servers are widespread as address databases that are accessed by using the Lightweight Directory Access Protocol (LDAP), a simple variant of the X.500 ISO standard (Howes et al. 1995). Entries in an LDAP directory contain information about objects such as companies, departments, resources, and people in a company. They are ordered hierarchically, as people normally work in departments of companies. Entries consist of attributes and their values or value sets.
Although directory servers were originally developed for providing central address books, which is reflected in the attribute names?"o" for "organization", "ou" for "organizational unit", "sn" for "surname"?they can include entries of any object classes (i.e., with self-defined attribute types).
An entry for a professor of a department is presented in LDIF (Lightweight Directory Interchange Format), a text format for the exchange of directory data, in Listing 19.3.
Listing 19.3 A Directory Entry
dn: personnelNo=1012, ou=FBWI, o=fh-karlsruhe.de objectclass: professor objectclass: employee objectclass: person objectclass: top cn: Cosima Schmauch givenname: Cosima sn: Schmauch personnelNo: 1012 uid: scco0001 telephone: 2960 roomNo: K111 courses: courseNo=wi2034, ou=FBWI, o=fh-karlsruhe.de courses: courseNo=wi2042, ou=FBWI, o=fh-karlsruhe.de
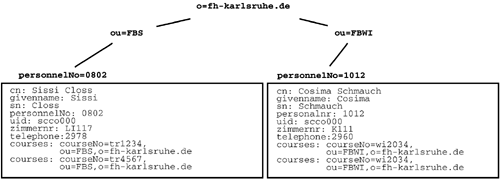
Every entry in the directory server is given a so-called distinguished name (dn) that uniquely identifies it. The distinguished name is derived from a defined relative distinguished name (rdn) consisting of attribute value pairs and extensions of namespaces. The namespaces are ordered hierarchically and are normally represented as trees?directory information trees. Figure 19.3 shows a section of the directory information tree at the Karlsruhe University of Applied Sciences.
Figure 19.3. A Section of the Directory Information Tree of the Karlsruhe University of Applied Sciences
Just as with object-oriented databases, we define the directory server schema using classes. Relationships between directory server classes are, however, established using distinguished names. An example of this is the professor entry, which is linked to several course entries. A link between directory server entries is not typed?it is a string or a set of strings, which are marked as distinguished names.
The typed DOM implementation can therefore affect only the names of the directory server classes but not the relationship between the classes. The directory server schema, similar to an implementation using relational databases, cannot reflect the document structure. We have selected therefore the nontyped DOM implementation as the basis for the directory server schema.
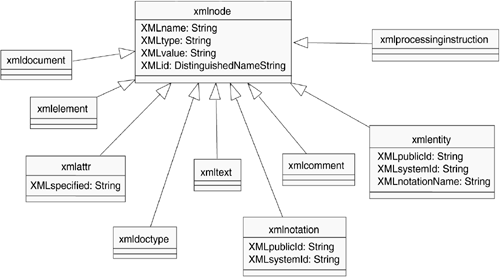
For the interfaces of the DOM, 13 classes are defined for their implementation?there was no implementation of the abstract class for the interface CharacterData. Figure 19.4 shows these classes. The class xmlnode implements the interface Node and is the base class for all remaining classes. It makes the attributes XMLname, XMLtype, and XMLvalue for storing the document-specific information available to them. The remaining classes add attributes, if required.
Figure 19.4. The Classes of the Directory Server Schema
We are left to decide how the parent-child relationships of the DOM tree are implemented. We could use distinguished names. The childNodes relationship between elements can be realized through a corresponding multivalued attribute at the class xmlnode. Because we already have the LDAP directory information tree, we can also map the DOM tree to it. We do not have to implement the tree using relations, as it is necessary with object-oriented databases via the childnodes association. We can rely on the directory information tree that is built by the form of the distinguished names. Therefore the base class xmlnode is given an additional attribute XMLid that contains a number and thus retains the order of the subelements. This id at the same time will form the relative distinguished name of the entry.
An XML document is now mapped to the directory information tree so that?modeled on the DOM tree?the element entries form the inner nodes, while all others become leaves. Figure 19.5 shows the directory information tree for the XML document from the example document of Listing 19.2. Every entry in the directory server is positioned in the directory information tree. It consists of the attribute values that are defined by its class. The personnel element is entered in the tree under the nodes with the distinguished name ou=xml. It has the following attribute values:
XMLname = personnel, XMLvalue = null, XMLtype = Element, XMLid = 1
Figure 19.5. The Directory Information Tree for the Example Document
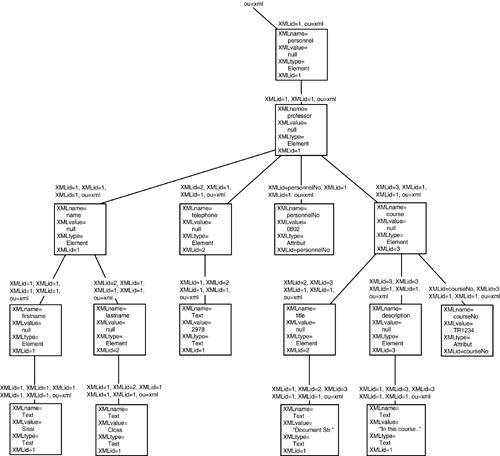
Thus the entry is given the distinguished name XMLid=1, ou=xml.
The course element, which is subsumed under the professor element as the third element after name and telephone, is given the value 3 as its XMLid and therefore the distinguished name
XMLid=3,XMLid=1,XMLid=1,ou=xml.
The attribute personnelNo obtains its name as a value of XMLid. It is subsumed under the professor element and therefore has the distinguished name
XMLid=personnelNo,XMLid=1,XMLid=1,ou=xml.
The ordering number given to every entry by the attribute XMLid contributes to its distinguished name. This allows it to retain the sequence of the elements, comments, and text parts. The value for the XMLid is assigned, and from its position in the tree and the XMLid, a new distinguished name is formed.
Because of the nontyped DOM implementation, a parser must validate the XML document, create the DOM tree, and allow access to the root of the DOM tree that represents the document. Starting at the root, the tree is then traversed completely. While doing so, the type is determined for every node, the corresponding LDAP entry is created with a distinguished name, the rest of the attribute values of the entry are set, and the entry is stored into the directory server. Then its child nodes are processed.
19.3.4 Native XML Databases
Finally, we should have a look at native XML databases, which are specialized to store and process XML documents. The database system we use has to know the DTD. From the DTD, it creates a database schema. Using a Java API, the XML document has to be parsed with the integrated DOM parser, which returns a reference to the root object. This root object will then be inserted into the database.
| Top |







