9.3 High-Level System Architecture
The high-level logical architecture of the prototype?illustrated in Figure 9.1?is fairly orthodox. XML data and XPath expressions are passed into the repository at some pro cedural mechanism: for example, a SOAP call or HTTP POST request. Three basic calls are provided by the prototype: AddSchema(), AddDocument(), and ExecXPath().
Figure 9.1. Logical Architecture of XML Repository Prototype
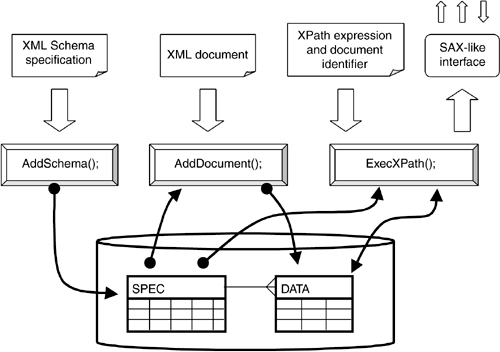
The first two interfaces, AddSchema() and AddDocument(), add new schema specifications and document data to the repository, respectively. While the prototype relies upon the repository to manage both document data and the schema specification for each document, there is no requirement that each XML document must be preceded by its schema definition. As it parses a new XML document?shredding it into a sequence of document nodes?the prototype stores whatever schema structure it finds at the same time it stores the data. XML schema information is clearly very useful: Without knowledge of what data type a particular document node value belongs to, it is impossible to know precisely what is meant by the comparison operators in XPath. Metadata about the document's structure is used by the final function in the interface?ExecXPath()?to validate and interpret XPath expressions over documents.
The prototype stores XML schema and document data in relational tables. Each XML document node is stored in its own row. The first area where this prototype differs from others is in how the XML data are mapped to relational tables. Every XML document node is assigned a unique "value" that identifies it within the document independently of whatever data values the node contains. In fact, this node value identifies the new document node within the larger document consisting of the entire repository history. Further, the prototype's node identifier value can also be used to reason about the node's position in the hierarchy: its relationship to other nodes. (A more detailed description of the schema and the user-defined types used as node identifiers is discussed in Section 9.4.) The SQL-3 queries over the repository tables exploit the information contained within the node identifier to reason about the document's hierarchical structure.
In the ExecXPath() module, each incoming XPath expression is parsed and converted into an SQL-3 query expression that exploits the schema and user-defined types already mentioned. Given the repository design, the mapping from XPath expressions to SQL-3 queries is relatively straightforward, and these queries execute very efficiently. XPath is only a subset of the XQuery standard, which also includes a number of looping and set-manipulation aspects. In the prototype, we do not build a complete XQuery processor. Instead, we focus on the navigational XPath expressions because they constitute the most serious difficulties for an SQL database.
One interesting feature of our prototype concerns its handling of the results of an XPath expression from the ExecXPath() module. Most researchers have focused on XML as a document model. XML data in document form serves as the basic unit of input to the system, and most XML repositories output entire XML documents. This XML-as-document approach is clearly appropriate when XML is being used as a medium of communication: The whole point of the technology is to support self-contained and self-describing messages. But in the context of a centralized repository, the advantages of the XML-as-document approach are less clear. Our prototype takes a different approach.
Instead of handing an entire document back to the program that submitted the XPath query, the prototype instead hands back a parser interface, similar in its functionality to the SAX (Simple API for XML) interface. Not constructing the entire result document is made possible by the way the repository stores the XML data in a shredded format. Because of the way that the XML data are organized within the repository, the task of reconstructing a document to be returned incurs considerable computational overhead (whether or not the repository stores the document as a single contiguous byte stream). If the experience with SQL DBMS technology is any guide, applications requesting data from a repository are rarely interested in the entire result set for its own sake. A particularly common usage pattern is to iterate over some query results, discarding some results based on local (i.e., external to the DBMS) variable or end-user decision. Consequently, it seems likely that the first act of a program using an XML-as-document storage model repository will be to parse and shred any document returned. It seems wasteful to invest computational resources in putting a document together only to have it immediately pulled apart again.
In a similar vein, composing a document from its component parts is an example of what is known in query processing as a blocking operation. Before even the first byte of data can be returned to the external program, the repository is obliged to examine the entire result set. By streaming data out of the repository as soon as it is found to be part of the answer to the XPath expression, the prototype permits a degree of pipe-lining impossible in document-centric systems. An external program can be working on one part of the result document at the same time that the repository is producing the rest.
Replacing the XML-as-document model with an XML-as-data model yields one more advantage. In its current form, the XQuery language standard provides no mechanism for update operations over a persistent XML document. Even overwriting the value of a single xsd:decimal element requires replacing the entire document with a new version. Making matters worse, when a new XML document A is created by extracting a subdocument from some larger, persistently stored document B with some XPath expression, the new document's node identifiers are completely independent of the identifiers in the persistent store (node identifiers are scoped to the document). Thus it is not clear how an update operation over a data node identified in document A can be tied back to a node in document B. Only by providing an interface that maps back to the original, persistent data can an update be made reliably. We illustrate the problem in Figure 9.2.
Figure 9.2. XML-as-Document Model and Repository Update Problem
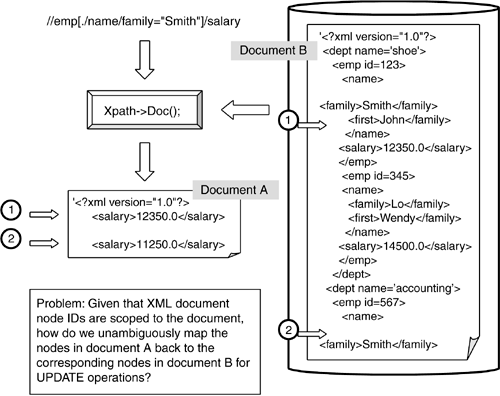
To overcome this problem, our prototype abandons the XML-as-document model except when data are being added to the repository. Even the pair of functions?AddSchema() and AddDocument()?that do deal with documents are shims over identical internal logic that shreds each XML document and stores its contents in the prototype's internal structure. XML documents are not stored in BLOB (Binary Large Object) form (except for larger blocks of text in data nodes), and document data is never reparsed. Further, the prototype includes interface mechanisms allowing external programs to update document nodes stored in the repository in much the same way that SQL developers can use UPDATE WHERE CURRENT OF CURSOR.
In Listing 9.1 we present a sequence of operations to illustrate how the prototype is used. The schema and data introduced in Listing 9.1 are used as grist for examples later in this chapter. First, we show a call to AddSchema(), which adds a schema to the repository. This step is not strictly necessary, but the schema information, as we have mentioned already, is useful for discriminating among data types in an XML document. The second call adds a new document to the repository. In the prototype we adopt the practice of allowing a single schema to be used for multiple documents, and the AddDocument() call appends a new XML document to the end of an existing one (named in the second argument to AddDocument()). Alternative models of document management?multiple distinct documents or fewer instances of much larger documents?are not precluded by anything in the prototype's fundamental design.
Listing 9.1 Adding a New Schema and a Document to the Repository
$ AddSchema ('<xs:schema xmlns:xs=http://www.w3.org/2001/XMLSchema>
<xs:element name="peach" type="part-type"/>
<xs:complexType name="part-type">
<xs:sequence>
<xs:element name="variety" type="xs:string"/>
<xs:element name="price" type="xs:decimal"/>
<xs:attribute name="quantity" type="xs:integer"/>
</xs:sequence>
<xs:attribute name="quality" type="xs:string"/>
</xs:complexType>
</xs:schema>', 'peaches');
$ AddDocument ('peaches','peach list # 1',
'<?xml version="1.0"?>
<peach quality="good">
<variety>Belle of Georgia</variety>
<price>1.25</price>
<quantity>2500</quantity>
</peach>
<!<\#45><\#45> This data is from two weeks ago <\#45><\#45>!>
<peach>
<price>1.35</price>
<quantity>1500</quantity>
</peach>
<peach quality="poor">
<variety>Southland</variety>
<price>0.95</price>
<quantity>300</quantity>
</peach>');
In Listing 9.2, we present an example of an XML XPath expression together with the result produced by the expression evaluator. This XPath expression's plain language description would be: "List all of the peaches where the price is greater than $1.00." The results list shown in Listing 9.2 reflects only a fraction of the information the XPath evaluator returns. In fact, what the ExecXPath() function returns is a sequence of Parser Event Objects. Not shown in Listing 9.2 are the node identities of the schema node, and the document node, which are used within the repository to organize the XML data. The complete set of document node information is needed by both the UPDATE methods of the interface and whatever superstructure is required by a fully functional XQuery interpreter.
Listing 9.2 Evaluating an XPath Expression
$ Exec_XPath ('peaches list # 1','/peach[price>1.00]');
begin document
start element "peach"
start attribute "quality"
attribute data "good"
end attribute "quality"
start element "variety"
text data "Belle of Georgia"
end element "variety"
start element "price"
text data 1.25
end element "price"
start element "quantity"
text data 2500
end element "quantity"
end element "peach"
start element "peach"
start element "price"
text data 1.35
end element "price"
start element "quantity"
text data 1500
end element "quantity"
end element "peach"
end document
Because we have the luxury of working with an extensible DBMS the "objects" returned by the XPath interpreter are considerably more complex than the simple row sets or cursors with which SQL developers will be familiar. Instead, each result value is a self-contained "event" object. In our prototype, these are implemented as SQL-3 structured types, but other standards?such as the SQL-J standard for Java?provide a standard mechanism for returning Java objects directly from the DBMS. Since, in our prototype, this functionality is built into the framework provided by a commercial ORDBMS, product developers have a wide range of options for external APIs: ODBC (Open Database Connectivity), JDBC, or ESQL/C (Embedded SQL for C). All of the functional interfaces were developed in a mixture of C and the DBMS's own (proprietary) stored procedure language. In hindsight, this idea was a bad one as building a slow, buggy XML parser using a DBMS-stored procedure language added little to the sum of human knowledge. Fast, reliable, and free alternatives in the form of several C and Java parsers are available on the Internet.
Once indices have been added, experimental evidence suggests that the storage space requirement of our prototype is a little less than three times the storage space required to store the original documents uncompressed (although it is significantly more than the space required to store compressed XML). In compensation for the storage overhead, the schema and node identifier values together result in the useful situation where every XPath expression over all of the document(s) in the repository is indexed.
| Top |








