15.3 The Proposed Data Model: XDM
In this section, we introduce the proposed data model, XDM (XML for Data Mining). We first show the basic idea that is behind a knowledge discovery process conducted through XDM; then we illustrate, by means of several examples, how XDM can be effectively used.
15.3.1 Basic Concepts
Past experience shows that data-mining tasks should be supported by a database system for several reasons. The first one is that data come from large databases and are often stored in data warehouses. The second reason is that if data-mining tasks are supported by a database, it helps to keep track of the intermediate and final results of the knowledge discovery process.
Nevertheless, the database support need not be necessarily provided by a relational (or an object-relational) database. In this chapter, we want to show that better support can be provided by an XML database?that is, a database that stores semi-structured data. The result is a more flexible way to represent heterogeneous data patterns and data transformation models.
XDM Database State
An XDM database is a set of XDM data items. An XDM data item is a fragment of a semi-structured tree, represented as an XML fragment rooted in an XDM-DATA-ITEM node (element). The root node has three mandatory attributes. The first one, named Name, defines the name given to the data item; the second one, named Derived, indicates if the data item is (value "YES") or is not (value "NO") derived; the third attribute, named Date, indicates the creation date for the data item.
A nonderived data item is a data item that is not the result of the application of a data-mining operator; in this case, the XDM-DATA-ITEM element has only one child element?that is, the root of the actual data fragment.
A derived data item is the result of the application of a data-mining operator. In this case, the XDM-DATA_ITEM element has two children: The first one is an XDM-DERIVATION node (element) and describes the application of the data-mining operator that generated the data described by the data item; the second child node (element) is the root of the actual derived data.
For example, a generic nonderived XDM data item has the aspect shown in Listing 15.6.
Listing 15.6 A Nonderived XDM Data Item
<XDM Database="host.xdm/AssociationRulesData">
<XDM-DATA-ITEM Name="Purchases" Derived="NO"
Date="23/3/2002">
<TRANSACTIONS>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="A" PRICE="25"/>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="B" PRICE="12"/>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="C" PRICE="30"/>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="D" PRICE="20"/>
<PRODUCT TID="2" CUSTOMER="c2" ITEM="C" PRICE="30"/>
<PRODUCT TID="2" CUSTOMER="c2" ITEM="D" PRICE="20"/>
<PRODUCT TID="2" CUSTOMER="c2" ITEM="B" PRICE="12"/>
. . . . . . . . . . . . . . . . . . . . . . . .
</TRANSACTIONS>
</XDM-DATA-ITEM>
</XDM>
The example in Listing 15.6 shows a fragment of the content of table Transactions on purchase transactions data previously discussed in Section 15.2.1, "Extracting and Evaluating Association Rules." However Listing 15.6 and Listing 15.7 will be described in full detail in Section 15.3.3, "Association Rules with XDM," later in this chapter.
The root element is named XDM, whose attribute Database denotes the database instance named AssociationRulesData hosted by a hypothetical XDM Database Management System residing on a computer named host.xdm. The XDM-DATA-ITEM has a name and a date, and its attribute Derived is false. Observe that the actual data are described by elements inside the TRANSACTIONS element.
In contrast, a derived XDM data item describing extracted patterns (association rules) from the XDM-DATA-ITEM in Listing 15.6 is shown in Listing 15.7.
Listing 15.7 A Derived XDM Data Item Containing Association Rules
<XDM Database="host.xdm/AssociationRulesData">
<XDM-DATA-ITEM Name="rules" Derived="YES" Date="28/3/2002">
<XDM-DERIVATION>
<MINE-RULE>
<SOURCE select="//XDM-DATA-ITEM[ @Name='Purchases']"/>
specification section of a mining operator (e.g., MINE RULE)
<OUTPUT Type="RULE-SET"/>
</MINE-RULE>
</XDM-DERIVATION>
<ASSOCIATION-RULE-SET>
specification section of the set of extracted association rules
</ASSOCIATION-RULE-SET>
</XDM-DATA-ITEM>
</XDM>
In Listing 15.7, we omitted the parameters that characterize the data-mining task; they depend on the particular data-mining operator and will be discussed in Section 15.3.3, "Association Rules with XDM," later in this chapter. It is important to note here that the first child element of the XDM-DATA-ITEM element is an XDM-DERIVATION element. This one describes the source data item (in the SOURCE element) and the type of the output (the OUTPUT element). Then the second child of the XDM-DATA-ITEM element is the ASSOCIATION-RULE-SET element, which contains the derived set of association rules.
XDM Database State Transitions
An XDM database instance evolves thorough state transitions. A state transition consists of the application of a data-mining operator to a set of XDM data items and extends the database state with a set of new derived XDM data items.
The state transition is described by an XML document whose root node is named XDM-TRANSITION. It includes the name of the database instance on which the state transition is performed, the mining statement that performs the state transition, the set of source XDM data items, the data-mining operator, the relevant parameters for the data-mining task, and the name and possibly the format of the new derived XDM data items.
The documents specifying state transitions are not stored in the XDM database instance as they are; in contrast, these documents are submitted to the system, similarly to classical SQL statements. When the system generates and stores new derived XDM data items, the XDM-DERIVATION tags report about the statement that generated the data item.
Let us consider a sample state transition submitted to the system (see Listing 15.8).
Listing 15.8 A State Transition Applied to the XDM Data Item of Listing 15.6
<XDM-TRANSITION Database="host.xdm/AssociationRulesData">
<XDM-STATEMENT>
<MINE-RULE>
<SOURCE select="//XDM-DATA-ITEM [@Name='Purchases']"/>
fragment describing the parameters of the state transition
<OUTPUT Type="RULE-SET" Name="rules"/>
</MINE-RULE>
</XDM-STATEMENT>
</XDM-TRANSITION>
This document is submitted to the system in order to perform a data-mining operation, namely the extraction of association rules using the MINE-RULE operator (the XDM version of the MINE RULE operator previously discussed). For the moment, we still omit the parameters that characterize the data-mining task; they will be discussed later.
Here it is important to note that the XDM state transition is described by an XDM-TRANSITION element applied to the XDM data item of the same database instance shown in Listing 15.6. The XDM-TRANSITION contains an XDM-STATEMENT element describing the actual XDM statement. This latter, in turn, contains a child element corresponding to a data-mining operator?in this case, the MINE-RULE element. Elements corresponding to a data-mining operator must contain one or more SOURCE elements that refer to the source XDM data item through an XPath expression (see the select attribute). The OUTPUT element, instead, defines the output format and the name of the XDM data item being generated.
Figure 15.2 shows a typical XDM state transition that occurs when an XDM operator is applied to an initial database state.
Figure 15.2. A Typical XDM State Transition
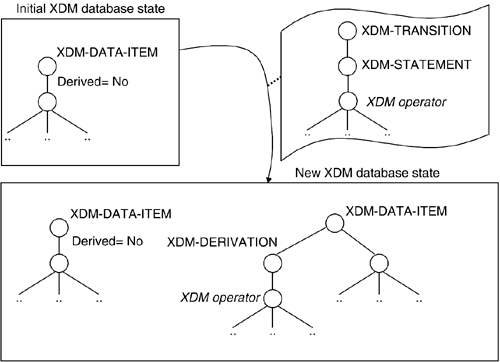
XDM Database Views
A view of an XDM database is a subset of XDM data items, involved in a complex knowledge discovery process. A view can be complete or partial: Specified a given target XDM data item, a complete view contains all the XDM data items derived by the process and the source data items; a partial view is similar to a complete view, but it contains only a user-defined set of XDM data items.
In an orthogonal way, a view can be a detailed view or an abstract view: In the former, all the included XDM data items are fully described; in the latter, only references to the actual XDM data item are reported, and, in the case of a derived data item, the derivation process description.
In the following sections, we will explain the previously introduced concepts by means of two typical application cases: classification and association rule extraction.
15.3.2 Classification with XDM
Let us now consider a typical data-mining problem?that is, the classification problem. Recall that the classification problem is divided into two steps: the training phase and the test phase. During the training phase, a classification model is built analyzing the so-called training set?that is, a set of classified data. During the test phase, the classification model is applied to new and unclassified data. Hence, the knowledge discovery process based on the classification task necessarily requires the sequential application of two operators.
Initial XDM Database State
Suppose we are creating an XDM database instance, named ClassificationData, hosted by a hypothetical XDM Database Management System identified as host.xdm; the complete URI for the XDM database instance might be host.xdm/ClassificationData.
The initial XDM database state is constituted by one data item?the training set. If we take as an example the training set described in Table 15.4, this state can be described by the XML document shown in Listing 15.9.
Listing 15.9 The XDM Data Item Containing the Training Set of a Classification Problem
<XDM Database="host.xdm/ClassificationData">
<XDM-DATA-ITEM Name="Training Set" Derived="NO" Date="22/3/2002">
<CAR-INSURANCE>
<PROFILE AGE="17" CAR-TYPE="Sports" RISK="High" />
<PROFILE AGE="43" CAR-TYPE="Family" RISK="Low" />
<PROFILE AGE="68" CAR-TYPE="Family" RISK="Low" />
<PROFILE AGE="32" CAR-TYPE="Truck" RISK="Low" />
<PROFILE AGE="23" CAR-TYPE="Family" RISK="High" />
<PROFILE AGE="18" CAR-TYPE="Family" RISK="High" />
<PROFILE AGE="20" CAR-TYPE="Family" RISK="High" />
<PROFILE AGE="45" CAR-TYPE="Sports" RISK="High" />
<PROFILE AGE="50" CAR-TYPE="Truck" RISK="Low" />
<PROFILE AGE="64" CAR-TYPE="Truck" RISK="High" />
<PROFILE AGE="46" CAR-TYPE="Family" RISK="Low" />
<PROFILE AGE="40" CAR-TYPE="Family" RISK="Low" />
</CAR-INSURANCE>
</XDM-DATA-ITEM>
</XDM>
The root element has an attribute, named Database, which denotes the URI of the database instance.
The data item is described by element XDM-DATA-ITEM, is named "Training Set", is not derived, and its creation date is 22/3/2002.
Notice that the actual data are contained in the CAR-INSURANCE element. The data are described by a set of empty elements named PROFILE, and their attributes describe properties (e.g., AGE and CAR-TYPE) that characterize each classified profile and the class that they have been assigned to (Risk Attribute).
Observe that this is one possible representation of the training set. A possible alternative representation, allowed by the semi-structured nature of XML, might be the one shown in Listing 15.10.
Listing 15.10 An Alternative Representation of Listing 15.9
<XDM Database="host.xdm/ClassificationData">
<XDM-DATA-ITEM Name="Training Set 2" Derived="NO" Date="22/3/2002">
<CAR-INSURANCE>
<PROFILE> <AGE>17</AGE> <CAR-TYPE>Sports</CAR-TYPE>
<RISK>High</RISK> </PROFILE>
<PROFILE> <AGE>43</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>Low</RISK> </PROFILE>
<PROFILE> <AGE>68</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>Low</RISK> </PROFILE>
<PROFILE> <AGE>32</AGE> <CAR-TYPE>Truck</CAR-TYPE>
<RISK>Low</RISK> </PROFILE>
<PROFILE> <AGE>23</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>High</RISK> </PROFILE>
<PROFILE> <AGE>18</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>High</RISK> </PROFILE>
<PROFILE> <AGE>20</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>High</RISK> </PROFILE>
<PROFILE> <AGE>45</AGE> <CAR-TYPE>Sports</CAR-TYPE>
<RISK>High</RISK> </PROFILE>
<PROFILE> <AGE>50</AGE> <CAR-TYPE>Truck</CAR-TYPE>
<RISK>Low</RISK> </PROFILE>
<PROFILE> <AGE>64</AGE> <CAR-TYPE>Truck</CAR-TYPE>
<RISK>High</RISK> </PROFILE>
<PROFILE> <AGE>46</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>Low</RISK> </PROFILE>
<PROFILE> <AGE>40</AGE> <CAR-TYPE>Family</CAR-TYPE>
<RISK>Low</RISK> </PROFILE>
</CAR-INSURANCE>
</XDM-DATA-ITEM>
</XDM>
Notice that this representation pushes single pieces of data into the content of elements named AGE, CAR-TYPE, and RISK. Although less synthetic, it is equivalent to the former representation.
Building the Classification Model
The first step for solving a classification problem is to build the classification model based on the training set. Suppose that a suitable operator is available in our framework; to obtain the classification model, it is necessary to apply such an operator to the training set, which constitutes the initial state of the XDM database. In other words, we have to perform a state transition that produces a new database state, augmenting the initial state with a new data item describing the classification model.
Let us see how the state transition might be described, by means of an XML document rooted in the XDM-TRANSITION element (see Listing 15.11).
Listing 15.11 The Transition Performed by the Generation of the Classification Model
<XDM-TRANSITION Database="host.xdm/ClassificationData">
<XDM-STATEMENT>
<MINE-CLASSIFICATION>
<SOURCE select="//XDM-DATA-ITEM[ @Name='Training Set']/CAR-INSURANCE"/>
<CLASSIFICATION-UNIT select="PROFILE">
<PARAM name="AGE" select="@AGE" Type="Integer"/>
<PARAM name="CAR-TYPE" select="@CAR-TYPE" Type="String"/>
<CLASS-PARAM select="@RISK"/>
</CLASSIFICATION-UNIT>
<OUTPUT Type="CLASSIFICATION-TREE" Name="Risk Classes"/>
</MINE-CLASSIFICATION>
</XDM-STATEMENT>
</XDM-TRANSITION>
The first thing to note in Listing 15.11 is the root element of the XML document: It is the XDM-TRANSITION node. Indeed Listing 15.11 specifies a mining task or a state transition. The attribute named Database specifies the XDM database instance on which the specified state transition must be performed.
The applied operator is named MINE-CLASSIFICATION and is described by the homonymous element. Elements in their content define parameters necessary to drive the classification process.
The SOURCE element selects the data item that constitutes the training set; in particular, the selection is performed through the XPath query specified in the select attribute. The reported XPath expression:
//XDM-DATA-ITEM[ @Name='Training Set']/CAR-INSURANCE
denotes that the training set is within the CAR-INSURANCE element contained in the XDM data item whose name is Training Set (see Listing 15.9).
The next element appearing in the state transition specification, named CLASSIFICATION-UNIT, denotes which elements inside the selected CAR-INSURANCE element must be considered for building the classification model. In particular, the select attribute denotes (through an XPath expression that implicitly operates in the context defined by the SOURCE element) the set of elements in the training set whose properties must be used to build the classification model. Inside the CLASSIFICATION-UNIT element, a nonempty set of PARAM elements denotes the properties that will be used to build the classification model (always through XPath expressions). The Type attribute specifies the data type (e.g., integers, real numbers, strings, etc.) that will be used for the evaluation of the property. Notice that this is necessary to overcome the absence of data types in XML. Finally, the CLASS-PARAM element specifies the property inside the classification unit that defines the class (always by means of an XPath expression denoted by the select attribute).
In our sample case, the elements named PROFILE are the classification units, as specified by the select attribute (select="PROFILE") in the CLASSIFICATION-UNIT node. The PARAM nodes denote that the properties that will be used for the classification model are the attributes AGE and CAR-TYPE, through the XPath expressions @AGE and @CAR-TYPE in the PROFILE nodes. The class label is included in attributes RISK, as specified by the XPath expression @RISK in the CLASS-PARAM node.
To conclude the specification, it is necessary to specify the output, by means of the OUTPUT element. Its attribute named Name specifies the name of the newly generated XDM data item. Attribute Type allows the specification of the format chosen for the classification model: In this case, a classification tree is specified, but we can suppose that implementations of this operator generate both classification trees and classification rules.
Observations
At first, notice the fact that elements that constitute the MINE-CLASSIFICATION operator are not prefixed as XDM elements. This is motivated by the fact that XDM is an open framework, which is not based on any predefined data-mining operator. In contrast, XDM is devised in order to be extended with any operator, provided that its application can be specified by means of an XML specification.
A second thing to notice is the following. The use of XPath provides several advantages. At first, XPath expressions are simple to write and easy to understand. Furthermore, they make transparent the information sources to the operator. To explain this concept, suppose we had to build the same classification model moving from the alternative representation of the training set described by the XDM data item named Training Set 2; we can specify the application of the MINE-CLASSIFICATION operator by using a state transition identical to the previously discussed one, apart from the content of the CLASSIFICATION-UNIT element, which becomes as follows:
<CLASSIFICATION-UNIT select="PROFILE"> <PARAM name="AGE" select="AGE/." Type="Integer"/> <PARAM name="CAR-TYPE" select="CAR-TYPE/." Type="String"/> <CLASS-PARAM select="RISK/."/> </CLASSIFICATION-UNIT>
Observe that only the value of the select attributes has changed with respect to the example of Listing 15.11. In particular, we now consider the content of elements named AGE, CAR-TYPE, and RISK (through the XPath expressions "AGE/.", "CAR_TYPE/.", and "RISK/.", respectively).
The Classification Model
The state transition discussed so far produces a new XDM data item containing a classification tree. Consequently, the state of the XDM database now contains two data items. The first is the original one, and the second is the new generated one. For the sake of saving space, we do not report the complete database state, but the partial view that reports only the data item describing the classification tree.
In the following examples of XDM code, when necessary, we will show in normal font the portion of code that has already been described in previous examples and has been inserted in the current example for the sake of the derivation process. The new portion of the XDM code is shown in bold font. However, the code in normal font need not to be reexamined by the reader since it is the same as the code already explained. For example, in Listing 15.12, the code already shown in Listing 15.11 is in normal font.
Listing 15.12 The XDM Data Item with the Classification Tree Obtained after the Transition of Listing 15.11
<XDM Database="host.xdm/ClassificationData">
<XDM-DATA-ITEM Name="Risk Classes" Derived="YES" Date="5/4/2002">
<XDM-DERIVATION>
<MINE-CLASSIFICATION>
<SOURCE select="//XDM-DATA-ITEM[@Name='Training Set']/CAR-INSURANCE "/>
<CLASSIFICATION-UNIT select="PROFILE">
<PARAM name="AGE" select="@AGE"/>
<PARAM name="CAR-TYPE" select="@CAR-TYPE"/>
<CLASS-PARAM select="@RISK"/>
</CLASSIFICATION-UNIT>
<OUTPUT Type="CLASSIFICATION-TREE" Name="Risk Classes"/>
</MINE-CLASSIFICATION>
</XDM-DERIVATION>
<CLASSIFICATION-TREE>
<CLASS-PARAM Name="RISK"/>
<CONDITION>
<EQ> <PARAM Name="CAR-TYPE"/> <VALUE String5"Sports"/>
</EQ>
</CONDITION>
<TRUE-BRANCH>
<CLASS Value="High"/>
</TRUE-BRANCH>
<FALSE-BRANCH>
<CONDITION>
<LEQ> <PARAM Name="AGE"/> <VALUE Integer="23"/> </LEQ>
</CONDITION>
<TRUE-BRANCH>
<CLASS Value="High"/>
</TRUE-BRANCH>
<FALSE-BRANCH>
<CLASS Value="Low"/>
</FALSE-BRANCH>
</FALSE-BRANCH>
</CLASSIFICATION-TREE>
</XDM-DATA-ITEM>
</XDM>
Since the classification tree is a derived data item, the first element in the content of the XDM-DATA-ITEM element is an XDM-DERIVATION element. This element reports the state transition that generated the data item.
Consider now the element CLASSIFICATION-TREE that describes the classification tree generated by the application of the data-mining operator. Notice that while it is hard to effectively represent a classification tree in a table, XML is really suitable for this purpose, due to the a priori unlimited nesting levels. In fact, consider the sample classification tree depicted in Figure 15.1. The first child element in the content of element CLASSIFICATION-TREE, named CLASS-PARAM, specifies which parameter constitutes the class (the risk property). Then, a sequence of three elements, named CONDITION, TRUE-BRANCH, and FALSE-BRANCH, describes the condition to be applied in the root node, the branch to follow if the condition is evaluated to true, and the branch to follow when it is false, respectively.
Inside a branch, it is possible to find either a class assignment (denoted by element CLASS, which is also a leaf of the tree) or another triple, CONDITION, TRUE-BRANCH, and FALSE-BRANCH, and so forth.
As far as conditions are concerned, they are usually based on comparisons between properties and numerical ranges or categorical values; the syntax chosen in our sample classification tree is just an example to show that it is possible to represent conditional expressions in XML. The reader can anyway notice that the XML representation corresponds to the classification tree of Figure 15.1.
The Test Phase
Typically, the classification model is used to classify unclassified data. For example, we can think that a new data item is loaded into the XDM database, consisting of unclassified applicants' profiles. Then a suitable state transition is performed: It takes the unclassified data set and the classification tree and generates the classified data set.
Let us describe such a process by means of our sample XDM database. Suppose that a new set of applicants is loaded into the database. This might be described by the following XDM data item, named New Applicants (see Listing 15.13).
Listing 15.13 The XDM Data Item Containing the Test Set
<XDM Database="host.xdm/ClassificationData">
<XDM-DATA-ITEM Name="New Applicants" Derived="NO" Date="10/4/2002">
<NEW-APPLICANTS>
<APPLICANT Name="John Smyth" AGE="22" CAR-TYPE="Family"/>
<APPLICANT Name="Marc Green" AGE="60" CAR-TYPE="Family"/>
<APPLICANT Name="Laura Fox" AGE="35" CAR-TYPE="Sports"/>
</NEW-APPLICANTS>
</XDM-DATA-ITEM>
</XDM>
Observe that the root element (NEW-APPLICANTS) and the elements in its content (APPLICANT elements), which describe single profiles of new applicants, are different with respect to the corresponding elements of the training set?for example, CAR-INSURANCE and PROFILE (see Listing 15.9); in particular, data about applicants also describe applicants' names. With XDM, this is not a problem because the XPath expressions used in state transition specifications make the applied data-mining operator unaware of the root element.
At this point, we have to define an XDM state transition, whose goal is to generate a new data item: This new data item is obtained by adding an attribute, which denotes the risk class, to each APPLICANT element in the data item named New Applicants (see Listing 15.13); the class value is determined by applying the classification tree generated by the previous state transition (see Listing 15.12). Suppose the XDM system provides such an operator, named, for example, TEST-CLASSIFICATION. The desired state transition might be as shown in Listing 15.14.
Listing 15.14 The XDM State Transition Leading to the Classified Test Set
<XDM-TRANSITION Database="host.xdm/ClassificationData">
<XDM-STATEMENT>
<TEST-CLASSIFICATION>
<SOURCE select="//XDM-DATA-ITEM[@Name='New Applicants']/NEW-APPLICANTS"/>
<CLASSIFICATION-MODEL Type="CLASSIFICATION-TREE"
select="//XDM-DATA-ITEM [@Name='Risk Classes']
[ @Date='5/4/2002']/CLASSIFICATION-TREE"/>
<CLASSIFICATION-UNIT select="APPLICANT">
<PARAM name="AGE" select="@AGE"/>
<PARAM name="CAR-TYPE" select="@CAR-TYPE"/>
</CLASSIFICATION-UNIT>
<EXTEND-WITH-CLASS Name="Risk" Type="Attribute"/>
<OUTPUT Name="Classified Applicants"/>
</TEST-CLASSIFICATION>
</XDM-STATEMENT>
</XDM-TRANSITION>
This state transition specification can be read as follows. The element SOURCE specifies the XDM data items to classify, through the XPath expression in the select attribute. This is:
Select="//XDM-DATA-ITEM [ @Name='New Applicants']/NEW-APPLICANTS"
and states that the data set to classify is contained in the XDM data item whose name is New Applicants, rooted in the node NEW-APPLICANTS (see Listing 15.13).
Then the CLASSIFICATION-MODEL element specifies the XDM data item that contains the classification model to apply on the data to classify. In fact, the XPath expression that constitutes the value of the select attribute:
select="//XDM-DATA-ITEM[ @Name='Risk Classes'] [ @Date='5/4/2002']/CLASSIFICATION-TREE"
says that the classification tree is contained in the XDM data item whose name is Risk Classes and the generation date is 5/4/2002 (see Listing 15.12).
Similarly to the MINE-CLASSIFICATION operator, the CLASSIFICATION-UNIT element specifies the nodes in the data item that contain the data to classify. In this case, the select attribute says that nodes named APPLICANT contain data to classify (select="APPLICANT"). Inside this element, a set of PARAM elements denotes the nodes in the data item that describe the classification model parameters. In this case:
<PARAM name="AGE" select="@AGE"/> <PARAM name="CAR-TYPE" select="@CAR-TYPE"/>
Attributes AGE and CAR-TYPE (see the XPath expressions in the select attributes) in the APPLICANT nodes are mapped to the homonymous parameters in the classification tree.
The next element, named EXTEND-WITH-CLASS, specifies how the data to classify are extended with the class label, when the new data item containing classified data is generated. In particular, in our case:
<EXTEND-WITH-CLASS Name="RISK" Type="Attribute"/>
The element says that a new object is added to the APPLICANT node; this object is called RISK and is an attribute (alternatively, it is possible to add a node/element).
Finally the OUTPUT element denotes the name of the new data item (the TEST-CLASSIFICATION operator is polymorph with respect to the structure of classified data, so no output type must be specified). In our case:
<OUTPUT Name="Classified Applicants"/>
says that the new generated data item is called Classified Applicants. This data item is shown in the next section.
The Derivation of the Classified Test Data
In this section we describe the derivation of the classified test data, starting with the derived XDM data item in Listing 15.15.
Listing 15.15 The Derived XDM Data Item Containing the Classified Test Data
<XDM Database="host.xdm/ClassificationData">
<XDM-DATA-ITEM Name="Classified Applicants" Derived="YES"
Date="10/4/2002">
<XDM-DERIVATION>
<TEST-CLASSIFICATION>
<SOURCE
select="//XDM-DATA-ITEM[ @Name='New Applicants']/NEW-APPLICANTS"/>
<CLASSIFICATION-MODEL Type="CLASSIFICATION-TREE"
select="//XDM-DATA-ITEM[ @Name='Risk Classes']
[ @Date='5/4/2002']/CLASSIFICATION-TREE"/>
<CLASSIFICATION-UNIT select="APPLICANT">
<PARAM name="AGE" select="@AGE"/>
<PARAM name="CAR-TYPE" select="@CAR-TYPE"/>
</CLASSIFICATION-UNIT>
<EXTEND-WITH-CLASS Name="RISK" Type="Attribute"/>
</TEST-CLASSIFICATION>
</XDM-DERIVATION>
<CLASSIFIED-NEW-APPLICANTS>
<APPLICANT Name="John Smyth" AGE="22" CAR-TYPE="Family"
RISK="High"/>
<APPLICANT Name="Marc Green" AGE="60" CAR-TYPE="Family"
RISK="Low" />
<APPLICANT Name="Laura Fox" AGE="35" CAR-TYPE="Sports"
RISK="High"/>
</CLASSIFIED-NEW-APPLICANTS>
</XDM-DATA-ITEM>
</XDM>
Notice the XDM-DERIVATION element, which reports the state transition (described with Listing 15.14) and the CLASSIFIED-NEW-APPLICANTS element, which contains the classified data. Observe that each APPLICANT element has now a new attribute, named RISK, which describes the class; its value has been determined based on the classification tree. The reader can easily check these values?for example, by using the graphical representation of the classification tree reported in Figure 15.1.
To conclude our discussion about the test phase, we report a view that describes the test phase previously described (see Listing 15.16).
Listing 15.16 The XDM Database View Showing the Test Phase
<XDM Database="host.xdm/ClassificationData">
<XDM-DATA-ITEM Name="New Applicants" Derived="NO" Date="10/4/2002">
<NEW-APPLICANTS>
<APPLICANT Name="John Smyth" AGE="22" CAR-TYPE="Family"/>
<APPLICANT Name="Marc Green" AGE="60" CAR-TYPE="Family"/>
<APPLICANT Name="Laura Fox" AGE="35" CAR-TYPE="Sports"/>
</NEW-APPLICANTS>
</XDM-DATA-ITEM>
<XDM-DATA-ITEM Name="Classified Applicants" Derived="YES"
Date="10/4/2002">
<XDM-DERIVATION>
<TEST-CLASSIFICATION>
<SOURCE
select="//XDM-DATA-ITEM[ @Name='New Applicants']/NEW-APPLICANTS"/>
<CLASSIFICATION-MODEL Type="CLASSIFICATION-TREE"
select="//XDM-DATA-ITEM[@Name='Risk Classes']
[ @Date='5/4/2002']/CLASSIFICATION-TREE"/>
<CLASSIFICATION-UNIT select="APPLICANT">
<PARAM name="AGE" select="@AGE"/>
<PARAM name="CAR-TYPE" select="@CAR-TYPE"/>
</CLASSIFICATION-UNIT>
<EXTEND-WITH-CLASS Name="RISK" Type="Attribute"/>
</TEST-CLASSIFICATION>
</XDM-DERIVATION>
<CLASSIFIED-NEW-APPLICANTS>
<APPLICANT Name="John Smyth" AGE="22" CAR-TYPE="Family"
RISK="High"/>
<APPLICANT Name="Marc Green" AGE="60" CAR-TYPE="Family"
RISK="Low" />
<APPLICANT Name="Laura Fox" AGE="35" CAR-TYPE="Sports"
RISK="High"/>
</CLASSIFIED-NEW-APPLICANTS>
</XDM-DATA-ITEM>
</XDM>
The Overall Classification Process
At this point, it is important to summarize the overall classification process, by means of Figure 15.3.
Figure 15.3. The Overall Classification Process
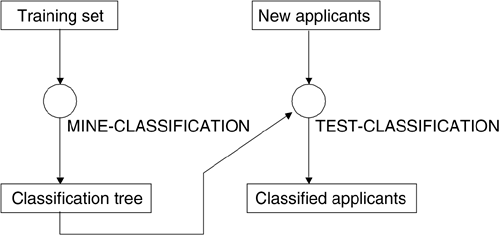
In the figure, we represent XDM data items as labeled rectangles, where the label denotes the data item name; with labeled circles, we denote the application of XDM data-mining operators, where the label denotes the applied operator.
The first step is constituted by the extraction of the classification model, represented as a classification tree, by means of the MINE-CLASSIFICATION operator applied to the XDM data item named Training Set; this operator generates the XDM data item named Classification Tree.
Then the application of the TEST-CLASSIFICATION operator allows us to classify data in the XDM data item named New Applicants based on the classification model in the XDM data item named Classification Tree; the operator generates the new XDM data item named Classified Applicants, which contains the same data of the data item named New Applicants extended with the class label.
From now on, any other data-mining or analysis task might be performed. The advantage of XDM is that the overall process, even complex, is traced by the system.
15.3.3 Association Rules with XDM
In this section, the example of the extraction of association rules presented in Section 15.2.1, "Extracting and Evaluating Association Rules," is discussed with the use of XDM.
We want to create here another XDM database instance, named AssociationRulesData, hosted by the hypothetical XDM Database Management System host.xdm; the complete URI for the XDM database instance is therefore host.xdm/AssociationRulesData.
The initial XDM database state is constituted by one data item, Purchases, the source data that we want to analyze by means of association rules. The initial state is described by the following XML document in Listing 15.17. Notice that the attribute Derived is false.
Listing 15.17 The XDM Data Item Containing the Purchase Transaction Data
<XDM Database="host.xdm/AssociationRulesData">
<XDM-DATA-ITEM Name="Purchases" Derived="NO"
Date="23/3/2002">
<TRANSACTIONS>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="A" PRICE="25"/>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="B" PRICE="12"/>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="C" PRICE="30"/>
<PRODUCT TID="1" CUSTOMER="c1" ITEM="D" PRICE="20"/>
<PRODUCT TID="2" CUSTOMER="c2" ITEM="C" PRICE="30"/>
<PRODUCT TID="2" CUSTOMER="c2" ITEM="D" PRICE="20"/>
<PRODUCT TID="2" CUSTOMER="c2" ITEM="B" PRICE="12"/>
. . . . . . . . . . . . . . . . . . . . . . . .
</TRANSACTIONS>
</XDM-DATA-ITEM>
</XDM>
The actual data are contained in the TRANSACTIONS element and are described by a set of empty elements named PRODUCT, where the attributes describe the properties that characterize each purchased product (TID is the transaction identifier, customer; item and price are the homonymous attributes already seen in Transactions shown in Table 15.1). Observe that, analogously as already said with the representation of classification data, this is only a possible representation of the source data set. An alternative representation might include the content of the attributes of the transactions in the children elements of PRODUCT.
The Extraction of Association Rules
We suppose at this point that an implementation of the MINE-RULE operator is available in this framework. This MINE-RULE implementation extracts association rules from an XDM data item, according to MINE-RULE semantics described in Section 15.2.1, "Extracting and Evaluating Association Rules." In other words, it performs a state transition that produces a new database state augmenting the initial state with a new data item. In Listing 15.18 we provide the description of the state transition by means of an XML document rooted in the XDM-TRANSITION element.
Listing 15.18 The XDM State Transition Produced by the MINE RULE Operator
<XDM-TRANSITION Database="host.xdm/AssociationRulesData">
<XDM-STATEMENT>
<MINE-RULE>
<SOURCE select="//XDM-DATA-ITEM[@Name='Purchases']/TRANSACTIONS"/>
<GROUPING select="PRODUCT" common-value="@TID"/>
<RULE-SCHEMA>
<BODY-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
<CARD min="1" max="N"/>
</BODY-SCHEMA>
<HEAD-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
<CARD min="1" max="N"/>
</HEAD-SCHEMA>
</RULE-SCHEMA>
<MEASURES>
<SUPPORT threshold="0.5"/>
<CONFIDENCE threshold="0.8"/>
</MEASURES>
<OUTPUT Type="RULE-SET" Name="rules"/>
</MINE-RULE>
</XDM-STATEMENT>
</XDM-TRANSITION>
Notice that the root node, named XDM-TRANSITION, recalls that the document considered here specifies a mining task, or a state transition to the database instance AssociationRulesData.
The XDM-STATEMENT, as already said, provides a description of the syntactic elements of the MINE RULE operator described by the MINE-RULE element. Again analogously to the MINE-CLASSIFICATION operator, SOURCE identifies the source of the data from which association rules will be extracted, through an XPath expression described by attribute select.
The GROUPING element specifies how source data is grouped (that is, by keeping together data having a common property). Grouping constitutes one of the most important operations in association rule mining because the association rules will be extracted, taking elements from within groups. Therefore, select defines the elements that are grouped together, and common-value defines the common property to the elements of the group.
<GROUPING select="PRODUCT" common-value="@TID"/>
This GROUPING element specifies that groups will be composed of PRODUCT elements found in the XDM data item (select attribute) such that given a group all PRODUCT nodes share the same value for attribute TID (common-value attribute).
RULE-SCHEMA defines the schema of the association rules by separately defining the body and head of rules through elements named BODY-SCHEMA and HEAD-SCHEMA. Both of them allow the children nodes RULE-ELEMENT and CARD.
The node RULE-ELEMENT defines elements that constitute the body of the rule; the XPath expression specified by select denotes either attributes or #PCDATA nodes, whose values are associated by rules; attribute name specifies the name given to the body element. The body schema definition is completed by the CARD element, whose attributes min and max denote the minimum and maximum number of elements appearing in the body; the value "N" for attribute max specifies that the maximum cardinality is unlimited.
In our sample state transition, the body schema is defined as follows:
<BODY-SCHEMA> <RULE-ELEMENT name="ITEM" select="@ITEM"/> <CARD min="1" max="N"/> </BODY-SCHEMA>
The MEASURES element in the MINE-RULE operator introduces, by means of ad hoc subelements, minimum support and confidence threshold values.
Notice that here it is possible to extend the semantics of the operator and allow other evaluation measures (such as conviction or lift) known in the literature on association rules.
Finally, element OUTPUT tells us the type of the derived XDM data item (RULE-SET) and its name (rules).
The Derivation of the Association Rules
The XML document in Listing 15.19 describes the XDM data item produced by the state transition and named rules. Notice that attribute derived is set to "YES". The child node ASSOCIATION-RULE-SET contains the set of association rules extracted by the MINE-RULE operator. The XDM-DERIVATION child element explains how this data item has been derived, resuming the state transition that generated the data item; in particular, it contains the definition of the extracted association rules.
Listing 15.19 The XDM Data Item with Association Rules Obtained by the State Transition
<XDM Database="host.xdm/AssociationRulesData">
<XDM-DATA-ITEM Name="rules" Derived="YES" Date="28/3/2002">
<XDM-DERIVATION>
<MINE-RULE>
<SOURCE select="//XDM-DATA-ITEM[ @Name='Purchases'] /TRANSACTIONS"/>
<GROUPING select="PRODUCT" common-value="@TID"/>
<RULE-SCHEMA>
<BODY-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
<CARD min="1" max="N"/>
<BODY-SCHEMA/>
<HEAD-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
<CARD min="1" max="N"/>
<HEAD-SCHEMA/>
<RULE-SCHEMA/>
<MEASURES>
<SUPPORT threshold="0.5"/>
<CONFIDENCE threshold="0.8"/>
<MEASURES/>
<OUTPUT Type="RULE-SET" Name="rules"/>
</MINE-RULE>
</XDM-DERIVATION>
<ASSOCIATION-RULE-SET>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> A </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> B </ELEMENT>
</HEAD>
<SUPPORT value="0.667">
<CONFIDENCE value="0.8">
</RULE>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> B </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> A </ELEMENT>
</HEAD>
<SUPPORT value="0.667">
<CONFIDENCE value="0.8">
</RULE>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> B </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> C </ELEMENT>
</HEAD>
<SUPPORT value="0.667">
<CONFIDENCE value="0.8">
</RULE>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> C </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> B </ELEMENT>
</HEAD>
<SUPPORT value="0.667">
<CONFIDENCE value="1">
</RULE>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> A </ELEMENT>
<ELEMENT Name="ITEM"> C </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> B </ELEMENT>
</HEAD>
<SUPPORT value="0.5">
<CONFIDENCE value="1">
</RULE>
</ASSOCIATION-RULE-SET>
</XDM-DATA-ITEM>
</XDM>
In the ASSOCIATION-RULE-SET node, BODY and HEAD children nodes contain a set of ELEMENT nodes that are the elements that have been associated with each other in an association rule. Each ELEMENT node has an attribute Name, which indicates the name given to the rule element (as specified by the RULE-ELEMENT tag in the state transition); the content of the ELEMENT node is the value associated by the rule.
Finally, the SUPPORT element gives the value of support of an association rule, and analogously of the CONFIDENCE element.
For example, rule {A,C}  {B}, which associates itemset {A, C} to itemset {B} with support 0.5 and confidence 1, is represented as shown in Listing 15.20.
{B}, which associates itemset {A, C} to itemset {B} with support 0.5 and confidence 1, is represented as shown in Listing 15.20.
Listing 15.20 Rule Example
<RULE>
<BODY>
<ELEMENT Name="ITEM"> A </ELEMENT>
<ELEMENT Name="ITEM"> C </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> B </ELEMENT>
</HEAD>
<SUPPORT value="0.5">
<CONFIDENCE value="1">
</RULE>
Observe that the presented data item is the XDM representation of the rule set depicted in Table 15.2; hence, the state transition described is the XDM counterpart of the MINE-RULE statement described in Section 15.2.1, "Extracting and Evaluating Association Rules."
As a final comment, notice that the elements that constitute the MINE-RULE operator and its result set (RULE-SET) are not prefixed as XDM elements, as happened with MINE-CLASSIFICATION. This is motivated again by the fact that XDM is an open framework and might be extended with any operator, provided that its application is specified with an XML specification.
Evaluation of Association Rules with XDM
We present in this paragraph the evaluation of association rules with XDM. The association rules that must be evaluated have been already extracted during the mining step with the XDM MINE-RULE operator whose state transition is detailed in Listing 15.8.
We suppose that an implementation of the EVALUATE-RULE operator, described by the element EVALUATE-RULE in XDM, is available. This operator extracts its results from two XDM data items, the transaction data and the association rule set?and performs a state transition whose result is a new data item and a new database state, with the set of evaluated association rules. The state transition that applies the EVALUATE-RULE operator to the sample database instance obtained by the previous application of the MINE-RULE operator is described in Listing 15.21), rooted in the XDM-TRANSITION element.
Listing 15.21 The XDM State Transition Performed by the EVALUATE Operator
<XDM-TRANSITION Database="host.xdm/AssociationRulesData">
<XDM-STATEMENT>
<EVALUATE-RULE>
<DATA-SECTION>
<SOURCE select="//XDM-DATA-ITEM[ @Name='Purchases']/TRANSACTIONS"/>
<EVALUATION-FEATURE name="CUSTOMER" select="@CUSTOMER"/>
<GROUPING select="PRODUCT" common-value="@TID"/>
</DATA-SECTION>
<RULE-SECTION>
<SOURCE
select="//XDM-DATA-ITEM[ @Name='rules']/ASSOCIATION-RULE-SET"/>
</RULE-SECTION>
<RULE-SCHEMA>
<BODY-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
</BODY-SCHEMA>
<HEAD-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
</HEAD-SCHEMA>
</RULE-SCHEMA>
<OUTPUT Type="DATA-WITH-RULES" Name="Rules with Customers"/>
</EVALUATE-RULE>
</XDM-STATEMENT>
</XDM-TRANSITION>
The XDM-STATEMENT provides a description of the syntactic elements of the EVALUATE-RULE operator. Recall from Section 15.2.1, "Extracting and Evaluating Association Rules," that the operator evaluates an association rule set over the source data set; in the example case, the goal is to evaluate the association rule set over the transaction data, in order to obtain, for each rule, the set of customers for which the rule holds.
For this reason, the EVALUATE-RULE tag contains four elements: the DATA-SECTION element specifies the data item on which the association rule set must be evaluated; the RULE-SECTION specifies the data item containing the association rule set; the RULE-SCHEMA element specifies the structure of association rules; finally, the OUTPUT element specifies the output data item.
In more detail, the DATA-SECTION element specifies the data item on which the rules must be evaluated and how the evaluation must be performed. Hence, in its content we find a SOURCE element whose select attribute specifies an XPath expression that selects the data item. Then, an element named EVALUATION-FEATURE specifies the feature for which the rules must be evaluated: In particular, the attribute name specifies the feature name, while the attribute select defines the XPath expression that locates the evaluation feature. Finally, the GROUPING element specifies how data in the source data item are grouped (analogously to the MINE-RULE operator). To clarify, the fragment in Listing 15.22 says that the data item named Purchases (see Listing 15.6) will be selected in order to evaluate association rules.
Listing 15.22 Purchases Example
<DATA-SECTION> <SOURCE select="//XDM-DATA-ITEM[ @Name='Purchases']/TRANSACTIONS"/> <EVALUATION-FEATURE name="CUSTOMER" select="@CUSTOMER"/> <GROUPING select="PRODUCT" common-value="@TID"/> </DATA-SECTION>
The evaluation will be performed with respect to customers. To do so, data are partitioned based on the CUSTOMER attribute, in order to have in a partition all transaction data concerning the same customer. Then, all transaction data concerning a single customer (a partition) are further grouped by transaction IDs (attribute TID). Consequently, an association rule holds for a customer if it is present in at least one group (which contains all transaction data referring to the same transaction ID). That group appears in the partition corresponding to the transaction data of that customer.
The RULE-SCHEMA element contains only a SOURCE element, which specifies, through an XPath expression, the XDM data item containing the rule set that must be evaluated. In our example, the XDM data item named rules is selected (see Listing 15.19). The element named RULE-SCHEMA simply contains body schema and head schema definitions, rooted in the BODY-SCHEMA and in the HEAD-SCHEMA elements, respectively. They are the same elements appearing also in the MINE-RULE operator. Body schema and head schema definitions in MINE-RULE and EVALUATE-RULE are the same, apart from the fact that in EVALUATE-RULE they do not contain the CARD element. Indeed, since rules have already been extracted, it is not necessary to specify a constraint on the cardinality of body and head.
For example, our state transition contains the RULE-SCHEMA definition shown in Listing 15.23.
Listing 15.23 RULE-SCHEMA Definition
<RULE-SCHEMA>
<BODY-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
</BODY-SCHEMA>
<HEAD-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
</HEAD-SCHEMA>
</RULE-SCHEMA>
The RULE-SCHEMA definition shows how to associate values of the ITEM attribute to the transaction data.
The Derivation of the Evaluated Association Rules
The state transition produces a new, derived XDM-DATA-ITEM, named Rules with Customers, containing the association rules in rules and, for each rule, the set of customers for which the rule is satisfied. The XDM-DERIVATION element contained in the XML document in Listing 15.24 explains how this data item has been derived. In particular, it contains the specification of the EVALUATE-RULE statement used to verify the validity of each reported rule (see Listing 15.19).
Listing 15.24 The Derivation of the XDM Data Item with the Evaluated Association Rules
<XDM Database="host.xdm/AssociationRulesData">
<XDM-DATA-ITEM Name="Rules with Customers" Derived="YES"
Date="30/3/2002">
<XDM-DERIVATION>
<EVALUATE-RULE>
<DATA-SECTION>
<SOURCE select="//XDM-DATA-ITEM[@Name='Purchases']/TRANSACTIONS"/>
<EVALUATION-ELEMENT name="CUSTOMER" select="@CUSTOMER"/>
<GROUPING select="PRODUCT" common-value="@TID"/>
</DATA-SECTION>
<RULE-SECTION>
<SOURCET select="//XDM-DATA-ITEM[@Name='rules']/ASSOCIATION-RULE-SET"/>
</RULE-SECTION>
<RULE-SCHEMA>
<BODY-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
</BODY-SCHEMA>
<HEAD-SCHEMA>
<RULE-ELEMENT name="ITEM" select="@ITEM"/>
</HEAD-SCHEMA>
</RULE-SCHEMA>
<OUTPUT Type="DATA-WITH-RULES"/>
</EVALUATE-RULE>
</XDM-DERIVATION>
<DATA-AND-RULE-SET>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> A </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> B </ELEMENT>
</HEAD>
<EVALUATED-FOR>
<ELEMENT Name="CUSTOMER"> c1 </ELEMENT>
<ELEMENT Name="CUSTOMER"> c3 </ELEMENT>
<ELEMENT Name="CUSTOMER"> c4 </ELEMENT>
</EVALUATED-FOR>
</RULE>
<RULE>
<BODY>
<ELEMENT Name="ITEM"> B </ELEMENT>
</BODY>
<HEAD>
<ELEMENT Name="ITEM"> A </ELEMENT>
</HEAD>
<EVALUATED-FOR>
<ELEMENT Name="CUSTOMER"> c1 </ELEMENT>
<ELEMENT Name="CUSTOMER"> c3 </ELEMENT>
<ELEMENT Name="CUSTOMER"> c4 </ELEMENT>
</EVALUATED-FOR>
</RULE>






