4.4 Building Applications for Embedded XML Databases
An embedded XML database is a library that links directly into the address space of the application that uses it. This has significant implications for the design of both the embedded database and the application.
Because an embedded XML database needs to run inside the application, the database code itself cannot make many assumptions about how the application operates or what platform-specific services the application uses. What threading model should the database use? In practice, it must be able to use whatever threading model the application designer has selected. Similarly, the embedded database system must give the application developer control over resource consumption, whether concurrent access to the data is supported (and, if so, what degree of concurrency is required), and so on.
The good news for application developers is that the embedded database system leaves so many policy decisions in the developer's hands. This means that an embedded database system can support small, single-user applications efficiently, or can handle thousands of concurrent users on a large multiprocessor box with huge amounts of memory and disk.
The bad news, of course, is that the developer has so many policy decisions to make. Building an application with an embedded XML database forces the developer to think not just about the data that the application will manage, but also about how the database code will operate inside the application.
The rest of this chapter covers some of the issues that arise in the design and implementation of applications using embedded XML databases. The examples refer to the interfaces provided by Berkeley DB XML, an Open Source-embedded XML database available from Sleepycat Software (http://www.sleepycat.com).
4.4.1 Overview of Berkeley DB XML
Berkeley DB XML is an embedded XML database. It is built on top of Berkeley DB, the general-purpose embedded database engine. The Berkeley DB XML product stores XML documents, indexes them, and provides an XPath query interface. XML documents are organized into containers, which may share a common schema or may be schema-less. Each container is configured by the client application with an indexing strategy. Listing 4.1 shows an example of using a container.
Listing 4.1 Opening and Using a Berkeley DB XML Container
#include "dbxml/DbXml.hpp"
using namespace DbXml;
int main()
{
try
{
XmlContainer container (0, "test")
container.open(0,DB_CREATE);
XmlDocument document;
string content(
"<book><title>The Cement Garden</title></book>");
document.setContent(content);
u_int32_t id= container.putDocument(0, document);
document = container.getDocument(0,id);
string s(document.getContentAsString());
cout << id << " = " << s << "\n";
container.close();
}
catch(XmlException &e)
{
cerr << e.what() << "\n";
}
}
Physically, a Berkeley DB XML container consists of several Berkeley DB tables, including a table that stores configuration information for the container, a data dictionary for the container schema, a table to store the XML document text, and tables for each index that the programmer creates. Berkeley DB XML stores statistical information about each index. This information allows the XPath query optimizer to choose an access path that minimizes the cost of executing queries at runtime.
The underlying Berkeley DB library, which handles low-level storage and transaction and recovery services, is written in C. The XML parser, XPath query processor, and other code specific to Berkeley DB XML is written in C++ and makes calls to the Berkeley DB library. Berkeley DB XML includes Java language bindings.
The rest of this chapter discusses the issues that confront programmers when they design and implement applications that use an embedded XML database. The text includes examples based on Berkeley DB XML to illustrate key points.
4.4.2 Configuration
Embedded XML databases must leave important policy decisions in the hands of the developer building the final application. Examples include:
Memory available to the embedded database system for managing its cache of recently used documents, information on locking, and other shared state
Whether the application requires transaction and recovery services
The degree of concurrency that the application requires
Whether the application will use multiple concurrent processes for different users, multiple threads inside a single process, or some combination of the two
Embedded databases generally provide sensible default settings for all of these policy decisions but permit the programmer to override any of them as the application requires.
Berkeley DB XML uses an abstraction called an environment (see Listing 4.2) to manage the shared state of a set of document collections. Generally, calling methods on the environment or on a particular container change any configuration setting. Many of the settings cannot be changed after the initial configuration step by the application. For example, the size of the shared memory region is fixed once the environment is opened. As a result, most applications create the environment, change any of the default configuration parameters as required by the application, and then open it and begin normal processing.
Listing 4.2 Using a Berkeley DB XML Container within an Environment
DbEnv environment(0); // Configure the environment here. environment.open(0, DB_CREATE | DB_INIT_MPOOL, 0); XmlContainer container(&environment, "test"); container.open(0, DB_CREATE); // Use the container here. container.close(); environment.close(0);
4.4.3 Indexing and Index Types
Any document collection in a Berkeley DB XML container can be indexed in several different ways. When a container is created, the programmer must consider the common queries that are likely to be evaluated over the container. The common queries will run faster if the container is indexed so that the attributes or elements used in the search can be looked up efficiently. Indexes are kept up to date automatically when new documents are added to the container, and the XPath query processor uses these indexes to search collections expeditiously.
It is not enough merely to decide what the most common attributes or elements for searches will be. XPath permits a variety of queries over a container, and different index types support different queries efficiently.
Indexing and optimizing queries are important topics not just in embedded XML databases, but also in client/server systems. However, the configurability of embedded systems often requires the programmer to make explicit decisions about indexing. Fundamentally, creating an index trades off query time against disk space, since the index entries must be stored, and against update speed, since every index must be updated when a new or changed record is written to the database.
Berkeley DB XML indexing strategies are best illustrated by example. Consider the XML document in Listing 4.3:
Listing 4.3 XML Document
<book bookID="books/mit/AbelsonS85"> <author>Abelson, H</author> <title>Structure and Interpretation of Computer Programs</title> <isbn>0-262-51036-7</isbn> </book>
Depicted as a graph, the document consists of a series of nodes (book, bookID, author, title, ISBN), edges that connect the nodes (book.bookID, book.author, book.title, book.ISBN), and values (1234, Abelson, H, Structure and Interpretation of Computer Programs, 0-262-51036-7). This document is illustrated in Figure 4.1.
Figure 4.1. Graphical Version of an XML Document
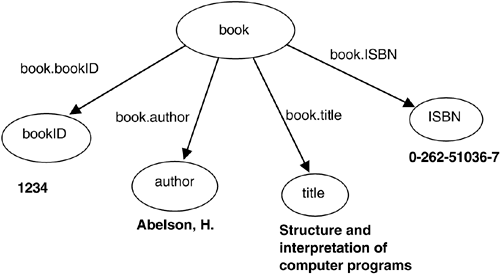
Many indexing strategies could be used to index this XML document. When creating a container, the application developer must specify the indexes that are to be maintained for that container. Each index specification is represented by a string. For example, the index "node-element-equality-string" specifies an index of elements with string values. The index specification string consists of four components: path type, node type, key type, and syntax type. There are multiple possible values for each of these types, offering a total of 16 possible combinations.
Path type: Either node or edge. Using the book example, an index with path type of node would contain five entries, one for each node in the graph (book, bookID, author, title, ISBN). An index with path type of edge would have four entries, one for each edge in the graph (book.bookID, book.author, book.title, and book.ISBN).
Node type: Specifies which document nodes should be included in the index. Supported node types are element and attribute. In the book example, an index with node type element would have four entries (for book, author, ISBN, and title). An index with node type attribute would have a single entry, for the bookID node, as it is the only attribute in the original XML document.
Key type: Determines the kind of index key that is created. The legal values are equality, presence, and substring. An index of key type equality will provide fast searches for specific nodes that match a given value. An index of key type substring enables fast substring searches. An index of key type presence will quickly find any node that matches the search key.
Syntax type: Dictates how a value will be interpreted for comparison. The choices are string, number, and none. String and number are interpreted as you would expect. None means that the index is for presence only.
The code example in Listing 4.4 demonstrates the creation of a container with the declaration of an index for the nodes named title of type node-element-equality-string. In other words, all document element nodes named title will have an index key created for them containing the value of the node as a string.
Listing 4.4 Creating an Index on a Collection in Berkeley DB XML
XmlContainer container(0, "test"); container.open(0, DB_CREATE); container.declareIndex(0, "", "title", "node-element-equality-string"); container.close();
4.4.4 XPath Query Processing
Berkeley DB XML uses XPath for queries. Query processing consists of four steps:
The XPath parser translates the text query into an internal representation.
The query plan generator creates an initial query plan.
The query optimizer considers various execution strategies and chooses one likely to minimize the execution cost.
The query execution engine runs the optimized plan against a document container and delivers results to the application. The results may be computed eagerly or lazily.
The efficiency of the query evaluation is dependent upon the class of query and the suitability of the indexes configured for the collection. Each indexing strategy is suitable for a different class of XPath query.
Presence Keys
An index of type node-element-presence-none has keys that record the presence of an element type within a document. They are suitable for path navigation expressions such as /book/author/name/first as the index will find all documents that contain the element types that appear in the path. They are also suitable for expressions containing element type value predicates such as /book[author='john'] as the index will find all documents that have elements of type book and author.
An index of type node-attribute-presence-none has keys that record the presence of an attribute name within a document. They are suitable for expressions that include path navigation expressions to attributes such as /book/@bookID as the index will find all documents that contain bookID attributes. They are also suitable for expressions that include attribute value predicates such as /book[@bookID= 'a1b2c3'] for the same reason.
Equality Keys
An index of type node-element-equality-string has keys that record the value of an element type. They are suitable for expressions that include element type value predicates such as /book[author='john'] as the index will find all documents that have elements of type author with the value john. An equality index is always more specific than a presence index, so query processing favors an equality lookup over a presence lookup.
An index of type node-attribute-equality-string has keys that record the value of an attribute. They are suitable for expressions that include attribute value predicates such as /book[@bookID='a1b2c3'] as the index will find all documents that have bookID attributes with the value a1b2c3. An equality index is always more specific than a presence index, so query processing favors an equality lookup over a presence lookup.
An index with key type equality and syntax type number has equality keys that are compared numerically, rather than lexically. The numeric syntax is provided to support queries such as /book[(year=>1980 and year<1990) or year=2000] or /book[@bookID>1000].
The query processor also makes use of equality indexes for satisfying queries that use the XPath function starts-with. For example, /book[starts-with(title, 'Structure').
Substring Keys
An index with key type substring?for example, node-element-substring-string?has keys that support substring queries. In XPath, substring searches are expressed using the XPath function contains?for example, /book[contains (title,'Computer')]. The XML indexer creates one key for every three-character substring of the node value. So, for example, the node value "abcde" creates the keys {abc, bcd, cde}.
Edge Keys
An index of type edge-element-presence-none is a more specific form of the node-element-presence-none index and is suitable for expressions containing long path navigations. If an XML document is viewed as a graph, with the elements being nodes, then the index keys are formed from the edges between the nodes. For example, the contrived XML fragment <a><b><c>d</c></b></a> has element nodes {a,b,c} and edges {a-b,b-c}. A query with an expression such as /book/author/name can be efficiently satisfied with lookups into the index for the edges { book-author,author-name}. An edge index is always more specific than a node index, so query processing favors an edge lookup over a node lookup.
The other indexes of node type edge are also supported. Each works in the same way as its node counterpart. For example, indexing the above XML fragment with edge-element-equality-string would give one key, b.c=d.
Listing 4.5 shows an example query.
Listing 4.5 Running a Query against a Berkeley DB XML Collection
XmlContainer container(0, "test");
container.open(0, DB_CREATE);
XmlDocument document;
string content("<book><title>The Rachel Papers</title></book>");
document.setContent(content);
container.putDocument(0, document);
XmlResults results(container.queryWithXPath(0, "/book"));
XmlValue value;
for(results.next(0, value);
!value.isNull();
results.next(0, value))
{
XmlDocument document(value.asDocument(0));
cout << document.getID() << " = " << value.asString(0) << "\n";
}
container.close();
4.4.5 Programming for Transactions
Most databases support transactions. An embedded database allows the programmer to determine where the transaction boundaries appear in an application. The developer can choose to make a group of related changes in a single transaction, so that all of them succeed or they are all rolled back together. This affects the way that developers write embedded XML database applications, as the next few sections will describe.
Choosing where to begin and end a transaction requires the developer to think about the application and the work that it is doing. Generally, a single transaction should include a set of related changes to the database. In the case of an XML database, two different containers may include documents that refer to one another, and the programmer may want to ensure that neither container is ever changed without a corresponding change to the other. If the two changes are made in a single transaction, then the database will always be consistent. Listing 4.6 shows an example transaction.
Listing 4.6 Transactional Updates in Berkeley DB XML
int main()
{
try
{
DbEnv environment(0);
environment.open(0, DB_CREATE | DB_INIT_LOCK | DB_INIT_LOG |
DB_INIT_MPOOL | DB_INIT_TXN, 0);
XmlContainer container1(&environment, "test1");
XmlContainer container2(&environment, "test2");
container1.open(0, DB_CREATE | DB_AUTO_COMMIT);
container2.open(0, DB_CREATE | DB_AUTO_COMMIT);
DbTxn *txr;
environment.txn_begin(0, &txn, 0);
try
{
XmlDocument document;
string content("<book><title>Fever Pitch</title>s</book>");
document.setContent(content);
container1.putDocument(txn, document);
container2.putDocument(txn, document);
txn->commit(0);
}
catch(XmlException &e)
{
txn->abort();
cerr << e.what() << "\n";
}
container1.close();
container2.close();
environment.close(0);
}
catch(XmlException &e)
{
cerr << e.what() << "\n";
}
}
4.4.6 Two-Phase Locking and Deadlocks
Most database systems support transactions using two low-level services, called two-phase locking and write-ahead logging. The locking service guarantees that concurrent transactions cannot interfere with one another, since each locks the values that it touches for the duration of the transaction. The logging service lets transactions commit or roll back, by keeping track of changes that must be backed out if the transaction fails.
Locking guarantees that transactions cannot modify the same XML documents at the same time. To enforce the locking protocol, a database system makes one of the transactions wait to acquire a lock until the transaction that holds the lock has run to completion. If the two transactions want to update the same documents at the same time, they may deadlock against one another. A deadlock can arise, for example, when two transactions are waiting for one another to complete. This is shown in Figure 4.2.
Figure 4.2. Deadlock
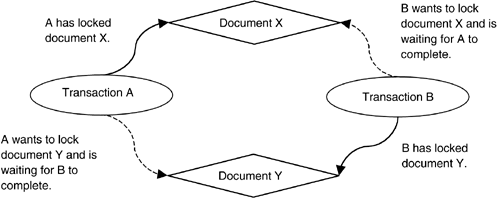
In Figure 4.2, the database system must terminate either transaction A or transaction B and roll back all its changes. The remaining transaction can then proceed to completion.
A client/server database can do this on behalf of the application. An embedded database requires the programmer to watch for deadlock errors and to roll back a transaction in the case of a deadlock (see Listing 4.7).
Fortunately, the code to identify and deal with deadlocks in an embedded XML database application is straightforward. Inside a transaction, any database operation may result in a deadlock. The embedded database can report the situation to the application, which must then abort the deadlocked transaction.
Listing 4.7 Deadlock Detection and Rollback
int main()
{
try
{
DbEnv environment(0);
environment.set_lk_detect(DB_LOCK_DEFAULT)
environment.open(0, DB_CREATE | DB_INIT_LOCK | DB_INIT_LOG |
DB_INIT_MPOOL | DB_INIT_TXN, 0);
XmlContainer container1(&environment, "test1");
XmlContainer container2(&environment, "test2");
container1.open(0, DB_CREATE | DB_AUTO_COMMIT);
container2.open(0, DB_CREATE | DB_AUTO_COMMIT);
bool retry = true;
while(retry)
{
DbTxn *txn;
environment.txn_begin(0, &txn, 0);
try
{
XmlDocument document;
string content("<book><title>Fight Club</title> </book>");
document.setContent(XmlDocument::XML,
content, strlen(content));
container1.putDocument(txn, document);
container2.putDocument(txn, document);
txn->commit(0);
retry = false;
}
catch(DbDeadlockException &e)
{
txn->abort();
retry = true;
}
}
container1.close();
container2.close();
environment.close(0);
}
catch(XmlException &e)
{
cerr << e.what() << "\n";
}
}
Rolling back a deadlocked transaction is easy to do programmatically. The embedded database system uses the log to undo all the changes that the transaction made and then releases all its locks. This can be a very expensive operation for two reasons, however. First, if the number of changes is high, then the work to undo all of them can be substantial. Second, all the work that the transaction did before it rolled back was done for a reason. It is likely that the end user will want that work to be retried. Rolling back a transaction usually means that the same sequence of updates needs to happen again in a new transaction, duplicating the work that failed in the first case.
It is much better to design database applications, including embedded XML database applications, to minimize or eliminate deadlocks. One way to do that is to keep transactions short. If a transaction touches only one or two items, it is less likely to encounter a conflict with another transaction. Another technique is to always touch items in the same order in all transactions. In Figure 4.2, the problem is that B locked Y before locking X, and A locked X before locking Y. If both transactions locked the documents in the same order, then one would still have to wait on the other, but there would be no deadlock, and no work would have to be rolled back and redone.
4.4.7 Reducing Contention
Contention can lead to deadlocks in database applications, but it can also cause more general performance problems. Embedded XML databases in particular must offer the programmer ways to measure and reduce contention. Since the database code executes using the threading model and degree of concurrency that the programmer selects, an embedded XML database's performance is much more profoundly affected by application design choices than a client/server system is.
Contention can arise from multiple transactions that need to operate on the same data at the same time. The locking subsystem will permit multiple transactions to read the same XML document in a container, but if any of them wants to modify the document, that transaction must have exclusive access to the document. As a result, it is important to lay out data in the database, and to consider query patterns, to minimize the number of concurrent transactions that want write access to the same document.
Another common source of contention is for the disk arm, in moving documents between memory and disk. Most XML database systems, whether client/server or embedded, maintain an in-memory cache of recently used documents. If that cache is smaller than the working set of the application, then the I/O subsystem will be forced to fetch documents from disk frequently. Under a heavy update load, contention is worse, since removing a document from the cache may first require writing the changed version back to stable storage before reusing the space it occupied for a new document. Thus, what might have been a single read operation turns into a write, followed by a read. Cache sizing is important in database applications generally, but because an embedded XML database gives the programmer much finer control over cache size than is common for client/server products, the matter demands more attention with an embedded database.
Finally, a third common source of contention in database applications is the transaction log. When a transaction makes changes to the database, the log records information that allows the database system to reapply or roll back the changes as necessary. Every update operation that an application makes turns into a log write. An embedded XML database allows the programmer to determine the number of threads and processes that can write to the database at the same time. As a result, an embedded XML database may exhibit log contention because of the application design. If the embedded XML database supports a service like group commit, it will monitor and adjust for that contention. Otherwise, the programmer must consider the commit throughput that the log supports and design the application accordingly.
4.4.8 Checkpoints
Both embedded and client/server XML databases use a technique called check-pointing to limit the time that an application will have to spend recovering the database after a system failure. Performing a checkpoint guarantees that the actual database contents on disk are consistent with the change log up to a particular point. As a result, after a system failure, the change log prior to that point can be ignored.
An XML database server can take periodic checkpoints on the application's behalf. An embedded XML database, by contrast, requires the programmer to decide when, and how frequently, to take a checkpoint. The code to take a checkpoint is straightforward, but the programmer must do the work periodically to ensure that the system can start up quickly after a failure. The example in Listing 4.8 makes use of Win32 threads, but any threading package can be used with Berkeley DB XML.
Listing 4.8 Checkpoints
void checkpoint(DbEnv *environment)
{
while(true)
{
::Sleep(60 * 1000); // 60 seconds
int r = environment->txn_checkpoint(0, 0, 0);
if(r != 0)
{
exit(1);
}
}
}
int main()
{
try
{
DbEnv environment(0);
environment.open(0, DB_CREATE | DB_INIT_LOCK | DB_INIT_LOG |
DB_INIT_MPOOL | DB_INIT_TXN, 0);
HANDLE checkpointThread =
::CreateThread(0, 0, (LPTHREAD_START_ROUTINE)&checkpoint,
&environment, 0, 0);
// Create containers, add documents, perform queries, etc.
::CloseHandle(checkpointThread);
environment.close(0);
}
catch(XmlException &e)
{
cerr << e.what() << "\n";
}
}
After a checkpoint, the application can also reclaim the space occupied by log records that are no longer needed. This allows the programmer to bound the space that is consumed by the log during normal processing.
4.4.9 Recovery Processing after Failures
A client/server XML database system automatically runs recovery when the database server restarts after an abnormal shutdown. Since an embedded XML database has no server process of its own, the application programmer is responsible for running recovery prior to beginning normal processing.
Berkeley DB XML makes this operation fairly simple, but every Berkeley DB XML application must begin by recovering the database. Listing 4.9 shows an example of recovery at start-up.
Listing 4.9 Recovery at Start-up
DbEnv environment(0);
environment.open(0, DB_CREATE | DB_INIT_LOCK | DB_INIT_LOG |
DB_INIT_MPOOL | DB_INIT_TXN | DB_RECOVERY, 0);
// Create containers, add documents, perform queries, etc.
environment.close(0);
| Top |








