9.4 Detailed Design Descriptions
In this section we explore three aspects of the prototype in some detail: the object-relational DBMS schema used to hold the XML document schemas and data, the user-defined types needed to make hierarchical operations efficient, and the algorithms used to map XPath expressions to their corresponding SQL-3 queries.
Figure 9.3 presents the basic schema used in the prototype in an entity-relationship diagram, and Listing 9.3 shows the required SQL-3 DDL (Data Definition Language). What Figure 9.3 conveys can be thought of as a design pattern, rather than a complete schema. Because the prototype generates all of its SQL at runtime, it has considerable flexibility in terms of how it uses the table and schema management facilities of the underlying DBMS. For example, different subsets of an XML repository can be stored in separate pairs of tables. By extending the interface functions with a qualifying name, it becomes possible to discriminate among multiple pairs of tables.
Listing 9.3 SQL Definition of Repository Schema
CREATE TABLE Spec (
Schema_Node Node PRIMARY KEY
CONSTRAINT Spec_Node_PK_Schema_Node,
Local_Name String NOT NULL,
XML_Node_Type XML_Node_Type DEFAULT 'ELEMENT'
Data_Type XML_Atomic_Type DEFAULT 'xs:anyType',
Arity XML_Node_Arity DEFAULT '[0..N]'
);
--
CREATE TABLE Data (
Doc_Node Node PRIMARY KEY
CONSTRAINT Data_Doc_Node_PK,
Schema_Node Node NOT NULL
REFERENCES Spec ( Schema_Node )
CONSTRAINT Data_Spec_FK_Schema_Node,
Value XSDSTRING DEFAULT '<EMPTY>'
);
Figure 9.3. Entity-Relationship Diagram
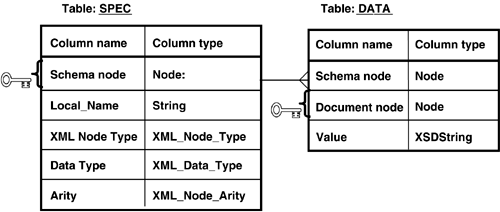
Each of the table data types in Listing 9.3 is an example of an extended data type managed by the ORDBMS. Many of these user-defined types are implemented to model aspects of the XML Schema and Data Model specification. For example, the specification provides for seven kinds of XML document nodes: Document, Element, Attribute, Namespace, Processing Instruction, Comment, and Text. Also, the XML Data Model includes a set of 19 primitive atomic types (in addition to a generic type known as xsd:anyType). Each atomic node value in the document must be of one of these types. XML Node Types and XML Atomic Data Type identifiers are modeled using the XML_Node_Type and XML_Data_Type SQL types.
Our prototype uses only a single pair of tables. In practice, an XML repository would need considerably more. XML's use of namespaces to assign semantic intent to tag names, for example, suggests that some additional columns are necessary. And although XML's "wire" format consists of ASCII strings, care must be taken to ensure that XPath expressions with range predicates (>, <, etc.) and the more complex set-membership operations evaluate correctly. Replacing the single DATA table from Figure 9.3 with a branching hierarchy of tables allows us to overload the data type used to define the VALUE column. The type system of the XML Schema and Data Model?which is considerably richer than the SQL-92 type system or the SQL-3 built-in types?can be modeled with user-defined types in an SQL-3 ORDBMS. We illustrate this approach with the E-ER diagram in Figure 9.4.
Figure 9.4. Extended-ER Diagram for OR Schema That Handles XML Built-in Data Type Information
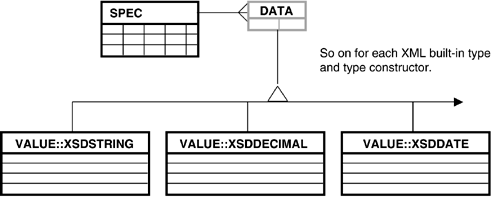
SQL-3 DBMS engines convert queries addressing the "table" DATA in Figure 9.4 into queries over the entire hierarchy of type-specific tables beneath it. A table per XML type approach is useful because it permits the DBMS to create a separate index per type/table ensuring that, for example, two xsd:decimal values 21 and 123 and two xs:string values "21" and "123" are handled in the manner appropriate to their type. Further, a distinct SQL-3 type/table per XML type simplifies the mapping from the typed operators specified in XQuery (>, >=, etc.) into SQL-3 equivalents. Although the XML Schema Specification includes about 40 types, the number of tables needed to manage them is fortunately much fewer. All 10 integer types, for example, can be stored in a single table. In all cases, typed data is converted back into an ASCII representation.
Understanding how XML data are mapped to relational tables is central to understanding how the XPath expressions are mapped into fairly simple and efficient SQL-3 queries. We take a minute here to explain how this is done.
XML's data model is hierarchical (e.g., Figure 9.5). All XML documents combine tags that define the tree-like structure of the document with whatever data the document contains. Each item in an XML document is either a node (associated with the document's structure), or it is an atomic value (which makes up the data the document contains) bound to a node. XML nodes are organized into hierarchies; formally we can say that each node in a document has at most one other node that it can call its parent node, although it may have many children and an even larger number of descendants. Further, nodes have identity (every node is distinct from all other nodes within the document), and they are ordered within the document (XML documents have a well-defined node order).
Figure 9.5. Hierarchical Structure of XML Document Data from Listing 9.1
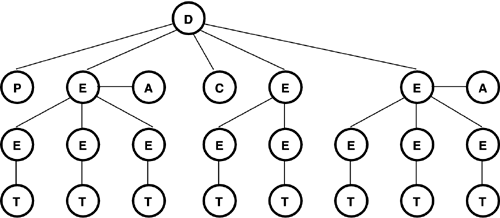
Note that, without the schema specification, it is possible to determine the names and kinds (attributes, elements, etc.) of each node, although it is not clear how to extract data type information from a document. If the type of element or attribute data is unknown, then it is classified as being of xsd:anyType.
Among the various things standardized as part of XML is a set of operators for reasoning about the relative locations of nodes in a document tree. Collectively referred to as path expressions, these represent concepts such as "look for element node 'variety' under element node 'peach'", or "element node 'price' is a descendant of element node 'peach'", or "attribute node 'price' is a child of element node 'peach'". In the document data in Listing 9.1, for example, the <price></price> node associated with the "0.95" atomic value is a descendant of the <peach></peach> node that is the parent of the quality="poor" attribute node. Hierarchical operators are not part of the relational data model followed (more or less) by the implementers of SQL database management systems. An important challenge for our prototype, therefore, is to arrive at efficient ways to support hierarchical path operations in an object-relational DBMS.
We introduce hierarchical concepts into the DBMS through the mechanism of a new user-defined type (UDT) called "Node" (or "SQL Node" to distinguish it from "XML document node"), and a number of user-defined functions, which implement operators over the new type. You can see where the SQL Node type is used in Figure 9.3. SQL Node "values" consist of a variable length vector of positive integer values. Several internal representations suggest themselves, each with its own trade-off between complexity and performance. In the prototype we opted for the simplest possible representation: an array of 32-bit integers. The SQL Node type could easily be constructed to support parent->child branching or arbitrary width and of arbitrary depth by employing nonstandard integer representations.
In Tables 9.1 and 9.2 we present in tabular form what the SPEC and DATA tables would look like after the operations in Listing 9.1. SPEC stores nodes specified as part of an XML schema specification. DATA stores the actual data found in the XML documents stored in the repository with a reference back to the corresponding schema node.
SQL Node values are useful because they allow us to reason about hierarchies efficiently. Given two SQL Node values, it is possible to deduce what the relationship is between the corresponding XML document nodes. Other approaches to managing hierarchies (sometimes referred to in the literature as "containment" or "bill-of-materials" problems) require developers to reconstruct the relationship from data in several columns, or several rows, or both. Also, the query-processing techniques necessary to traverse the tree are very simple in the case of the SQL Node approach?a B-tree index scan to extract a list of descendants, hash joins for equality?while they are considerably more complex in other approaches?iteratively constructing an intermediate result set in recursive query processing.
|
Doc Node |
Schema_Node |
Value |
Doc_Node |
Schema_Node |
Value |
|---|---|---|---|---|---|
|
4447.0 |
6.0 |
peaches |
4447.2.1 |
6.1.2 |
1.35 |
|
4447.1 |
6.1 |
<EMPTY> |
4447.2.2 |
6.1.3 |
1500 |
|
4447.1.1 |
6.1.4 |
good |
4447.3 |
6.1 |
<EMPTY> |
|
4447.1.2 |
6.1.1 |
Belle of Georgia |
4447.3.1 |
6.1.4 |
poor |
|
4447.1.3 |
6.1.2 |
1.25 |
4447.3.2 |
6.1.1 |
Southland |
|
4447.1.4 |
6.1.3 |
2500 |
4447.3.3 |
6.1.2 |
0.95 |
|
4447.2 |
6.1 |
<EMPTY> |
4447.3.4 |
6.1.3 |
300 |
At the heart of the SQL Node UDT is a mechanism for ordering SQL Node values so that they can be indexed and compared in the manner required. This mechanism depends on a single user-defined function called COMPARE() that takes two SQL Node values and returns -1 if the first comes before the second, 1 if the first comes after the second, and 0 if they are the same value. In Listing 9.4 we present the pseudo code for this function.
Listing 9.4 Pseudo Code for Compare Function for SQL Node User-Defined Type
PROCEDURE COMPARE ( Node_A, Node_B )
RETURNS INTEGER
// Node.GetElement ( INTEGER ) returns the element value at some offset.
// If the INTEGER argument is larger than the number of elements in the Node
// the method returns 0. The initial element of a Node must be a positive
// integers.
LOCAL:
INTEGER Result := NOT_FOUND, // NOT_FOUND is out-of-band placeholder.
Offset := 1,
FirstElement, SecondElement;
WHILE ( Result == NOT_FOUND ) DO
FirstElement := Node_A.GetElement ( Offset );
SecondElement := Node_B.GetElement ( Offset );
IF ( FirstElement > SecondElement ) THEN
Result := 1;
ELSE IF ( FirstElement < SecondElement ) THEN
Result := -1;
ELSE IF ( FirstElement == 0 ) AND ( SecondElement == 0 ) THEN
Result := 0;
ELSE
OffSet := OffSet + 1;
END IF;
END DO;
RETURN Result;
END COMPARE;
SQL-3 and XML developers never use the COMPARE() UDF. Rather, it is embedded within the ORDBMS, which makes use of it as part of SQL query processing. A number of other SQL operations can be built on COMPARE(). For example, all of the Boolean ordinal operators over two SQL Nodes?equals, greater than, less than, and so on?can be determined from the COMPARE() function's return result. And in a well-engineered ORDBMS, this same function can be used to overload the sorting, B-tree indexing facilities, as well as the MIN() and MAX() aggregate functions.
In Table 9.3 we present a list of hierarchical "axes" operations taken from the XPath version 2.0 and XQuery specification and show their corresponding representation as user-defined predicates over the SQL Node UDT. "Axes" operations are navigational "path" expressions involving an XML document's structure. Underlined operations are all user-defined functions. In SQL-3 queries, user-defined functions can be combined using the standard logical operators.
All of the expressions in the right column of Table 9.3 can be invoked as part of SQL-3 queries over the tables used to store the XML data. As part of its query-processing work, the ORDBMS engine calls the appropriate user-defined function in the appropriate places. As several of the examples in Table 9.3 imply, SQL Node values can be sorted into document order. For example, to reconstruct a list of all of the nodes in the documents, along with their tags, the kind of XML node and the XML node's data type all in document order, it is only necessary to use the query in Listing 9.5. Further, it is possible to use the relational concept of views in interesting ways. For example, the data in the VIEW in Listing 9.6 corresponds to a list of every possible subdocument in the repository (i.e., every possible target of an XPath expression over the repository). Clearly, for any reasonably large repository, selecting all of the data in this view is impossible. Even the 14 nodes in the single, small document added in Listing 9.1 by itself generates 37 "rows" in XML_Doc_Trees. In practice this view is used only to extract results from the repository, which means that other, very restrictive predicates are all applied over it.
|
XPath Axes Operations |
Equivalent SQL Node User Defined Type Expression, and Examples |
|---|---|
|
is: Equivalent Document Node (or different Document Node) |
EQUAL ( Node_A, Node_B ): '4447.1.4' = '4447.1.4', '6.1.3' <> '6.1.4' |
|
descendant: Document Node A is descendant of Document Node B |
GREATERTHAN (Node_A, Node_B ) and LESSTHAN ( Node_A, INCREMENT ( Node_B ) ): '4447.1.4' > '4447.1' AND '4447.1.4' < (INCREMENT ( '4447.1' ) == '4447.2') NOTE: The order-sensitive operations (GREATERTHAN() and LESSTHAN() ) are determined by comparing each integer in each input node from left to right and returning when one integer is found to be different from the integer in the corresponding location in the other node. If no differences are found the result is an equality. If one node terminates before the other without there being any difference the terminating node is less than longer node. The INCREMENT ( Node ) function increments the least significant (last) integer value in the Node. |
|
child: Document Node A is a child of Document Node B |
GREATERTHAN ( Node_A, Node_B ) and LESSTHAN ( Node_A, INCREMENT ( Node_B ) ) AND LENGTH ( Node_A ) = LENGTH ( Node_B ) + 1; NOTE: The LENGTH ( Node ) function returns the number of integers or 'levels' in the Node. Thus LENGTH('4447.1') == 2. |
|
ancestor: Document Node A is an Ancestor of Document Node B. (Note that this is simply the commutation of descendant). |
GREATERTHAN (Node_B, Node_A ) and LESSTHAN ( Node_B, INCREMENT ( Node_A ) ): |
|
parent: Document Node A is a parent of Document Node B. (Note that this is simply the commutation of child.) |
EQUAL ( Node_A, GETPARENT ( Node_B )); NOTE: GETPARENT(Node) trims the least significant (last) integer from the input. |
|
sibling: Document Node A is a sibling of Document Node B which occurs after it. |
EQUAL (GETPARENT (Node_A), GETPARENT (Node_B)); NOTE: To compute the following or preceding sibling in a set it is necessary to find the MIN() or MAX() node value in the set matching the predicate above. |
Listing 9.5 SQL-3 Query to Reconstruct Entire XML Document from Repository Schema
SELECT S.XML_Node_Type AS Kind_of_Node,
S.Local_Name AS Tag_Name,
S.XML_Data_Type AS Data_Type,
D.Value AS Value,
D.Schema_Node AS Schema_Node,
D.Doc_Node AS Doc_Node
FROM Data D, Spec S
WHERE D.Schema_Node = S.Schema_Node
ORDER BY D.Doc_Node;
Listing 9.6 SQL-3 View Representing Every Possible Subtree in the Repository
CREATE VIEW XML_Doc_Trees AS
SELECT S1.Local_Name AS Root_Tag_Name,
S1.Schema_Node AS Root_Schema_Node,
D1.Doc_Node AS Root_Doc_Node,
S2.XML_Node_Type AS Value_Data_Type,
S2.Local_Name AS Local_Tag_Name,
S2.Data_Type AS Data_Type,
D2.Value AS Value,
D2.Doc_Node AS Doc_Node,
D2.Schema_Node AS Schema_Node
FROM Data D1, Spec S1, Data D2, Spec S2
WHERE S1.Schema_Node = D1.Schema_Node -- JOINS between Schema and
AND S2.Schema_Node = D2.Schema_Node -- DATA.
AND D2.Doc_Node >= D1.Doc_Node -- This pair of predicates
AND D2.Doc_Node < -- specifies all of the Nodes
Increment(D1.Doc_Node); -- in D2 which are
descendants of
-- each node in D2. See
Table 9.3.
How can such queries be made to scale to large documents or large numbers of documents? Database indexing is key to scalability, and providing the ability to support indexing operations over SQL Node user-defined type columns is critical to getting good performance out of the prototype. Not all modern DBMS products provide this functionality, and some that promote their user-defined indexing features implement the feature poorly. However, the Open Source PostgreSQL DBMS, IBM's Java-based Cloudscape, and Informix IDS products all implement such support quite well.
XML's document hierarchy is only one example of a data-modeling problem for which the Node UDT is suitable. Reporting hierarchies (employees, managers, and the manager's managers) and process hierarchies are other applications where the hierarchical structure of the information is a key challenge. In any data-modeling situation where there exists a parent/child relationship between objects of the same type can use the SQL Node UDT extension.
We now turn to a discussion of how the prototype converts XPath expressions into SQL-3 queries. In Listing 9.7 we provide a complex XML Schema definition, together with some example data. Figure 9.6 presents the same schema information as a graph.
Listing 9.7 XML Document for More Complex XPath Examples
$ AddDocument (
'INQUIRY','Inquiry List # 1',
'<?xml version="1.0"?>
<inquiry reference-num="123" respond-by="2002-05-21">
<inquiry-from>
<name>Ajax Inc</name>
<address country="US">
<street>123 Ajax St</street>
<city>Ajaxville</city>
<state>CA</state>
<zip>95123</zip>
</address>
</inquiry-from>
<delivery-to country="US">
<street>123 Ajax St</street>
<city>Ajaxville</city>
<state>CA</state>
<zip>95123</zip>
</delivery-to>
<requested-order>
<item partNum="ABC-123">
<productName>Shoes</productName>
<quantity>2</quantity>
</item>
<item partNum="CBA-321">
<productName>Sox</productName>
<quantity>2</quantity>
</item>
</requested-order>
</inquiry>');
Figure 9.6. Tree Graph for XML Schema in Listing 9.7
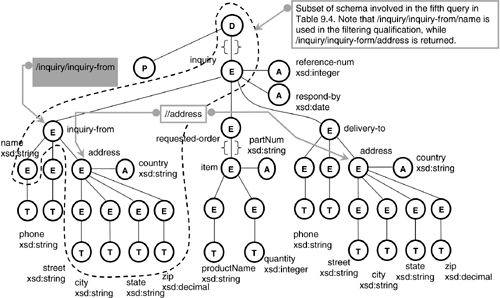
The primary purpose of XPath expressions is to identify interesting subsets of some XML data document. For example, a user may want address information of potential customers making inquiries or information about items that have a particular partNum. XPath expressions are deceptively simple. They derive their power from the flexibility of the underlying hierarchical data model. Each XPath expression describes a path within some target document. Names in the path expression correspond to element names (tags) in the document's structural schema, and each path expression will probably refer to a great many node locations in any particular document. Several examples of XPath path expressions and their interpretations are to be found in Table 9.4. Note that the "//" or "descendant-of" path separator might produce as a result a situation where a single XPath expression addresses a number of nodes in the schema! And in an XML document subsets of a schema can be present multiple times.
At various points in the path, the XPath expression can add predicate expressions that filter (qualify) the set of possible document locations. Filter expressions are combinations of type-specific comparison operations. For example, the XPath standard includes a full set of comparison operators for numbers and strings as well as a set of mathematical and string-manipulation functions. In general, all of these are equivalent to a straightforward SQL-3 query statement.
Each path in an XPath expression is a sequence of node (element or attribute) names. Each has (at least) a hierarchical relationship (see Table 9.3) with the prior node in the list, with the initial node descending from some document root node or a current context node in the document. Consequently, an XPath expression in an XML document schema can be validated by joining the SPEC table from the prototype schema once with itself for each tag or label in the XPath expression. XPath expressions with a single node label require a single selection from the SPEC table: the root label of the result document. Each additional node label in the XPath expression adds another SPEC table join, with the join predicate depending on the axes relationship (descendant of, child of). If what separates the two nodes is a single "/", then the second element is a child of the first, and if the separator is a "//", or some relative path expression such as "..//", then a more complex hierarchical relationship is used in the join (descendant, or descendant-of-parent, respectively).
|
XPath Expression |
Plain Language Interpretation |
|---|---|
|
/inquiry |
Return all of the document nodes descendant from the /inquiry path, together with the /inquiry node itself. |
|
/inquiry/inquiry-from |
Return all of the document nodes descendant from the '/inquiry/inquiry-from' path together the inquiry-from node itself. |
|
//address |
Return all of the document nodes which are descendants of an 'address' node together with the 'address' document node itself. Note that the '//' addressing says that the subsequent tag is either a descendant-or-self of the current node. |
|
/inquiry//address [city eq "Ajaxville"] |
Return all of the document nodes which are descendants of an 'address' node together with the 'address' document node itself, so long as the 'address' document node has a child node called 'city' whose value is equal to "Ajaxville". |
|
/inquiry/inquiry-from [name eq "Ajax inc"]/address |
Return all of the document nodes which are descendants of an 'address' node that is a child of an '/inquiry/inquiry-from' path together with the 'address' document node itself, so long as the 'inquiry-from' document node has a child node called 'name' whose value is equal to "Ajax Inc". |
|
//address[zip intersect (94090, 95000 to 96000)] |
Return all of the document nodes which are descendants of an 'address' node where a child node element called 'zip' has a value of 94090 or a value between 95000 and 96000. |
Having determined through a series of joins the schema node that is the root node of the XPath result, the SQL-3 query then needs to use the XML_Doc_Trees view from Listing 9.6 to retrieve the actual data. Listing 9.8 illustrates three SQL-3 queries that correspond to the first three XPath expressions in Table 9.4. Sorting the data?the last step in each of the queries in Listing 9.8?is necessary to meet the requirement that XML data always appear in document order. All of the predicates in the Table 9.4 queries are "indexable"?that is, the ORDBMS makes use of an index on the Data.Schema_Node column to compute the joins efficiently. Note that all of the navigational axes operations can be indexed if the schema size should be large enough to justify it. And a repository containing a very large number of schemas (where, for instance, each and every document produces its own schema as a side effect of parsing) presents no difficulty.
Listing 9.8 SQL-3 Equivalents for First Three XPath Expressions from Figure 9.6
SELECT X.* FROM XML_Doc_Trees X , Spec P1 WHERE X.Root_Schema_Node = P1.Schema_Node AND P1.local_name = "inquiry AND Length (GetParent(P1.Schema_Node)) = 1 ORDER BY X.Doc_Node; SELECT X.* FROM XML_Doc_Trees X, Spec S1, Spec S2 WHERE X.Root_Schema_Node = P2.Schema_Node AND P1.local_name = "inquiry" AND P2.local_name = "inquiry-from" AND P1.Schema_Node = GetParent(P2.Schema_Node) AND Length(GetParent(P1.Schema_Node)) = 1 ORDER BY X.Doc_Node; SELECT X.* FROM XML_Doc_Trees X ,Spec P1 WHERE X.Root_Schema_Node = P1.Schema_Node AND P1.local_name = "address" ORDER BY X.Doc_Node;
Qualifiers in the XPath expression can also be checked in the SQL query. Nodes?attributes as well as elements?mentioned in qualification predicates can also be thought of as part of a path. In the fourth XPath example from Table 9.4, for instance, the "city" element (attributes are always preceded either by an "@" symbol or an "attribute::" expression) is a child of the "address" element, which is a descendant of the "inquiry" element, which makes up the root of the document path. The XPath qualifies only those addresses where the city element equals "Ajaxville". Another way of saying this is that the qualifier ensures that there exists a child element of address whose label name is "city" and whose value is "Ajaxville". It is this existential qualifier mechanism that the prototype exploits (see Listing 9.9).
Each qualifier identifies an element (or attribute) relative to one outer component of the XPath and provides an expression to evaluate over that element (or attribute). The prototype relegates the identification of the qualifier node and the qualifier check to a subquery. Multiple qualifiers in the XPath result in multiple subqueries.
Listing 9.9 SQL-3 Equivalent for Fourth XPath Expression in Table 9.4
SELECT X.*
FROM XML_Tree X , Spec P1, Spec P2
WHERE X.Root_Schema_Node = P2.Schema_Node
AND P1.local_name = "inquiry"
AND Length (GetParent(P1.Schema_Node)) = 1
AND P2.Schema_Node > P1.Schema_Node
AND P2.Schema_Node < Increment ( P1.Schema_Node )
AND P2.local_name = "address"
AND EXISTS ( SELECT 1
FROM Spec P3, Data D1
WHERE D1.Schema_Node = P3.Schema_Node
AND P3.Local_Name = "city"
AND P2.Schema_Node = GetParent(D1.Schema_Node)
AND D1.Doc_Node > X.Root_Doc_Node
AND D1.Doc_Node < Increment ( X.Root_Doc_Node
)
AND D1.Value = "Ajaxville")
ORDER BY X.Doc_Node;
A qualifying filter expression may be the termination of an XPath expression. As you can see from the outlined subset of XML Schema Nodes in Figure 9.6, it is possible for a filtering qualifier to be applied over a path that branches from the path returned. In this case, the query needs to ensure that it is addressing only those data branches where an appropriate subnode exists. Our transformation algorithm achieves this by adding a join back to the DATA table in the outer query and adding another predicate to the subquery (see Listing 9.10).
Listing 9.10 SQL-3 Query Equivalent of the Fifth Query in Table 9.4
SELECT X1.*
FROM Spec P1, Spec P2, Spec P3, Data D1,
XML_Doc_Tree X1
WHERE X1.Root_Schema_Node = P3.Schema_Node
AND P1.local_name = "inquiry"
AND Length (GetParent(P1.Schema_Node)) = 1
AND P2.local_name = "inquiry-from"
AND P1.Schema_Node = GetParent ( P2.Schema_Node )
AND D1.Schema_Node = P2.Schema_Node
AND GetParent(X1.Root_Doc_Node) = D1.Doc_Node
AND P3.local_name = "address"
AND P2.Schema_Node = GetParent ( P3.Schema_Node )
AND EXISTS (
SELECT 1
FROM Spec P4, Data D2
WHERE P4.local_name = 'name'
AND P2.Schema_Node = GetParent(P4.Schema_Node)
AND D2.Schema_Node = P4.Schema_Node
AND D2.Value = 'Ajax Inc'
AND D1.Doc_Node = GetParent(D2.Doc_Node ))
ORDER BY X1.Doc_Node;
Supporting update operations is another important objective of the repository. The AddDocument() interface call parses the input document and validates its contents against the schema. As it does so it stores the rows corresponding to input document nodes in a temporary table, inserting the entire set into the DATA table once it has validated the entire input document. In terms of the XML-as-document model what AddDocument() is doing is appending the new document to the end of the existing document data. Another kind of update operation modifies the data in a single document node: for example, changing a price in a catalog. And, of course, an entire subset of the document may be deleted. XPath and XQuery do not currently include support for update operations. Nevertheless they are likely to be important in any practical system of the kind the prototype addresses.
Storing XML documents as contiguous blocks of data presents a number of problems to concurrent read/write operations. If the locking granularity of the repository is at the document level?that is, if the system only supports document level concurrency control?then different users may not be reading and writing different parts of the same document at the same time. Storing XML document data with one node-per-record offers the best possible granularity control: Modern DBMS products all support row-level locking. But any mechanism for supporting concurrent read/write access should do so with minimal cost overheads.
Support for INSERT and UPDATE operations over XML documents has proven to be a very hard problem because of the need to maintain document order. In Figure 9.7 we illustrate the problem. The tree graph on the left represents the before state of some subset of document nodes in an XML document. For completeness we include a sequence value representing node order. New nodes are added?an additional item might be in an inquiry document, for example?producing the tree on the right. All of the nodes to the left of the newly inserted nodes and all of the nodes to the left of the entire Figure 9.7 subtree have been modified. Consequently, adding new nodes to a document might have the side effect of modifying all of the node values coming after it in the document.
Figure 9.7. INSERTING Subtree into XML Document Preserving Document Order
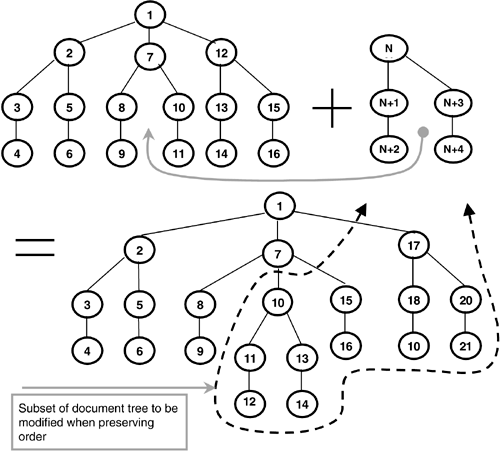
The Node UDT reduces but does not eliminate the problem. In Figure 9.8 we show the same subtree as in Figure 9.7, only this time using the SQL Node to enumerate the XML document nodes. As you can see, the addition of the new nodes has only modified the values of nodes descended from the after-siblings of the new root node. This is a significant improvement over the sequence value "worst case" of Figure 9.7.
Figure 9.8. SQL Node Tree Hierarchy and Effect of INSERT Operation
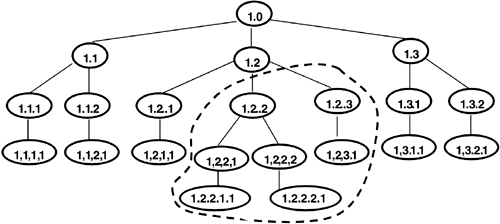
Using the SQL Node type for XML document node identity reduces the amount of work required when adding (or deleting) values to (or from) an XML document stored in the repository. This represents more work than is required in other document management approaches?storing each "edge" in the document tree as a parent/child relationship between nodes allows for the absolute minimum of work?but it is less than certain other schemes. As a result, the XML repository prototype is fairly resilient to insert operations in the document tree.
| Top |








