5.4 Future Architecture and Technology
This section provides a glance at the challenges and potential directions for IBM XML data management development.
5.4.1 The Vision
The vision is to deliver a data store and application processing interface that helps developers create and run XML as well as current relational data applications without worrying about how the data are stored or in what form they are stored. The data management system provides a consistent way to store and access all digital media. Relational users will see a world-class RDBMS that also handles XML extremely well. XML users will see a strong XML database with native type, function, and indexing that also supports current relational applications.
5.4.2 Application Interface, Data Type, and API Goals
The vision (see Figure 5.12) has two major components: the application view of the data and the storage of the data. From an application perspective, there will be support for XML data as a native type and general functional support, making it easier to access, query, and make good use of XML information. Currently, with the XML Extender, data are stored as a CLOB or shredded into relational tables using existing SQL and specialized UDTs. Similarly, SQL/XML support currently makes use of the CLOB type to contain composed XML data. This use of object-relational technology to represent XML will be replaced with a native XML data type within the database and function supporting use of that type. This native XML type will allow for more straightforward application development because developers can
Count on improved scalability for large XML documents
Nest XML manipulation operations
Access, view, store, and manipulate XML data using operators specifically optimized for XML
Figure 5.12. The Future
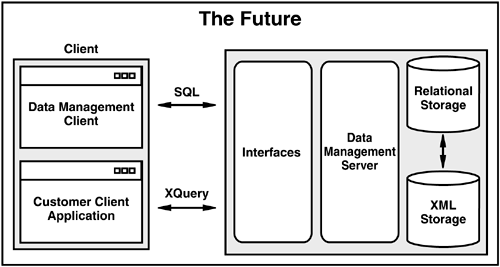
The focus on application interface and data type enhancements also correlates to likely directions for SQL/XML development (e.g., constructor functions, shredding functions) and improvements to overall navigation function within XML documents (through use of path expressions).
New API development objectives are to expose true XML and relational data types, including support for materializing XML data to the application either in DOM form or through a series of SAX events. At the high end, application-serving function will become much more tightly integrated with the database engine. At a lower level, additional support will be provided for developers to create table or scalar functions from WSDL descriptions.
Specific to support for storing and manipulating XML is development on a new API, based on XQuery, to interact with the XML and relational data. This API will provide callable support for XML, structured (relational data, through XML views), semi-structured (XML fragments), and unstructured (text) applications. This level of XQuery support will provide developers the ability to:
Automatically create low-level XML views of existing relational data without the need for a DAD file
Use not only the full set of XQuery, but also the union of XQuery capabilities with relational capabilities
Create application-specific views using XQuery
Store XML data automatically without a DAD file
Query XML and relational data with one statement
Query data and metadata
Perform queries on data efficiently, passing function down to the engine and materializing only the minimum set of required data for queries
Use high-performance text search functions including advanced capabilities such as linguistic search, stemming, proximity search, thesaurus similarity search, classification and categorization, and automated summarization
The net result is that developers will have the ability to quickly load, query, and manipulate both XML and relational data with a standard API while leveraging existing strengths of relational function augmented with XQuery capability.
Listing 5.13 shows an example of XQuery statements. The result set is a new document that contains a set of all hippos that live in fresh water that weigh less than one ton. This statement shows not only XQuery itself, but XQuery with full text (the contains clause) and user-defined function support originally developed for object relational support (a function called legs2weight that is not an XQuery-bodied function but rather a function written in a third-generation language such as C and accessible to XQuery as though it were a built-in function).
Listing 5.13 XQuery Statements
<zoo_hippos habitat_type='fresh water' body_configuration='slender'>
{
for $a in document("/attractions/zoos/animals.xml")
where $a/type="Hippo" and
contains($a/habitat, "fresh water") and
legs2weight($a/legs/text()) < 2000
return
<hippo legs={$a/legs} food={$a/food}>
{$a/name}
</hippo>
}
</>
5.4.3 Storage, Engine, and Data Manager Goals
An application view of XML is not sufficient if the data engine does not have robust support for storing and manipulating that type. Relational engines must undergo significant XML-related modifications to:
Not only support structured data, but also support semi-structured data extremely well.
Support sequential operations and data, not just set-based.
Handle sparse attribute processing.
Provide flexible schema support. This includes support for features such as transformations, schema migration, and constraint enforcement.
Have a full suite of integrated tools for management of relational as well as XML data.
Support search, composition, and interrogation (which includes taking full advantage of metadata for improved performance).
Provide high performance, exploiting the last quarter century of optimizer technology. XQuery support will be deeply integrated into the query compiler?enjoying the same world-class optimization provided to relational users.
Most importantly, the data store must help developers create XML applications with at least the same level of ease and power available to SQL developers now. In terms of overall XML and SQL support, the architecture would look like Figure 5.13.
Figure 5.13. Future Architecture
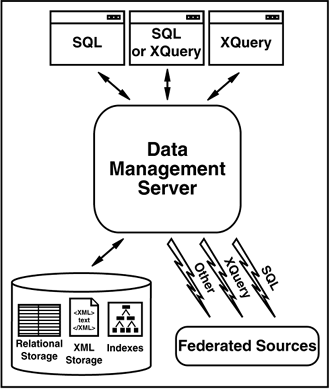
Object-relational extensions will no longer be required to support XML; the functionality will be part of the core engine. Transformations, intermediary stored procedures, and data-mapping files will not be required.
Developers can submit XQuery or SQL requests and receive relational or XML data in response as application needs dictate. They can even mix and match XQuery and SQL in the same unit of work. They can choose the right language and interface to use based on characteristics of the application, while choosing the right storage model based on characteristics of the data. XQuery support will take advantage of XML storage to provide improved performance for operations involving multiple documents. For example, it is currently feasible to search through one XML document for a particular string or attribute using XSL or an XPath processor. However, if you need to search an entire collection of whole XML documents for an attribute, without preindexing elements/attributes of interest, executing XQuery statements on natively stored XML documents using local engine function will provide superior performance.
Overall function support will show similar levels of improvement. For example, today, XML Extender applications must call UDFs to invoke XML processing capabilities; in the future, those capabilities will be part of the built-in function set of the database engine. This set of capabilities will be available through most existing APIs such as ODBC, JDBC, and even as an embedded language (the XQuery equivalent of embedded SQL).
Indexing methods will be available specifically for XML data that are developed and tuned specifically for XML data. The methods will take into account, not only the hierarchical nature of XML data, but also all of the information set. These indexes will vary considerably from existing relational indexes because they will be able to efficiently index the entire document and not just select portions.
A key part of the vision is supporting a flexible approach to data schemas. Typically, for relational data, arbitrary schema support is very difficult. You can create views on data, but you really don't have a lot of flexibility in terms of changing the underlying structure. With XML data, XML Repository (XR), and XSLT support, changing the data schema becomes possible without copying the data into a new database. For example, an application could make use of several schemas (some of which are versioned) and then have a set of documents that work well with each schema. Later, a requirement is received requiring a restructure of the data (adding a new field). This is not a problem because you can create a -01 version of the schema that allows for the new usage without requiring changes to the stored document. This is quite different from the relational model; with the relational model, if you change or add a data type, you need to unload everything, create a new table, and then put the data back.
5.4.4 Why Support Both XML and Relational Storage in One System?
From a user and developer perspective, the simple answer is that there are not two systems. There is just one data management system used to store data, and the system will worry about the format and location as needed. From an architectural perspective, the simple answer is that there are advantages to providing underlying function that allows for the storage of data in its native type. And there are advantages to starting with current relational technology and adding in XML support in a manner that takes advantage of what relational engines already have. Here are some specific points:
XML has a linear/hierarchical structure; SQL data are structured as relations. Data access methods must exist that are optimized for both structures so as to provide reasonable performance for query and insert, update, and delete operations.
Relational metadata is captured in a distinct catalog and tends to be static; XML metadata is distributed within the document, and the validity of the data can vary as required (different/versioned schemas). Simply verifying that an existing XML document or data set is correct, and reverifying that as needed, is a new step from a relational perspective.
Relational data are usually much more dense in the sense that typically all/most columns have values. XML documents can be sparse, and missing information is indicated simply through the lack of an element or attribute.
An XML document has an implicit order?document order, child order under parents, and so on. Relational data has no order beyond that derived from data values.
Regarding the advantages of starting with an existing base of relational technology, here are some reasons:
Leverage existing transaction management, data storage, and security function.
Reuse existing data flow capacity.
Take full advantage of scalability and parallelization technology.
Exploit local engine level access to existing relational data sets. This approach allows developers to extend to and support new data without losing current structured data and federated data framework.
5.4.5 Why Not Object-Relational Long Term?
The primary reason is that an OR approach does not provide the level of performance and function required for the efficient handling of a data type of this importance (XML). Specifically, an OR future:
Does not fully address XML document linear structures.
Requires users to pre-specify storage models for data.
Relies on a UDT, UDF approach instead of native support.
Relies on existing LOB technology.
Cannot easily address XQuery semantics and behavior. XQuery requires two-value logic in some cases and three-value logic in others. Also, it has an approach for empty sequences that is quite different from standard relational null handling.
The overall issue with an OR approach is that the engine never really understands that it is processing XML data.
5.4.6 Impacted Technology Areas
Achieving this vision will require many changes and additions. Key areas are
New storage and runtime support (XML type, native storage, XPath retrieval, search, and full expression support, security enhancements, access control list support, versioning)
Indexing (automatic function, statistics)
Compiler updates to support XML (SQL/XML and XQuery handling, XQuery parser, optimization support, new runtime operators)
Logging and locking mechanisms
Transaction management
Utilities
In summary, because XML is being fully integrated into all facets of the database management system, any area that provides specific relational function will require change or new function to support XML.
| Top |







