17.4 Existing Benchmarks for XML
In this section we discuss and compare three benchmarks currently available that test XML systems for their query-processing abilities: XOO7 (Bressan, Dobbie 2001; Bressan, Lee 2001), XMach-1 (Böhme and Rahm 2001), and XMark (Schmidt, Waas, Kersten, Florescu, Manolescu et al. 2001). We will first describe the three benchmarks before comparing them.
17.4.1 The XOO7 Benchmark
The XOO7 benchmark was developed using the well-established OO7 benchmark as the starting point. The XOO7 benchmark is an XML version of the OO7 benchmark with new elements and queries added to test the features that are unique in XML.
The XOO7 Database
The basic data structure in the XOO7 benchmark comes from the OO7 benchmark. Figure 17.1 shows the conceptual schema of the database modeled using the ER diagram. We have translated this schema into the corresponding DTD as shown in Listing 17.1.
Listing 17.1 DTD of XOO7 Database
<!ELEMENT Module (Manual, ComplexAssembly)>
<!ATTLIST Module MyID NMTOKEN #REQUIRED
type CDATA #REQUIRED
buildDate NMTOKEN #REQUIRED>
<!ELEMENT Manual (#PCDATA)>
<!ATTLIST Manual MyID NMTOKEN #REQUIRED
title CDATA #REQUIRED
textLen NMTOKEN #REQUIRED>
<!ELEMENT ComplexAssembly (ComplexAssembly+ | BaseAssembly+)>
<!ATTLIST ComplexAssembly MyID NMTOKEN #REQUIRED
type CDATA #REQUIRED
buildDate NMTOKEN #REQUIRED>
<!ELEMENT BaseAssembly (CompositePart+)>
<!ATTLIST BaseAssembly MyID NMTOKEN #REQUIRED
type CDATA #REQUIRED
buildDate NMTOKEN #REQUIRED>
<!ELEMENT CompositePart (Document, Connection+)>
<!ATTLIST CompositePart MyID NMTOKEN #REQUIRED
type CDATA #REQUIRED
buildDate NMTOKEN #REQUIRED>
<!ELEMENT Document (#PCDATA | para)+>
<!ATTLIST Document MyID NMTOKEN #REQUIRED
title CDATA #REQUIRED>
<!ELEMENT para (#PCDATA)>
<!ELEMENT Connection (AtomicPart, AtomicPart)>
<!ATTLIST Connection type CDATA #REQUIRED
length NMTOKEN #REQUIRED>
<!ELEMENT AtomicPart EMPTY>
<!ATTLIST AtomicPart MyID NMTOKEN #REQUIRED
type CDATA #REQUIRED
buildDate NMTOKEN #REQUIRED
x NMTOKEN #REQUIRED
y NMTOKEN #REQUIRED
docId NMTOKEN #REQUIRED>
Figure 17.1. Entity Relationship Diagram for the OO7 Benchmark
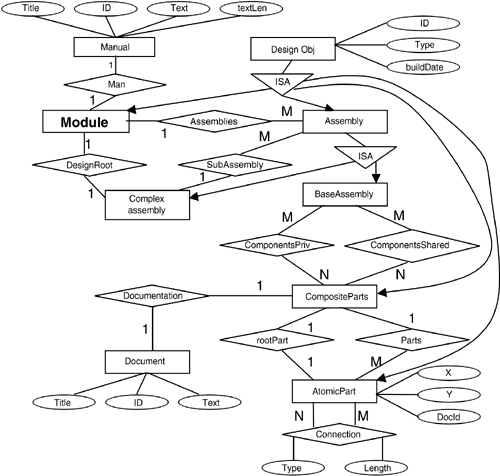
Since XML does not support ISA relationships, we have to preprocess the inheritance of attributes and relationships. We choose <Modulei> as the root element of the XML document. Although XML is supposed to be portable and independent of any platform, some systems designate special functions to certain attributes. For example, Lorel (Abiteboul et al. 1997) uses the name of the root element to identify an XML document, while the majority of the XMS uses the filename as the identifier. XOO7 assigns a unique root name to each XML file so that the XML data can be stored and queried in most systems.
Two <para> elements are created in <Document> to cater to the document-centric aspect of XML. In fact, the <Document> element provides for a liberal use of free-form text that is "marked up" with elements. <Document> contains two attributes, MyID (integer) and title (string). Since two attributes are in the connection relation, we choose to convert connection to a subelement of CompositePart with attributes type and length. Then AtomicPart becomes a subelement of connection instead of CompositePart.
Similar to OO7, the XOO7 benchmark allows data sets of varying size to be generated: small, medium, and large. Table 17.2 summarizes the parameters and their corresponding values that are used to control the size of the XML data.
Note that there are some important differences in the XOO7 benchmark database parameters compared to those in the OO7 benchmark:
While seven levels of assemblies are in the OO7 benchmark, only five levels are used in the small and medium databases because existing XML tools have limitations in the amount of data they can manipulate.
There are ten modules in the large database in the OO7 benchmark. In XOO7, the number of modules is fixed at one because the module element is chosen as the root of the XML document.
Since the XML data set can be represented as a tree, the data size can be changed in two directions: depthwise and breadthwise. The depth of the tree can be varied by changing the value of NumAssemblyLevels, while the breadth of the tree can be controlled by the value of NumAtomicPerComposite or NumCompositePer Module. Furthermore, users can include different amounts of text data according to their application by changing the size of Document and Manual.
The XOO7 Queries
The queries generated from the OO7 benchmark do not cover a substantial number of the XML query functionalities we identified earlier (compare Table 17.1 and the OO7 queries in S. Bressan et al. [Bressan, Lee 2001]). In fact, the majority of the OO7 queries focus on the data-centric query capabilities of object-oriented database systems. It is therefore imperative that the benchmark be extended to include queries to test document-processing capabilities. Table 17.3 lists the complete set of queries in the XOO7 benchmark together with comments and coverage. The XOO7 queries are divided into three main groups. Group I consists of traditional database queries. Most of these functionalities are already tested in many existing database benchmarks. Group II consists of navigational queries. They were designed because of the similarities between XML data and semi-structured data (Abiteboul et al. 2000; Buneman 1997). These queries test how traversals are carried out in the XML tree. Group III consists of document queries. These queries test the level of document-centric support given by systems and test the ability of data to maintain order.
|
Group |
ID |
Description |
Comments |
Coverage |
|---|---|---|---|---|
|
I |
Q1 |
Randomly generate 5 numbers in the range of AtomicParts MyID. Then return the AtomicPart according to the 5 numbers |
Simple selection. Number comparison is required. |
R1, R2 |
|
Q2 |
Randomly generate 5 titles for Documents. Then return the first paragraph of the document by lookup on these titles. |
String comparison and element ordering are required in this query. |
R1, R2 |
|
|
Q3 |
Select 5% of AtomicParts via buildDate (in a certain period). |
Range query. Users can change the selectivity. |
R4 |
|
|
Q4 |
Join AtomicParts and Documents on AtomicParts docId and Documents MyID. |
Test join operation. It is commonly tested in many benchmarks. |
R9 |
|
|
Q5 |
Randomly generate 2 phrases among all phrases in Documents. Select those documents containing the 2 phrases. |
Text data handling. Contains-like functions are required (Contains is a function defined in the XQuery specification. It checks if a string occurs in another string). |
R5 |
|
|
Q6 |
Repeat query 1 but replace duplicated elements using their IDREF. |
This is to test the ability to reconstruct a new structure. |
R1, R18 |
|
|
Q7 |
For each BaseAssembly count the number of documents. |
Test count aggregate function. |
R9, R10 |
|
|
Q8 |
Sort CompositePart in descending order where buildDate is within a year from current date. |
Test sorting and use of environment information. |
R11, R14 |
|
|
Q9 |
Return all BaseAssembly of type "type008" without any child nodes. |
Users only require a single level of the XML document without child nodes included. |
R18 |
|
|
II |
Q10 |
Find the CompositePart if it is later than BaseAssembly it is using (comparing the buildDate attribute). |
Compare attributes in parent nodes and child nodes. It tests the basic relation in XML data. |
R13 |
|
Q11 |
Select all BaseAssemblies from one XML database where it has the same "type" attributes as the BaseAssemblies in another database but with later buildDate. |
Selection from multiple XML documents. It performs string and number comparison as well. |
R9 |
|
|
Q12 |
Select all AtomicParts with corresponding CompositeParts as their subelements. |
Users may have various choices to store the same data, so they always require switching the parent nodes with the child nodes. |
R18 |
|
|
Q13 |
Select all ComplexAssemblies with type "type008". |
Note ComplexAssembly is a recursive element, so it tests on regular path expression. An XMS should not browse every node. |
R20 |
|
|
Q14 |
Find BaseAssembly of not type "type008". |
Robustness in presence of negation. |
R8 |
|
|
Q15 |
Return all Connection elements with length greater than Avg(length) within the same composite part without child nodes. |
Avg function and group-by-like functions are required in this query. |
R9, R10 |
|
|
Q16 |
For CompositePart of type "type008", give 'Result' containing ID of CompositePart and Document. |
Part of information of an element is required in this query. Test data transformation. |
R17, R18 |
|
|
III |
Q17 |
Among the first 5 Connections of each CompositePart, select those with length greater than "len". |
Test element order preservation. It is a document query. |
R9, R21 |
|
Q18 |
For each CompositePart, select the first 5 Connections with length greater than "len". |
Similar to above. It is to check if some optimization is done. |
R9, R21 |
These three groups of queries are relevant to the characteristics of XML data and cover most of the functionalities. All of the queries are simple, and each query covers only a few functionalities. The majority of the queries is supported in many XMS, which makes them very portable. Users can always choose a subset of queries to test the features required in their applications.
17.4.2 The XMach-1 Benchmark
The XMach-1 benchmark (Böhme and Rahm 2001) is a multiuser benchmark designed for B2B applications. In this chapter, we did not analyze the multiuser part of the benchmark but we consider only the special case of the XMach-1 benchmark, a single-user issuing queries from a local machine. The benchmark models a Web application using XML as follows: XML manipulations are performed through an XML-based directory system sitting on top of XML files.
The XMach-1 Database
The XMach-1 benchmark limits the XML data to be simple in data structure and small in size. It supports both schema-based and schema-less XMS and allows implementing some functionality at the application level. Figure 17.2 shows the ER diagram of XMach-1 database and the corresponding DTD is given in Listing 17.2. Attributes have been omitted to simplify the diagram. Each of the XML files simulates an article with elements like title, chapter, section, paragraph, and so on. The element section is a recursive element. Text data are taken from the natural language text. Users can vary an XML file size by modifying the number of the article elements. Varying the number of XML files controls the size of the database. Note that XMach-1 assumes that the size of the data files exchanged in Web applications will be small (1?14KB).
Listing 17.2 DTD of XMach-1 Database
<!ELEMENT document (title, chapter+)>
<!ATTLIST document author CDATA #IMPLIED
doc_id ID #IMPLIED>
<!ELEMENT author (#PCDATA)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT chapter (author?, head, section+)>
<!ATTLIST chapter id ID #REQUIRED>
<!ELEMENT section (head, paragraph+, subsection*)>
<!ATTLIST section id ID #REQUIRED>
<!ELEMENT subsection (head, paragraph+, subsection*)>
<!ATTLIST subsection id ID #REQUIRED>
<!ELEMENT head (#PCDATA)>
<!ELEMENT paragraph (#PCDATA | link)*>
<!ELEMENT link EMPTY>
<!ATTLIST link xlink:type (simple) #FIXED "simple"
xlink:href CDATA #REQUIRED>
Figure 17.2. ERD of XMach-1 Database
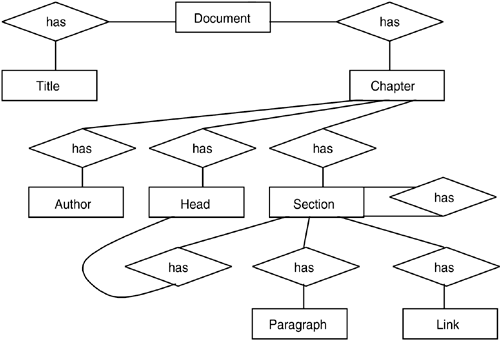
The XMach-1 Queries
XMach-1 evaluates standard and nonstandard linguistic features such as insertion, deletion, querying URL, and aggregate operations. The benchmark consists of eight queries and two update operations as shown in Table 17.4. For the sake of a consistent comparison, we divide the queries into four groups according to the common characteristics they capture. Group I consists of simple selection and projection queries with comparisons on element or attribute values. Group II queries require the systems to use the element order to extract results. Group III queries test aggregation functions and the use of metadata information. Group IV are update operations. We observe that while the proposed workload and queries are interesting, the benchmark has not been applied, and no performance results are available.
|
Group |
ID |
Description |
Comment |
|---|---|---|---|
|
I |
Q1 |
Get document with given URL. |
Return a complete document (complex hierarchy with original ordering preserved). |
|
Q2 |
Get doc_id from documents containing a given phrase. |
Text retrieval query. The phrase is chosen from the phrase list. |
|
|
Q5 |
Get doc_id and id of parent element of author element with given content. |
Find chapters of a given author. Query across all DTDs/text documents. |
|
|
II |
Q3 |
Return leaf in tree structure of a document given by doc_id following first child in each node starting with document root. |
Simulates exploring a document with unknown structure (path traversal). |
|
Q4 |
Get document name (last path element in directory structure) from all documents that are below a given URL fragment. |
Browse directory structure. Operation on structured unordered data. |
|
|
Q6 |
Get doc_id and insert date from documents having a given author (document attribute). |
Join operation. |
|
|
III |
Q7 |
Get doc_id from documents that are referenced by at least four other documents. |
Get important documents. Needs some kind of group by and count operation. |
|
Q8 |
Get doc_id from the last 100 inserted documents having an author attribute. |
Needs count, sort, and join operations and accesses metadata. |
|
|
IV |
M1 |
Insert document with given URL. |
The loader generates a document and URL and sends them to the HTTP server. |
|
M2 |
Delete a document with given doc_id. |
A robot requests deletion, e.g., because the corresponding original document no longer exists in the Web. |
|
17.4.3 The XMark Benchmark
The XML benchmark project at CWI (Schmidt, Waas, Kersten, Florescu, Manolescu et al. 2001) recently proposed the XMark benchmark. This benchmark consists of an application scenario that models an Internet auction site and 20 XQuery (Boag et al. 2002) challenges designed to cover the essentials of XML query processing.
The XMark Database
Figure 17.3 shows the ER diagram of the XMark database. The corresponding DTD can be seen in Listing 17.3. We have again omitted the attributes to simplify the diagram. The main entities in the database are item, person, open auction, close auction, and category. Items are the objects that are for sale or are sold already; person entities contain subelements such as name, e-mail address, phone number; open auctions are auctions in progress; close auctions are the finished auctions; categories feature a name and a description. The XMark benchmark enriches the references in the data, like the item IDREF in an auction element and the item's ID in an item element. The text data used are the 17,000 most frequently occurring words of Shakespeare's plays. The standard data size is 100MB with a scaling factor of 1.0, and users can change the data size by 10 times from the standard data (the initial data) each time.
Listing 17.3 DTD of XMark Database
<!ELEMENT site (regions, categories, catgraph, people, open_auctions,closed_auctions)> <!ELEMENT categories (category+)> <!ELEMENT category (name, description)> <!ATTLIST category id ID #REQUIRED> <!ELEMENT name (#PCDATA)> <!ELEMENT description (text | parlist)> <!ELEMENT text (#PCDATA | bold | keyword | emph)*> <!ELEMENT bold (#PCDATA | bold | keyword | emph)*> <!ELEMENT keyword (#PCDATA | bold | keyword | emph)*> <!ELEMENT emph (#PCDATA | bold | keyword | emph)*> <!ELEMENT parlist (listitem)*> <!ELEMENT listitem (text | parlist)*> <!ELEMENT catgraph (edge*)> <!ELEMENT edge EMPTY> <!ATTLIST edge from IDREF #REQUIRED to IDREF #REQUIRED> <!ELEMENT regions (africa, asia, australia, europe, namerica, samerica)> <!ELEMENT africa (item*)> <!ELEMENT asia (item*)> <!ELEMENT australia (item*)> <!ELEMENT namerica (item*)> <!ELEMENT samerica (item*)> <!ELEMENT europe (item*)> <!ELEMENT item (location, quantity, name, payment, description, shipping, incategory+, mailbox)> <!ATTLIST item id ID #REQUIRED featured CDATA #IMPLIED> <!ELEMENT location (#PCDATA)> <!ELEMENT quantity (#PCDATA)> <!ELEMENT payment (#PCDATA)> <!ELEMENT shipping (#PCDATA)> <!ELEMENT reserve (#PCDATA)> <!ELEMENT incategory EMPTY> <!ATTLIST incategory category IDREF #REQUIRED> <!ELEMENT mailbox (mail*)> <!ELEMENT mail (from, to, date, text)> <!ELEMENT from (#PCDATA)> <!ELEMENT to (#PCDATA)> <!ELEMENT date (#PCDATA)> <!ELEMENT itemref EMPTY> <!ATTLIST itemref item IDREF #REQUIRED> <!ELEMENT personref EMPTY> <!ATTLIST personref person IDREF #REQUIRED> <!ELEMENT people (person*)> <!ELEMENT person (name, emailaddress, phone?, address?, homepage?, creditcard?, profile?, watches?)> <!ATTLIST person id ID #REQUIRED> <!ELEMENT emailaddress (#PCDATA)> <!ELEMENT phone (#PCDATA)> <!ELEMENT address (street, city, country, province?, zipcode)> <!ELEMENT street (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT province (#PCDATA)> <!ELEMENT zipcode (#PCDATA)> <!ELEMENT country (#PCDATA)> <!ELEMENT homepage (#PCDATA)> <!ELEMENT creditcard (#PCDATA)> <!ELEMENT profile (interest*, education?, gender?, business, age?)> <!ATTLIST profile income CDATA #IMPLIED> <!ELEMENT interest EMPTY> <!ATTLIST interest category IDREF #REQUIRED> <!ELEMENT education (#PCDATA)> <!ELEMENT income (#PCDATA)> <!ELEMENT gender (#PCDATA)> <!ELEMENT business (#PCDATA)> <!ELEMENT age (#PCDATA)> <!ELEMENT watches (watch*)> <!ELEMENT watch EMPTY> <!ATTLIST watch open_auction IDREF #REQUIRED> <!ELEMENT open_auctions (open_auction*)> <!ELEMENT open_auction (initial, reserve?, bidder*, current, privacy?, itemref, seller, annotation, quantity, type, interval)> <!ATTLIST open_auction id ID #REQUIRED> <!ELEMENT privacy (#PCDATA)> <!ELEMENT initial (#PCDATA)> <!ELEMENT bidder (date, time, personref, increase)> <!ELEMENT seller EMPTY> <!ATTLIST seller person IDREF #REQUIRED> <!ELEMENT current (#PCDATA)> <!ELEMENT increase (#PCDATA)> <!ELEMENT type (#PCDATA)> <!ELEMENT interval (start, end)> <!ELEMENT start (#PCDATA)> <!ELEMENT end (#PCDATA)> <!ELEMENT time (#PCDATA)> <!ELEMENT status (#PCDATA)> <!ELEMENT amount (#PCDATA)> <!ELEMENT closed_auctions (closed_auction*)> <!ELEMENT closed_auction (seller, buyer, itemref, price, date, quantity, type, annotation?)> <!ELEMENT buyer EMPTY> <!ATTLIST buyer person IDREF #REQUIRED> <!ELEMENT price (#PCDATA)> <!ELEMENT annotation (author, description?, happiness)> <!ELEMENT author EMPTY> <!ATTLIST author person IDREF #REQUIRED> <!ELEMENT happiness (#PCDATA)>
Figure 17.3. Queries Specified in the XMark Benchmark
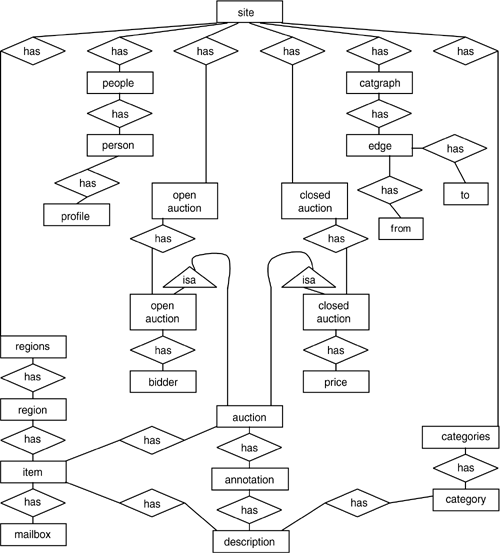
The XMark Queries
XMark provides 20 queries that have been evaluated on an internal research prototype, Monet XML, to give a first baseline. Table 17.5 shows the XMark queries and our comments. For the sake of a consistent comparison, we divide the queries into four groups based on the query functionality. Group I contains simple relational queries with comparisons on various types of data values. Queries in Group II are document queries that preserve the element order. Group III contains navigational queries. For example, Q8 and Q9 check the navigational performance in the presence of ID and IDREF, while Q15 and Q16 test long path traversals. Queries in Group IV require aggregate handling and sort operations.
|
Group |
ID |
Description |
Comment |
|---|---|---|---|
|
I |
Q1 |
Return the name of the person with ID 'person0' registered in North America. |
Check ability to handle strings with a fully specified path. |
|
Q5 |
How many sold items cost more than 40. |
Check how well a DBMS performs since XML model is document oriented. Checks for typing in XML. |
|
|
Q14 |
Return the names of all items whose description contains the word 'gold'. |
Text search but narrowed by combining the query on content and structure. |
|
|
II |
Q2 |
Return the initial increases of all open auctions. |
Evaluate cost of array lookups. Authors cite that a relational backend may have problems determining the first element. Essentially query is about order of data which relational systems lack. |
|
Q3 |
Return IDs of all open auctions whose current increase is at least twice as high as initial. |
More complex evaluation of array lookup. |
|
|
Q4 |
List reserves of those open auctions where a certain person issued bid before another person. |
Querying tag values capturing document orientation of XML. |
|
|
Q11 |
For each person, list the number of items currently on sale whose price does not exceed 0.02% of person's income. |
Value-based joins. Authors feel this query is a candidate for optimizations. |
|
|
Q12 |
For each richer-than-average person list the number of items currently on sale whose price does not exceed 0.02% of the person's income. |
As above. |
|
|
Q17 |
Which persons don't have a homepage? |
Determine processing quality in presence of optional parameters. |
|
|
III |
Q6 |
How many items are listed on all continents? |
Test efficiency in handling path expressions. |
|
Q7 |
How many pieces of prose are in our database? |
Query is answerable using cardinality of relations. Testing implementation. |
|
|
Q8 |
List the names of persons and the number of items they bought. |
Check efficiency in processing IDREFs. Note a pure relational system would handle this situation using foreign keys. |
|
|
Q9 |
List the names of persons and the names of items they bought in Europe (joins person, closed auction, item). |
As above. |
|
|
Q10 |
List all persons according to their interest. Use French markup in the result. |
Grouping, restructuring, and rewriting. Storage efficiency checked. |
|
|
Q13 |
List names of items registered in Australia along with their descriptions. |
Test ability of database to reconstruct portions of XML document. |
|
|
Q15 |
Print the keywords in emphasis in annotations of closed auctions. |
Attempt to quantify completely specified paths. Query checks for existence of path. |
|
|
Q16 |
Return the IDs of those auctions that have one or more keywords in emphasis. |
As above. |
|
|
IV |
Q18 |
Convert the currency of the reserve of all open auctions to another currency. |
User defined functions checked. |
|
Q19 |
Give an alphabetically ordered list of all items along with their location. |
Query uses SORT BY, which might lead to an SQL-like ORDER BY and GROUP BY because of lack of schema. |
|
|
Q20 |
Group customers by their income and output the cardinality of each group. |
The processor will have to identify that all the subparts differ only in values given to attribute and predicates used. A profile should be visited only once. |
| Top |







