|
Microsoft has positioned SQL Server 2005 as the back-end data platform for the Microsoft Office System and most of its enterprise products, with the notable exception of Microsoft Exchange. The database engine serves up data; Integration Services (SSIS) provides extracts, transformations, and loading of data; Analysis Services provides business intelligence; and Reporting Services serves the online and analytical reporting needs of the organization. The Service Broker allows for an HTTP-based messaging system to enable service-oriented applications (SOAs), and Replication allows for disconnected recordsets and high availability along with Clustering and several other technologies. And these are just the delivered services and features, not what you can create with them. Each of these features has multiple components in their individual architectures, and keeping everything straight can be a challenge.
There are a couple of approaches to comprehending the architecture in a product as large as SQL Server. The first is to take each component and break down its parts, examining how it operates. The second is to trace what happens when an operation is performed. I do a little of both in this chapter. I start with the physical "footprint" of the system and then explain how the database engine behaves. I then cover the objects within a database and finish up with how an application communicates with the server. I use that process to tie the physical, engine, and objects concepts together.
Physical Footprint
As in all software, SQL Server is at its core a mixture of files and registry settings. Some files store the code to run the software (called the binaries), and other files store the data the system produces. For this discussion, I call the first set operational files and the second set data files.
Operational Files
You may recall from the first chapter that I mentioned that you want to keep the various SQL Server files apart for optimal performance. In this section, I explain the default locations for operational and data files, and you can extrapolate to the drive letters you selected during your specific installation.
Assuming you have taken the default file locations and a standard installation, the base directory is found at C:\Program Files\Microsoft SQL Server. Within that, the following table shows the rest of the directories and their primary uses.
Location | Primary Use |
|---|
C:\Program Files\Microsoft SQL Server | Base directory | C:\Program Files\Microsoft SQL Server\MSSQL.1 | System database files, log files, and default backup location | C:\Program Files\Microsoft SQL Server\MSSQL.2 | OLAP database files, log files, and control files, if installed | C:\Program Files\Microsoft SQL Server\90\ MSSQL.3\Reporting Services | Reporting Services databases, binaries, and assemblies, if installed | C:\Program Files\Microsoft SQL Server\90 | | C:\Program Files\Microsoft SQL Server\80\COM | Legacy files | C:\Program Files\Microsoft SQL Server\90\COM | Replication control files | C:\Program Files\Microsoft SQL Server\90\DTS | SQL Server Integration Services files | C:\Program Files\Microsoft SQL Server\90\NotificationServices | Notification Services control files | C:\Program Files\Microsoft SQL Server\90\SDK | Software development files, if installed | C:\Program Files\Microsoft SQL Server\90\Setup Bootstrap | Setup files | C:\Program Files\Microsoft SQL Server\90\Shared | Interface files and error dumps, and the Surface Area Configuration Tool | C:\Program Files\Microsoft SQL Server\90\Tools | SQL Server tools, with the Visual Studio hooks (By default, this is where all projects are stored, too.) | C:\Program Files\Microsoft SQL Server 2005 Sample | Samplesdatabase files, source files, and script files, if installed
| C:\Documents and Settings\Username\My Documents\SQL Server Management Studio | User backup files, settings, and templates for projects | C:\Documents and Settings\Administrator\My Documents\Visual Studio 2005 | User templates for projects, if installed |
The Samples directory is not off of the main SQL Server directory by default. When you install your instances, you can change that if you like by editing the Advanced settings in the installer panels.
Data Files
The data files are actually made up of two kinds of files. The first stores data, with the extension of .mdf, which stands for Microsoft Database Format. The second stores the log files, which have the extension .ldf, standing for Log Database File.
Having the log files separated from the database files provides many benefits. The first is greater speed. Because the data is written sequentially to the log file, it is not blocked by nonsequential writes to the data file. And, because data is read nonsequentially from the data file, those reads do not block the transaction writes in the log.
The separation of transaction and data files also provides safety. Depending on the recovery model, you can then back up the (smaller) log files frequently, even once per hour or more. Because the database backups contain all the data to a point in time, and the log backups contain all the changes, if the database has an issue, you can restore the database to the last backup and then restore the log file(s) to the database. Your database is then up-to-date as of the last log backup. I cover this process in great detail in Chapter 3, "Maintenance and Automation."
You can have more than one of each of these kinds of files. In fact, you can create as many database and log files as you want. Placing them on different physical devices will help with performance, because you can specify what database objects, such as tables and indexes, are placed on these files. That allows you to plan the layout of your database, separating the heavily used objects onto different physical devices. Because those devices can deliver the data without interfering with each other, you get better response. I deal more with performance tuning in Chapter 5, "Monitoring and Optimization." You can have up to 32,767 files per database, and they can be 16 terabytes in size.
You can logically group the data files into filegroups. The process is quite simpleyou create a filegroup and name it, and when you create files you can specify which of these filegroups you want them to use. You can then back up and restore filegroups independently of each other, which is useful in large databases. You always have one filegroup called Default, and you can make up to 32,766 more.
The Query Process
The two types of data files work in concert to store and retrieve data for applications. These applications either change data (which includes adding, deleting, and editing) or request data. All of these operations are generically called queries, although the word query is often used to describe a request for data. Queries are generated from various programming methods, which I explain a little further in this chapter.
What follows is a high-level description of the query process. It does not differ much from most any Relational Database Management System. In the next section, I explain the low-level details of the entire data flow through SQL Server 2005.
When an application enters, edits, or deletes data, it submits a transaction. That package of information is communicated across the network layer on the client machine to the server network layer and then on to the database engine.
|
You can think of a transaction in terms of an ATM transaction at your bank. Suppose that you decide to move $100 from your savings account to your checking account. If the money comes out of savings, you want it to go into checking, or not happen at all. The bank is concerned that if the money goes into checking, that it also leaves savings. Otherwise, they do not want anything to happen either. The idea that a group of things happen as a unit is a transaction.
|
Once submitted, the transaction is entered into the transaction log. After it is recorded there, a logging process enters the data into the database. Depending on a configuration setting that I explain later, the transaction is kept in the log until a backup is taken, or it is erased from the log after it is committed to the database.
Unless you specify otherwise, all transactions go through this process. What this means is that if you enter a row of data and then immediately delete it, both transactions go through the log. The only time that this does not hold true is when you enable the database to bypass the log when a special import process is run, called a bulk load.
When an application retrieves data, the client submits a query through whatever connection method the application uses, once again using the networking layer on both systems, sending the request on to the database engine. The database engine uses the Query Processor to locate the data in the physical files. The data is returned as a dataset to the client through the networking layers of the server and then the workstation.
The Database Engine
The database engine is the core process within SQL Server 2005 that moves data in and out of the physical files (I/O). The physical files I mentioned earlier map to logical files that SQL Server works with. The name of these logical files, what objects they store, and their physical names are stored in the master database, which is SQL Server's primary control file.
SQL Server automatically recovers itself in case of a problem shutdown. On the rare occurrences where the server does not have a chance to commit all the entries in the transaction log to the database before it shuts down, the system either rolls forward, meaning that the log entries (transactions) are written to the database, or rolls back, meaning that the transactions are not deemed complete and are not entered in the database at all. When either of these things happens, an entry is made into the Windows Application Log and the SQL Server error logs. I explain how to read those logs in Chapter 4, "Security."
Another of the database engine's primary tasks is to run the Query Processor. The Query Processor intercepts all calls made to the database and interprets them to develop a query plan that details the most efficient path to the data stored in the database and log files. If it can, the Query Processor will reuse a plan to get the same data when called for, making those queries even faster. The biggest impacts on the Query Processor's performance are the system's CPUs and memory.
The Query Processor, along with several dozen other processes, lives in memory while SQL Server is running. Data is also cached in memory. That is why SQL Server, like most Relational Database Systems, needs a lot of RAM. In Chapter 5, I explain how to watch these items and determine when you need more memory on your server.
The database engine passes off the transaction results to the networking layer, which in turn talks to the Windows networking layer. The more protocols you have enabled on SQL Server, the more cycles are used to deal with them. For this reason, it is best not to enable protocols you do not need. By default, some SQL Server 2005 editions only enable the Shared Memory protocol, which allows the system to talk to itself on the same machine only. In the section on tools that follows, I show you how to change that.
Objects
The database engine, along with the other processes, is designed to move data back and forth to and from a client. To facilitate a fast, safe environment, SQL Server 2005 uses several objects to store and optimize the data. I classify everything in SQL Server that is not a process to be an object.
Database
The first object is the database. The database is the outermost collection object, which means that it contains other objects. Databases have logical files defined in it that point to the location of physical files on the storage subsystem. Databases also have user logins associated with them, which I explain further in Chapter 4.
There are two categories of databases within SQL Server 2005: system databases and user databases. Both have the same structure; it is just that they are used for different reasons.
System Databases
The first system database is called master. This database contains the data used by SQL Server 2005 for all its operations, including security, and mounting and configuring all the other databases and their objects.
|
You can query the tables in the master database directly, but Microsoft provides lots of customized views and functions to get at the data they contain. In previous versions, Microsoft also provided system views, but they were not complete, and most administrators worked around them by writing queries directly against the system tables. This is usually a bad idea because the system tables are apt to change. Microsoft does not guarantee that the master database structure will remain constant throughout the life cycle of the product.
Because you should not write code depending on the master tables, understanding the system views and functions is essential for managing your system. In Chapter 5, I explain what the system views and functions do and how you can use them. Get in the habit of using these functions; they are safer than using the system tables.
|
The model system database is just thata model for any other databases that you create. When you create a new database and you do not specify any options, the model database structure is used as a template. You can place any other objects that you want in every database in the model database, and new databases will "inherit" those objects. This does not apply to databases that you restore from a backup, just the ones you create directly in code or using the graphical tools.
The msdb system database contains all the scheduling information, jobs, alerts, and operators (more on those in a moment) that SQL Server 2005 uses for things such as maintenance and replication. It also stores history entries for maintenance plans and database backups, as well as the SQL Agent metadata. System views and functions query from this database for that information.
The final system database is tempdb. This is SQL Server's "scratch" area. Whenever a query has an ORDER BY clause that sorts data for a query, or SQL Server itself needs to sort the results of a query or do some other intermediate work, it is done in tempdb. This database is destroyed and re-created each time the server is started, so you do not want to put anything into this database that you need to keep. When your developers create an in-memory table (called a temporary table), it is stored in the tempdb database.
|
It is best if you do not modify system databases at all, other than perhaps to add objects into the model database. Whenever a new service pack comes around, the system databases are fair game for changes by Microsoft, and during upgrades you are sure to have issues if you change them. You also risk the stability of your system when you add or change anything on the system databases.
|
User Databases
User databases are those you create. There are a few ways to create a new database, such as issuing a Transact-SQL (T-SQL) command, using a programming method, or using graphical tools. I show you a few of these in the "Tools" section of this chapter. Another way is to restore the database from a previous backup. You can use a backup from the same server or even a backup file from another system. I explain that process in Chapter 3.
Yet another way that you can create a database is to attach it. This involves disconnecting a database from a system, copying the files elsewhere, and then connecting the files. You can detach and attach a database on the same server or even another SQL Server 2005 system.
To detach a database using the graphical tools, right-click that database and select Detach from the menu. This shuts that database down gracefully, and then removes the logical entries for the files it uses from the master database. You can then copy the physical files to the new location and right-click the databases object; select Attach from the menu and enter the location for the files. The system makes entries for the new database in its master database and starts up the database.
Within each user database are system tables, views, and other objects. After you create the database, you can start putting other objects in it right away.
Databases have states, which indicate how they can or cannot be used. You will see these states when you first start the graphical interfaces or you can use the T-SQL statement of SELECT for the state_desc column in the sys.databases catalog view (more on that later).
You can also call the Status property in the DATABASEPROPERTYEX function to give you the same information.
State | Available | Meaning |
|---|
Online | Yes | This is the normal state for a database and means that it is ready for use. | Offline | No | This state is something that you set, when you want to remove it from use but not from the server. Use this state to move files around. | Restoring | Yes, for those filegroups not being restored | This state indicates that the database is being restored from a backup. | Recovering | No | This state indicates that the transactions in the log are being checked and if needed are rolled forward or back. | Recovery Pending | No | This state requires you to intervene. Either system resources or files are unavailable to complete the recovery process. | Suspect | No | One or more filegroups is not consistent at the operating system level. |
There are also various synchronizing states for a database involved in mirroring, which I discuss in Chapter 7, "Notification Services and the Service Broker."
As far as the technical details go, the database size depends largely on the edition you use (see Chapter 1, "Installation and Configuration") and the operating system file limitations, but the larger editions can scale database sizes up to 1,048,516 terabytes. In each instance of SQL Server, you can have up to 32,767 databases. You can have up to 50 instances on a single server.
Schema
SQL Server 2005 uses an abstraction object called a schema. A schema is simply a naming object within a particular database, which in turn "owns" other objects. Users are granted rights to the schema so that they can access the objects the schema owns. This allows the database to have multiple tables called "product," for instance, and by using a separate schema name you can keep them separate. It also allows for objects to remain independent of users, so that when user accounts change, the object does not have to.
You are limited to 2,147,483,647 objects in any database, and schemas come out of that limit. In other words, if you had only one table and one user, you could have roughly 2,147,483,645 schemas.
Table
The next object within a database is the table. A table is an entity in a relational system that provides columns and rows of data. You can think of a single spreadsheet as a table.
I do not cover table design here, but to design tables properly, you should be familiar with a little relational calculus.
|
All the relational calculus you need to know right now is that in a relational system, tables should contain discrete data that is stored only once. To allow multiple rows to show the same data, Sequential Query Language (SQL) selects from various tables, joining them on a common field. A field that uniquely identifies a row in the table is called a key field. You can use one field in a table to point to the key field anotheran object called a foreign key.
This means that you would store a customer's name one time, with a single field in that row designating that customer, say, customer_number. When you place multiple orders for that customer, a field in the orders table would contain this single number, one per order, to show that a group of orders belonged to a particular customer. In that way, you could change the customer's name once, and all the orders would point to the new name, provided the number stayed the same.
In this case, the customer_number field in the customers table is called the primary key or key, and the customer_number field in the orders table is called the foreign key. The customer_key in the customers table can appear only once, and the customer_key in the orders table can appear multiple times. Combining the two in a query is called a join.
|
If it helps to have an analogy, you can think of the SQL Server environment as a building. The databases are the floors on that building, and the offices are the schemas within the database. A file stored in an office could be considered a table. Thinking of the database this way will help give you a basis for understanding the security chapter a little later on.
Tables form the basis for all your data. You have the same object limitation (2,147,483,647 objects per database) I mentioned earlier to take the number of tables from. You can have up to 1,024 columns in a table, and as many rows as storage space allows. The rows can be 8,096 bytes long (each). There are 16 columns allowed for a primary or foreign key, and you can have 253 foreign keys referencing a table.
View
A view is a T-SQL set of code that selects data from one or more "base" tables, and the result looks like a new table. For instance, if you took the customers and orders tables I mentioned earlier, and joined them with a T-SQL statement as a view called cust_orders, you could query the cust_orders view as if it were a real table. I show you an example of this in the "Take Away" section that follows.
Views are used to partition data by selecting only certain columns or by selecting rows where they match a certain criteria. You can combine the two to limit or simplify the data your users will see.
You can also use views to hide the structure of base tables, because you can name and order the columns differently in the view than they are in the tables. You can also combine multiple tables in a view to present them as a single table.
Often your base tables and the columns will see their names or structures change over time. If your application's code is based on those tables, the code will also need to be changed. However, if your developers base their code on views, you can simply change the view to reference the new table or column names and the original code does not have to be touched.
Views have a few limitations. You can only update data into one of the base tables at a time through a view. If you want to change the value of three columns in our sample view in a single statement, they need to be in either the customers table or the orders table, but not both.
The same overall objects limitation number holds for creating views, and there are a couple of other numbers to know. You can reference up to 256 base tables in a SELECT statement (which forms the basis for a view), and you can have 4,096 columns referenced in a view. You can get around some of these limits by having one view select data from another.
Stored Procedure
A stored procedure is similar to a view, in that it is a bunch of code that runs on the server and returns a result. The difference is that a view is unchanging. Whatever you have entered as the code for a view is that way until you delete (or drop) and re-create it. A stored procedure can accept parameters from users or code. A stored procedure can return data, a status, or perform some other work in the database. Stored procedures can be used like a view to hide the complexity of a table or to slice and dice the data.
Stored procedures have another advantage over views. SQL Server 2005 will evaluate the stored procedure the first time it is run and compile it into a faster form. This makes the stored procedure perform better when it is called again. You might hear this referred to as "server-side code" in some documentation, because it is processed and cached on the server. This is another reason that the server is so memory intensive.
Microsoft provides several stored procedures right out of the box, and we will be working with a few of those throughout this book.
A stored procedure has the same limits as a view as far as object counts go, and the text that forms the code for a stored procedure must be smaller than 250 megabytes. If you have a single stored procedure anywhere over 2 megabytes, you probably need to examine the codemost stored procedure code is only a few thousand bytes.
Trigger
A trigger is another set of T-SQL code similar to a stored procedure, but rather than being called by the user, it executes on certain conditions. The two kinds of conditions are when users alter data, called Data Manipulation Language (DML) operations, and when the structure of an object changes, called Data Definition Language (DDL) operations. In other words, this is code that runs when the user issues a statement that updates, edits, or deletes data, or runs a statement that changes the structure of the database objects.
For DML, the trigger types are INSERT, UPDATE, or DELETE statements against a table or view, and for DDL statements you can "fire" triggers for CREATE, ALTER, DROP, GRANT, DENY, REVOKE, or UPDATE STATISTICS statements. Triggers normally fire directly on the statement's call, but you can specify that they fire after the code on the table or view completes.
Another type of trigger, called an INSTEAD OF TRigger, fires when the statement is run but does not run the statement. When the statement is called, the code in the trigger runs instead. For instance, if you make an INSTEAD OF trigger on a table for a DELETE operation, when the user tries to delete data from the table, the trigger could print text on the screen that says "Do not delete this record. Archive it instead."
Triggers can become highly complex, and a logic-flow diagram is essential to track them properly when they get a few levels deep or when they implement complex functions.
Developers often use triggers to enforce business logic. In SQL Server 2005, you can also use the Common Language Runtime (CLR) feature to have entire programs run as a trigger. Your developers might, for instance, have a C# program act as a trigger to gather metrics from a Web service when a new order is entered.
Special settings are available to your developers to prevent recursive triggers from firing. If the developers are not careful, an INSERT to table A might cause a DELETE in table B, which might have an DELETE TRigger to perform an INSERT to table A, which in turn causes another DELETE to table B. That is a recursive trigger, and you normally want to prevent that kind of situation.
In any case, you can only "nest" triggers 32 levels deep. Triggers are also part of the 2,147,483,647 objects per database limit.
Function
A function is yet another set of T-SQL or CLR code, similar to a stored procedure that returns a value to the user. It falls under the same 2,147,483,647 objects per database limit.
Functions can return a table, and can even be used recursively in a query. This makes them very powerful for developing server-side code. SQL Server 2005 contains several system functions, and you can create your own user-defined functions (UDFs).
Index
An index is really another table but contains ranges of data and the physical location where the data is found. It is like an index in a book, showing where the data is located. SQL Server uses B-Tree indexes, which sequentially branch off of the ranges of data in an upside-down tree fashion.
Indexes make reads fast, but cause a slight penalty when data is written. This performance tradeoff is one of the primary factors you will use when you begin to tune your system, something I will cover in Chapter 5. To create an index, you name it and specify the columns that will be indexed. These columns are then said to be "covered."
There are two types of indexes: clustered and nonclustered. In a clustered index, the table is physically rearranged to the order of the indexed columns. In our fictional customers table, we might create the clustered index on the primary key, and the table would be physically arranged from 1 to 100, for instance. Because the table is physically arranged by the clustered index, there can be only one clustered index per table. In fact, the clustered index is the table.
It is also a good idea to cluster those columns that are additive, because the entire table would have to be relocated on disk every time an earlier number is inserted.
The other type of index is called a nonclustered index, and is another table-like structure entirely. It stores the range of data and a pointer to where the data is stored. When query references columns found in the index, the Query Processor process will use the index to look up the physical location of the data. If you reference only the columns in the index, SQL Server does not have to access the table at allit can get the data right from the index itself. That is called a "covered query."
You can have 249 of these indexes, and each can reference up to 16 columns. Indexes come out of the same object number limitation as everything else.
Job
A job is a special set of entries into the msdb database. Jobs contain steps, which are made up of tasks such as T-SQL queries, ActiveX scripts, operating system calls, and more. Steps have conditions, such as success or fail, which you can string together to loop or jump over one step to another to form simple logic.
You can call a job from a stored procedure, directly within T-SQL code or from a programming library. Jobs can also be called by an alert (see the next section). Jobs also have schedules, which tells the job when and how often to run. Jobs are used extensively by SQL Server itself; replication even depends on them.
Jobs have a status, which can be logged. Jobs interact with operators, which I explain in a moment. Jobs can also record their history automatically, which you can query.
Jobs are run by the SQL Server Agent service. If that service is not started or does not have an account associated with it that is allowed to perform the tasks, they will not run. I explain jobs in greater detail in Chapter 5.
Alert
An alert is a condition that is raised based on an event, such as a full database file or other system and database-related action in SQL Server 2005. Developers can code them to receive system responses in their programs. Microsoft delivers several system alerts right out of the box, mostly dealing with system-level events, and you can make more alerts for just about anything that happens on your server. The system events are triggered by the server engine, and user-defined alerts can be called by a server condition or directly in code.
An alert is made up of an error number, a severity level, a database reference, event texts, and actions.
The error number is a reference, so that you can track the alert in the Application Log in Windows or in the SQL Server logs. The error number is the identifier used to call a particular alert from code. Developers can also watch for these error numbers in their own code.
The severity level indicates how big an issue the alert is. Microsoft reserves levels 19 through 25 for itself and sends a SQL Server message to the Microsoft Windows Application Log when they occur.
Events with severity levels less than 19 trigger alerts only if you use the stored procedures called sp_altermessage or xp_logevent, or if you use the T-SQL statement RAISERROR WITH LOG to force them to be written to the Windows Application Log.
The database reference sets which database the alert fires in, and the event text specifies the message the alert generates.
An alert can do two thingsit can send a message to an operator (see below) or it can run a stored procedure or script. Putting all of this together, you can code an alert that is called by a program, which then inserts an entry into the SQL Server logs and the Windows Application Log, sends a message to the application, and then runs a job. All with a few lines of T-SQL code.
Operator
An operator is a set of identification information such as a name, network login, e-mail addresses, and pager number. SQL Server can send messages to operators, alerts and jobs can both notify operators, and automated maintenance plans can send an operator a message containing the results of system maintenance.
It is important to note that anyone can be an operator, not just people in IT. You can define any user as an operator and have the system send them a message based on code, jobs, or alerts.
You will want to create at least one failsafe operator that receives messages when the system cannot reach anyone else. That operator is normally the administrator for the system.
Communication Processes
Let's expand the view of the path that a data request takes that I mentioned earlier. We start with a fairly complex graphic (shown in Figure 2-1), and I explain each part as we drill down through the levels.
[View full size image] 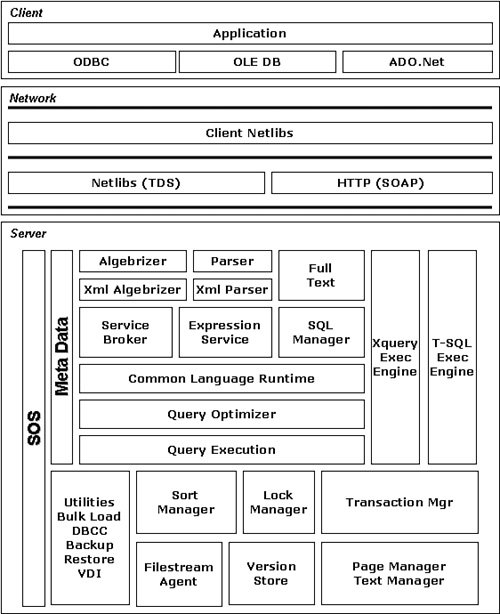
Application
Although this book does not deal with writing programs for SQL Server 2005, a little development background is useful to help you properly size and design your systems. It can also help you with troubleshooting.
The possible applications for SQL Server 2005 include "rich" or "fat" clients, Web interfaces, and development and maintenance tools. Rich clients are developed using C#, Visual Basic, C++, Java, or some other high-level programming language. These programs are compiled and placed on a client machine. Often these types of applications make frequent calls to the database server, and as a result use more resources.
Web interface clients include those based on a Web site or those that use Web protocols. These interfaces, when coded properly, normally take fewer resources on the local system than a rich client.
When you use the SQL Server Management Studio or a third-party tool to manage or control SQL Server, you are still using an application as far as SQL Server is concerned.
Regardless of which type of client or interface is used, all programs use a connection method, a library, and a network protocol to access the server.
Connection Methods
An application that is coded for SQL Server 2005 can use several methods to connect to the server. These are not network connections; they are programmatic connections.
ODBC
One of the most popular and widely used connection methods is Open Database Connectivity (ODBC). ODBC is made up of a provider, a data source name, and options. The provider is a library supplied by a database or other software vendor that allows connections to their software. The Data Source Name (DSN) is a group of settings stored either in a user-specific registry entry, one that is generic to the whole system, or DSN information that is stored in a file. These settings provide the name of the server, the database name, and the security credentials. Each provider offers options for the connection such as tracing and language settings.
ODBC is mature, well understood, and supported by every major platform and database vendor. The disadvantages with an ODBC driver are its speed and the need in many cases to configure the client to use it.
Microsoft ships several vendors' ODBC drivers natively on the Windows platform, but most vendors supersede the installed drivers with their own. This does not cause any problems with SQL Server 2005 because it updates the Windows system when the client tools are installed, but some third-party drivers have been known to cause issues with stability on the client.
OLE DB
To address some of the shortcomings of ODBC and allow for a distributed computing environment, Microsoft created Object Linking and Embedding for Databases (OLE DB). OLE DB is basically a set of Component Object Model (COM) interfaces for applications to access database functionality and datasets. With an OLE DB connection, the client machine does not need to create a data source name, and the developer can create a connection to the server, and provide locations and credentials all within code.
Both ODBC and OLE DB use a set of components within the Windows operating system called Microsoft Data Access Components (MDAC). The MDAC is a series of software libraries, binaries, and utilities that are so spread into the operating system that it is difficult to tell which version is installed.
You can search for the msador15.dll file in the Program Files directory and then view the Properties tab to find what version of MDAC your system is using. Microsoft also has a tool you can use to check the version of MDAC, called the Component Checker. You can find that by searching the Microsoft Knowledge Base for item 301202.
The primary issues you will run into crop up when the MDAC version on the client or middle tier is different than on the server. It is best to pair these up, but the developers sometimes require a certain version for their applications to work properly.
JDBC
Microsoft wants to make SQL Server 2005 widely available to all coding platforms, so they developed a Java Database Connection (JDBC) driver to provide access to SQL Server 2000 and SQL Server 2005. You can use this driver from a Java application, application server, or Java-enabled applet. It is a Type 4 JDBC driver using the standard JDBC application program interfaces (APIs) available in Java2 Enterprise Edition (J2EE). This is updated on the Microsoft SQL Server site, so after you have completed your installation, you can download the latest one from there.
DB-Library
DB-Library, or DBLIB as it is sometimes called, actually belongs to both connection methods and APIs (see below). It is a proprietary library used by early versions of SQL Server, most commonly seen in C (and C-based) programs. Prior to the ODBC and then JDBC connectors, DB-Library was often used on UNIX-based client systems to program SQL Server applications.
Application Programming Interfaces
Within each connection method, there are various programming libraries called application programming interfaces (APIs). These interfaces represent functionality the developer uses to perform database-related tasks. The developers can use standard T-SQL statements to manipulate data and database objects or use the API functions to do the same thing.
The API functions work by instantiating an object, such as a database, making a connection to it, and then calling methods or properties to work with them. One type of method the developer can use is the "command," which accepts and passes T-SQL statements.
|
Methods are things that objects can do and can be enacted. Properties describe the object and can be set. For instance, a method for a dog might be "Bark," and a property for the dog might be "Color."
|
The other ways of using an API is to instantiate an object, such as a database or table, and then call methods against it, such as "backup" or "query." If the developer follows this process, the code they create is independent of the language extensions for a particular database platform. The code could just as easily run against SQL Server as Oracle.
RDO/DAO
Two of the earliest programming interfaces are Remote Data Objects (RDO) and Data Access Objects (DAO). They were the first attempts at providing a distributed environment for applications. Both had fairly significant drawbacks, and you will not see a great many applications using these libraries in newer applications.
ADO/ADO.Net
ActiveX Database Objects (ADO) and the newer ADO.Net provide far more functionality than that found in RDO or DAO. One of the primary enhancements was that the developer can address independent objects such as tables and rows without having to navigate a hierarchy as they did in RDO.
ADO is one of the most popular programming libraries in use, and to allow for a smooth transition to the .NET environment Microsoft updated the library to ADO.NET. This newer library is largely backward compatible with ADO and allows the developers to use what they already know and take advantage of the managed environment that the .NET suite provides.
SQL Native Client
The SQL Native Client is the newest programming library provided by Microsoft. It is basically one dynamic link library (DLL) that combines the functionality of the OLE DB and ODBC libraries and provides new features. The SQL Native Client can take advantage of SQL Server 2005 features such as Multiple Active Result Sets (MARS), User-Defined Types (UDT), and XML data type support. This is the preferred library for newer development efforts.
SMO
In earlier versions of SQL Server, a library called Distributed Management Objects (DMO) allowed developers to write management applications. The objects exposed in this library dealt more with maintenance and performance monitoring than the other programming interfaces, although with a little work both could be made to do the same things.
In SQL Server 2005, the DMO library is replaced with a more powerful set of interfaces, called Server Management Objects (SMO). As a maintenance DBA, you might not program often, but when you do the SMO library is the one to learn.
Client Network Library
After the connection method and programming library are coded, the application uses a connection method to talk with the network protocols. Networking protocols include TCP/IP, Named Pipes, and those installed by other network applications. These protocols have properties based on what they provide including encryption, compression, and so forth. If you enable those on the client, they need to match what is enabled on the server.
You will find that TCP/IP is often faster than Named Pipes, but that depends on the environment and the coding techniques in the application. TCP/IP is more secure than Named Pipes.
SQL Server 2005 also comes with the Shared Memory protocol. Shared Memory is a protocol that you can use when the client and the server are on the same machine. Because the packets do not have to travel on a physical network card, speed and security are increased. The MDAC mentioned earlier can only use Shared Memory in versions 2.8 and higher.
Another protocol in SQL Server 2005 is the Virtual Interface Adaptor (VIA), which works with special adaptors shipped with some systems.
To set the protocols and their options, you use the SQL Server Configuration Manager tool available from the Start menu under Microsoft SQL Server 2005 > Configuration Tools > SQL Server Configuration Manager. I show you that tool in a moment.
Server Network Library
Moving to the server side of the transaction, SQL Server 2005 listens for network calls using a similar set of network libraries to those installed on the client. This layer also handles encryption at the network level. You may have more protocols enabled on the server than on a particular client so that the server can answer the various protocols on each client. If you find that you have a protocol enabled for the server that none of your clients are using, disable it. It is safer and improves performance.
You use the SQL Server Configuration Manager tool available from the Start menu under Microsoft SQL Server 2005 > Configuration Tools > SQL Server Configuration Manager to set options on the server as well as the client.
In addition to network protocols, SQL Server 2005 uses two other "shims" between the engine and the networking layer. The first is called the tabular data stream (TDS), which is a streaming protocol for moving data in and out of the server. There is nothing for you to set or tune here, but you might see it mentioned in an error log or program return.
The second is a layer that may be called from Internet connections that make up the Simple Object Access Protocol (SOAP). This layer allows SQL Server 2005 to communicate using HTTP and XML and also provides the "endpoints" that SQL Server uses. I describe endpoints in more detail in Chapter 4 and Chapter 7.
Algebrizer
Most of the time, the path a query takes can be explained in simple terms. The query originates at the client, as we have seen, and then is passed to the network layer on the client, which talks to the network layer on the server. The server processes the request and then returns the result through the networking layers back to the client.
Although it is not as important to understand each and every part of what the server does with the request once the networking layer contacts the SQL Server engine, it is interesting to know what the query goes through to process the request. The first thing that SQL Server does with a query it receives from the networking layer is to implement the SQL Server Algebrizer. The Algebrizer dissects the T-SQL code, and then creates an operator tree, which uses further scalar and relational operators to determine how to split up the query. The Algebrizer also takes a part in determining how much parallelism the server can implement on the query, and also where to locate some objects in cache memory.
And that is not allthe Algebrizer also helps determine the best way to work with subqueries and aggregate functions, which are two of the thorniest problems in database theory.
As you can see in the flow diagram, there is also an XML version of the Algebrizer. This separate function is necessary to work with the hierarchical data in an XML document as opposed to the relational calculus used by the Algebrizer.
Parser
When the query is split up, the Parser breaks the smaller queries down even further. Just like the Algebrizer, there is also an XML twin for this process, called the XML Parser.
Full Text
If the query calls for an operation involving full text queries, the Full Text process calls out to an external engine for text string parsing.
Service Broker
Next in line is the Service Broker. This component allows the developers to build disconnected or federated, applications, and this process handles where those requests should be processed.
Expression Service
In some queries, particularly those involving stored procedures, SQL Server has to deal with variables. The Expression Service process handles variables and parameters.
SQL Manager
The SQL Manager process takes care of stored procedures and how they execute. Some T-SQL statements, even those not found in a stored procedure, are also handled by the SQL Manager, especially if they use auto-parametized queries.
T-SQL Exec Engine
The T-SQL Execution Engine and its XML counterpart, the XQuery Execution Engine, are responsible for T-SQL language processing. They interpret the T-SQL or XQuery (the XML querying specification) statements and break them down into parts, checking to ensure the syntax is correct.
Common Language Runtime
The CLR process provides communications to .NET libraries. This is a new feature in SQL Server 2005 and allows developers to extend the power of the database engine by writing high-level code that can be called inside T-SQL just like a stored procedure or a function. Developers compile the code and then instantiate it into the database, or they can use Visual Studio to develop and instantiate the assembly directly into the database.
This ability is both a blessing and a curse. Providing a high-level language processor gives an incredible amount of flexibility to the platform, but also allows for poorly written code to disappear into a black box. Great care should be taken in implementing this feature.
The CLR has proven to be very stable, so it will not easily crash your SQL Server. Because of the security implications, however, you have to enable the CLR on a SQL Server before the developers can instantiate any assemblies into the database. To do that, you can use the SQL Server Surface Area Configuration (SAC) tool, or run the following statements on SQL Server 2005:
EXEC sp_configure 'show advanced options', '1';
GO
RECONFIGURE;
GO
EXEC sp_configure 'clr enabled', '1'
GO
RECONFIGURE;
I show you how to use the SAC tool further in Chapter 4.
Query Optimizer
The Query Optimizer is the process that determines the indexes, statistics, and optimal paths to answer the query. Several performance counters and system views help you see what the Query Optimizer is doing.
Query Execution
After the query has been checked for syntax and optimized, the Query Execution process creates a final query plan, checks and implements any timeouts, and then creates the final execution plan. You can view these plans, both graphically and in text, in the SQL Server Management Studio. We make extensive use of this feature in Chapter 5.
Sort Manager
By design, data stored in a relational database system is not stored in any particular order. The only time that is not true is when you have applied a clustered index, as I mentioned earlier. When an application wants to receive sorted data, the Sort Manager process manages ORDER BY statements that sort the recordsets. To do that, the process must be able to store temporary results as it sorts them, so this is one of the processes that use the tempdb database mentioned earlier.
Lock Manager
The Lock Manager process handles lock determinations. It determines when to escalate a lock from one type to another and will also find and settle deadlocks.
|
Locks are one subject that interest both administrators and developers.
A lock occurs when one query depends on another. Consider an inventory-ordering system. It is important that when the sales staff looks up an item in inventory, they can be sure of the number of items on hand. However, another salesperson might be selling a number of those items out of that same inventory location. To ensure that the two have the access they need to the right number, database engines implement locks.
The effect is that while the first salesperson is looking up the items, the second is prevented from selling them, and if the second is selling them, the first is prevented from seeing the number until second salesperson is done.
There are many lock types in SQL Server 2005, indicating everything from an intent to take a lock, through the various levels of the lock, such as database, table, or row.
The three most important lock categories are shared, update, and exclusive. A shared lock will not prevent another read. The update and exclusive locks prevent reads and other updates.
SQL Server tries to take the most optimal lock that it can. If it makes more sense to lock an entire section of rows because it would be quicker to do that and get out than it would to determine the row lock needed, it will.
Deadlocks occur when two items depend on each other. Proper coding can usually prevent this situation, but if it does not, SQL Server will pick a "victim," kill its query, and then send a response code to the offending program. Developers can watch for t
|
| 






