|
Because other ETL tools view the migration of data from their sources to various levels of storage, they view the ETL process as a series of data paths. This colors the way the tools implement their design process. Most of the code and toolset they provide are slanted toward data manipulation only. They are also often geared toward complex data warehousing environments, so they have a steep learning curve.
Because Microsoft views the data as a single path, the toolset focuses not only on the data manipulation, but the extract process, the operating system, Web services, and more. Although it has many powerful BI features, it contains many wizards that simplify tasks such as copying a database or importing a text file to a table.
SSIS has two primary areas that you will work with: the control flow and the data flow. I explain these concepts as we explore the components of the system and then I demonstrate them fully in the section describing the Business Intelligence Development Studio, one of the tools you can use to work with Integration Services.
Integration Services Components
The components within SSIS include the outer objects such as packages, which hold other objects, and two primary objects to process and work with the data. The first is the control flow, which contains tasks you want to perform before, in between, or after the data is moved. The second is the data flow, which has connections, sources, transforms, and destinations to work with the data.
Within the design environment, you will see two sequential tabs with those objects as the title. You will actually create the control flow first, and it will contain at least one data flow object, even though you work with them on what appear to be equal tabs. We come back to that in a little while, but it is important to remember the distinction that a control flow contains data flow objects.
Packages
The first object we will explore is the package. This is the collection of the control flow and data flow objects in a single unit. The problem with this term is that it was also used in the previous version of SQL Server to refer to the data movement tool there, called Data Transformation Services (DTS). To confuse matters even further, when you design a SSIS system, the largest container is called a solution, which is made up of one or more projects. Projects contain packages.
You can store a package in a SQL Server database, the SSIS Package Store, or even as a file.
To help separate these terms, keep in mind that solutions and projects are part of the design effort; an SSIS package runs on a server and is separate from a DTS package. I will make sure I am clear when I use these terms as I explain the SSIS objects. For now, think of the package as the outermost container of the rest of the objects.
Control Flow
The control flow view of the process involves the tasks performed before the data is imported or exported and the tasks performed after the transfer occurs. Although you can work with data in this process, it is normally done in another area.
Available tasks in this area include downloading a file from a foreign system using File Transfer Protocol (FTP), sending a notification that a transfer process is starting, or making a database call to trigger a process on another server. You can also create tasks that link into an Analysis Services system to prepare a transfer there. As we work through the various scenarios, I explain more about these components.
There are three types of objects within the control flow. The first are the containers, which hold units of work. Containers deal with loops and sequences. If you want to iterate through a series of tasks, you can create either a Foreach loop, which works through a defined number of steps, or a For loop, which works through a series of steps until some condition is true or false. Both of these are types of containers.
Another container is the sequence. This container provides order to the processes it contains and can even act like an entire package within a package.
The second type of object in the control flow is the task. Tasks are the individual units of work for the control flow. Remember, the control flow contains the work your package does around the data movements.
Tasks include items such as scripting, Analysis Services, XML manipulations, downloads, and more. Tasks are the building blocks of your package. By putting tasks together, you can create complex operations that are easy to follow because they are represented graphically.
One of the most important tasks is also the second major component within SSIS: the data flow task. This task moves data from one place to another. I cover the data flow task separately because it has its own types of tasks within it.
You can create one or more tasks within a single control flow. That means you could load data from one location, receive a downloaded XML file, read it in, and transform all that data into a final form.
Here are the control flow tasks you have available and a quick synopsis of what they do.
[Pages 404 - 405]Task Name | Task Type | Short Description |
|---|
File System task | Data Preparation | Reads, copies, deletes, and moves directories and files. | FTP task | Data Preparation | Upload and download files on an FTP server, also create and delete directories. | Web Service task | Data Preparation | Executes Web service methods, such as connecting to an HTTP server to query a database. | XML task | Data Preparation | Reads, compares, merges, and validates XML documents. Can also reformat XML documents or run an XPath query against them. | Execute Package task | Workflow | Runs another Package as part of the workflow. | Execute DTS 2000 Package task | Workflow | Runs a SQL Server 2000 DTS package as part of the workflow. | Execute Process task | Workflow | Runs an application or batch file. | Message Queue task | Workflow | Send and receive messages between SSIS and Microsoft Messaging Queue (MSMQ). | Send Mail task | Workflow | Sends an e-mail, with or without attachments. | WMI Data Reader task | Workflow | Runs Windows Management Instrumentation (WMI) Query Language statements (WQL) that allow you to query the operating system on everything from logins to processors. | WMI Event Watcher task | Workflow | Runs WQL statements to determine the status of an object in the operating system. | Bulk Insert task | SQL Server | Copies data into a SQL Server table or viewrequires that the SQL Server database allows these types of inserts since they bypass the transaction log. | Execute SQL task | SQL Server | Runs a set of SQL statements using OLEDB, ODBC, ADO, ADO.NET, SQLMOBILE, or even Excel connections on any database that supports those connection methods. | Transfer Database task | SQL Server | Copies or moves an entire SQL Server database from one server to another. | Transfer Error Messages task | SQL Server | Transfers custom error messages from one SQL Server to another. | Transfer Jobs task | SQL Server | Transfers SQL Agent jobs from one SQL Server to another. | Transfer Logins task | SQL Server | Transfers SQL logins (other than sa) from one SQL Server to another. | Transfer Master Stored Procedures task | SQL Server | Transfers user-created stored procedures from the master database of one SQL Server to another. | Transfer SQL Server Objects task | SQL Server | Copies objects such as tables, views, or even schemas from one SQL Server to another. | ActiveX Script task | Scripting | Runs ActiveX scriptsthe Script task is preferred because they can be precompiled. | Script task | Scripting | Runs scripts created in the Visual Studio for Applications (VSA) environmentprovides full programmatic extensions to the package. | Analysis Services Processing task | Analysis Services | Runs Analysis Services processing tasks against cubes, dimensions, and mining models. | Analysis Services Execute DDL task | Analysis Services | Allows you to create, alter, or drop cubes, mining models, and other multidimensional objects. | Data Mining Query task | Analysis Services | Runs Data Mining Extensions (DMX) prediction queries based on data mining models. | Back Up Database task | Maintenance | Backs up a SQL Server database. | Check Database Integrity task | Maintenance | Checks the integrity of one or more SQL Server databases. | Execute SQL Server Agent Job task | Maintenance | Runs a SQL Server Agent job. | Execute T-SQL Statement task | Maintenance | Runs a T-SQL statement (SQL Server only). | History Cleanup task | Maintenance | Deletes entries in the msdb history tables for things such as backup and restore operations. | Notify Operator task | Maintenance | Sends notifications to a SQL Server Agent operator. | Rebuild Index task | Maintenance | Rebuilds indexes on SQL Server tables and views. | Reorganize Index task | Maintenance | Reorganizes indexes on SQL Server tables and views. | Shrink Database task | Maintenance | Shrinks a SQL Server database. | Update Statistics task | Maintenance | Updates the statistics on a table or indexed view. | Custom tasks | Maintenance | Allows you to create your own task type using any .NET language that supports COM. |
The third type of objects are the precedence constraints. They connect containers and tasks in packages into an ordered control flow. Using precedence constraints, you can control the sequence execution for tasks and containers and specify conditions that determine whether tasks and containers run.
Data Flow
Inside the control flow (although viewed separately in the design environment) is the data flow. The data flow contains connections to data systems and three basic objects and tasks: sources, transformations, and destinations.
Each source object represents various places that you can pull data. You can read from databases, files, Web services, Excel files, XML documents, and more.
You can also apply transformation tasks, which include things such as aggregations, merges, splits, various mathematical and string manipulations, and more. You can place these tasks directly after the source system objects to create the pipeline architecture, or after data arrives at the destination. You can have as many transformation tasks as you want.
When you are finished importing and transforming the data, you place it into a destination. The destination does not have to be a SQL Server database. You can read data from an FTP site, transform it into all lowercase, and then record the data out into an XML file. The data never has to pass through a SQL Server database at all.
The Connection Manager
Before you can read data from a source or write it to a destination, you must have a connection to work with. Connections involve the libraries that talk across protocols to systems and the security authentication (if any) that those connections require.
If you have never programmed before, this might be a new concept, because it seems unnecessary to tell the system you want to extract data and also that you want to connect to that data. In practice, connections are useful because you can reuse them. Not only that, but connections need to be abstracted from the data transfer because you might want to make two connections to a system with different security or configuration information but perform the same data operations on both.
There are a lot of data sources you can access, right out of the box. Here is a quick list:
In the following sections, I show you how to create connections for both source and destination data.
Sources
With the connection created, SSIS can read from several types of data sources. Here is a chart of the types you have available.
Source | Short Description |
|---|
DataReader | Reads data from a .NET Framework data provider | Excel | Reads data from an Excel worksheet | Flat file | Reads data from an ASCII file | OLE DB | Reads data from an OLE DB connection | Raw file source | Reads bytes from a file | Script component | Uses a script to extract, transform, or load data | XML Source | Reads and shreds data from an XML document |
If you are connecting to a SQL Server database, you will most often use the OLE DB data source.
In a moment, I put all this together in a simple package so that you can see the interactions between the connections and the data sources.
Transforms
When you bring data from another system into a database, you will often need to change it. Most often, it is a data-type issue.
For instance, when you are reading from a flat file, the data is necessarily all text. There is no notion of dates, numbers, or binary representation because the ASCII set does not support a "type" attribute. When you put the data into a database, however, it will have a type. In some cases, the database can just "figure out" what to do, such as importing the string "10/23/1963" as a date. That is called an implicit conversion, and other than the convenience factor, it is not always a good thing. The system might implicitly convert a telephone number string into a numeric format, and subtract the phone number from the area code.
To prevent this kind of thing, you should at least implicitly transform the data types from the source system to the destination. In other cases, you might want to completely change the string, even if the data types match. In applications such as BI systems, you might have a need to change the case of text or add ten days to a date.
So far, I have been describing changing the contents of a single field within the extract. In more complex applications, you need to do much more than that. SSIS includes several types of transformation operations, covering everything from the single-field changes to creating fields that do not even exist in the source system.
I am describing these transformations so that you can plan your ETL process. Even if you are not setting up a complex BI system, you still need to have a plan for the data path. The reason for that plan is that you do not own the data. The minute you change the data from what it originally was in the source system you have added meaning, which is not something the DBA should do. I explain that concept in greater depth in Chapter 10, "Analysis Services," but for now you should ensure that you present your plan to change data to the data owners for their sign-off. Only the owners can set the meaning for the data.
Let's take a look at some of the more common types of transformations you are likely to use and then compare that to the transformation tasks available in SSIS.
Homogenized
One of the most common transformations is to homogenize data. That simply means making the data from multiple sources look the same by changing case, order, data types, and so forth.
Assume that you have three source systems at various plants. One might represent part numbers separated by dashes, another might use forward slashes, and still another might use periods to separate the numbers. When you bring that data in, you may want to strip out all of those characters and simply run the numbers together. That is a homogenization transformation.
Cleansing
Another more difficult transformation is cleansing. If you import much data, you will certainly encounter sources that have allowed "dirty" data into their systems. This can include foreign characters, strings where numbers are required, or any number of data corruptions. In this case, a judicious review of what your goals are is essential. Do you ignore the rows with the bad data? If you do, there is a possibility you will violate the integrity of the system you are designing. For instance, if you delete a "bad" part number from an import, you might not be able to import the larger assembly that depends on it.
In addition to ignoring the data, which really is not a transform anyway, you could set up a logical rule that changes the bad data to an acceptable form. This is possible if you know what the possible errors are and what they should map to, but this is not always possible.
The last choice you have if you cannot cleanse the data is to write it to an "exceptions table" or to a logging file. Although technically a transform, you should at least employ some sort of detection logic so that you do not stop an entire import process because of a single row of bad data.
Aggregating
An aggregation transformation is used with numeric values. In this case, you add numbers or counts of data elements and store the result into a single field. For instance, instead of recording every part from the source system, you might record that there were ten part number 12345s, five number 34215s, and so on.
Aggregations are common in analytical systems because by definition they are more concerned with strategic numbers than the detail.
Merging
A merging transformation type is used when you need to combine fields. You may find that your source systems have broken a single field into multiple parts. This is quite common in project management systems, where the Work Breakdown Structure (WBS) numbers are used as a "database in a database," meaning that each character in the number has positional relevance. In that case, you may want to combine the fields into one field.
Conversion
In global systems, you may need to convert data from one language or format to another. This might be as simple as changing one character to another or as complex as looking up a currency rate on a Web service and changing the inputs to dollars or euros.
Joining
Much like the merge transformation, joining transformations involves combining fields. The difference is that a joining transformation adds two or more fields together or even appends data to an existing field and does not make any other changes to it.
Materialized
One of the most interesting transformations is when you create a new field from the data that is imported. This is called a materialized transformation. Possible uses include creating totals by performing mathematical operations on merged or joined columns or adding a location field to the import based on where it came from.
Most every BI extract includes this type of transform because they include a timestamp field on the import. Because that data was not in the original file, it is a materialized transform.
SSIS Transforms
You can achieve the types of transformations I have just described by using one of the transformations that SQL Server provides or by combining the output of one to the input of another.
It is beyond the scope of this chapter to describe each of the transformations and how you can use them, but here is a chart that gives you a quick rundown of the variety of capabilities SSIS transformations provides.
Transformation Name | Short Description |
|---|
Aggregate transformation | Creates aggregations | Audit transformation | Creates information about the environment available in a package | Character Map transformation | Applies string functions to character data | Conditional Split transformation | Routes rows to different outputs | Copy Column transformation | Adds copies of input columns to the output (useful for combinations) | Data Conversion transformation | Converts data types | Data Mining Query | Runs data mining prediction queries transformation | Derived Column transformation | Creates new columns with the results of expressions | Export Column transformation | Inserts data into a file | Fuzzy Grouping transformation | Standardizes column of data | Fuzzy Lookup transformation | Uses lookup tables and creates a fuzzy match | Import Column transformation | Reads data from a file | Lookup transformation | Uses a lookup table by an exact match | Merge Join transformation | Uses FULL, LEFT, or INNER joins to combine data | Merge transformation | Merges data | Multicast transformation | Distributes data to multiple outputs | OLE DB Command transformation | Runs SQL commands for each row in an import | Percentage Sampling transformation | Creates a sample set using a percentage specifying a sample | Pivot transformation | Flips a data set on its axis | Row Count transformation | Counts rows as they pass and stores the count in a variable | Row Sampling transformation | Creates a sample set by specifying the number of rows in a sample | Script Component | Uses scripts to extract, transform, or load data | Slowly Changing Dimension transformation | Configures a slowly changing dimension's updates | Sort transformation | Sorts data | Term Extraction transformation | Extracts terms from text | Term Lookup transformation | Uses lookup tables and counts terms extracted from text | Union All transformation | Merges all data | Unpivot transformation | Unflips a data set on its axis |
Destinations
The destinations for the data are similar to what I explained for sources, but SSIS includes a few more destinations than sources. The reason is that SSIS is used a great deal for BI applications, so you will see destinations for dimensions, data models, and partitions. I cover those objects more in Chapter 10. Here is a list to help you with the type of destinations you have available:
Precedence Constraints
To connect containers to tasks or tasks to other tasks, you use the next object in the control flow, precedence constraints. Precedence constraints are conditions of failure, success, completion, or any mix of all three.
Essentially, you "tie" a container or task to another container or task. In this way, you can create your logic for the workflow, such as "Do A if this task succeeds, B if it fails, or C when it completes." By using the proper constraint precedence arrangements, you can create AND and OR conditions on a task. This creates the flow for the package.
You have a few choices for the precedence constraints. Most of the time, you will use the execution results from the task to enforce the constraint. For instance, to enforce the following workflow: "If the execute T-SQL command is successful, move on to the next task, but if it fails, send an e-mail," you would create two precedence constraints: one for the success tied to the next task, and the other for the failure tied to a Send Mail task.
You can also code your precedence constraints to use an expression evaluation. This would mean something like "If A = B, then True" to evaluate whether to branch off to one task over another. The variables I discuss in a moment are useful for this type of workflow requirement.
Precedence constraints attach to either an input or an output of another object. Although you might think a destination would not have an output, it does. Many objects, such as destinations, have error outputs.
Not all inputs can be linked to all inputs, but don't worry: The interface will stop you if you try to attach to the wrong place.
Event Handlers
Another concept that is borrowed from programming that you may not be familiar with is the event. Conceptually, the idea of an event is not hard to follow. When something happens, that is an event. The more interesting part is that certain SSIS objects can "raise" events, which you can watch for and respond to. You can watch events from a package, a task, or a container.
To watch and respond to the events, you create an event handler. Here are the types of event handlers and what they watch for.
Event Handler Name | Watches For |
|---|
OnError | An error in execution | OnExecStatusChanged | Execution status changes in an object | OnInformation | Information during execution, but not errors | OnPostExecute | An execution's completion step | OnPostValidate | An execution's validation step | OnPreExecute | Just before an execution step | OnPreValidate | Just after the validation starts in an execution step | OnProgress | The progress of an execution step, if available | OnQueryCancel | The cancellation of a query | OnTaskFailed | Task failure | OnVariableValueChanged | Changes in a variable | OnWarning | Warnings during execution, but not errors |
Event handlers are great for debugging your process, too. You can watch for status changes, errors, and so on when the package is running, and when you have got everything worked out, you can remove them.
Other Components
Even with all those objects, there is still more that you can do with SSIS. To really extend the Package into an enterprise process, you need two other facets: logging and extensibility. I cover the logging options in the "Management" section a little later, because it allows you to maintain your system as well as develop against it.
Variables
Another handy concept borrowed from programming is the variable. A variable is a name set aside to hold a value that can change while the package is running. It is similar to a notepad off to the side that you can write on and read while your workflow completes.
Variables are stored in a central location, called a namespace. SSIS has some built-in variables and stores them in the namespace called System Variables, which you can also read. The variables you create for yourself are normally stored in a namespace called User Variables. In this section, I focus on the user variables, but do not overlook the valuable information that the system variables hold. I show you how to get to those later.
When you create a variable, it applies to only the area that contains it. For instance, if you create a variable in a task, only that task and any objects contained within it can see or change the variable. This is called scope.
If you create a variable in a container, all the objects within that container can reference the variable. Creating a variable in the package essentially creates a "global" variable that all objects can see. Although my developer friends cringe when they see me do it, I normally create variables with the scope in their name.
To set a variable, you can right-click an object and select that option from the menu that appears. You can also work with variables in the Expressions property page in the Business Intelligence Development Studio, which I describe next.
Tools
Because the SSIS feature has so many facets, you can use more than one tool to work with it. You can use several command-line tools to manage and deploy packages. SSIS also includes a full programming model, so your developers can create entire applications using only code. In this chapter, I focus on the tools that you will be asked to use as the DBA.
Creating a Project with the Business Intelligence Development Studio
To design SSIS packages, you will use the Business Intelligence Development Studio. This is a Visual Studio-inspired application that has an integrated graphical design interface, a debugger, context-sensitive help, and even source control.
You will find the Business Intelligence Development Studio in the Start menu in the SQL Server 2005 item. In this section, I open the interface and explain the environment. You can follow along on your own testing system.
You have already seen much of this interface when we explored the SQL Server Management Studio, so I do not cover things such as the pushpins on the menus or the panel placements. Those work here the same as in the SQL Server Management Studio. There are, however, a few other items that are unique to a design environment.
In this section, I am not creating a real project; we are just exploring the interface. While you read through this section, watch for all the objects I explained earlier in the chapter.
When you first open the Business Intelligence Development Studio (which I call the Development Studio from here on), you are placed in the Start page, which is actually in the main section of the environment, similar to the Summary area in SQL Server Management Studio. You can see the screen layout in Figure 8-1.
[View full size image] 
This HTML-enabled area has hyperlinked items you can click, showing the latest news from the Microsoft development world and introductions to various parts of the tool. One of the main panels within this screen allows you to create various projects, such as a Reporting application, a BI application, and an Integration Services application. Click the Create: Project link on the Start page to bring up the dialog shown in Figure 8-2.
[View full size image] 
Here you are able to set the directory for the project and create a subdirectory for the project automatically. This is a practice that I recommend, along with storing your projects in a central location.
After you make your selections, you are dropped right into the interface without connecting to a server first. This is because you are working in a development environment. You could create an entire project without connecting to a database at all.
In Figure 8-3, you can see the screen I am presented with on my test system.
[View full size image] 
If your screen does not look like this one, you can click the Window menu bar item and then select Reset Window Layout.
On the far-right side of the screen are the Solution Explorer and Properties panels, just as I showed you earlier when we spoke about the SQL Server Management Studio. In a moment, I show you how to add data sources and data source views and how you use those, but for now "unpin" those panels to hide them. Next slide out and "pin" the Toolbox on the left side of the screen.
As you can see in Figure 8-4, this is where having multiple monitors really comes in handy. With a large-enough monitor, you could set all of the menus to "Float," and then have a large central area to work with the package. In this case, just keep the menus in the tabbed interface.
[View full size image] 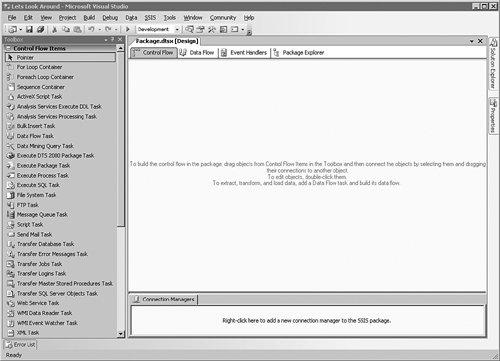
The large area in the center-right of this screen has four tabs, containing the control flow, the data flow, event handlers, and the Package Explorer view. That is all encompassed inside one tab referenced by the name of the project. At the bottom of the screen is the Connection Manager area. This is where we will make the connections to the databases that are used by the other objects. On the left-hand panel is the Toolbox for the control flow items.
To begin the project, simply drag items from the Toolbox into the panel on the right that you are interested in working with. Because the control flow is what is showing here, drag a File System task into that part of the screen.
In Figure 8-5, you can see that there is an error on this task, indicated by the X in a red circle. It also has a precedent constraint highlighted. In this case, it is green, which means it is the success precedent. I come back to that in a moment.
[View full size image] 
Right-click the object and select the Properties item from the menu that appears. The tab on the right shown in Figure 8-6 slides out to show all the properties of the object and allows you to set or edit them.
[View full size image] 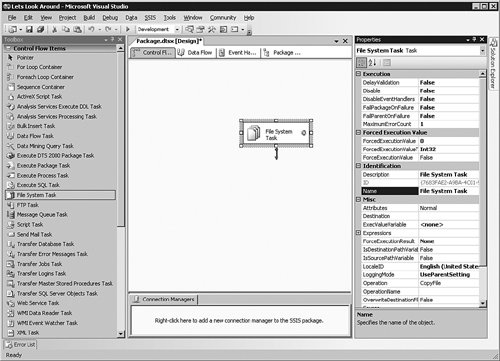
Close that panel and double-click the File System Task object. You can also right-click an object and select Edit from the menu that appears to do the same thing. The results are shown in Figure 8-7.
[View full size image] 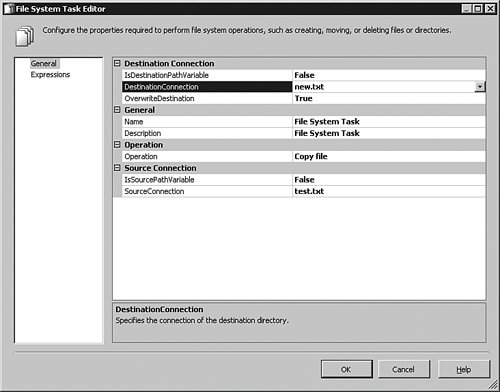
In this case, the File System task expects information about what it needs to do. As I explained earlier, the File System task can copy, move, delete, or create files and folders on the operating system. This example I have created copies a file called test.txt in the c:\temp directory to a file called new.txt in the c:\temp directory (and overwrites it if it already exists). Most of those instructions are visible in this panel, but the directories are not.
The reason is that when you click the SourceConnection entry box to set the start file, you have to either specify a file connection or create a new one. Although I'm not showing that dialog box here, selecting the item marked <…new connection .. > brings up a panel with a browse button to set the path or filename. Once those are created, they show up in the bottom part of the environment and are available to any of the other objects you work with.
Click the OK button to close that item and create the next item in the workflow we are developing. In this case, we will send an e-mail that the process is complete. Drag the Send Mail task onto the control flow.
You can see the object in Figure 8-8. With the Send Mail task created, it must be configured for use. Double-click the object to bring up the editor for it, shown in Figure 8-9.
[View full size image] 
[View full size image] 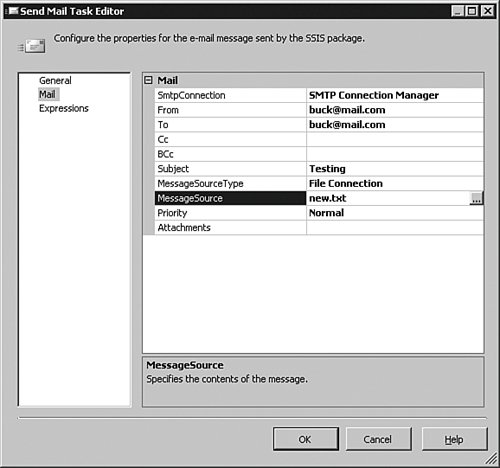
In this case, the Mail item on the left is selected to show that the system will attempt to mail a message containing the text of the file called new.txt from the file connection created a moment ago; notice how we are already reusing connections. Clicking the name of the SMTP Connection allows you to set up the SMTP server the task connects to. Click OK to close out the task.
Next we turn our attention to the precedence constraints. We need to tell the system to create the new.txt file and then send out the mail only if that is a successful event.
To set the constraint, click once on the File System task and then click once on the green arrow pointing downward from it. You do not have to hold the mouse button down; the line is now "locked" to your pointer until you click another object. Move the arrow until it connects to the Send Mail task, and then click once more. You can see the results in Figure 8-10.
[View full size image] 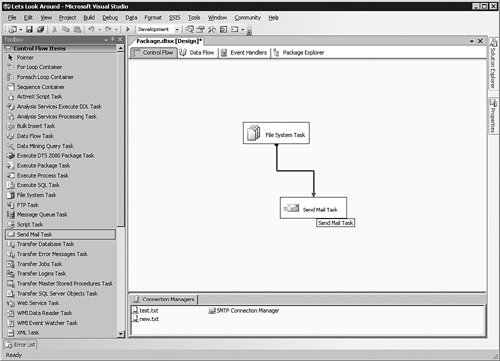
Now double-click the green line, which brings up the dialog box shown in Figure 8-11.

This is the Precedence Constraint Editor. Here you can set whether the step evaluates to a constraint such as success, failure, or completion; or whether the step evaluates an expression, which contains the variables I explained earlier in the chapter. You can also set the evaluation to both the constraint and the expression or the constraint or the expression. Selecting the Expression option opens up the Expression text box below. Click OK to continue.
If you want to add another precedence constraint, right-click the object and then select Add Precedence Constraint from the menu that appears.
Figure 8-12 shows the complete picture of the package as it stands now.
[View full size image] 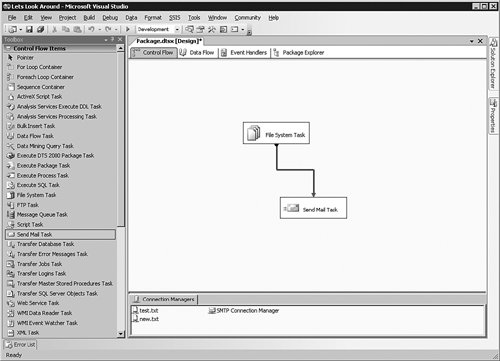
In that screen, you can see the two tasks I have created, the success precedent constraint, and the connections for the files and the mail system. Although this seems perfectly clear now, if you begin to add more File System tasks or Send Mail tasks, it will not be obvious what you are trying to accomplish in the package.
To add more meaning to the graphics, click the File System object in the text that is displayed, wait a moment, and then click it again. The text will highlight, which allows you to type a more meaningful title, as shown in Figure 8-13.
[View full size image] 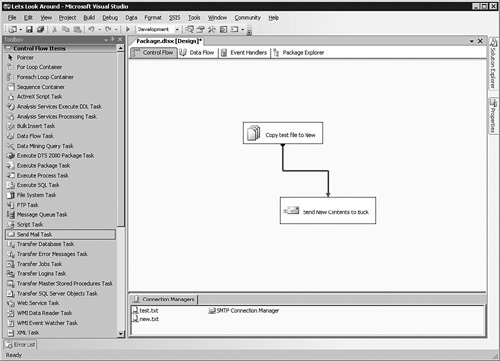
With everything complete, it is time to save the project. I normally click the "multiple disks" icon in the icon bar, but you can also use the menu bar to save your work. The project is now saved, the objects are all configured, and we are ready to run the package. In the Development Studio, this is known as debugging, and you can start it by pressing the F5 key or you can click Debug and then Start Debugging in the menu bar.
On my test system, the File System task worked properly and is colored green. The Send Mail task has failed, however, and is indicated with a red box, which you can see as the darker box in Figure 8-14.
[View full size image] 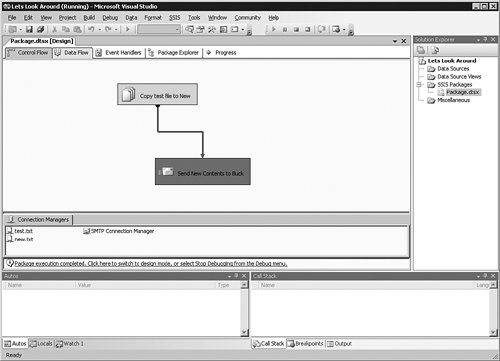
To find out why it has failed, I click the Progress tab at the top of the package.
You can see in Figure 8-15 that my test system is behind a firewall that blocks SMTP traffic. Although the actual failure message text is not helpful in this case, the steps taken by the package are clearly diagrammed so that you can trace each activity within SSIS. This is useful when trying to find an issue with your package's execution. You will also get feedback on how long the process takes, which is valuable in performance monitoring.
[View full size image] 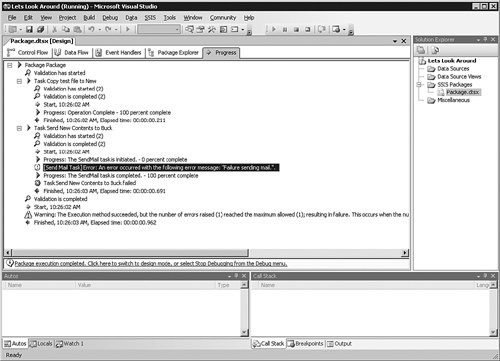
Command-Line Utilities
The graphical tools are by far the easiest method to work with SSIS, but sometimes you will need to use the command line to access the system. In that case, you have four tools at your disposal.
Tool | Purpose |
|---|
Dtutil | Manages SSIS packages | Dtexec | Executes SSIS packages | Dtexecui | Displays a graphical user interface to load and run SSIS packages | Dtswizard | Launches the Import and Export Wizard |
Wizards
Although you have a powerful environment to work with for designing projects, you might only have modest data transport needs, such as moving a table to a file or reading data from an Excel spreadsheet into a database. You will be happy to learn that you do not have to learn an entire new development environment to do that. Microsoft provides a simple wizard-driven interface that walks you through the process to move data to or from your database. In fact, if you followed the Maintenance Wizard process I demonstrated earlier in the book, you have already used SSIS to set up a package. In your role as a DBA, you will often create a package using a wizard and then expand the pac
| 






