Data Analysis and Design
After you have analyzed and documented all the tasks involved in a system, you're ready to work on the data analysis and design phase of an application. In this phase, you must identify each piece of information needed to complete each task. You must assign these data elements to subjects, and each subject will become a separate table in the database. For example, a subject might be a client; every data element relating to that client?the name, address, phone number, credit limit, and any other pertinent information?would become fields within the client table.
You should determine the following for each data element:
The appropriate data type
The required size
Validation rules
You should also determine whether you will allow the user to update each data element and whether the user will enter each update or the system will calculate it. Then you can figure out whether you have properly normalized the table structures.
Database Terms Introduced
In the preceding hours we have briefly mentioned some terms that are integrally important now that you will be designing your own objects. The following are the most important of these terms and what they mean:
Column or field? A single piece of information about an object (for example, a company name).
Row or record? A collection of information about a single entity (for example, all the information about a customer).
Table? A collection of all the data for a specific type of entity (for example, all the information for all the customers stored in a database). It is important that each table contain information about only a single entity. In other words, you would not store information about an order in the Customers table.
Primary key field? A field or a combination of fields in a table that uniquely identifies each row in the table (for example, the CustomerID).
Natural key field? A primary key field that is naturally part of the data contained within the table (for example, a Social Security number). Generally it is better to use a contrived key field, such as an AutoNumber field, than a natural key field as the primary key field.
Composite key field? A primary key field comprising more than one field in a table (for example, LastName and FirstName fields). It is preferable to create a primary key based on an AutoNumber field than to use a composite key field.
Relationship? Two tables in a database sharing a common key value. An example is a relationship between the Customers table and the Orders table: The CustomerID field in the Customers table is related to the CustomerID field in the Orders table.
Foreign key field? A field on the many side of the relationship in a one-to-many relationship. Whereas the table on the one side of the relationship is related by the primary key field, the table on the many side of the relationship is related by the foreign key field. For example, one customer has multiple orders, so whereas the CustomerID field is the primary key field in the Customers table, it is the foreign key field in the Orders table.
Normalization Introduced
Normalization is a fancy term for the process of testing a table design against a series of rules to ensure that the application will operate as efficiently as possible. These rules are based on set theory and were originally proposed by Dr. E. F. Codd. Although you could spend years studying normalization, its main objective is to create an application that runs efficiently with as little data manipulation and coding as possible. Hour 9, "Creating Relationships," covers normalization and database design in detail. For now, here are six of the basic normalization rules: |
 Fields should be atomic?that is, each piece of data should be broken down as much as possible. For example, rather than create a field called Name, you should create two fields: one for the first name and another for the last name. This method makes the data much easier to work with. If you need to sort or search by first name separately from the last name, for example, you can do so without any extra effort.
Fields should be atomic?that is, each piece of data should be broken down as much as possible. For example, rather than create a field called Name, you should create two fields: one for the first name and another for the last name. This method makes the data much easier to work with. If you need to sort or search by first name separately from the last name, for example, you can do so without any extra effort.Each record should contain a unique identifier so that you have a way of safely identifying the record. For example, if you're changing customer information, you can make sure you're changing the information associated with the correct customer. This unique identifier is called the primary key.
- The primary key is a field (or fields) that uniquely identifies the record. Sometimes you can assign a natural primary key. For example, a Social Security number in an employees table should serve to uniquely identify each employee to the system. At other times, you might need to create a primary key. Because two customers could have the same name, for example, a customer name might not uniquely identify the customer to the system. It might be necessary to create a field that would contain a unique identifier for each customer, such as a customer ID.
A primary key should be short, stable, and simple. Short means it should be small in size (not a 50-character field). Stable means the primary key should be a field whose value rarely, if ever, changes. For example, whereas a customer ID would rarely change, a company name is rather likely to change. Simple means it should be easy for a user to work with.
Every field in a table should supply additional information about the record that the primary key serves to identify. For example, every field in a customers table should describe the customer who has a particular customer ID.
Information in a table shouldn't appear in more than one place. For example, a particular customer name shouldn't appear in more than one record.
Let's look at an example. The datasheet shown in Figure 7.1 is an example of a table that hasn't been normalized. Notice that the CustInfo field is repeated for each order, so if the customer address changes, it has to be changed in every order assigned to that customer. In other words, the CustInfo field is not atomic. If you want to sort by city, you're out of luck because the city is in the middle of the CustInfo field. If the name of an inventory item changes, you need to make the change in every record where that inventory item was ordered. Probably the biggest limitation of this example involves items ordered. With this design, you must create four fields for each item the customer orders: name, supplier, quantity, and price. This design would make it extremely difficult to build sales reports and other reports your users need to effectively run the business.
Figure 7.1. A table that hasn't been normalized.
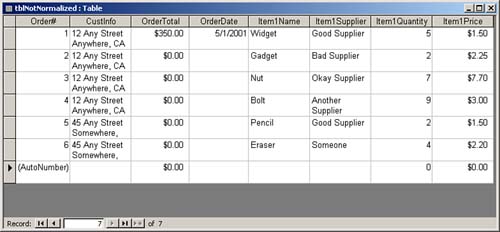
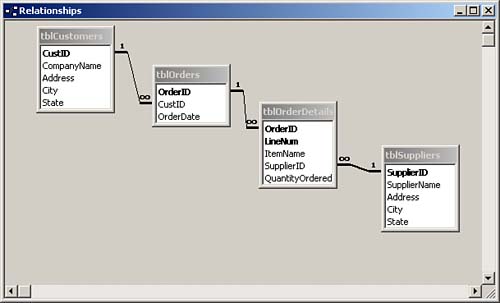
Figure 7.2 shows the same data shown in Figure 7.1, but in this case the data is normalized. Notice that the data is broken out into several different tables: tblCustomers, tblOrders, tblOrderDetails, and tblSuppliers. The tblCustomers table contains data that relates only to a specific customer. Each record is uniquely identified by a contrived CustID field, which is used to relate the orders table, tblOrders, to tblCustomers. The tblOrders table contains only information that applies to the entire order, rather than to a particular item that the customer ordered. The tblOrders table contains the CustID of the customer who placed the order and the date of the order, and it is related to the tblOrderDetails table based on the OrderID. The tblOrderDetails table holds information about each item ordered for a particular OrderID. There's no limit to the potential number of items that the user can place on an order. The user can add as many items to the order as needed, simply by adding more records to the tblOrderDetails table. Finally, the supplier information appears in a separate table, tblSuppliers, so that if any of the supplier information changes, the user has to change it in only one place.
Figure 7.2. Data normalized into four separate tables.