SQL Server 2000 Components and Features
SQL Server 2000 is more than just the database engine. While the database engine is at the core of the product, and obviously the most important component, there are a number of additional applications bundled with the database engine, such as the tools and utilities used to manage the SQL Server environment, as well as other components and server applications that extend the capabilities and features of SQL Server 2000. This section provides an overview of the components and features that are included with the SQL Server 2000 product. Each of these components is subsequently explored in greater detail in the rest of this book.
SQL Server Database Engine
SQL Server's database engine is the primary server application in the SQL Server package. Following are the main responsibilities of the database engine:
Provide reliable storage for data sent to the engine
Provide a means to rapidly access this data
Provide consistent access to the data
Control access to the data through security
Enforce data-integrity rules to ensure the data is accurate and consistent
Each of these points will be examined in detail later in the book. I will touch on each of these points to show how Microsoft SQL Server fulfills these core responsibilities.
Reliable Storage
Reliable storage starts at the hardware level. This isn't the responsibility of the database engine, but it's a necessary part of a well-built database. Although you can put an entire SQL database on an old IDE drive (or even burn a read-only copy on a CD), it is preferrable to maintain the data on RAID arrays. The most common RAID arrays allow hardware failures at the disk level without losing data.
To learn more about RAID arrays and database hardware planning, check out Chapter 39, "Database Design and Performance."
Using whatever hardware you have decided to make available, the database engine handles all the data structures necessary to ensure reliable storage of your data. Rows of data are stored in pages, each 8KB in size. Eight pages make up an extent, and the database engine tracks which extents are allocated to which tables and indexes.
For an in-depth discussion of data structures and how they factor into performance and reliability, see Chapter 33, "SQL Server Internals."
NOTEPage: An 8KB chunk of a data file, the smallest unit of storage available in the database. Extent: A collection of eight 8KB pages. |
Another key feature the engine provides to ensure reliable storage is the transaction log. The transaction log makes a record of every change that is made to the database for rollback and recovery purposes. See Chapter 31, "Transaction Management and the Transaction Log."
NOTEIt is not strictly true that the transaction log records all changes to the database?some exceptions exist. Binary Large Objects?data of type image and text?can be excepted from logging, and inserts generated by bulk table loads can be non-logged to get the fastest possible performance. |
Rapidly Accessing Data
SQL Server provides rapid access to data by utilizing indexes and storing frequently accessed data in memory.
SQL Server allows the creation of clustered and nonclustered indexes, which speed access to data by using the index pointers to find data rows rather than having to scan all the data in the table each time. See Chapter 34, "Indexes and Performance," for an in-depth discussion of indexes and how they are used to improve query performance.
Memory is allocated by SQL Server database to be used as a data cache to speed access to data by reducing the number of required physical I/Os to the disks. When pages are requested from the database, the server checks to see if they are already in the cache. If not, it reads them off the disk and inserts them into the data cache. With sufficient memory, the next time the data needs to be accessed, it should still be in cache, avoiding the need to access the disk drive(s). A separate process runs continuously and attempts to keep frequently accessed information in memory by pushing old pages that haven't been accessed recently out of the cache to make room for newly accessed pages. If the pages contain modifications, they are written to disk first before being removed from cache, otherwise the old pages are simply discarded.
NOTEWith sufficient memory, the entire database can fit completely into memory. |
More information on the data cache and how it is managed is available in Chapter 33.
Providing Consistent Access to Data
Getting to your data quickly doesn't mean much if the information you receive is inaccurate. SQL Server follows a set of rules to ensure that the data you receive back from queries is consistent.
The general idea with consistent access is to allow only one client at a time to change the data, and to prevent others from reading data from the database while it is undergoing changes.
Transactional consistency has several levels of conformance, each of which provides a trade-off between accuracy of the data and concurrency. These levels of concurrency are examined in more detail in Chapter 38, "Locking and Performance." In particular, check out the sections on "SQL Server Lock Types" and "Transaction Isolation Levels in SQL Server."
Controlling Access
The database server provides security at multiple levels. Security is enforced at the server level, the database level, and at the database object level. Access to the server is verified by either a username and password, or through integrated network security. Integrated security uses the client's network login credentials to establish identity.
SQL Server security is examined in more detail in Chapter 15, "Security and User Administration."
Enforcing Data Integrity Rules
Some databases have to serve the needs of more than a single application. A corporate database that contains valuable information might have a dozen different departments wanting to access portions of the database for different needs.
In this kind of environment, it is impractical to expect the developers of each application to agree on an identical set of standards for maintaining data integrity. For example, one department might allow phone numbers to have extensions, whereas another department does not need that capability. One department might find it critical to maintain a relationship between a customer record and a salesman record, whereas another might care only about the customer information.
The best way to keep everybody sane in this environment?and to ensure that the data stays consistent and usable by everyone?is to enforce a set of rules at the database level. This is accomplished through the database objects, including rules, defaults, triggers, stored procedures, and data-integrity constraints. See Chapter 14, "Implementing Data Integrity," for details.
SQL Server Enterprise Manager
The Enterprise Manager is the central console from which most SQL Server database-management tasks can be coordinated. SQL Enterprise Manager (hereafter referred to as SQL-EM) provides a single interface from which all servers in a company can be managed.
The SQL-EM is examined in more detail in Chapter 4, "SQL Server Enterprise Manager."
Figure 1.2 shows Enterprise Manager being used for some everyday administration tasks.
Figure 1.2. Enterprise Manager showing a list of scheduled jobs on the Palpatine server.
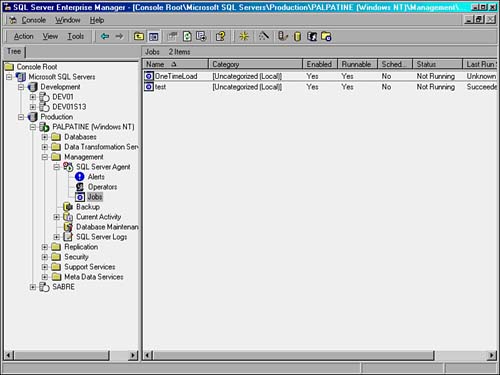
Figure 1.2 shows a list of available servers in the leftmost pane. The servers are organized into two groups: Development and Production. A connection to Palpatine has been opened, and the right pane shows the scheduled jobs on Palpatine.
The following lists some of the tasks that can be performed with SQL-EM. Most of these are discussed in detail later in the book:
Completely manage many servers in a convenient interface
Set server options and configuration values, such as the amount of memory and processors to use, the default language, and the default location of the data and log files
Manage logins, database users, and database roles
Schedule automated jobs through the SQL Agent
Back up and restore databases and develop maintenance plans
Create new databases
Browse table contents
Manage database objects, such as tables, indexes, and stored procedures
Configure and manage replication
Import and export data
Transfer data between servers, SQL Server, and otherwise
Monitor SQL Server activity and error logs
Provide a convenient centralized front end to other applications, such as the Data Transformation Services designer, Query Analyzer, Full Text Search Services, and SQL Mail
NOTESQL Enterprise Manager interacts with SQL Server using standard Transact-SQL commands. For example, when you create a new database through the SQL-EM interface, behind the scenes it generates a CREATE DATABASE SQL command. Whatever you can do through SQL-EM, you can do with the Query Analyzer or even the command line ISQL or OSQL programs. If you're curious how EM is accomplishing something, you can run SQL Profiler to trap the commands that SQL-EM is sending to the server. I've used this technique to discover some interesting internals information. You can also use this tactic to capture SQL scripts, and then repeat tasks using the script instead of a few dozen interface clicks. |
SQL Service Manager
The Service Manager is a small applet that allows easy control of several key SQL services:
SQL Server, the database engine
SQL Agent, a job scheduler
SQL Search, a full-text search engine
Distributed Transaction Coordinator
OLAP Server, a separate service used for warehousing
The Service Manager can be used to control or monitor these services on any machine on the network. It will poll each service every few seconds (configurable through Options) to determine its state. A check box also exists for each service, which allows automatic starting of the service when Windows starts. Most servers automatically start the SQL service on system startup, but in some maintenance situations, it's important to be able to disable this property.
All services can be stopped and started. Some can also be paused. When SQL Server is paused, it continues operating normally except that new login connections are not accepted.
SQL Server Agent
The SQL Server Agent is an integrated scheduling tool that allows convenient execution of scheduled scripts and maintenance jobs. It is required to use replication services. The agent also handles automated alerts (for example, if the database runs out of space).
The Agent is a Windows service that runs on the same machine as the SQL Server engine. The agent service can be controlled through either SQL-EM, the SQL Service Manager, or the ordinary Windows service manager. The Agent is configured through SQL-EM by drilling down through the SQL Server instance | Management | SQL Server Agent.
SQL jobs can be complex. Branching is possible depending on the outcome of a query or job return status.
The Agent also handles alerting. The alert system can watch for a particular event, and then respond to this event by paging an operator, sending an e-mail, running a predefined job, or any combination of these. In the previous example of the database running out of space, an alert could be defined to watch the free space, and when it got to less than 5 percent, the database could be expanded by 100MB and the on-call DBA could be paged.
In enterprise situations in which many SQL Server machines need to be managed together, the SQL Agent can be configured to distribute common jobs to multiple servers through the use of Multiserver Administration. This is most helpful in a wide architecture scenario, in which many SQL Server databases are performing the same tasks with the databases. Jobs are managed from a single SQL Server machine. This machine is responsible for maintaining the jobs and distributing the job scripts to each target server. The results of each job are maintained on the target servers, but can be observed through a single interface.
If you have 20 servers that all need to run the same job, you can check the completion status of that job on a single server in moments, instead of logging into each machine and checking the individual status 20 times.
The SQL Agent Event also handles forwarding. Any system events that are recorded in the Windows System Event Log can be forwarded to a single machine. This gives the busy admininstrator a single place to look for errors.
More information about how to accomplish these tasks, and other information on the Agent, is available in Chapter 18, "SQL Server Scheduling and Notification."
SQL Query Analyzer
The Query Analyzer is the easiest place to run SQL scripts. Each window in the Query Analyzer represents a connection to a database. It's possible to have connections to many different servers.
Some wonderful changes have been made to the 2000 version of Query Analyzer, most notably the addition of an object browser/template manager and an integrated stored procedure debugger.
Figure 1.3 shows the Query Analyzer with the Template Manager open on the left.
Figure 1.3. SQL Query Analyzer displaying the Template Manager pane on the left side, and two connections to a database server in the main window.
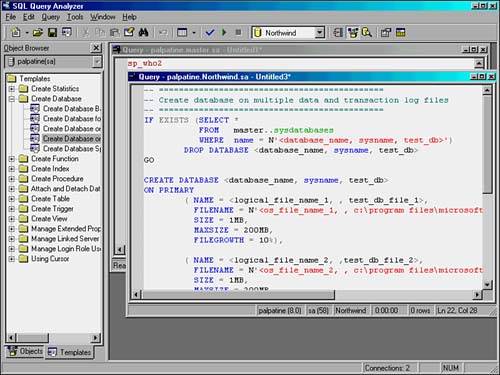
The Query Analyzer tool is discussed in Chapter 6, "SQL Server Query Analyzer and SQL Debugger," along with a discussion on using its built-in SQL Debugger. See Chapter 36, "Query Analysis," for details on using the Query Analyzer to troubleshoot long-running or complex queries.
SQL Profiler
The SQL Profiler is a client tool that captures the queries and results flowing to and from the server. It is analogous to a network sniffer, although it does not operate on quite that low a level. The Profiler has the ability to capture and save a complete record of all the traffic passed to the server. A series of filters is useful for paring down the results when you want to drill down to a single connection or even a single query.
The SQL Profiler can be used to perform these helpful tasks:
Capture the exact SQL statements sent to the server from an application for which source code is not available (third-party applications, for example).
Capture all of the queries sent to SQL Server for later playback on a test server. This is extremely useful for performance testing with live query traffic.
If your server is encountering recurring Access Violations (AVs), the profiler can be used to reconstruct what happened leading up to the AV.
The profiler shows basic performance data about each query. When your users start hammering your server with queries that cause hundreds of table scans, the profiler can easily identify the culprits.
For complex stored procedures, the tool can identify which portion of the procedure is causing the performance problem.
Audit server activity in real time.
The profiler is a versatile tool; it provides functionality that is not duplicated elsewhere in the SQL Server Tools suite. More information on the Profiler is available in Chapter 7, "Using the SQL Server Profiler."
Data Transformation Services
Data Transformation Services (DTS) is a powerful tool used primarily to move data from one source to another. In the early days of client/server databases, the only way to move data from the mainframe to your shiny, new SQL Server box was to get a text file from the mainframe.
Then the fun really started. If the file was relatively uniform and straightforward, you might have been able to use a command-line BCP program to import, or bulk-copy, your data in. If not, you might have had to resort to a simple VB program to parse out each line and insert it, ever so slowly, into SQL Server.
DTS offers a simple interface, the DTS Designer, which is accessed through the SQL Enterprise Manager. DTS provides a simple means to import text files quickly, using a fast bulk insert process, and little development time. Following are some of the tasks you can do with DTS:
Quickly import a text file into SQL Server.
Using OLEDB or ODBC, connect to a different database (Oracle, DB2, and so forth) to use as either the source or target of the data transformations.
Write custom scripts to cleanse/transform data to your specifications. The scripts can be written in VBScript or JScript.
New to the 2000 version of DTS, connect to an ftp site and download files.
Send a mail message to someone with the results of an error message or a query.
Hook into an MS Message Queue to send or receive and process MSMQ messages.
Read information from an ini file to drive any DTS tasks, such as the server name to which to connect, the database in which to execute specific tasks, the table name to use, or the stored procedures to call.
Perform any of these tasks on a scheduled, recurring basis with full error control and workflow capabilities.
DTS is a wonderful tool for moving data between two places. Figure 1.4 shows a DTS Designer window inside SQL Enterprise Manager. It shows the multistep process to run a scheduled, daily import. The ini file (first step on the left) determines the name of the file to be imported and the database and table names for the destination. The truncate step empties out the table to prepare it to receive new data. If this step succeeds, the first path (colored green in the interface, though not in this screenshot) continues by running the data transformation from the text file (shown by the icon in the upper-right corner) to SQL Server (icon in the lower-left corner). If the step fails, the Log Failure step runs, which records the error and aborts the job. Finally, the GetFileDate script runs. This is a custom ActiveX script written with VBScript. It determines the date and time the file was imported, along with the date and time the file was "dropped off," and logs these details in the final step.
Figure 1.4. DTS Designer with a multistep import process example.
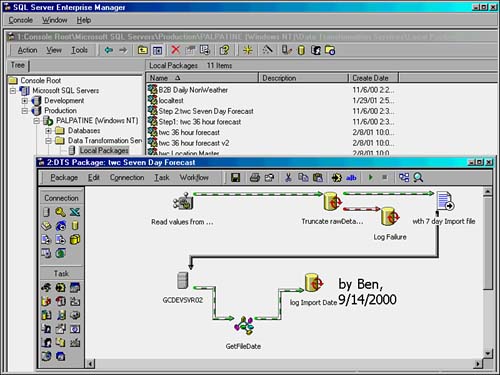
Replication
Replication is a server-based tool that allows data to be synchronized between two or more databases. Replication can send data from one SQL Server to another, or it can include Oracle, Access, or any other database that is accessible via ODBC or OLEDB.
SQL Server supports three kinds of replication:
Snapshot replication
Transactional replication
Merge replication
The replication functionality available may be restricted depending on the version of SQL Server 2000 that you are running.
Snapshot Replication
To perform snapshot replication, the server takes a picture, or snapshot, of the data in a table at a single point in time. Usually, if this operation is scheduled, the target data is simply replaced at each update. This form of replication is appropriate for small data sets, infrequent update periods (or for a one-time replication operation), or for management simplicity.
Transactional Replication
Initially set up with a snapshot, the server maintains downstream replication targets by reading the transaction log at the source and applying each change at the targets. For every insert, update, and delete, the server sends a copy of the operation to every downstream database. This is appropriate if low latency replicas are needed. Keep in mind that transactional replication does not guarantee identical databases at any given point in time. Rather, it guarantees that each change at the source will eventually be propogated to the targets. Transactional replication can keep databases in-synch within about five seconds of each other, depending on the underlying network infrastructure. If you need to guarantee that two databases are transactionally identical, look into two-phase commit possibilities.
Transactional replication might be used for a Web site that supports a huge number of concurrent browsers, but only a few updaters, such as a large and popular messaging board. All updates would be done against the replication source database, and would be replicated in near-real-time to all of the downstream targets. Each downstream target could support several Web servers, and each incoming Web request would be balanced among the Web farm. If the system needed to be scaled to support more read requests, you could simply add more Web servers and databases, and add the database to the replication scheme.
Merge Replication
With snapshot and transactional replication, a single source of data exists from which all the replication targets are replenished. In some situations, it might be necessary or desirable to allow the replication targets to accept changes to the replicated tables, and merge these changes together at some later date.
Merge replication allows data to be modified by the subscribers and sychronized at a later time. This could be as soon as a few seconds or a day later.
Merge replication can be helpful for a sales database that is replicated from a central SQL Server box out to several dozen sales laptops. As the sales personnel make sales calls, they can add new data to the customer database or change errors in the existing data. When the salespeople return to the office, they can synchronize their laptops with the central database. Their changes are submitted, and the laptop gets refreshed with whatever new data was entered since the last sycnhronization.
NOTEReplication will copy the data from your tables and indexed views and will even replicate changes to multiple tables caused by a stored procedure, but it will not normally re-create indexes or triggers at the target. It is common to have different indexes on replication targets rather than on the source to support different application and query requirements. |
Immediate Updating
Immediate update allows a replication target to immediately modify data at the source. This is accomplished by using a trigger to run a two-phase commit transaction. Immediate updating is performance-intensive, but it does allow for updates to be initiated from anywhere in the replication architecture.
More details on replication are available in Chapter 22, "Data Replication."
Microsoft Full Text Search Services
The Microsoft Full Text Search Services provides full text searching capabilities. This is useful for searching large text fields, such as movie reviews, book descriptions, or case notes.
Full text searching works together with the SQL database engine. You specify tables or entire databases that you want to index. The full text indexes are built and maintained outside the SQL engine in special full text indexes. You can specify how often the full text indexes are updated to balance out performance issues with timeliness of the data.
NOTEThe Full Text Search Server is a separate service from the database engine. You have the option of installing it as an add-on feature when you install SQL Server. You can add it to an existing server later by running SQL Setup. |
The SQL engine supports basic text searches against specific columns. For example, if you wanted to find all the rows where a text column contained the word guru, you might write a SQL statement like that in Listing 1.1.
Listing 1.1 A SQL Query That Searches for the Word Guru in the Resume Table
select * from resume where description like '%guru%'
This will find all the rows in the resume table where the description contains the word guru. This method has a couple of problems, however. First, the search will be slow. Because text columns can't be indexed by the database engine, a full table scan will be done to satisfy the query. Even if the data were stored in a varchar column instead of a text column, an index wouldn't help because you're looking for guru anywhere in the column, not just at the beginning. (More information on avoiding situations like this one are discussed later in the book, in Chapter 34.) What if you wanted to search for the word guru anywhere in the table, not just in the description column? What if you were looking for a particular set of skills, such as "SQL" and "ability to work independently?"
Full text indexing addresses these problems. To perform the same search with full text indexing, you would use a query like that in Listing 1.2.
Listing 1.2 A Full Text Query to Find the Results from Listing 1.1
select * from resume where contains(description, 'guru')
To perform the last search mentioned, use a query like that shown in Listing 1.3 in any free-text indexed column in the table:
Listing 1.3 A More Complex Full Text Query Demonstrating Features Not Available Through the SQL Server Database Engine's Indexing Methods
select * from resume where contains(*, 'SQL and "ability to work independently"')
NOTETwo commonly used functions are available for free text searches: CONTAINS and FREETEXT. CONTAINS is a better performing function and returns more exact results. FREETEXT will return looser results based on the meaning of the search phrase you enter. It does this by finding alternate word forms in your queries. For example, FREETEXT(*, 'work independently') would match 'Work Independently', 'Independent work preferred', and 'Independence in my work'. |
SQL Server Analysis Services
SQL Server Analysis Services provides essential services for using a data warehouse. These services are often referred to as OLAP, which stands for On Line Analytical Processing.
SQL Server Analysis Services connects to one or more SQL Server databases containing a data warehouse. Based on the criteria you select, data cubes are created on this data to allow powerful searches, called data mining. The SQL Server Analysis Services client tool assists in the addition of new data to the warehouse and allows scheduling of cube updates.
NOTESQL Server Analysis Services can be leveraged even if you do not have your data warehouse in a classical star or snowflake schema. |
OLAP is commonly used to perform the following tasks:
Perform trend analysis to predict the future. Based on how many widgets I sold last year, how many will I sell next year?
Combine otherwise disconnected variables to gain insight into past performance. Was there any connection between widget sales and rainfall patterns? Searching for unusual connections between your data points is a typical data mining exercise.
Perform offline summaries of commonly used data points for instant access via Web or custom interface. For example, a relational table might contain one row for every click on a Web site. OLAP can be used to summarize these clicks by hour, day, week, and month, then further categorize these by business line.
You can access OLAP services through the Analysis Services front-end application. For more in-depth analysis, make use of a SQL-like query language called Multidimensional Expressions, or MDX. MDX uses similar language to SQL, but instead of operating on tables in the from clause, it operates on data cubes.
SQL Server Analysis Services is a complex topic. For more information on MDX, data cubes, and how to use data warehousing analysis services, see Chapter 42, "Microsoft SQL Server Analysis Services."
Distributed Transaction Coordinator
With the increasing proliferation of distributed systems comes the need to access and modify data that is often in separate physical locations and in varying types of datasources. These distributed transactions need to be treated as a single logical transaction (one "Unit of Work"). You need a way to ensure that the distributed transaction operates in the same way that a local transaction does, and that it adheres to the same ACID properties of a local transaction, across multiple servers. Microsoft provides this capability with the Distributed Transaction Coordinator.
Microsoft has implemented its distributed transaction processing capabilities using the industry standard two-phase commit protocol. The Distributed Transaction Coordinator Service (MS DTC) provides the means of managing distributed transactions within the SQL Server 2000 environment. Typically, each Microsoft SQL Server will have an associated distributed transaction coordinator on the same machine with it. MS DTC runs as a separate service and can be started using the SQL Sevice Manager, SQL Enterprise Manager, or it can be started via the Windows Services Control Panel.
The MS DTC allows applications to extend transactions across two or more instances of MS SQL Server and participate in transactions managed by transaction managers that comply with the X/Open DTP XA standard. The MS DTC will act as the primary coordinator for these distributed transactions. The specific job of the MS DTC is to enlist (include) and coordinate SQL Servers and remote servers (linked servers) that are part of a single distributed transaction. The MS DTC coordinates the execution of the distributed transaction at each participating datasource and makes sure the distributed transaction completes. It ensures that all updates are made permanent in all datasources (committed), or makes sure that all of the work is undone (rolled back) if it needs to be. At all times, the state of all datasources involved are kept intact.
For more information on distributed transactions and the MS DTC, see Chapter 32, "Distributed Transaction Processing."
Notification Services
SQL Server Notification Services is a platform for the development and deployment of notification applications. Notification applications send messages to users based upon subscriptions made to the notification application. Depending on how the subscriptions are configured, messages can be sent to the subscriber immediately or on a predetermined schedule. The messages sent can be personalized to reflect the preferences of the subscriber.
The Notification Services platform is a reliable, high-performance, scalable server that is built on the .NET Framework and SQL Server 2000 and runs on the Microsoft Windows Server family of operating systems. Notification Services was designed for extensibility and interoperability with a variety of existing applications.
SQL Server primarily serves as the storage location for the subscription information for Notification Services. The subscriber and delivery information is stored in a central Notification Services database, and individual subscription information is stored in application-specific databases.
For more information on the Notification Server architecture and configuring and using SQL Server Notification Services, see Chapter 45, "SQL Server Notification Services."
English Query
English Query is a framework that provides the tools to develop and deploy English Query applications, which allow end users to pose questions against your relational database in English instead of forming a query with a SQL statement.
Developing an English Query application involves creating, refining, testing, compiling, and deploying a model based on a normalized SQL database or an OLAP cube. In general, it is easiest to create English Query applications against normalized SQL databases and the resulting applications are typically more flexible and powerful than those developed against databases that are not normalized.
The English Query Model Editor runs within the Visual Studio 6.0 development environment. You can begin the creation of your English Query applications using either the SQL Project Wizard or the OLAP Project Wizard to automatically create an English Query project and model. After the basic model is created, you can refine, test, and compile it into an English Query application and then deploy it (to the Web, for example).
The basic steps for developing and deploying an English Query application are as follows:
-
Determine the questions that end users are most likely to ask. Determining the questions to be answered prior to creating a model helps you to create the appropriate entities and relationships and test your application.
-
Create a basic model using the SQL Project Wizard or OLAP Project Wizard. The wizards create a basic model by bringing in the schema of the data source (database or cube) and automatically creating entities and relationships based on the tables, columns, joins, or OLAP objects.
-
Refine the model to address any questions that cannot be answered using the basic model. This is done by adding additional entities and relationships.
-
Test and refine the model until it properly returns the answers to the questions posed.
-
Build the application and deploy it. An English Query application can be deployed as a Visual Basic or Microsoft Visual C++ application, or on a Web page running on the Microsoft Internet Information Services (IIS) as a set of Microsoft Active Server Pages (ASP).
For more detailed information on developing and deploying English Query applications, see Chapter 47, "English Query."







