Windows Performance Counters
You need to be able to tell how NT/Windows 2000 is reacting to the presence of SQL Server running within it: how SQL Server is using memory, the processors, and other important system resources. A large number of objects and counters relate to Windows and the services it is running. The next few sections will look at which objects and counters provide useful information in investigating certain areas of the system and focus on the ones that you need for monitoring SQL Server.
TIPSome of the network counters are available only if you add the Network Monitor Agent. You can add this software component through the Network icon (Add Network Components) in the Control Panel. This is highly recommended because it will allow you to monitor all activity passing through the installed network card. Figure 37.5 shows the Install Network Component option for both Windows 2000 and Windows NT. Figure 37.5. Windows 2000/NT install network management and monitoring tools.
|
Monitoring the Network Interface
One area of possible congestion is the network card or network interface; it does not matter how fast the server's work is if it has to queue up to go out through a small pipe.
Remember: Any activity on the server machine might be consuming some of the bandwidth of the network interface/card. You can see the total activity via Performance Monitor. The detail information is good now. Table 37.1 shows the typical network performance object and counters you will want to be using to measure the total network interface activity.
| Performance Monitor Object | Description |
|---|---|
| Network Inter: Bytes Received | The rate at which bytes are received on the interface. |
| Network Inter: Bytes Sent | The rate at which bytes are sent on the interface. |
| Network Inter: Bytes Total | The rate at which all bytes are sent and received on the interface. |
| Network Inter: Current Bandwidth | The bits per second (bps) of the interface card. |
| Network Inter: Output Queue Length | The length of the output packet queue (in packets). If this is longer than 2, delays are being experienced and a bottleneck exists. |
| Network Inter: Packets Received | The rate at which packets are received on the network interface. |
| Network Inter: Packets Sent | The rate at which packets are sent on the network interface. |
| Network Inter: Packets | The rate at which packets are sent and received on the network interface. |
| Server: Bytes Received | The number of bytes the server has received from the network. This is the big picture indicator of how busy the server is. |
| Server: Bytes Transmitted | The number of bytes the server has sent/transmitted to the network. Again, this is a good overall picture of how busy the server is. |
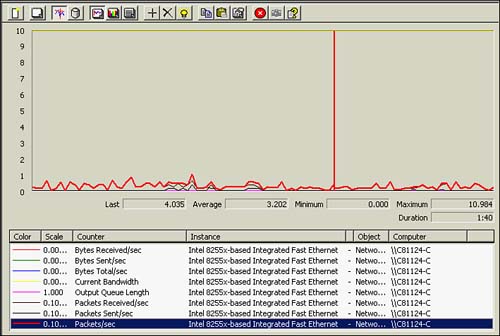
Figure 37.6 illustrates a pretty low usage picture for a particular network interface.
Figure 37.6. Network interface's performance object and counters.
NOTEUnder previous versions of SQL Server (6.5 and earlier), a counter called SQLServer:Network Reads/sec indicated SQL Server's contribution. With SQL Server 2000, you need to use the DBCC PERFMON command to find similar information or use sp_monitor. |
In general, if the SQL Server counter is grossly lower than the server's counter, then other activity on the server is occurring that is potentially bogging this server down or not allowing SQL Server to be used optimally. The rule of thumb here is to isolate all other functionality to other servers if you can and let SQL Server be the main application on a machine.
Pay strict attention to how many requests are queuing up, waiting to make use of the network interface. You can see this by using the DBCC PERFMON command and looking at the Command Queue Length value. As mentioned earlier, this number should be 0. If it is 2 or more, then the network interface has a bottleneck. Check the bus width of the card. Obviously, a 32-bit PCI card is faster than an 8-bit ISA one. Also, check that you have the latest drivers from the hardware vendor.
When using DBCC PERFMON, the detail information of actual bytes read and written allows you to understand the size of this network activity. A quick calculation of reads/bytes gives you an average size of reads from the network. If this is large, then you might want to question what the application is doing and whether the network as a whole can handle this big of a bandwidth request.
DBCC PERFMON Go Statistic Value -------------------------------- ------------------------ Network Reads 39.0 Network Writes 47.0 Network Bytes Read 4008.0 Network Bytes Written 70975.0 Command Queue Length 0.0 Max Command Queue Length 0.0 Worker Threads 0.0 Max Worker Threads 0.0 Network Threads 0.0 Max Network Threads 0.0 Wait Type Requests Wait Time Signal Wait Time ----------------- --------------- ---------------- ------------------------ NETWORKIO 18.0 40.0 0.0
Sp_Monitor as well as several SQL Server system variables can also be used to see much of what is being shown in DBCC PERFMON. DBCC PERFMON:Network Reads corresponds to sp_monitors (or @@pack_received system variable) packets_received and DBCC PERFMON:Network Writes corresponds to sp_monitors (or @@pack_sent system variable) packets_sent.
The following SELECT statement retrieves the current picture of what is being handled by SQL Server from a network packets point of view:
SELECT @@connections as 'Connections',
@@pack_received as 'Packets Received',
@@pack_sent as 'Packets Sent',
getdate() as 'As of datetime'
go
Connections Packets Received Packets Sent As of datetime
39 998 1799 2001-09-01 14:11:56.660
(1 row(s) affected)
Monitoring the Processors
The main processor(s) of your server is doing the majority of all the hard work, executing the operating system code and all applications. This is the next logical point to start looking at the performance of your system. The emphasis here will be to see if the processors that are allocated to the server are busy enough to maximize performance, but not too saturated as to create a bottleneck. The rule of thumb here is to see if your processors are working at between 50?80 percent. If this usage is consistently above 90?95 percent, then you must look at splitting off some of the workload or adding processors. Table 37.2 indicates some of the key performance objects and counters for measuring processor utilization.
| Performance Monitor Object | Description |
|---|---|
| Processor: % Processor Time | The rate at which bytes are received on the interface. |
| System: Processor Queue Length | The number of threads in the processor queue. A sustained processor queue of greater than two threads indicates a processor bottleneck. |
| System: Threads | The number of threads executing on the machine. A thread is the basic executable entity that can execute instructions in a processor. |
| System: Context Switches | The rate at which the processor and SQL Server had to change from executing on one thread to executing on another. This costs CPU resources. |
| Processor: % Interrupt Time | The percentage of time that the processor spends receiving and servicing hardware interrupts. |
| Processor: Interrupts/sec | The average number of hardware interrupts the processor is receiving and servicing. |
The counters System: % Total Processor Time, System: Processor Queue Length and Processor: % Processor Time are the most critical to watch. If the percentages are consistently high (above that 90?95 percent level), then you need to identify which specific processes and threads are consuming so many CPU cycles.
From the SQL Server point of view, you can execute a simple SELECT statement that yields the SQL Server processes and their corresponding threads.
[View full width]SELECT spid, lastwaittype, dbid, uid, cpu, physical_io, memusage,status, loginame,program_name from master..sysprocesses ORDER BY cpu desc Go
This will give you the top CPU resource hogs that are active on SQL Server. After you identify which processes are causing a burden on the CPU, check whether they can be either turned off or moved to a different server. If they cannot be turned off or moved, then you might want to consider upgrading the processor.
No one should use the SQL Server box as a workstation because using the processor for client applications can cause SQL Server to starve for processor time. The ideal Windows setup for SQL Server is on a standalone member server to the Windows domain. Do not install SQL Server onto a primary domain Controller (PDC) or backup domain controller (BDC) because they run additional services that consume memory, CPU, and network resources.
Before you upgrade to the latest processor just because the % Processor Time counter is constantly high, you might want to check the load placed on the CPU by your other adapters. By checking Processor: % Interrupt Time and Processor: Interrupts/sec, you can tell whether the CPU is interrupted more than normal by adapters such as disk controllers.
The % Interrupt Time should be as close to 0 as possible; controller cards should handle any processing requirements. The optimum value of Interrupts/Sec varies with the CPU used; DEC Alpha processors generate a nonmaskable interrupt every 10 milliseconds (ms), whereas Intel processors interrupt every 15ms. The lowest absolute values are 100 interrupts per second and 67 interrupts per second, respectively.
The System: Context Switches counter can reveal when excessive context switching occurs, which usually directly affects overall performance. In addition, the System: Threads counter can give a good picture of the excessive demand on the CPU of having to service huge numbers of threads. In general, only look at these counters if processor queuing is happening.
By upgrading inefficient controllers to bus-mastering controllers, you can take some of the load from the CPU and put it back on the adapter. You will also want to keep the controller patched with the latest drivers from the hardware vendor.
Monitoring Memory
Memory, like the processor, is divided into segments for each process running on the server. If memory has too much demand, the operating system has to use virtual memory to supplement the physical memory. Virtual memory is storage allocated on the hard disk; it is named PAGEFILE.SYS under Windows. Table 37.3 reflects the main performance objects and counters that are best utilized to monitor memory for SQL Server.
| Performance Monitor Object | Description |
|---|---|
| Process: Working Set|sqlservr | The set of memory pages touched recently by the threads in the process (SQL Server in this case). |
| MSSQL Buffer Manager: Buffer | The percentage of pages that were found in the cache hit ratio buffer pool without having to incur a read from disk. |
| MSSQL Buffer Manager: Total Pages | The total number of pages in the buffer pool, including database pages, free pages, and stolen pages. |
| MSQL Memory Manager: Total Server Memory (KB) | The total amount of dynamic memory the server is currently consuming. |
| Memory: Pages | The number of pages read from or written to disk to resolve hard page faults. This usually gives a direct indication of memory issues. |
| Memory: Pages Read | The number of times that the disk was read to resolve hard page faults. |
| Memory: Page Faults | The overall rate at which faulted pages are handled by the processor. |
| Process: Page Faults|sqlservr | The rate of page faults occurring in the threads associated with a process (SQL Server in this case). |
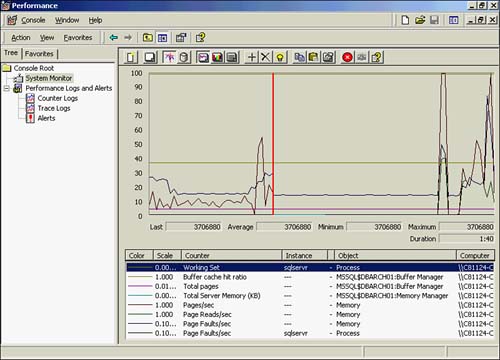
Numerous goals can be achieved related to memory and SQL Server. Figure 37.7 shows a typical monitoring of memory underway.
Figure 37.7. Memory performance object and counters.
It is important to remember that when the operating system or SQL Server isn't able to use memory to find something and has to use virtual memory stored on the disk, performance will degrade. Therefore, you need to work on minimizing this situation, known as swapping or page faulting.
To observe the level of the page faulting, you can look at the Memory: Page Faults/sec and Process: Page Faults (for a SQL Server Instance) counters.
Next in line are the MSSQL Buffer Manager: Buffer Cache hit ratio and MSSQL Buffer Manager: Total Pages counters. These directly indicate how well SQL Server is finding data in its controlled memory (cache). You need to achieve a near 90 percent or higher ratio here. DBCC PERFMON also has the Cache Hit Ratio and Cache Size information.
If the Memory: Pages/sec counter is greater than 0 or the Memory: Page Reads counter is greater than 5, the operating system is being forced to use disk to resolve memory references. These are called hard faults. The Memory: Page counter is one of the best indicators of the amount of paging that Windows is doing and the adequacy of SQL Server's current memory configuration.
Because the memory used by SQL Server 2000 dynamically grows and shrinks, you might want to track the exact usage using either Process: Working Set: SQLServr or MSSQL: Memory Manager: Total Server Memory (KB). These counters indicate the current size of the memory used by the SQL Server process. If these are consistently high as compared to the amount of physical memory in the machine, then you are probably ready to install more memory on this box. If you see a performance degradation because SQL Server must continually grow and shrink its memory, you should either remove some of the other services or processes running or use the configuration option Use a Fixed Memory Size.
Monitoring the Disk System
By monitoring the portion of the system cache used for the server services (synchronous) and that related to the SQL Server (asynchronous), you can see how much disk access is related to SQL Server. Not all asynchronous disk activity is SQL Server, but on a dedicated box, it should be. You can watch a number of different synchronous and asynchronous counters, depending on the type of activity you want to monitor. The essential performance objects and counters related to monitoring the disk system are indicated in Table 37.4.
| Performance Monitor Object | Description |
|---|---|
| Physical Disk: Current Disk Queue Length | The number of outstanding requests (read/write) for a disk. |
| Physical Disk: Avg. Disk Queue Length | The average number of both read and write requests that were queued for disks. |
| Physical Disk: Disk Read Bytes | The rate that bytes are transferred from the disk during read operations. |
| Physical Disk: Disk Write Bytes | The rate that bytes are transferred to the disk during write operations. |
| Physical Disk: % Disk Time | The percentage of elapsed time that the selected disk drive is busy servicing read or write requests. |
| Logical Disk: Current Disk Queue Length | The number of outstanding requests (read/write) for a disk. |
| Logical Disk: Avg. Disk Queue Length | The average number of both read and write requests that were queued for disks. |
| Logical Disk: Disk Read Bytes | The rate that bytes are transferred from the disk during read operations. |
| Logical Disk: Disk Write Bytes | The rate that bytes are transferred to the disk during write operations. |
| Logical Disk: % Disk Time | The percentage of elapsed time that the selected disk drive is busy servicing read or write requests. |
Before you can get information from some of these counters, you must first turn them on by using diskperf. From a command prompt, you need to execute diskperf -y and then reboot the computer (see Figure 37.8). This is done this way so that nothing is slowing down disk performance in any way (as the default). If you want to monitor this area, you have to ask for it and take a slight hit on overall performance due to the overhead of these counters.
Figure 37.8. Setting the diskperf ?y option on.
Slow disk I/O causes a reduction in the transaction throughput. To identify which disks are receiving all the attention, you should monitor both the Physical Disk and Logical Disk performance objects. You have many more opportunities to tune at the disk level than you do with other components such as processors. This has long been the area that database administrators and system administrators have been able to get better performance.
CAUTIONA critical oversight such as specifying "compression" when configuring a disk drive that will be used to store either the data portion or log portion of a SQL Server database can be fatal. Well, maybe not fatal, but the degradation in performance at the disk-file system level can impact SQL Server between 40 and 50 percent. Here's an example of a situation that was discovered the hard way during a recent production implementation. Queries were taking much longer in production than in test, even with the exact same size databases and same workload. The system admin for the production system discovered this compression error, expanded the disk, and was given a week's vacation in Hawaii. Do yourself a favor and just take a quick glance at the disk management properties of each of your production drives to verify that compression is not being used (NTFS). |
The place to start is with looking at the Physical Disk: Current Disk Queue Length and Physical Disk: Avg. Disk Queue Length counters' behavior of all disks or of each particular disk. This will identify where much of the attention is from a disk-usage point of view. Figure 37.9 shows a disk-monitoring session under way that is loaded with long disk queues. In other words, disk operations are being stacked up and there appears to be a major issue here.
Figure 37.9. Disk performance object and counters.
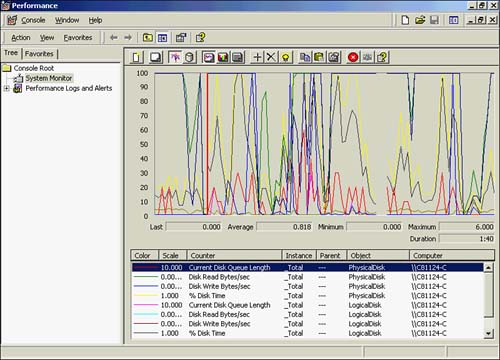
As you monitor each individual disk, you might see that some drives are not as busy as others. You can relocate heavily used resources to minimize these long queue lengths that you have uncovered and spread out the disk activity. Common techniques for this are to relocate indexes away from tables, isolate read-only tables away from volatile tables, and so on.
The Physical Disk: % Disk Time counter for each physical disk drive will show you the percentage of time that the disk is active; a continuously high value could indicate an under-performing disk subsystem.
CAUTIONRemember to turn off the disk-performance counters when you are finished by executing diskperf -n. Running your system with these counters on will impact your performance. |
Of course, the monitoring up to this point will only show half the picture if drives are partitioned into multiple logical drives. To see the work on each logical drive, you need to examine the logical disk counters; in fact, you can monitor read and write activity separately with Logical Disk: Disk Write Bytes/sec and Logical Disk: Disk Read Bytes/sec.
TIPIf you are running disk striping, you need to turn on the disk counters using diskperf -y. |
If you use RAID, it is necessary to know how many physical drives are in each RAID array to figure out the monitored values of disk queuing for any one disk. In general, just divide the disk queue value by the number of physical drives in the disk array. This will give you a fairly accurate number for each physical disk's queue length.







