Monitoring Replication
After replication is up and running, it is important for you to monitor the replication and see how things are running. You can do this in several ways, including SQL statements, SQL Enterprise Monitor, and Windows NT Performance Monitor. You are interested in the agent's successes and failures, the speed at which replication is done, and the synchronization state of tables involved in replication. Other things to be watched are the sizes of the distribution database, the growth of the subscriber databases, and the available space on the distribution server's snapshot working directory.
SQL Statements
One way to look at the replication configuration and do things like validate row counts is to use various replication stored procedures.
These include the following:
sp_helppublication? Info on the publication server
sp_helparticle? Article definition information
sp_helpdistributor? Distributor information
sp_helpsubscriberinfo? Subscriber server information
sp_helpsubscription The subscription information
Figure 22.36. Replication stored procedure results.
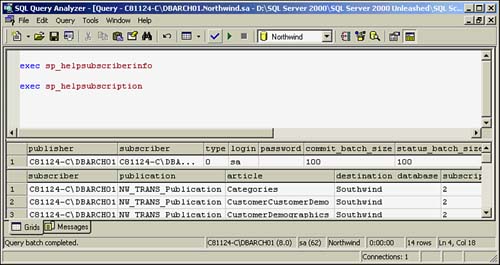
These are all extremely useful for verifying exactly at what the replication configuration is really configured.
Also
sp_replcounters? Shows the activity of this replication session. You can see the volume of traffic and the throughput here.
exec sp_replcounters go
Yields
database repl_trans rate trans/sec latency (sec) etc. Northwind 110 71.428574 2.1830001
For actual row count validation:
sp_publication_validation? Goes through and checks the row counts of the publication and subscribers.
exec sp_publication_validation @publication = 'NW_TRANS_Publication' go
Yields
Generated expected rowcount value of 53 for Territories. Generated expected rowcount value of 58 for Suppliers. Generated expected rowcount value of 6 for Shippers. Generated expected rowcount value of 4 for Region. Generated expected rowcount value of 154 for Products. Generated expected rowcount value of 1690 for Orders. Generated expected rowcount value of 2155 for Order Details. Generated expected rowcount value of 49 for EmployeeTerritories. Generated expected rowcount value of 18 for Employees. Generated expected rowcount value of 95 for Customers. Generated expected rowcount value of 0 for CustomerDemographics. Generated expected rowcount value of 0 for CustomerCustomerDemo. Generated expected rowcount value of 16 for Categories.
Another way to monitor replication is to look at the actual data that is being replicated. To do this, first run a SELECT count (*) FROM tblname statement against the table where data is being replicated. Then verify directly if the most current data available is in the database. If you make a change to the data in the published table, do the changes show up in the replicated tables? If not, you might need to investigate how replication was configured on the server.
If you are allowing updatable subscriptions, the replication queue comes into play. You'll need to learn all about the queueread utility. This utility configures and begins the Queue Reader Agent, which reads messages stored in the SQL Server queue, or a Microsoft message queue, and applies those messages to the publisher. queueread is a command prompt utility.
SQL Enterprise Manager
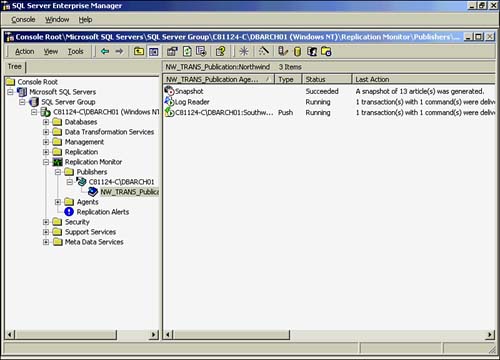
As you can imagine, Enterprise Manager provides considerable information about the status of replication. Most of this is available via the Replication Monitor branch. In Replication Monitor, you can see the activity for publishers, agents, and the ability to configure alerts:
Publishers?This folder contains information about publishers on the machine. By selecting any publisher on the machine, you can view information about any computers that have subscribed to the publication. This will tell you the current status and the last action taken by the subscriber.
Agents?The Agents folder contains information about the different agents on the machine. By choosing any Agents folder, you can see the current status of that agent. Selecting an agent and double-clicking it will display the history of that agent.
Replication Alerts?The Replication Alerts folder allows you to configure alerts to fire in response to events that occur during replication. These can activate when errors occur, or in response to success messages.
As you can see from Figure 22.37, it appears that this transactional replication scenario is operating successfully.
Figure 22.37. Successful data replication.
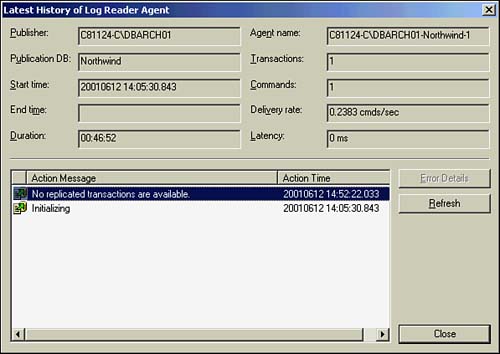
If you drill down even more, you will see the execution history. Figure 22.38 shows a healthy Log Reader history.
Figure 22.38. Execution history.
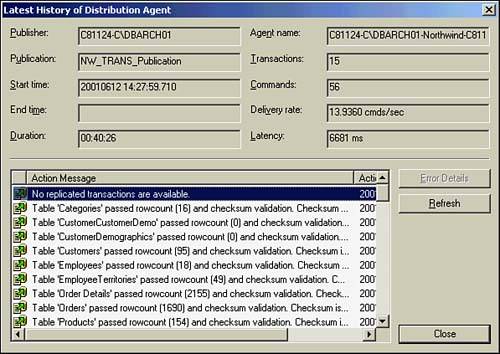
Through Enterprise Manager and Replication Monitor, you also can invoke the validate subscriptions processing to see if replication is in sync. Under the Publication branch of Replication Monitor, simply right-click on the publication you wish to validate. You will see the menu option to Validate Subscriptions. You can validate all subscriptions or just a particular one. After invoked, the results can be viewed via the distribution agent history as depicted in Figure 22.39.
Figure 22.39. Distribution agent?validated subscription details.
Troubleshooting Replication Failures
Configuring replication and monitoring for successful replication are pretty easy. The fun begins when failures start arising. Using Replication Monitor starts paying for itself in big dividends quickly. Red flags begin appearing to indicate agent failures. Depending on how you have the Alerts defined, you are probably also getting considerable e-mails or pages.
The following are the most common issues you will find with data replication:
Data row count inconsistencies, as we looked at in the prior section
Subscriber/publisher schema change failures
Connection failures
Agent failures
For the conventional replication situations, if the problem is with the validation of subscriptions processing, it is usually best to resync the subscription by dropping it and resubscribing.
Another common issue is that of the SQL Server Agent service not starting. Manually attempting to restart this service usually shakes things loose.
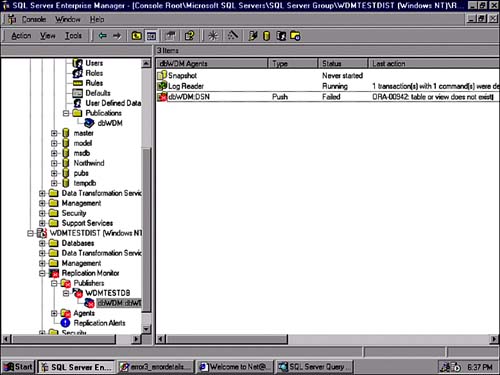
Sometimes an object on the subscriber will become messed up and result in an error like that in Figure 22.40. The solution is usually to create that object again and reload its data via BCP or DTS. Then resync the subscription. The subscription included this object originally, but it has become invalid in some way.
Figure 22.40. Replication error?object existence issue.
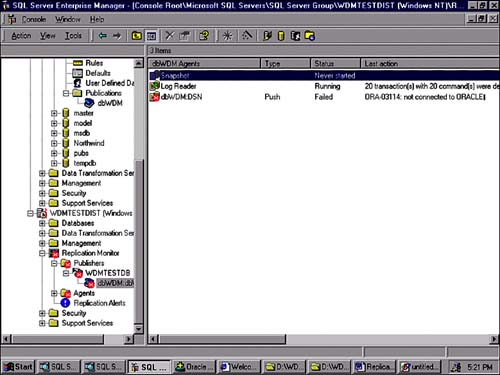
With a heterogeneous subscriber, you often see connection errors due to invalid login IDs used in the ODBC connection. Figure 22.41 illustrates just such a failure. The quick fix is usually to just redefine the ODBC data source connection information.
Figure 22.41. Replication error?connectivity issue.
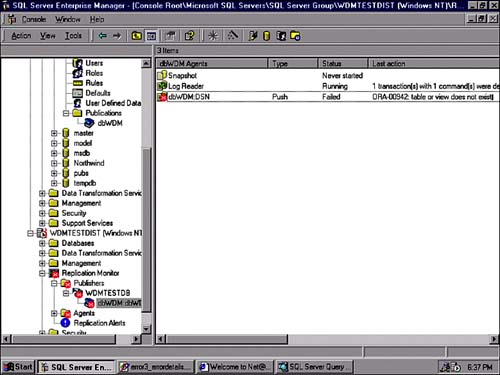
A much more complex failure can arise when the replication queue is stopped due to some type of SQL language failure in the command being replicated. This is extremely serious because it stops all replication from continuing and the distribution database starts growing rapidly. Replication keeps trying to execute this, failing each time. This situation is essentially a permanent road block.
Figure 22.42 shows such a failure. The solution is to locate the exact transaction in the distribution database, and delete it physically from the transaction queue. This is highly unusual, but necessary when the circumstance presents itself.
Figure 22.42. Push failure.
First, by looking at the error detail information in the Distribution Agent History dialog box, you will be able to isolate the SQL statement on which it is choking. You now have to find this in the distribution database. Start by executing the sp_browsereplcmds stored procedure. This gives you all the replication transactions (xact_seqno's) along with the associated SQL command. You will have to pump this to a text file for searching. You then must search this data for the matching SQL command. When you locate it, look for its associated transaction number (xact_seqno). Use this xact_seqno value to delete it from the Msrepl_commands table in the distribution database. This will free up the road block. You will see this type of issue about once every six months.
The Performance Monitor
You also can use Windows NT Performance Monitor to monitor the health of your replication scenario. Installing SQL Server adds several new objects and counters to Performance Monitor:
SQLServer:Replication Agents?This object contains counters used to monitor the status of all replication agents, including the total number running.
SQLServer:Replication Dist?This object contains counters used to monitor the status of the distribution agents, including the latency and the number of transactions transferred per second.
SQLServer:Replication Logreader?This object contains counters used to monitor the status of the log reader agent, including the latency and the number of transactions transferred per second.
SQLServer:Replication Merge?This object contains counters used to monitor the status of the merge agents, including the number of transactions and the number of conflicts per second.
SQLServer:Replication Snapshot?This object contains counters used to monitor the status of the snapshot agents, including the number of transactions per second.
Replication in Heterogeneous Environments
SQL Server 2000 allows for transactional and snapshot replication of data into and out of environments other than SQL Server. This is termed heterogeneous replication. The easiest way to set up this replication is to use ODBC or OLE DB, and create a push subscription to the subscriber. This is much easier to make work than you would imagine. SQL Server can publish to the following database types:
Microsoft Access
Oracle
Sybase
IBM DB2/AS400
IBM DB2/MVS
SQL Server can replicate data to any other type of database, providing that the ODBC driver supports the following:
The driver must be ODBC Level-1 compliant.
The driver must be 32-bit, thread-safe, and designed for the processor architecture on which the distribution process runs.
The driver must support transactions.
The driver and underlying database must support Data Definition Language (DDL).
The underlying database cannot be read-only.
Replicating to Internet Subscribers
With SQL Server 2000, you easily can replicate data to Internet subscribers. The first requirement for this feature is that your publication allows pull and anonymous subscriptions. You must take three steps to configure an Internet subscription:
-
Configure the publisher or distributor to listen on TCP/IP.
-
Configure a publication to use FTP.
-
Configure a subscription to use FTP.
Configuring a Publisher or Distributor to Listen on TCP/IP
Before you can set up replication to Internet subscribers, you must configure SQL Server to communicate on TCP/IP or the multiprotocol network library. You can configure this area using the SQL Server Network Utility. You also must have Internet Information Server set up on the distribution server because Internet replication relies on the FTP service to transfer the snapshots from the distribution server to the subscribers. You have to set up the FTP home directory to the snapshot folder and configure the FTP home directory as an FTP site.
Configuring a Publication to Use FTP
After you have configured the server to use FTP, the next step is to set up the publication to allow for Internet replication. You can do this using SQL Enterprise Manager. After it is configured, the distribution or merge agents will use FTP to download the snapshot files to the subscriber server. After the snapshot files are copied to the subscriber, the agent applies the files to the tables at the subscriber. The following steps walk you through setting up an existing database to use the Internet:
-
Connect to the publishing server in SQL Enterprise Manager. From the Tools menu, choose Create and Modify Publications. This will open the Create and Manage Publication dialog box.
-
From the dialog box, choose the publication that you want to edit and click the Properties & Subscriptions button. This will open the publication's Properties box.
-
From the Subscription Options tab, put a check in the Allow Subscriptions to Be Downloaded Using FTP check box.
Configuring a Subscription to Use FTP
After the publication has been configured to use FTP, you must create a pull or anonymous subscription to the database. These subscriptions are created the same way that you would create any other subscription. The difference is that you need to configure the FTP options. The following steps walk you through setting up Internet-enabled subscriptions:
-
Connect to the publishing server in SQL Enterprise Manager. From the Tools menu, choose Pull Subscriptions. This will open the Pull Subscriptions dialog box.
-
From the dialog box, choose the publication that you want to edit and click the Properties button. This will open the publication's properties box.
-
From the Pull Subscriptions Properties screen, choose the Snapshot Delivery tab. Put a check in the Use the File Transfer Protocol When Downloading Snapshot Files from the Distributor check box. Enter the options in the FTP Parameters section.
Backup and Recovery in a Replication Configuration
Something that will reap major benefits for you after you have implemented a data replication configuration is a replication-oriented backup strategy. You must realize that the scope of data and what you must back up together has changed. In addition, you must be aware of what the recovery timeframe is and plan your backup/recovery strategy for this. You might not have multiple hours available to you to recover an entire replication topology. You now have databases that are conceptually joined, and you might need to back them up together as one synchronized backup. Figure 22.43 depicts an overall backup strategy for the most common recovery needs.
Figure 22.43. Common backup strategy for different recovery needs.
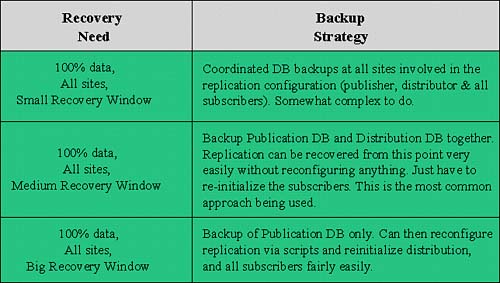
When backing up environments, back up the following at each site:
Publisher (published db, msdb, and master)
Distributor (distribution db, msdb, and master)
Subscribers (subscriber db, optionally msdb and master when pull subscriptions are being done)
Always make copies of your replication scripts and keep them handy. At a very minimum, keep copies at the publisher and distributor and one more location, such as at one of your subscribers. You will end up using these for recovery someday.
Don't forget to back up master and msdb when any new replication object is created, updated, or deleted.
If you have allowed updating subscribers using queued updates, you will have to expand your backup capability to include these queues.
In general, you will find that even when you walk up and pull the plug on your distribution server, publication server, or any subscribers, automatic recovery works well to get you back online and replicating quickly without human intervention.
Some Performance Thoughts
From a performance point of view, you will find that the replication configuration defaults err toward the optimal throughput side. That's the good news. The bad news is that everybody is different in some way, in which case you will have to consider a bit of tuning of your replication configuration. In general, you can get your replication configuration working well by doing the following:
-
Keeping the amount of data to be replicated at any one point small by running agents continuously, instead of at long, scheduled intervals.
-
Setting a minimum amount of memory allocated to SQL Server using the Min Server Memory option to guarantee ample memory across the board.
-
Using good disk drive physical separation rules, such as keeping translog on a separate disk drive from the data portion. Your transaction log will be much more heavily used when you have opted for transactional replication.
-
Putting your snapshot working directory on a separate disk drive to minimize disk drive arm contention. Make sure you use separate snapshot folders for each publi-cation.
-
Publishing only what you need. By selectively publishing only the minimum amount of data that your requirements need, you will, by definition, be implementing a much more efficient replication configuration, which is faster overall.
-
Trying to run snapshots in nonpeak times so your network and production environments won't be bogged down.
-
Minimizing transformation of data involved with replication.
Log Shipping: An Alternative to Data Replication
If you have a small need to create a read-only (ad hoc query/reporting) database environment that can tolerate a certain high degree of data latency, you might be a candidate to use log shipping. Log shipping is a new feature for SQL Server 2000. Using log shipping as an alternative to data replication has been referred to as "the poor man's data replication." Keep in mind that log shipping has three primary purposes:
Making an exact image copy of a database on one server from a database dump
Creating a copy of that database on one or more other servers from that dump
Continuously applying transaction log dumps from the original database to the copy
In other words, log shipping is effectively replicating the data of one server to one or more other servers via transaction logs. This is a great solution when you have to create one or more fail-over servers. It turns out that, to some degree, log shipping fits the requirement of creating a read-only subscriber as well.
You need to consider some important issues associated with log shipping, however:
The user IDs and the permissions associated with them will be copied as part of this scenario. They will be the same at all servers, which might or might not be what you want.
Log shipping has no filtering.
Log shipping has no data transformation.
Data latency exists because of the frequency of transaction log dumps being performed at the source and when they can be applied to the destination copies.
Sources and destinations must be the same SQL Server version.
All tables must be copied.
Indexes cannot be tuned in the copies to support the read-only reporting requirements.
Data is read-only.
Some of these restrictions might quickly disqualify log shipping as an alternative to using data replication. However, log shipping might be adequate for certain situations.
In Figure 22.44, you can see the start of the Database Maintenance Plan Wizard that includes the setup for log shipping if you are using the Enterprise Edition.
Figure 22.44. Log shipping.
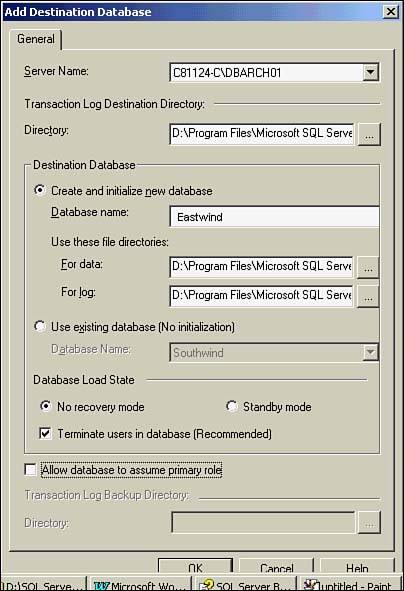
You will simply specify what your source database is at this point and check the box that indicates you will be log shipping. When this box is checked, you are taken through a series of log shipping?specific dialog box screens. You will specify the database backup plan, the location where backups are stored (on a shared drive for log shipping), and the backup schedule. For the log shipping part, the next step is to identify the destination database. You can either have the destination be created automatically, or start from a database that was manually created. Figure 22.45 indicates that a new database should be created.
Figure 22.45. Log shipping?new destination database creation.
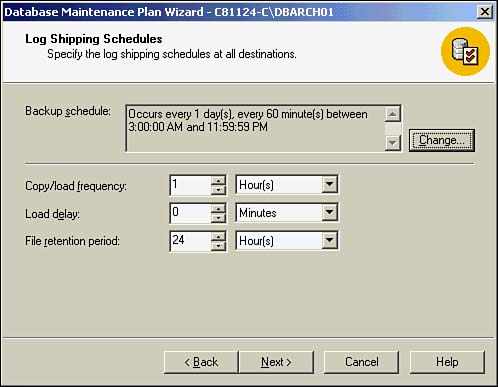
After a destination database has been specified, you can set up as many other destination databases as you want. You will go through a series of steps that further define the log shipping details. Figure 22.46 indicates the detailed log shipping schedule information (copy/load, delay, and retention information).
Figure 22.46. Log shipping schedule.
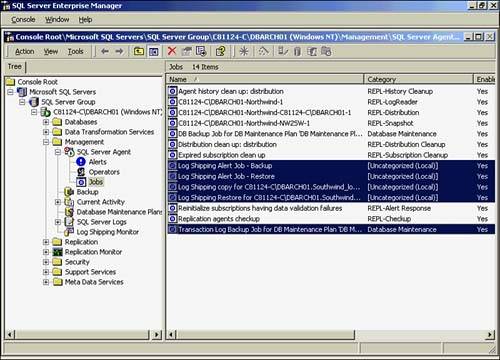
After the scheduling has been set up, a series of jobs dedicated to the log shipping processes will be set up along with the database maintenance job for the backups. Figure 22.47 shows the end results of this setup. Also, you can see that a log shipping Monitor branch has been added to the Maintenance branch for you to manage these tasks.
Figure 22.47. Log shipping agents.
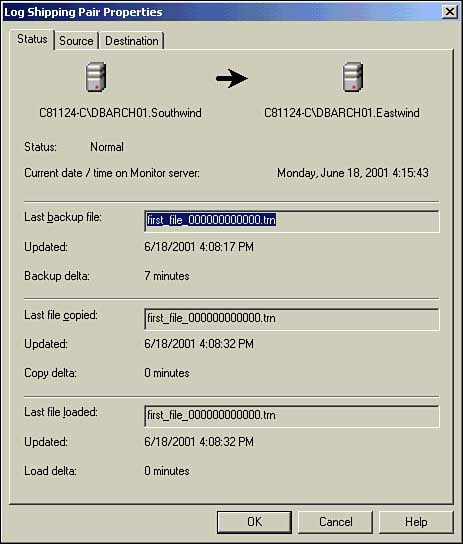
Finally, if you right-click on the log shipping task and choose Properties, you will be able to view and edit the properties of this source/destination log shipping pair.
Figure 22.48. Log shipping pair properties.