Other Query Processing Strategies
In addition to the optimization strategies covered so far, SQL Server also has some additional strategies it can apply for special types of queries. These strategies are employed to help further reduce the cost of executing various types of queries.
Predicate Transitivity
You might be familiar with the transitive property from algebra. The transitive property simply states that if A=B and B=C then A=C. SQL Server supports the transitive property in its query predicates. Predicate transitivity enables SQL Server to infer a join equality from two given equalities. Consider the following example:
SELECT * FROM table1 t1 join table2 t2 on t1.column1 = t2.column1 join table3 t3 on t2.column1 = t3.column1
Using the principle of predicate transitivity, SQL Server is able to infer that t1.column1 is also equal to t3.column1. This provides the optimizer with another join strategy to consider when optimizing this query. This might result in a much cheaper execution plan.
The transitive property can also be applied to SARGs used on join columns. Consider the following query:
select * from sales s join stores st on s.stor_id = st.stor_id and s.stor_id = 'B199'
Again, using transitive closure, we know that st.stor_id is also equal to 'B199'. SQL Server will also recognize this and be able to apply the constant against the indexes on both tables to more accurately estimate the number of matching rows from each table.
GROUP BY Optimization
Prior to SQL Server 7.0, GROUP BY was always processed in one way?SQL Server retrieved the data matching the SARGs into a worktable where the rows were sorted and the groups formed. In SQL Server 2000, the query optimizer might choose to use hashing to organize the data into groups and then compute the aggregates.
The hash aggregation strategy uses the same basic method for grouping and calculating aggregates as for a hash join. At the point where the probe input row is checked to determine whether it already exists in the hash bucket, the aggregate is computed if a hash match is found. The following pseudocode summarizes the hash aggregation strategy:
create a hash table
for each row in the input table
read the row
hash the key value
search the hash table for matches
if match found
aggregate the value into the old record
else
insert the hashed key into the hash bucket
scan and output the hash table contents
drop the hash table
For some join queries that contain a GROUP BY clause, SQL Server might perform the grouping operation before processing the join. This could reduce the size of the input table to the join and lower the overall cost of executing the query.
NOTEOne important point to keep in mind with both of these special strategies is that the rows might not come back in sorted order by the grouping column(s) as they did in earlier releases. If the results must be returned in a specific sort order, you will need to use the ORDER BY clause with the GROUP BY to ensure ordered results. You might want to get into the habit of doing this regularly. If the compatibility level for a database is set to 60 or 65, SQL Server will automatically include an ORDER BY in a GROUP BY query to order the results because they would be older SQL Server versions. |
Queries with DISTINCT
Similar to GROUP BY queries, in versions of SQL Server prior to 7.0, the resultset had to be generated first and then sorted in a worktable to remove duplicates. In SQL Server 2000, the optimizer can employ a hashing strategy similar to that used with GROUP BY to return only the distinct rows before the final resultset is determined.
Queries with UNION
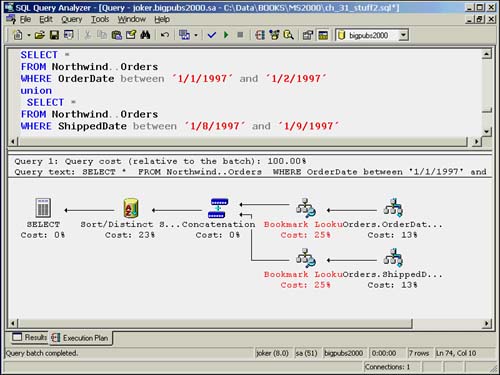
When you specify a UNION in a query, SQL Server merges the resultsets, applying one of the merge or concatenation strings with sorting strategies to remove any duplicate rows. Figure 35.16 shows an example very similar to the OR strategy where the rows are concatenated and then sorted to remove any duplicates.
Figure 35.16. Execution plan for a UNION.
If you specify UNION ALL in your query, SQL Server simply appends the resultsets together. No intermediate sorting or merge step is needed to remove duplicates. Figure 35.17 shows the same query as in Figure 35.16, except that a UNION ALL is specified.
Figure 35.17. Execution plan for a UNION ALL.
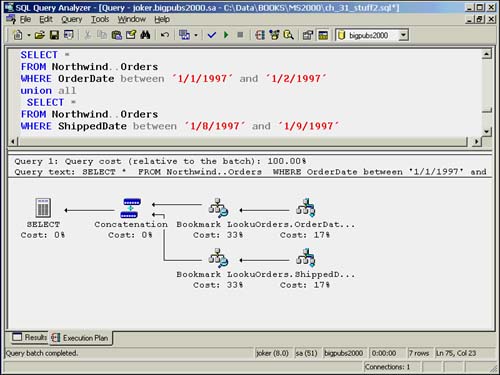
When you know that you do not need to worry about duplicate rows in a UNION resultset, always specify UNION ALL to eliminate the extra overhead required for sorting.







