The Publisher, Distributor, and Subscriber Metaphor
Any SQL Server can play up to three distinct roles in a data replication environment, as represented in Figure 22.3:
Being a publication server (the publisher of data)
Being a distribution server (the distributor of data)
Being a subscription server (the subscriber to the data being published)
Figure 22.3. The publisher, distributor and subscriber.
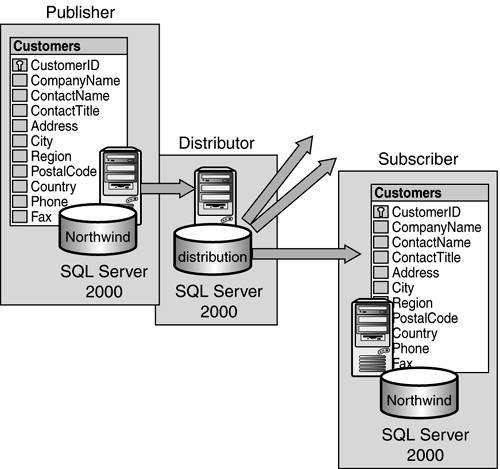
The publication server contains the database or databases that are going to be published. This is the source of the data that is to be replicated to other servers. In Figure 22.3, the Customers table in the Northwind database is the data to be published. To publish data, the database that contains the data that is going to be published must first be enabled for publishing. Full publishing configuration requirements will be discussed later in this chapter in the "Setting Up Replication" section.
The distribution server (distributor) can either be on the same server as the publication server or on a different server?in this case, a remote distribution server. This server will contain the distribution database. This database, also called the store-and-forward database, holds all the data changes that are to be forwarded from the published database to any subscription servers that subscribe to the data. A single distribution server can support several publication servers. The distribution server is truly the workhorse of data replication.
The subscription server contains a copy of the database or portions of the database that are being published, like the Customers table in the Northwind database. The distribution server sends any changes made to the published database via the subscription server's copy of the Customers table. This is known as store-and-forward. In previous versions of SQL Server, many data replication approaches would only send the data to the subscription server and then the data was treated as read-only. In SQL Server 7.0 and 2000, subscribers can make updates, which are returned to the publisher, known as the updating subscriber. It is important to note that an updating subscriber is not the same as a publisher. This chapter will cover more on updating subscribers in the "Publishing Subscriber" section.
Along with these distinct server roles, Microsoft utilizes a few more metaphors. These are publications and articles. A publication is a group of one or more articles, and is the basic unit of data replication. An article is simply a pointer to a single table, or a subset of rows or columns out of a table, that will be made available for replication.
Publications and Articles
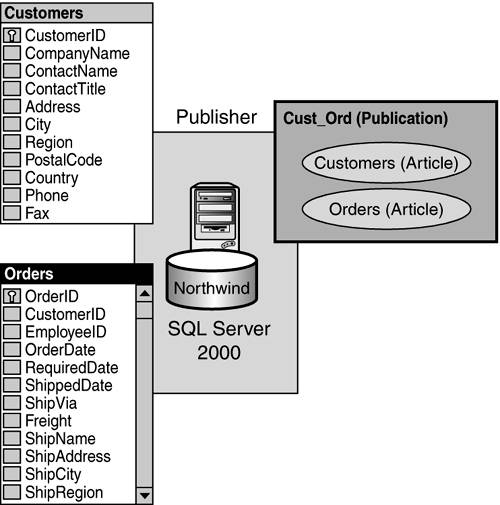
A single database can contain more than one publication. You can publish data from tables, database objects, the execution of stored procedures, and even schema objects, such as referential integrity constraints, clustered indexes, non-clustered indexes, user triggers, extended properties, and collation. Regardless of what you plan to replicate, all articles in a publication are synchronized at the same time. Figure 22.4 depicts a typical publication with two articles. You can choose to replicate whole tables, or just parts of tables via filtering.
Figure 22.4. Cust_Ord publication (Northwind DB).
Filtering Articles
You can create articles on SQL Server in several different ways. The basic way to create an article is to publish all of the columns and rows that are contained in a table. Although this is the easiest way to create articles, your business needs might require that you publish only certain columns or rows out of a table. This is referred to as filtering vertically or horizontally. Vertical filtering filters only specific columns, whereas horizontal filtering filters only specific rows. In addition, SQL Server 2000 provides the added functionality of join filters and dynamic filters.
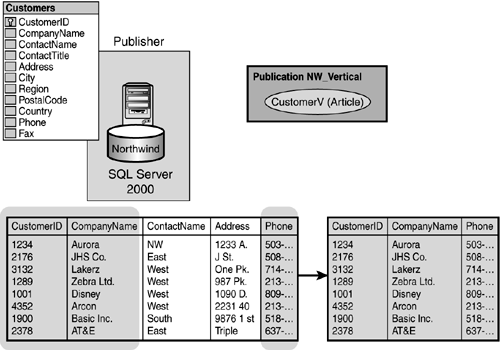
As an example, you might only need to replicate a customer's customer ID, company name, and phone number to various subscribing servers around your company. For this application, the Address data is restricted information and should not be replicated. You can create an article for data replication which contains a subset of the Customers table that will be replicated to these other locations (see Figure 22.5).
Figure 22.5. Vertical filtering is the process of creating a subset of columns from a table to be replicated to subscribers.
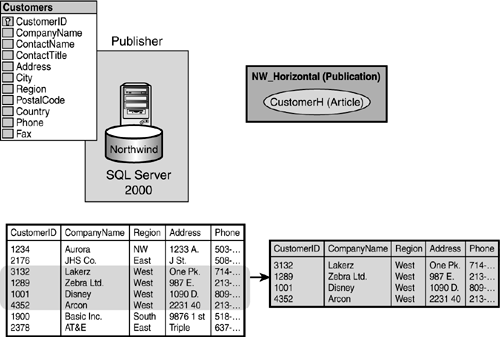
In another example, you might need to publish only the Customers table data that is in a specific region, requiring you to geographically partition the data. This process, as shown in Figure 22.6, is known as horizontal filtering.
Figure 22.6. Horizontal filtering is the process of creating a subset of rows from a table to be replicated to subscribers.
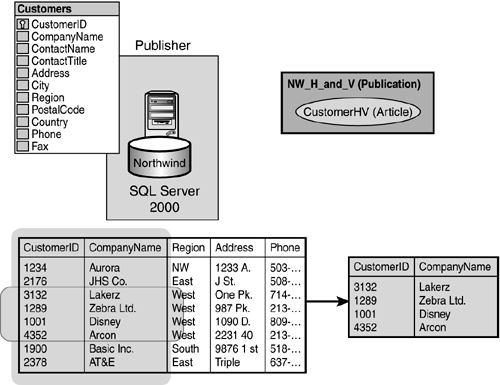
It is possible for you to combine both horizontal and vertical filtering, as shown in Figure 22.7. This allows you to pare out unneeded columns and rows that aren't required for replication. In our example, we might only need the "west" Region data and only require CustomerID and CompanyName data to be published.
Figure 22.7. Combining horizontal and vertical filtering allows you to pare down the information in an article to only the important information.
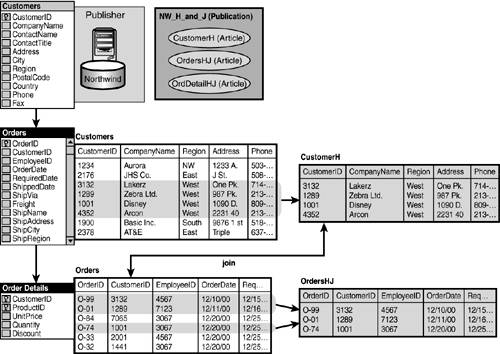
As mentioned earlier, it is now possible for you to have join filters. Join filters enable you to go one step further for a particular filter created on a table to another. In other words, if you are publishing the Customers table data based on the Region (west), you can extend filtering to the related Orders and Order Details tables for these west region customers, as shown in Figure 22.8. This way, you will only be replicating orders for customers in the west to a location that only needs to see west data in all related tables. This can be efficient if it is done well.
Figure 22.8. Horizontal and join publication.
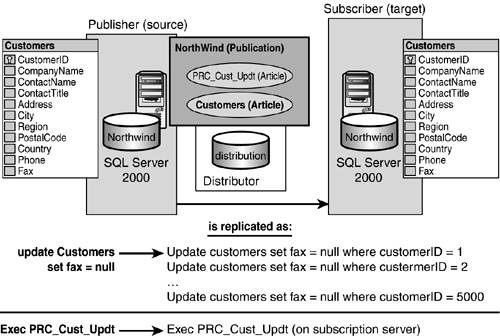
You also can publish "stored procedure executions" as articles, along with their parameters. This can be either a standard procedure execution article or a serializable procedure execution article. The difference is that the latter is executed as a serializable transaction, and the other is not. What this stored procedure execution approach buys you is the major reduction of mass SQL statements being replicated across your network.
For instance, if you wanted to update the Customers table for every customer, the resulting Customers table updates also would be replicated as a large multistep transaction involving 5,000 steps at minimum. This would significantly bog down your network. However, with stored procedure execution articles, only the execution of the stored procedure is replicated to the subscription server, and the stored procedure is executed on that subscription server. Figure 22.9 illustrates the difference in execution described earlier. Some subtleties when utilizing this type of data replication processing can't be overlooked, such as making sure that the published stored procedure behaves the same on the subscribing server side.
Figure 22.9. Stored procedure execution comparison.
Many more data replication terms will be presented in this chapter, but it is essential first to learn about the different types of replication scenarios that can be built, and the reasons why any one of these would be desired over the other. It also is worth noting that Microsoft SQL Server 2000 supports replication to and from many different "heterogeneous" data sources. In other words, OLE DB or ODBC data sources can subscribe to SQL Server publications, as well as receive data replicated from a number of data sources, including Microsoft Exchange, Microsoft Access, Oracle, and DB2.







