SQL Server Lock Types
Locking is handled automatically within SQL Server. The Lock Manager chooses the type of locks based on the type of transaction (such as select, insert, update, and delete). The various types of locks used by Lock Manager are as follows:
Shared
Update
Exclusive
Intent
Schema Locks
Bulk Update Locks
As in version 7.0, the Lock Manager in SQL Server 2000 automatically adjusts the granularity of the locks (row, page, table, and so on) based on the nature of the statement that is executed and the number of rows that are affected.
Shared Locks
SQL Server uses shared locks for all read operations. A shared lock is, by definition, not exclusive. Theoretically, an unlimited number of shared locks can be held on a resource at any given time. In addition, shared locks are unique in that, by default, a process locks the resource only for the duration of the read on that page. For example, a query such as select * from authors would lock the first page in the authors table when the query starts. After data on the first page is read, the lock on that page is released, and a lock on the second page is acquired. After the second page is read, its lock is released and a lock on the third page is acquired, and so on. In this fashion, a select query allows other data pages that are not being read to be modified during the read operation. This increases concurrent access to the data.
Shared locks are compatible with other shared locks as well as with update locks. In this way, a shared lock does not prevent the acquisition of additional shared locks or an update lock by other processes on a given page. Multiple shared locks can be held at any given time for a number of transactions or processes. These transactions do not affect the consistency of the data. However, shared locks do prevent the acquisition of exclusive locks. Any transaction that is attempting to modify data on a page or a row on which a shared lock is placed will be blocked until all the shared locks are released.
NOTEIt is important to point out that within a transaction running at the default isolation level of Read Committed, shared locks are not held for the duration of the transaction, or even the duration of the statement that acquires the shared locks. Shared lock resources (row, page, table, and so on) are normally released as soon as the read operation on the resource is completed. SQL Server provides the HOLDLOCK clause to the SELECT statement if you want to continue holding the shared lock for the duration of the transaction. HOLDLOCK is explained later in this chapter in the section "Table Hints for Locking." Another way to hold shared locks for the duration of the transaction is to set the isolation level for the session or the query to repeatable reads or higher. |
Update Locks
Update locks are used to lock pages that a user process would like to modify. When a transaction tries to update a row, it must first read the row to ensure that it is modifying the appropriate record. If the transaction were to put a shared lock on the resource initially, it would eventually need to get an exclusive lock on the resource to modify the record and prevent any other transaction from modifying the same record. The problem is that this could lead to deadlocks in an environment in which multiple transactions are trying to modify data on the same resource at the same time. Figure 38.7 demonstrates how deadlocks can occur if lock conversion takes place from shared locks to exclusive locks. When both processes attempt to escalate the shared lock they both hold on a resource to an exclusive lock, it results in a deadlock situation.
Figure 38.7. Deadlock scenario with shared and exclusive locks.
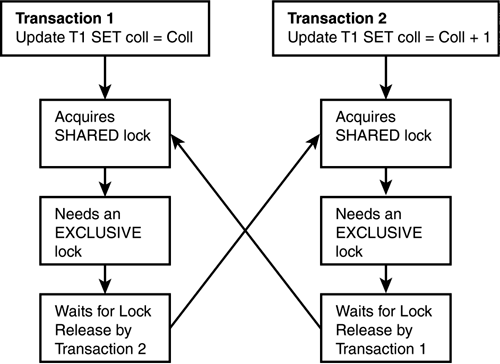
Update locks in SQL Server are provided to prevent this kind of deadlock scenario. Update locks are partially exclusive in that only one update lock can be acquired at a time on any resource. However, an update lock is compatible with shared locks, in that both can be acquired on the same resource simultaneously. In effect, an update lock signifies that a process wants to change a record, and keeps out other processes that also want to change that record. However, an update lock does allow other processes to acquire shared locks to read the data until the update or delete statement is finished locating the records to be affected. The process then attempts to escalate each update lock to an exclusive lock. At this time, the process will wait until all currently held shared locks on the same records are released. After the shared locks are released, the update lock is escalated to an exclusive lock. The data change is then carried out and the exclusive lock is held for the remainder of the transaction.
NOTEUpdate locks are not used just for update operations. SQL Server uses update locks any time that a search for the data is required prior to performing the actual modification, such as qualified updates and deletes (that is, when a where clause is specified). Update locks are also used for inserts into a table with a clustered index because SQL Server must first search the data and the clustered index to identify the correct position at which to insert the new row to maintain the sort order. After SQL Server has found the correct location and begins inserting the record, it escalates the update lock to an exclusive lock. |
Exclusive Locks
As mentioned earlier, an exclusive lock is granted to a transaction when it is ready to perform data modification. An exclusive lock on a resource makes sure that no other transaction can interfere with the data locked by the transaction that is holding the exclusive lock. SQL Server releases the exclusive lock at the end of the transaction.
Exclusive locks are incompatible with any other lock type. If an exclusive lock is held on a resource, any other read or data modification requests for the same resource by other processes will be forced to wait until the exclusive lock is released. Likewise, if a resource currently has read locks held on it by other processes, the exclusive lock request is forced to wait in a queue for the resource to become available.
Intent Locks
Intent locks are not really a locking mode, but a mechanism to indicate at a higher level of granularity the type of locks held at a lower level. The types of intent locks mirror the lock types previously discussed: shared intent locks, exclusive intent locks, and update intent locks. SQL Server Lock Manager uses intent locks as a mechanism to indicate that a shared, update, or exclusive lock is held at a lower level. For example, a shared intent lock on a table by a process signifies that the process currently holds a shared lock on a row or page within the table. The presence of the intent lock prevents other transactions from attempting to acquire a lock on the table.
Intent locks improve locking performance by allowing SQL Server to examine locks at the table level to determine the types of locks held on the table, rather than searching through the multiple locks at the page or row level within the table. Intent locks also prevent two transactions that are both holding locks at a lower level on a resource from attempting to escalate those locks to a higher level while the other transaction still holds the intent lock. This prevents deadlocks during lock escalation.
There are three types of intent locks that you will typically see when monitoring locking activity: intent shared (IS) locks, intent exclusive (IX) locks, and shared with intent exclusive (SIX) locks. The IS lock indicates that the process currently holds, or has the intention of holding, shared locks on lower-level resources (row or page). The IX lock indicates that the process currently holds, or has the intention of holding, exclusive locks on lower-level resources. The SIX (pronounced as the letters S-I-X, not like the number six) lock occurs under special circumstances when a transaction is holding a shared lock on a resource, and later in the transaction, an IX lock is needed. At that point, the IS lock is converted to an SIX lock.
In the following example, the SELECT statement run at the serializable level acquires a shared table lock. It then needs an exclusive lock to update the row in the sales_big table.
SET TRANSACTION ISOLATION LEVEL serializable
go
BEGIN TRAN
select sum(qty) FROM sales_big
UPDATE sales_big
SET qty = 0
WHERE sales_id = 1001
COMMIT TRAN
Because the transaction initially acquired a Shared (S) table lock and then needed an exclusive row lock, which requires an intent exclusive (IX) lock on the table within the same transaction, the S lock is converted to an SIX lock.
NOTEIf only a few rows were in sales_big, SQL Server might only acquire individual row or key locks rather than a table-level lock. SQL Server would then have an intent shared (IS) lock on the table rather than a full shared (S) lock. In that instance, the UPDATE statement would then acquire a single exclusive lock to apply the update to a single row, and the X lock at the key level would result in the IS locks at the page and table level being converted to an IX lock at the page and table level for the remainder of the transaction. |
Schema Locks
SQL Server uses schema locks to maintain structural integrity of SQL Server tables. Unlike other types of locks that provide isolation for the data, schema locks provide isolation for the schema of database objects, such as tables, views, and indexes within a transaction. The Lock Manager uses two types of schema locks:
Schema stability locks?When a transaction is referencing either an index or a data page, SQL Server places a schema stability lock on the object. This ensures that no other process can modify the schema of an object?such as dropping an index or dropping or altering a stored procedure or table?while other processes are still referencing the object.
Schema modification locks?When a process needs to modify the structure of an object (alter the table, recompile a stored procedure, and so on), the Lock Manager places a schema modification lock on the object. For the duration of this lock, no other transaction can reference the object until the changes are complete and committed.
Bulk Update Locks
Bulk Update locks are a special type of lock used only when bulk copying data into a table using the bcp utility or the BULK INSERT command. This special lock is used for these operations only when either the TABLOCK hint is specified to bcp or the BULK INSERT command, or when the table lock on bulk load table option has been set for the table. Bulk Update locks allow multiple bulk copy processes to bulk copy data into the same table in parallel, while preventing other processes that are not bulk copying data from accessing the table.
Lock Types and the syslockinfo Table
As stated before, the Lock Manager automatically manages the different types of locks that are placed on SQL Server objects. SQL Server keeps all this information in memory in its internal lock structures. To monitor the current locking activity in SQL Server 2000, you can view the contents of the internal lock structures via the syslockinfo system table. The syslockinfo table, which is defined in the master database, exists in memory only and is populated when queried. This table can be queried directly or via the sp_lock stored procedure to provide a snapshot of the locks currently held in SQL Server.
NOTEIn versions of SQL Server prior to SQL Server 7.0, lock information was contained in the syslocks system table. The syslockinfo table replaced the syslocks table. For backward compatibility with existing applications that might still reference the syslocks table, syslocks is provided in SQL Server 2000 as a view on the syslockinfo table. For future compatibility, all references to syslocks should be replaced with syslockinfo. |
Some of the more significant and useful columns in the syslockinfo table are described as follows:
rsc_dbid? This column contains the ID of the database that is associated with the object on which the lock is held.
rsc_objid? This is the ID of the table on which the lock is placed.
rsc_indid? This column contains the index ID of the resource on which the lock is held. This value is NULL if no locks are held on the index pages (or the rows of the index pages).
rsc_type? This column contains a numeric code that represents the type of resource being locked by a transaction. The possible values for this column are outlined in Table 38.1.
NOTEThe numeric code values in the rsc_type and the req_mode and req_status fields can be translated into more meaningful values by looking them up in the spt_values table. The following query shows an example of retrieving information from syslockinfo and translating the lock request type, lock request mode, and resource type code values into more meaningful names from spt_values.
|
| Column Value | Description | sp_lock Displayed Value (from spt_values) |
|---|---|---|
| 1 | No resources used | |
| 2 | Database | DB |
| 3 | File | FIL |
| 4 | Index | IDX |
| 5 | Table | TAB |
| 6 | Page | PAG |
| 7 | Key | KEY |
| 8 | Extent | EXT |
| 9 | Row ID | RID |
| 10 | Application | APP |
req_mode? This column contains a numeric code that represents the type of lock being requested by the transaction. The status of the request is kept in another column called req_status. Possible values for the req_mode column are shown in Table 38.2.
| Value | Lock Type | Description | sp_lock Displayed Value (from spt_values) |
|---|---|---|---|
| 1 | N/A | No access is provided to the requestor | NULL |
| 2 | Schema | Schema stability lock | Sch-S |
| 3 | Schema | Schema modification lock | Sch-M |
| 4 | Shared | Acquisition of a shared lock on the resource | S |
| 5 | Update | Acquisition of an update lock on the resource | U |
| 6 | Exclusive | Exclusive lock granted on the resource | X |
| 7 | Intent | Intent for a shared lock | IS |
| 8 | Intent | Intent for an update lock | IU |
| 9 | Intent | Intent for an exclusive lock | IX |
| 10 | Intent | Shared lock with intent for an update lock on subordinate resources | SIU |
| 11 | Intent | Shared lock with intent for an exclusive lock on subordinate resources | SIX |
| 12 | Intent | Update lock with intent for an exclusive lock on subordinate resources | UIX |
| 13 | Bulk | BULK UPDATE lock used for bulk copy operations | BU |
| 14 | Key-Range | Shared lock on the range between keys and shared lock on the key at the end of the range; used for serializable range scan | Range_S_S |
| 15 | Key-Range | Shared lock on the range between keys with update lock on the key at the end of the range | Range_S_U |
| 16 | Key-Range | Exclusive lock used to prevent inserts into a range between keys | RangeIn-Null |
| 17 | Key-Range | Key-Range conversion lock created by overlap of RangeIn-Null and shared (S) lock | RangeIn-S |
| 18 | Key-Range | Key-Range conversion lock created by overlap of RangeIn-Null and update (U) lock | RangeIn-U |
| 19 | Key-Range | Key-Range conversion lock created by overlap of RangeIn-Null and exclusive (X) lock | RangeIn-X |
| 20 | Key-Range | Key-Range conversion lock created by overlap of RangeIn-Null and RangeS_S lock | RangeX-S |
| 21 | Key-Range | Key-Range conversion lock created by overlap of RangeIn-Null and RangeS_U lock | RangeX-U |
| 22 | Key-Range | Exclusive lock on range between keys with an exclusive lock on the key at the end of the range | RangeX-X |
req_status? This column contains a numeric code that represents the status of a lock request. It can have the values as shown in Table 38.3.
| Value | Description | sp_lock Displayed Value (from spt_values) |
|---|---|---|
| 1 | Request for lock approved (granted) | GRANT |
| 2 | Request in the process of converting to approved (converting) | CNVT |
| 3 | Waiting to be approved (waiting) | WAIT |
req_spid? This column contains the SQL Server process ID of the session that is requesting the lock.
rsc_text? This column contains a textual description of the locked resource. For example, for a lock on a page, the rsc_text column contains the file number and page number of the locked page. Table 38.4 describes the contents of the rsc_text column depending on the type of lock.
| Lock Type | Description of rsc_text Value |
|---|---|
| Table | ObjectId. |
| Extent | FileNumber:PageNumber of first page in extent. |
| Page | FileNumber:PageNumber of data or index page. |
| Row | FileNumber:PageNumber:RowID. |
| Index Key | A hashed value derived from all the key components and the key locator. For example, for a nonclustered index on a heap table, the hash value would contain contributions from each of the key columns and the row ID. |
| Key-Range | Same as the index key. |
| Application | A hash value that is generated from the name given to the lock. |







