Step 2: Index Selection
When the query analysis phase of optimization is complete and all SARGs, OR clauses, and join clauses have been identified, the next step is to determine the selectivity of the expressions (estimated number of matching rows) and to determine the index cost to find the rows. The index costs are measured in terms of logical I/Os. If multiple indexes can be considered, the costs of each are compared with each other and also against the cost of a table scan to determine the least expensive access path.
Indexes are typically considered useful for an expression if the first column in the index is used in the expression and the search argument in the expression provides a means to limit the search. If no useful indexes are found for an expression, typically a table scan will be performed on the table. A table scan is the fall-back tactic for the optimizer to use if no better way exists of resolving a query.
Evaluating SARG and Join Selectivity
To determine selectivity of a SARG, the optimizer uses the index statistics stored for the index or column, if any. If no statistics are available for a column or index, by default, SQL Server will automatically create the statistics.
If no statistics are available for a column or index and the auto create statistics and auto update statistics options have been disabled for the database or table, SQL Server cannot make an informed estimate of the number of matching rows for a SARG and will have to resort to using some built-in percentages for the number of matching rows for various types of expressions. These percentages are as follows:
| Operator | Row Estimate |
|---|---|
| = | 10 percent |
| between, > and < | 10 percent (closed range search) |
| >, <, >=, <= | 30 percent (open range search) |
Using these percentages will almost certainly result in inappropriate query execution plans being chosen. Always try to ensure that you have up-to-date statistics available for any columns referenced in your SARGs and join clauses.
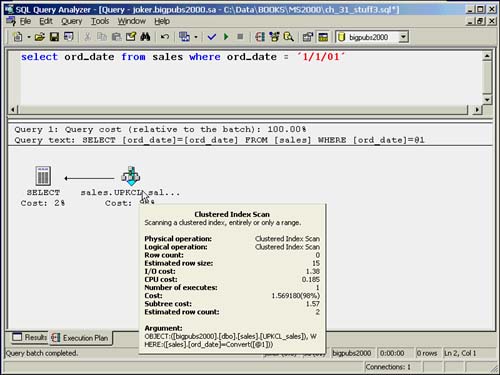
When the value of a SARG can be determined at the time of query optimization, the optimizer will use the index statistics histogram to estimate the number of matching rows for the SARG. The histogram contains a sampling of the data values in the column and stores information on the number of matching rows for the sampled values, as well as for values that fall between the sampled values. If the statistics are up-to-date, this is the most accurate estimate of the number of matching rows for a SARG.
If the SARG contains an expression that cannot be evaluated until runtime but is an equality expression (=), the optimizer will use the index density to estimate the number of matching rows. The index density reflects the overall uniqueness of the data values in the column or index. Index density is not as accurate as the histogram because its value is determined across the entire range of values in a column or index keys and can be skewed higher by one or more values that have a high number of duplicates. Expressions that cannot be evaluated until runtime include comparisons against functions, local variables, or other columns.
If the expression cannot be evaluated at the time of optimization, and the SARG is not an equality search but a closed or open range search, the index density cannot be used. The same percentages are used for the row estimates as for when no statistics are available.
As a special case, if a SARG contains the equality (=) operator and there's a unique index matching the SARG, by nature of a unique index, the optimizer knows that one and only one row will match the SARG without having to analyze the index statistics.
If the query contains a join clause, SQL Server determines whether any usable indexes exist that match the column(s) in the join clause. Because the optimizer has no way of determining what value(s) will join between rows in the table at optimization time, it can't use the statistics histogram to estimate the number of matching rows. Instead, it uses the index density as it does for SARGs that are unknown during optimization.
A lower density value indicates a more selective index. As the density approaches 1, the index becomes less selective. If a nonclustered index has a high density value, it will likely be more expensive in terms of I/O than a table scan and will not be used.
NOTEFor a more thorough discussion of index selection and index statistics, see Chapter 34. |
Estimating Index Cost
The second phase of index selection is identifying the total cost of various access paths to the data and determining which path results in the lowest cost to return the matching rows for an expression.
The primary cost of an access path, especially for single table queries, is the number of logical I/Os required to retrieve the data. Using the available statistics and the information stored in SQL Server regarding the number of rows per page and the number of pages in the table, the optimizer estimates the number of logical page reads necessary to retrieve the estimated number of rows using the candidate index. It then ranks the candidate indexes to determine which index requires the least amount of logical I/O.
NOTEA logical I/O occurs every time a page is accessed. If the page is not in cache, a physical I/O is first performed to bring the page into cache memory, and then a logical I/O is performed against the page. The optimizer has no way of knowing whether a page will be in memory when the query actually is executed and does not factor in the physical I/O cost. Physical I/Os are another performance factor that needs to be monitored by watching the overall cache-hit ratio for SQL Server. |
TIPThe rest of this section assumes a general understanding of SQL Server storage structures. If you haven't already, now is a good time to read through Chapter 33. |
Clustered Index Cost
Clustered indexes are efficient for lookups because the rows matching the SARGs are clustered on the same page or over a range of adjacent pages. SQL Server needs only to find its way to the first page and then read the rows from that page and any subsequent pages in the page chain until no more matching rows are found.
Therefore, the I/O cost estimate for a clustered index is calculated as follows:
the number of index levels in the clustered index
+ the number of pages to scan within the range of values
The number of pages to scan is based on the estimated number of matching rows divided by the number of rows per page.
For example, if SQL Server can store 250 rows per page for a table, and 600 rows are within the range of values being searched, SQL Server would estimate that it would require at least three page reads to find the qualifying rows. If the index is three levels deep, the logical I/O cost would be as follows:
3 (index levels to find the first row)
+ 3 (data pages?600 rows divided by 250 rows per page)
= 6 logical page I/Os
For a unique clustered index and an equality operator, the logical I/O cost estimate is one data page plus the number of index levels that need to be traversed to access the data page.
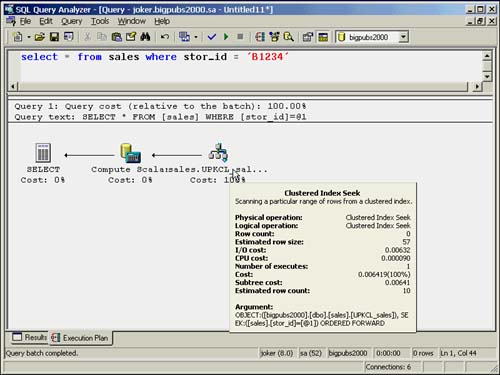
When a clustered index is used to retrieve the data rows, you will see a query plan similar to the one shown in Figure 35.1.
Figure 35.1. Execution plan for clustered index seek.
Nonclustered Index Cost
When searching for values using a nonclustered index, SQL Server reads the index key values at the leaf level of the index and uses the bookmark to locate and read the data row. SQL Server has no way of knowing if matching search values are going to be on the same data page until it has read the bookmark. It is possible that while retrieving the rows, SQL Server might find all data rows on different data pages, or it might revisit the same data page multiple times. Either way, a separate logical I/O is required each time it visits the data page.
With this in mind, the I/O cost is based on the depth of the index tree, the number of index leaf rows that need to be scanned to find the matching key values, and the number of matching rows. The cost of retrieving each matching row depends on whether the table is clustered or is a heap table. For a heap table, the nonclustered row bookmark is the page and row pointer to the actual data row. A single I/O is required to retrieve the data row. Therefore, the logical I/O cost for a heap table can be estimated as follows:
The number of nonclustered index levels
+ The number of leaf pages to be scanned
+ The number of qualifying rows (each row represents a separate data page read)
NOTEThis estimate assumes that the data rows have not been forwarded. In a heap table, when a row has been forwarded, the original row location contains a pointer to the new location of the data row; therefore, an additional page read is required to retrieve the actual data row. The actual I/O cost would be one page greater per row than the estimated I/O cost for any rows that have been forwarded. |
If the table is clustered, the row bookmark is the clustered key for the data row. The number of I/Os to retrieve the data row depends on the depth of the clustered index tree, as SQL Server has to use the clustered index to find each row. With this in mind, the logical I/O cost of finding a row using the nonclustered index on a clustered table is as follows:
The number of nonclustered index levels
+ The number of leaf pages to be scanned
+ The number of qualifying rows x the number of page reads to find a single row via the clustered index
As an example, consider a heap table with a nonclustered index on last name. Assume the index holds 800 rows per page (they're really big last names!), and 1,700 names are within the range we are looking for. If the index is 3 levels deep, the estimated logical I/O cost for the nonclustered index would be the following:
3 (index levels)
+ 3 (leaf pages?1,700 leaf rows/800 rows per page)
+ 1,700 (data page reads)
= 1,706 total logical I/Os
Now, assume that the table has a clustered index on it, and the size of the nonclustered index is the same. If the clustered index is 3 levels deep, including the data page, the estimated logical I/O cost of using the nonclustered index would be the following:
3 (nonclustered index levels)
+ 3 (leaf pages?1,700 leaf rows/800 rows per page)
+ 5,100 (1,700 rows x 3 clustered page reads per row)
= 5,106 total logical I/Os
NOTEAlthough the I/O cost is greater for bookmark lookups in a nonclustered index when a clustered index exists on the table, the cost savings during row inserts, updates, and deletes using the clustered index as the bookmark are substantial, whereas the couple extra logical I/Os per row during retrieval does not substantially impact query performance. |
For a unique nonclustered index using an equality operator, the I/O cost is estimated as the number of index levels traversed to access the bookmark plus the number of I/Os required to access the data page via the bookmark.
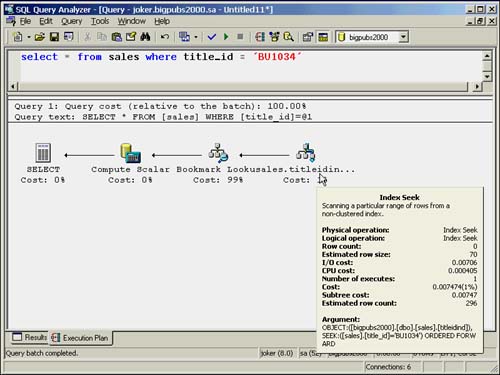
When a nonclustered index is used to retrieve the data rows, you will see a query plan similar to the one shown in Figure 35.2. Notice the additional bookmark lookup with a nonclustered index seek that was not present in the clustered index seek.
Figure 35.2. Execution plan for nonclustered index seek.
Covering Nonclustered Index Cost
When analyzing a query, the optimizer also considers any possibility to take advantage of index covering. Index covering is a method of using the leaf level of a nonclustered index to resolve a query when all the columns referenced in the query (in both the select list and WHERE clause, as well as any GROUP BY columns) are part of the index key.
This can save a significant amount of I/O because the query doesn't have to access the data page. In most cases, a nonclustered index that covers a query is faster than a similarly defined clustered index on the table.
If index covering can take place in a query, the optimizer considers it and estimates the I/O cost of using the nonclustered index to cover the query. The estimated I/O cost of index covering is as follows:
The number of index levels
+ The number of leaf index pages to scan
The number of leaf pages to scan is based on the estimated number of matching rows divided by the number of leaf index rows per page.
For example, if index covering could be used on the nonclustered index on last name for the query in the previous example, the I/O cost would be the following:
3 (nonclustered index levels)
+ 3 (leaf pages?1,700 leaf rows/800 rows per page)
= 6 total logical I/Os
TIPFor more information on index covering and when it can take place, see Chapter 34. |
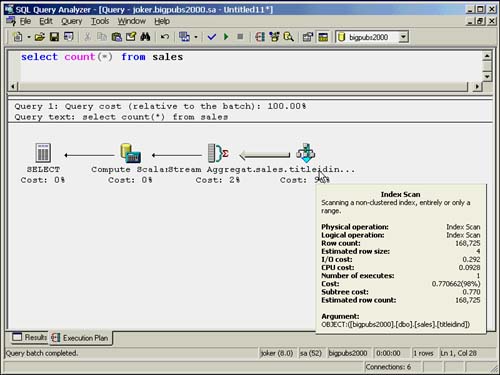
When an index covering is used to retrieve the data rows, you might see a query plan similar to the one shown in Figure 35.3. If the entire leaf level of the index is searched, it will display as an index scan, as shown in this example.
Figure 35.3. Execution plan for covered index scan without limits on the search.
Other times, if the index keys can be searched to limit the range, you might see an index seek used as shown in Figure 35.4. Note that the difference here from a normal index lookup is the lack of the bookmark lookup because SQL Server does not need to go to the data row to find the needed information.
Figure 35.4. Execution plan for covered index seek with limits on the search.
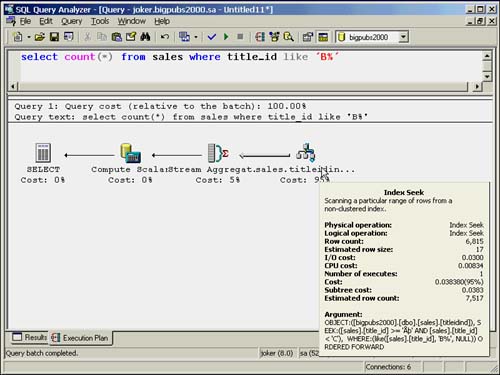
Table Scan Cost
If no usable index exists that can be matched with a SARG or a join clause, the optimizer's only option is to perform a table scan. The estimate of the total I/O cost is simply the number of pages in the table, which is stored in the dpages column in the sysindexes table.
Keep in mind that there are instances (for example, large range retrievals on a nonclustered index column) in which a table scan might be cheaper than a candidate index in terms of total logical I/O. For example, in the previous nonclustered index example, if the index does not cover the query, it would cost between 1,706 and 5,106 logical I/Os to retrieve the matching rows using the nonclustered index, depending on whether a clustered index exists on the table. If the total number of pages in the table is less than either of these values, then a table scan would be more efficient in terms of total logical I/Os than using a nonclustered index.
When a table scan is used to retrieve the data rows from a heap table, you will see a query plan similar to the one shown in Figure 35.5.
Figure 35.5. Table scan on a heap table.
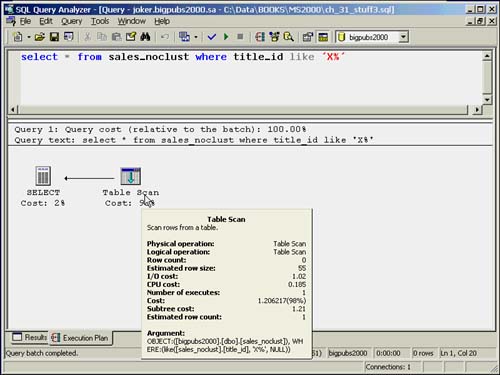
When a table scan is used to retrieve the data rows from a clustered table, you will see a query plan similar to the one shown in Figure 35.6. Notice that it displays as a clustered index scan because the table is the leaf level of the clustered index.
Figure 35.6. Table scan on a clustered table.
Using Multiple Indexes
You have always been able to create multiple indexes on a table in SQL Server. Prior to version 7.0, however, the query processor could exploit only one index per table per query. That restriction was eliminated in version 7.0, and the optimizer can now exploit multiple indexes in a couple of interesting ways.
Index Intersection
Index intersection is a mechanism that allows SQL Server to use multiple indexes on a table when you have two or more indexed SARGs in a query. Consider the following example:
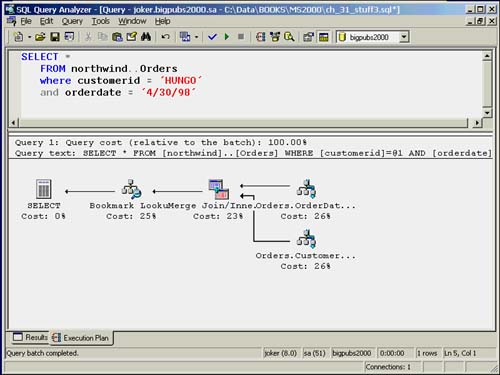
SELECT * FROM northwind..Orders where customerid = 'HUNGO' and orderdate = '4/30/98'
The Orders table contains two nonclustered indexes: one on the OrderDate column and one on the CustomerId column. In this case, the optimizer will consider the option of searching the index leaf rows of each index to find the rows that meet the search conditions and joining on the matching bookmarks for each resultset. It then uses the overlapping bookmarks to retrieve the actual data rows. This strategy will be applied only when the logical I/O cost of retrieving the bookmarks for both indexes and then retrieving the data rows is less than retrieving the qualifying data rows using only one of the indexes or using a table scan.
You can go through the same analysis as the optimizer to determine whether an index intersection makes sense. The Orders table has a clustered index on OrderId; therefore, OrderId is the bookmark used for the nonclustered indexes. Assume the following statistics:
19 rows are estimated to match where CustomerId = 'HUNGO'.
4 rows are estimated to match where OrderDate = '4/30/98'.
The optimizer estimates that the overlap between the two resultsets is 1 row.
The number of levels in the index on CustomerId = 2.
The number of levels in the index on OrderDate = 2.
The number of levels in the clustered index on OrderId = 1.
The Orders table is 21 pages in size.
Using this information, you can calculate the I/O cost for the different strategies the optimizer can consider.
A table scan would cost 21 pages.
A standard data row retrieval via the nonclustered index on CustomerID would cost
2 nonclustered index page reads (root and leaf)
+ 38 (19 rows x 2 pages per bookmark lookup via the clustered index)
= 40 pages
A standard data row retrieval via the nonclustered index on OrderDate would cost
2 nonclustered index page reads (root and leaf)
+ 8 (4 rows x 2 pages per bookmark lookup via clustered index)
= 10 pages
The index intersection is estimated to cost
2 pages (1 root page plus the 1 leaf page to find all the bookmarks for the 19 matching index rows on CustomerID)
+ 2 pages (1 root page plus the 1 leaf page to find all the bookmarks for the 4 matching index rows on OrderDate)
+ 2 page reads to find the 1 estimated overlap between the two indexes
= 6 pages
As you can see from these examples, the index intersection strategy is definitely the cheapest approach. If at any point the estimated intersection cost reached 10 pages, SQL Server would just use the single index on OrderDate and check both search criteria against the four matching rows for OrderId. If the estimated cost of using an index in any way ever reached 21 pages, a table scan would be performed and the criteria checked against all rows.
When an index intersection is used to retrieve the data rows from a table, you will see a query plan similar to the one shown in Figure 35.7.
Figure 35.7. Execution plan for index intersection.
OR Strategy
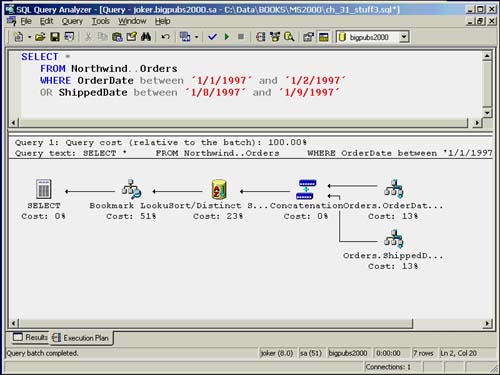
You will see a strategy similar to an index intersection applied when you have an OR condition between your SARGs, as shown in the following example:
SELECT * FROM Northwind..Orders WHERE OrderDate between '1/1/1997' and '1/2/1997' OR ShippedDate between '1/8/1997' and '1/9/1997'
The OR strategy is essentially the same as an index intersection with one slight difference. Using the OR strategy, SQL Server executes each part separately using the index that matches the SARG, but instead of merging the results, it has to concatenate the bookmarks in a worktable to sort the bookmarks and remove any duplicates. It then uses the unique bookmarks to retrieve the result rows from the base table.
When the OR strategy is used to retrieve the bookmarks from each of the indexes and concatenate them to build a list of bookmarks for retrieving the resulting data rows, you will see a query plan similar to the one shown in Figure 35.8. Notice the concatenation step, which differentiates it from a normal index intersection.
Figure 35.8. Execution plan for OR clause with concatenation of the bookmarks.
The following steps describe how SQL Server would handle the following query if useful indexes exist on both au_lname and state:
select * from authors
where au_lname = "Smith"
or state = "NY"
-
Estimate the cost of a table scan and the cost of using the OR strategy.
-
If the cost of the OR strategy exceeds the cost of a table scan, stop here and simply perform a table scan. Otherwise, continue with the succeeding steps to perform the OR strategy.
-
Break the query into multiple parts; for example:
select * from authors where au_lname = "Smith" select * from authros where state = "NY"
-
Match each part with an available index.
-
Execute each piece and get the row bookmarks into a worktable.
-
Sort the bookmarks and remove any duplicates.
-
Use the bookmarks to retrieve all qualifying rows from the base table.
If any one of the OR clauses needs to be resolved via a table scan for any reason, SQL Server will simply use a table scan to resolve the whole query rather than applying the OR strategy.
If the OR involves only a single column
where au_lname = 'Smith' or au_lname = 'Varney'
and an index exists on the column, the optimizer looks at the alternative of resolving it as a BETWEEN clause rather than using the OR strategy. Because the data in the index is sorted, the optimizer knows that all values satisfying the OR clause in the index are "between" the two values. Therefore, it could find the first matching row for the OR clause and simply scan the succeeding leaf pages of the index until the last matching row is found. Consider the following example:
select title_id from titles
where title_id in ("BU1032", "BU1111", "BU2075", "BU7832")
The OR clause could be translated into the following:
where title_id = 'BU1032' or title_id = 'BU1111' or title_id = 'BU2075' or title_id = 'BU7832'
To process this using the standard OR strategy would involve using four separate lookups on the titles table to get the matching row bookmarks into a worktable. As an alternative, SQL Server might internally translate the OR clause into a range retrieval similar to the following:
where title_id between "BU1032" and "BU7832"
and (title title_id = 'BU1032'
or title_id = 'BU1111'
or title_id = 'BU2075'
or title_id = 'BU7832')
The optimizer now has the option of using the index to perform a range retrieval and scan all rows in the range, applying the search criteria to each row in a single pass to find all the matching result rows, ignoring any nonmatching rows in the range. Figure 35.9 shows an example of this approach being applied for an OR condition.
Figure 35.9. Execution plan using index seek to retrieve rows for an OR condition on a single column.
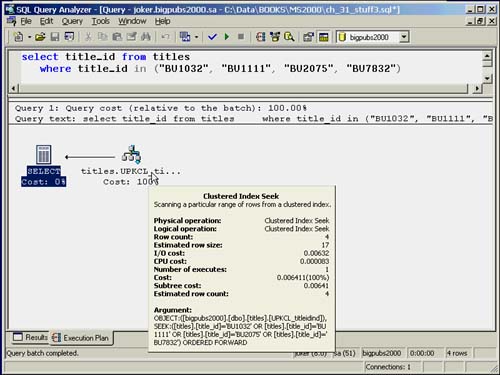
Index Joins
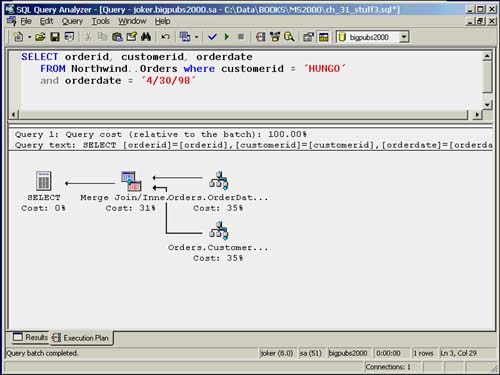
Another way of using multiple indexes on a single table is to join two or more indexes to create a covering index. This is similar to an index intersection, except that the final bookmark lookup is not required because the merged index rows contain all the necessary information. Consider the following example:
SELECT orderid, customerid, orderdate FROM Northwind..Orders where customerid = 'HUNGO' and orderdate = '4/30/98'
Again, the Orders table contains indexes on both the CustomerID and OrderDate columns. Each of these indexes contains the clustered key on OrderID as a bookmark. In this instance, when the optimizer merges the two indexes using a merge join, joining them on the matching OrderIDs, the index rows in the merge set have all the information we need because OrderID is part of the nonclustered indexes. There is no need to perform a bookmark lookup on the data page. By joining the two index resultsets, SQL Server created the same effect as having one covering index on CustomerId, OrderDate, and OrderID on the table. Using the same numbers as in the Index Intersection section presented earlier, the cost of the index join would be as follows:
2 pages (1 root page plus the 1 leaf page to find all the CustomerIDs and OrderIDs for the 19 matching index rows on CustomerID)
+ 2 pages (1 root page plus the 1 leaf page to find all the OrderDates and OrderIDs for the 4 matching index rows on OrderDate)
= 4 total page reads
Figure 35.10 shows an example of the execution plan for an index join. Notice that it does not include the bookmark lookup present in the index intersection execution plan, as shown earlier in Figure 35.7.
Figure 35.10. Execution plan for index join.
Optimizing with Indexed Views
A new feature in SQL Server 2000 is indexed views. When you create a unique clustered index on a view, the resultset for the view is materialized and stored in the database with the same structure as a table that has a clustered index. Changes made to the data in the underlying tables of the view will be automatically reflected in a view the same way as changes to a table are reflected in its indexes. In the Developer and Enterprise editions of SQL Server 2000, the query optimizer will automatically consider using the index on the view to speed up access for queries run directly against the view. The query optimizer in the Developer and Enterprise editions of SQL Server 2000 will also look at and consider using the indexed view for searches against the underlying base table when appropriate.
NOTEWhile indexed views can be created in any edition of SQL Server 2000, they will only be considered for query optimization in the Developer and Enterprise editions of SQL Server 2000. In other editions of SQL Server 2000, indexed views will not be used to optimize the query unless the view is explicitly referenced in the query and the NOEXPAND optimizer hint is specified. For example, to force the optimizer to consider using the sales_Qty_Rollup indexed view in the Standard Edition of SQL Server 2000, execute the query as follows:
select * from sales_Qty_Rollup WITH (NOEXPAND)
where stor_id between 'B914' and 'B999'SET ARITHABORT ON
The NOEXPAND hint is only allowed in SELECT statements and the indexed view must be referenced directly in the query (only the Developer and Enterprise editions will consider using an indexed view that is not directly referenced in the query). As always, use optimizer hints with care. Once the NOEXPAND hint is included in the query, the optimizer will not be able to consider any other alternatives for optimizing the query. |
Consider the following example that creates an indexed view on the sales table containing the stor_id and sum(qty) grouped by stor_id:
set quoted_identifier on
go
create view sales_qty_rollup
with schemabinding
as
select stor_id, sum(qty) as total_qty, count_big(*) as id
from dbo.sales
group by stor_id
go
create unique clustered index idx1 on sales_Qty_Rollup (stor_id)
go
The creation of the clustered index on the view essentially creates a clustered table in the database with the three columns stor_id, total_qty, and id. As you would expect, the following query on the view itself will use the clustered index on the view to retrieve the result rows from the view instead of having to scan or search the sales table itself:
select * from sales_Qty_Rollup where stor_id between 'B914' and 'B999'
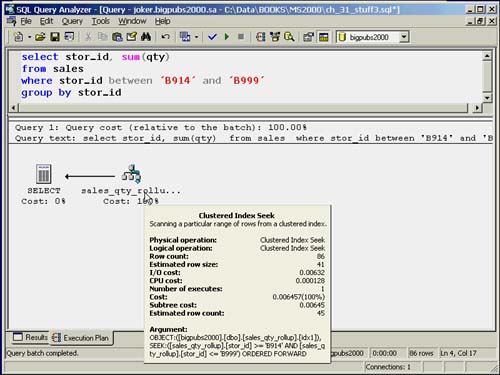
However, the following query on the sales table itself ends up using the indexed view, sales_qty_rollup, to retrieve the result set as well.
select stor_id, sum(qty) from sales where stor_id between 'B914' and 'B999' group by stor_id
Essentially, the optimizer recognizes the indexed view as an index on the sales table that covers the query. The execution plan shown in Figure 35.11 shows the indexed view being searched in place of the table.
Figure 35.11. Execution plan showing indexed view being searched to satisfy query on base table.
NOTEIn addition to the seven required SET options being set accordingly when the indexed view is created, they must also be set the same way for a session to be able to use the indexed view in queries. The required SET option settings are as follows: SET ARITHABORT ON SET CONCAT_NULL_YIELDS_NULL ON SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON SET ANSI_PADDING ON SET ANSI_WARNINGS ON SET NUMERIC_ROUNDABORT OFF If these SET options are not enabled for the session running a query that could make use of an indexed view, the indexed view will not be used and the table itself is searched instead. For more information on indexed views, see Chapter 27. |
On rare occasions, you might find situations where using the indexed view in the Enterprise or Developer editions of SQL Server 2000 leads to poor query performance, and you might want to avoid having the optimizer use the indexed view. To force the optimizer to ignore the indexed view(s) and optimize the query using the indexes on the underlying base tables, specify the EXPAND VIEWS query option as follows:
select * from sales_Qty_Rollup where stor_id between 'B914' and 'B999' OPTION (EXPAND VIEWS)







