Database Pages
All information in SQL Server is stored at the page level. The page is the smallest level of I/O in SQL Server and is the fundamental storage unit. Pages contain the data itself or information about the physical layout of the data. The page size is the same for all page types: 8KB or 8192 bytes (before version 7.0, the page size was 2KB). The pages are arranged in two basic types of storage structures: linked data pages and index trees.
Page Types
There are eight page types in SQL Server, as listed in Table 33.4.
| Page Type | Stores |
|---|---|
| Data | The actual rows, found in the tables |
| Index | Index entries and pointers |
| Text and Image | Textual and image data |
| Global Allocation Map | Information about allocated (used) extents |
| Page Free Space | Information about free space on pages |
| Index Allocation Map | Information about extents used by a table or an index |
| Bulk Changed Map | Information about which extents have been used in a minimally logged or bulk-logged operation |
| Differential Changed Map | Information about which extents have been modified since the last full database backup |
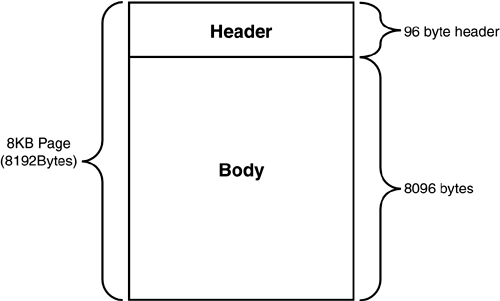
All pages, regardless of type, have a similar layout. They all have a page header, which is 96 bytes, and a body, which consequently is 8096 bytes. The page layout is shown in Figure 33.3.
Figure 33.3. SQL Server page layout.
Examining Page Content
The information stored in the page header and in the page body depends on the page type. You can examine the raw contents of a page by using the DBCC PAGE command. You must be logged in with sysadmin privileges to run the DBCC PAGE command. The syntax for the DBCC PAGE command is as follows:
DBCC PAGE (dbid | 'dbname', file_no, page_no [, print_option])
The parameters of the DBCC PAGE command are as follows:
dbid or dbname? ID or name of the database containing the page to be examined.
file_no? The number of the file in which the page resides. Typically, for a data page, this will be 1, unless the database is created on multiple files. When a command or tool displays a page number?for example, sp_lock?it usually displays the page number in the format of filenumber:pagenumber (for example, 1:165). The number to the left of the colon is the file number, the number to the right is the page number.
page_no? The number of the page within the file. Page numbers are unique within a file.
print_option? Optional parameter to specify how you want the page information displayed.
The valid values for the print_option are as follows:
0? The default option. Displays only the buffer header and page header.
1? Displays the buffer header, page header, a hex dump of the contents of the page with each row listed separately, and the contents of the row offset table.
2? Displays the buffer and page headers, a hex dump of the page as single block of data, and the contents of the row offset table.
3? Displays the buffer header, page header, and a hex dump of each row separately. Each row is followed by a printout of each of the column values in the row.
You must first run DBCC TRACEON (3604) if you want to get the results from DBCC PAGE returned to an application; otherwise, the output will be sent to the SQL Server error log. Listing 33.3 shows an example of using DBCC PAGE.
Listing 33.3 Sample Execution of DBCC PAGE
dbcc traceon(3604) dbcc page (pubs, 1, 91, 3) go PAGE: (1:91) ------------ BUFFER: ------- BUF @0x18F23680 --------------- bpage = 0x1C4F4000 bhash = 0x00000000 bpageno = (1:91) bdbid = 5 breferences = 1 bstat = 0x209 bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x1C4F4000 ---------------- m_pageId = (1:91) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000 m_objId = 2057058364 m_indexId = 0 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 10 m_slotCnt = 8 m_freeCnt = 7699 m_freeData = 477 m_reservedCnt = 0 m_lsn = (3:254:2) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 1 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED Slot 0 Offset 0x60 ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F4060: 000a0030 36333730 0005414d 23000300 0...0736MA.....# 1C4F4070: 2c002900 77654e00 6f6f4d20 6f42206e .).,.New Moon Bo 1C4F4080: 42736b6f 6f74736f 4153556e oksBostonUSA pub_id = 0736 pub_name = New Moon Books city = Boston state = MA country = USA Slot 1 Offset 0x8c ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F408C: 000a0030 37373830 00054344 25000300 0...0877DC.....% 1C4F409C: 32002f00 6e694200 2074656e 61482026 ./.2.Binnet & Ha 1C4F40AC: 656c6472 73615779 676e6968 556e6f74 rdleyWashingtonU 1C4F40BC: 4153 SA pub_id = 0877 pub_name = Binnet & Hardley city = Washington state = DC country = USA Slot 2 Offset 0xbe ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F40BE: 000a0030 39383331 00054143 29000300 0...1389CA.....) 1C4F40CE: 34003100 676c4100 7461646f 6e492061 .1.4.Algodata In 1C4F40DE: 79736f66 6d657473 72654273 656c656b fosystemsBerkele 1C4F40EE: 41535579 yUSA pub_id = 1389 pub_name = Algodata Infosystems city = Berkeley state = CA country = USA Slot 3 Offset 0x120 ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F4120: 000a0030 32323631 00054c49 2a000300 0...1622IL.....* 1C4F4130: 34003100 76694600 614c2065 2073656b .1.4.Five Lakes 1C4F4140: 6c627550 69687369 6843676e 67616369 PublishingChicag 1C4F4150: 4153556f oUSA pub_id = 1622 pub_name = Five Lakes Publishing city = Chicago state = IL country = USA Slot 4 Offset 0x154 ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F4154: 000a0030 36353731 00055854 26000300 0...1756TX.....& 1C4F4164: 2f002c00 6d615200 20616e6f 6c627550 .,./.Ramona Publ 1C4F4174: 65687369 61447372 73616c6c 415355 ishersDallasUSA pub_id = 1756 pub_name = Ramona Publishers city = Dallas state = TX country = USA Slot 5 Offset 0x183 ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F4183: 000a0030 31303939 00050000 1a000308 0...9901........ 1C4F4193: 28002100 47474700 fc4d4726 6568636e .!.(.GGG&GM.nche 1C4F41A3: 7265476e 796e616d nGermany pub_id = 9901 pub_name = GGG&G city = München state = [NULL] country = Germany Slot 6 Offset 0xf2 ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F40F2: 000a0030 32353939 0005594e 23000300 0...9952NY.....# 1C4F4102: 2e002b00 6f635300 656e746f 6f422079 .+...Scootney Bo 1C4F4112: 4e736b6f 59207765 556b726f 4153 oksNew YorkUSA pub_id = 9952 pub_name = Scootney Books city = New York state = NY country = USA Slot 7 Offset 0x1ab ------------------- Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1C4F41AB: 000a0030 39393939 00050000 27000308 0...9999.......' 1C4F41BB: 32002c00 63754c00 656e7265 62755020 .,.2.Lucerne Pub 1C4F41CB: 6873696c 50676e69 73697261 6e617246 lishingParisFran 1C4F41DB: 6563 ce pub_id = 9999 pub_name = Lucerne Publishing city = Paris state = [NULL] country = France DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Data Pages
The actual data rows in tables are stored on data pages. Figure 33.4 shows the basic structure of a data page.
Figure 33.4. The structure of a SQL Server data page.
The remainder of this section discusses and examines the contents of the data page.
The Page Header
The page header contains control information for the page. Some fields assist when SQL Server checks for consistency among its storage structures, and some fields are used when navigating among the pages that constitute a table. Table 33.5 describes the more useful fields contained in the page header and the corresponding value in the header output of DBCC PAGE.
| Page Header Fields | DBCC PAGE Name | Description |
|---|---|---|
| Page ID | m_pageId | Unique identifier for the page. It consists of two parts: the file ID number and the page number. |
| Next Page in Chain | m_nextPage | Contains the file number and page number of the next page in the chain (0 if the page is the last or only page in the chain or if the page belongs to a heap table). |
| Previous Page in Chain | m_prevPage | Contains the file number and page number of the previous page in the chain (0 if the page is the first or only page in the chain, or if the page belongs to a heap table). |
| Object ID | m_objID | ID of the object to which this page belongs. |
| Log Sequence Number | m_lsn | Log sequence number (LSN) value used for changes and updates to this page. |
| Number of Rows | m_slotCnt | Total number of rows (slots) used on the page. |
| Index Level | m_level | The level at which this page resided in an index tree (0 indicates a leaf page or data page). |
| Index ID | m_indexId | ID of the index this page belongs to. 0 indicates that it is a data page. 1 means that the page is a data page for a clustered table. A value greater than 1 is the ID of a nonclustered index; the value 255 indicates a text or image page. |
| Free Space Location | m_freeData | The byte offset where the available free space starts on the page. |
| Minimum Row Length | pminlen | The minimum size of the row. Essentially, this is the number of bytes in the fixed-length portion of the data rows. |
| Amount of Free Space | m_freeCnt | Number of free bytes available on the page. |
The Data Rows
Following the page header, starting at byte 96 on the page, are the actual data rows. Each data row has a unique row number within the page. Data rows in SQL Server cannot cross page boundaries. The maximum available space in a SQL Server page is 8096 bytes (8192 bytes minus the 96 byte header). However, this does not mean that your data rows can be 8096 bytes in size.
When a data row is logged in the transaction log (for an insert, for example), additional logging information is stored on the log page along with the data row. Because log pages are 8192 bytes in size and also have a 96 byte header, a log page has only 8096 bytes of available space. To store the data row and the logging information on a single log page, the data row cannot be more than 8060 bytes in size. This, in effect, limits the maximum data row size for a table in SQL Server 2000 to 8060 bytes as well.
Because each data row also incurs some overhead bytes in addition to the actual data, the maximum amount of actual data that can be stored in a single row on a page is slightly less than 8060 bytes. The actual amount of overhead required per row is dependent on whether the table contains any variable length columns. The limit on data row size does not take into account columns of text, ntext, or image datatypes because these data values are stored separately from the data row, as you'll see later in this chapter.
If you attempt to create a table with a minimum row size that exceeds 8060 bytes, you'll receive an error message as in the following example (remember that a multibyte character set datatype such as nchar or nvarchar requires 2 bytes per character, so an nchar(4000) column requires 8000 bytes):
CREATE TABLE customer_info (cust_no INT, cust_address NCHAR(200), info NCHAR(4000)) go Server: Msg 1701, Level 16, State 2, Line 1 Creation of table 'customer_info' failed because the row size would be 8425, including internal overhead. This exceeds the maximum allowable table row size, 8060.
If the table contains variable length or nullable columns, you can create a table for which the minimum row size is less than 8060 bytes, but the data rows could conceivably exceed 8060 bytes. SQL Server allows the table to be created, but whenever you create or alter such a table, you'll receive the warning message as shown in the following example:
CREATE TABLE customer_info (cust_no INT, cust_address NCHAR(200), info NVARCHAR(4000)) Warning: The table 'customer_info' has been created but its maximum row size (8429) exceeds the maximum number of bytes per row (8060). INSERT or UPDATE of a row in this table will fail if the resulting row length exceeds 8060 bytes.
If you then try to insert a row that exceeds 8060 bytes of data and overhead, the insert fails with the following error message:
Server: Msg 511, Level 16, State 1, Line 1 Cannot create a row of size 8405 which is greater than the allowable maximum of 8060. The statement has been aborted.
The number of rows stored on a page depends on the size of each row. For a table that has all fixed length, non-nullable columns, the number of rows that can be stored on a page will always be the same. If the table has any variable or nullable fields, the number of rows stored on page depends on the size of each row. SQL Server attempts to fit as many rows as possible in a page. Smaller row sizes allow SQL Server to fit more rows on a page, which reduces page I/O and allows more data pages to fit in memory. This helps improve system performance by reducing the number of times SQL Server has to read data in from disk.
The Structure of Data Rows
The data for all fixed-length data fields in a table are stored at the beginning of the row. All variable-length data columns are stored after the fixed-length data. Figure 33.5 shows the structure of the data row in SQL Server.
Figure 33.5. The structure of a SQL Server data row.
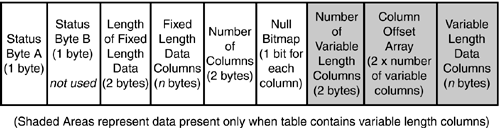
The total size of each data row is a factor of the sum of the size of the columns plus the row overhead. Seven bytes of overhead is the minimum for any data row:
1 byte for status byte A.
1 byte for status byte B (in SQL Server 2000, no information is stored in status byte B).
2 bytes to store the length of the fixed-length columns.
2 bytes to store the number of columns in the row.
1 byte for every multiple of 8 columns (ceiling(numcols / 8))in the table for the NULL bitmap. A 1 in the bitmap indicates that the column allows nulls.
The values stored in status byte A are as follows:
Bit 1?Provides version information. In SQL Server 2000, it's always 0.
Bits 2 through 4?A 3-bit value that indicates the nature of the row. 0 indicates that the row is a primary record, 1 indicates that the row has been forwarded, 2 indicates a forwarded stub, 3 indicates an index record, 4 indicates a blob fragment, 5 indicates a ghost index record, and 6 indicates a ghost data record. (Many of these topics, such as forwarded and ghost records, will be discussed in further detail in the "Data Modification and Performance" section later in this chapter.)
Bit 5?Indicates that a NULL bitmap exists. This is somewhat unnecessary in SQL Server 2000 because a NULL bitmap is always present, even if no NULLs are allowed in the table.
Bit 6?Indicates that one or more variable-length columns exists in the row.
Bits 7 and 8?These bits are not currently used in SQL Server 2000.
If the table contains any variable length columns, the following additional overhead bytes are included in each data row:
2 bytes to store the number of variable-length columns in the row.
2 bytes times the number of variable-length columns for the offset array. This is essentially a table in the row identifying where each variable-length column can be found within the variable-length column block.
Within each block of fixed-length or variable-length data, the data columns are stored in the column order in which they were defined when the table was created. In other words, all fixed-length fields are stored in column ID order in the fixed-length block, and all nullable or variable-length fields are stored in column ID order in the variable length block.
You can confirm the preceding information using DBCC PAGE. First, create a table with all fixed-length rows and add a couple of rows to it (if you use all character columns, you'll be able to read the information in DBCC PAGE more easily):
use pubs
go
create table withnull (a char(5) default 'aaaaa',
b char(5) null default 'bbbbb',
c char(5) default 'ccccc')
go
insert withnull default values
insert withnull values ('abcde', null, 'vwxyz')
go
Next, to examine the data page, you need to identify which page it is. Because this is a small table, all data is stored on the first page. You can find out the address of the first page by querying the first column in the sysindexes table for the table where the index ID is 0 or 1 (the contents of sysindexes will be explained in more detail throughout this chapter):
select id, indid, first, root from sysindexes
where id = object_id('withnull')
and indid <= 1
go
id indid first root
----------- ------ -------------- --------------
2009058193 0 0x4F0000000100 0x4F0000000100
CAUTIONIt is not guaranteed that the first column in sysindexes will always indicate the first page of a table. In general, it will be a reliable value until you begin to perform deletes and updates on the data in the table. |
The values in the root and first columns represent page numbers within the database. Unfortunately, each is stored in a byte-swapped format as hexadecimal numbers, and DBCC PAGE needs the decimal page and file numbers. To convert the file number and page number to decimal values, you must first swap the bytes and then convert the values from hexadecimal to decimal. The last four digits (the 5th and 6th bytes) represent the file number: 0100. If you reverse the 2 bytes (01 and 00), you end up with 0001 to represent the file number. That one is pretty easy to convert to decimal because it's usually a 1 unless the database is on multiple files.
The page number is a little trickier to decipher. You have to reverse the first 4 bytes (the first eight digits) in groups of two. For example, 0x4F000000 becomes 00 00 00 4F. The page number is then 4F. Unless you are an assembly programmer, you'll probably need to use the Windows Calculator to convert the hex value to a decimal. A better approach would be to let T-SQL do the conversion for you when you retrieve the data from sysindexes. Listing 33.4 provides a stored procedure that contains an example of a query that will do the trick. (You can find the source for this stored procedure on the accompanying CD.)
Listing 33.4 Stored Procedure to Display Hexadecimal Page Numbers from sysindexes As Decimal
use master
go
create proc dbo.sp_SSU_showindexpages @table sysname = null, @indid int = null
as
if @table is not null and object_id(@table) is null
begin
print 'Invalid table name: ''' + @table + ''''
return
end
if @indid is not null
and not exists (select 1 from sysindexes where id = object_id(@table)
and indid = @indid)
begin
print 'No index with id of ' + cast (@indid as varchar(3))
+ ' exists on table ''' + @table + ''''
return
end
select convert(char(30), object_name(id)) 'tablename',
id,
indid,
convert(char(30),name) 'indexname',
convert(varchar(2), (convert(int, substring(root, 6, 1)) * power(2, 8))
+ (convert(int, substring(root, 5, 1))))
+ ':'
+ convert(varchar(11),
(convert(int, substring(root, 4, 1)) * power(2, 24)) +
(convert(int, substring(root, 3, 1)) * power(2, 16)) +
(convert(int, substring(root, 2, 1)) * power(2, 8)) +
(convert(int, substring(root, 1, 1)))) as 'root',
convert(varchar(2), (convert(int, substring(first, 6, 1)) * power(2, 8))
+ (convert(int, substring(first, 5, 1))))
+ ':'
+ convert(varchar(11),
(convert(int, substring(first, 4, 1)) * power(2, 24)) +
(convert(int, substring(first, 3, 1)) * power(2, 16)) +
(convert(int, substring(first, 2, 1)) * power(2, 8)) +
(convert(int, substring(first, 1, 1)))) as 'first',
convert(varchar(2), (convert(int, substring(firstiam, 6, 1)) * power(2, 8))
+ (convert(int, substring(firstiam, 5, 1))))
+ ':'
+ convert(varchar(11),
(convert(int, substring(firstiam, 4, 1)) * power(2, 24)) +
(convert(int, substring(firstiam, 3, 1)) * power(2, 16)) +
(convert(int, substring(firstiam, 2, 1)) * power(2, 8)) +
(convert(int, substring(firstiam, 1, 1)))) as 'firstiam'
from sysindexes
where 1 = case when @table is null then 1
when id = object_id(@table) then 1
end
and 1 = case when @indid is null then 1
when @indid = 0 and indid <= 1 then 1
when @indid = 1 and indid = 1 then 1
when @indid > 1 and indid = @indid then 1
end
and isnull(indexproperty(id, name, 'IsAutoStatistics'), 0) = 0
order by 1, 3
return
go
use pubs
go
exec sp_SSU_showindexpages withnull
go
tablename id indid indexname root first firstiam
-------------- ----------- ------ ------------ ------- -------- --------
withnull 1061578820 0 withnull 1:79 1:79 1:80
Okay, so now you know that the first page number is 79 for this example. You can now use DBCC PAGE to look at the page contents:
dbcc page (pubs, 1, 79, 3) go PAGE: (1:79) ------------ BUFFER: ------- BUF @0x18EC48C0 --------------- bpage = 0x19586000 bhash = 0x00000000 bpageno = (1:79) bdbid = 14 breferences = 4 bstat = 0xb bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x19586000 ---------------- m_pageId = (1:79) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000 m_objId = 2009058193 m_indexId = 0 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 19 m_slotCnt = 2 m_freeCnt = 8048 m_freeData = 140 m_reservedCnt = 0 m_lsn = (43:62:2) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 0 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED Slot 0 Offset 0x60 ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 19586060: 00130010 61616161 62626261 63636262 ....aaaaabbbbbcc 19586070: 03636363 0000 ccc... a = aaaaa b = bbbbb c = ccccc Slot 1 Offset 0x76 ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 19586076: 00130010 64636261 00000065 77760000 ....abcde.....vw 19586086: 037a7978 0200 xyz... a = abcde b = [NULL] c = vwxyz DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Let's break out the values in the row for the second row in the table. The first 4 bytes are in the string 00130010. Status byte A is 10. This value indicates that bit 5 is on, which indicates that a null bitmap exists, which it does for every row. What is more telling is that bit 6 is off, indicating that there are no variable-length columns. Skipping status byte B, which is always 0, we have the value of 0013 for the length of the fixed-length data (for some curious reason, this value is not in reverse byte order). Hex 13 converts to decimal 19, which matches the value displayed in the page header for pminlen.
The next 19 bytes are then the fixed-length data: 64636261 00000065 77760000 037a7978. The first 5 bytes are column a (notice that the first four are in the first block, and the fifth character is on the right-hand side of the second block). If you reverse the byte order, you end up with 61 62 63 64 65, which are the ASCII values for the string "abcde". Because column b contains a null, it is all zeroes, and column c is represented, in reverse byte order, by 76 77 78 79 7a, the ASCII sequence for "vwxyz".
If you reverse the next two of the remaining 3 bytes, you get the value 0003, which is the number of columns in the table (3), and the last byte (02) is the Null bitmap. A value of 2 means that the second bit is on (00000010), which correlates with the second column (b), which in this row contains a null value. If you notice, the null bitmap in the first row is 0 because column b contains a value in that row.
To view the contents of page for a table with variable-length columns, create the following table and insert a row; then determine the page number of the first page:
use pubs
go
create table withvariable (a char(5) default 'aaaaa',
b char(5) null default 'bbbbb',
c varchar(10) default 'ccccc',
d char(5) default 'ddddd',
e nvarchar(10) default 'eeeee')
go
insert withvariable default values
go
exec sp_SSU_showindexpages withvariable
go
tablename id indid indexname root first firstiam
--------------- ----------- ------ ------------- ------- --------- --------
withvariable 1125579048 0 withvariable 1:81 1:81 1:82
You can see from the resultset that the first page is page 81. Now, use DBCC PAGE to display the contents:
dbcc page (pubs, 1, 81, 3)
go
PAGE: (1:81)
------------
BUFFER:
-------
BUF @0x191D26C0
---------------
bpage = 0x31C76000 bhash = 0x00000000 bpageno = (1:81)
bdbid = 14 breferences = 3 bstat = 0xb
bspin = 0 bnext = 0x00000000
PAGE HEADER:
------------
Page @0x31C76000
----------------
m_pageId = (1:81) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000
m_objId = 21575115 m_indexId = 0 m_prevPage = (0:0)
m_nextPage = (0:0) pminlen = 19 m_slotCnt = 1
m_freeCnt = 8051 m_freeData = 139 m_reservedCnt = 0
m_lsn = (43:104:1) m_xactReserved = 0 m_xdesId = (0:0)
m_ghostRecCnt = 0 m_tornBits = 0
Allocation Status
-----------------
GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED
PFS (1:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (1:6) = CHANGED
ML (1:7) = NOT MIN_LOGGED
Slot 0 Offset 0x60
------------------
Record Type = PRIMARY_RECORD
Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
31C76060: 00130030 61616161 62626261 64646262 0...aaaaabbbbbdd
31C76070: 05646464 00020000 002b0021 63636363 ddd.....!.+.cccc
31C76080: 65006563 65006500 006500 ce.e.e.e.e.
a = aaaaa
b = bbbbb
c = ccccc
d = ddddd
e = eeeee
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
The value for status byte A in this example is hex 30 (decimal 48). This indicates that in addition to bit 5, bit 6 is on, which indicates that this row contains variable-length data. The fixed-length data is still the same size, 19 bytes (0013, pminlen = 19). You'll also notice by looking at the data values on the far right, that all the fixed-length columns (a, b, and d) are stored at the beginning of the row. The 15-byte fixed data string (61616161 62626261 64646262 646464?remember the reverse byte ordering!), is then followed by 2 bytes for the the number of columns (0005) and 1 byte for the null bitmap, which in this example is 00 because none of the columns contain a null.
Following the null bitmap, the values are present only because there are variable-length columns. The next 2 bytes (again, curiously not in reverse byte order) are the number of variable-length columns (0002). The next 4 bytes (2 x the number of variable columns) are the column offset array (002b0021). These provide the location of the variable-length columns in the row. The first variable-length column, column c, is located at offset 0021, or decimal 33 (again, this value is not in reverse byte order). An offset of 33 indicates that the column ends at position 33, and if you look at the 33rd byte in the row, you'll find the end of the data value for column c. Column e is at offset 002b, which means that it ends at position 43, which is also the end, or total length, of the row. Notice also, that column e was defined as an nvarchar column and uses 2 bytes (0065) for each character.
Estimating Row and Table Sizes
Once you know the structure of a data row, you can estimate the size of a data row. Knowing the expected size of a data row and the corresponding overhead per row helps you determine the number of rows that can be stored per page and the number of pages a table will require. In a nutshell, a greater number of rows stored per page can help query performance by reducing the number of pages that need to be read to satisfy the query. In addition, you'll be able to estimate how much disk space your databases will require before you even insert your first row, so you can get the right size disks ordered before implementation.
If you have only fixed-length fields in your table, it's easy to estimate the row size:
n bytes (total of the fixed-column widths)
+ 1 byte for status byte A
+ 1 byte for status byte B
+ 2 bytes for the fixed-length data length
+ 2 bytes for the number of columns
+ ceiling (number of columns/8) for the null bitmap
= total row size
+ 2 bytes for the row offset table entry
There is a minimum amount of 7 bytes of overhead within each data row, plus 2 additional bytes of overhead for the row offset entry for the row (the row offset table is discussed in the next section of this chapter). For example, consider table withnull, described previously, which contains three fixed-length, char(5), columns. The total row size is the following:
| (3 * 5) | for fixed-column width |
| + 6 | fixed overhead bytes |
| + ceiling (3/8) | for null bitmap |
| = 22 | total row size |
| + 2 | row offset table entry |
| = 24 bytes per row | |
If the table contains variable-length fields, the average row width is determined as follows:
n bytes (total of the fixed-column widths)
+ 1 byte for status byte A
+ 1 byte for status byte B
+ 2 bytes for the fixed-length data length
+ 2 bytes for the number of columns
+ ceiling (number of columns/8) for the null bitmap
+ 2 bytes for the number of variable-length columns
+ 2 bytes * the number of variable columns for the column offset array
+ sum of average, or expected, size of variable-length columns
= average row size
+ 2 bytes for the row offset table entry
Each row containing variable-length columns has a minimum of 11 bytes of overhead?the 7 fixed bytes of overhead, plus a minimum of 4 bytes of overhead if the row contains at least one variable-length field. Consider table withvariable, which contains three fixed-length, (char(5)) columns and two variable-length columns of varchar(10) and nvarchar(10). Assume that the average data size for both variable-length columns is half the column size?5 and 10 bytes, respectively. The calculation of the average row size is as follows:
| (3 * 5) | for fixed fields |
| + 6 | for fixed-length overhead |
| + ceiling (5/8) | for null bitmap |
| + (5 + 10) | for sum of average size of variable fields |
| + 2 | number of variable fields |
| + (2 * 2) | for the column offset array |
| = 43 bytes | average row size |
| + 2 | row offset table entry |
| = 45 bytes |
NOTEFor a listing of SQL Server datatypes and their corresponding sizes, see Chapter 26, "Using Transact-SQL in SQL Server 2000." |
After you've estimated the data row size, you can determine the number of rows per page by dividing the average row size into the available space on the data page, 8096 bytes. For example, if your average row size is 45 bytes, the average number of rows per page is the following:
8096/45 = 179 rows per page
Remember to "round down" any fractions because you can't have only a portion of a row on a data page. If the calculation were to work out to something like 179.911 rows per page, it actually requires two pages to store 180 rows because the 180th row won't fit entirely on the first data page. If you are using a fill factor other than the default when you create your clustered index (fill factor is discussed in the "Setting the Fill Factor" section later in this chapter), you need to multiply the number of rows per page times the fill factor percentage as well to determine the actual number of rows that will initially be stored on each page. For now, assume that the default fill factor of 0 is used, which indicates that the data pages will be filled as full as possible.
When you know the average number of rows per page, you can calculate the minimum number of pages required to store the data by dividing the total number of rows in the table by the number of rows per page. To follow the example thus far, if you have 100,000 rows in the table, the number of pages required to store the data is the following:
100,000 rows/179 rows per page = 558.659… pages
In this case, you need to "round up" the value to get the actual number of pages (559) required to store all the data rows. The size of the table in pages is also the cost, in number of logical page I/Os, to perform a table scan. A table scan involves reading the first page of the table and following the page chain until all pages in the table have been read. The table scan, as you will explore in subsequent chapters, is the fallback technique employed by the SQL Server optimizer to find the matching rows for a query when there is no less-expensive alternative, such as a clustered or nonclustered index.
Format of the sql_variant Datatype
The sql_variant datatype is new for SQL Server 2000. The sql_variant datatype can contain a value of any column datatype in SQL Server except for text, ntext, image, and timestamp. For example, a sql_variant in one row could contain character data, in another row an integer value, and a float value in yet another row. Because they can contain any type of value, sql_variant columns are always considered variable length. The format of a sql_variant column is as follows:
Byte 1?Indicates the actual datatype being stored in the sql_variant.
Byte 2?The sql_variant version, always 1 in SQL Server 2000.
The remainder of the sql_variant contains the data value and, for some datatypes, information about the data value.
The datatype value in byte 1 corresponds to the values in the xtype column in the systypes database system table. For example, if the first byte contained a hex 38, that would correspond to the xtype value of 56, which is the int data type.
Some datatypes stored in a sql_variant column require additional information bytes stored at the beginning of the data value (after the sql_variant version byte). The datatypes requiring additional information bytes, and the values in these information bytes, are described as follows:
Numeric and decimal datatypes require 1 byte for the precision and 1 byte for the scale.
Character strings require 2 bytes to store the maximum length and 4 bytes for the collation ID.
Binary and varbinary data values require 2 bytes to store the maximum length.
The Row Offset Table
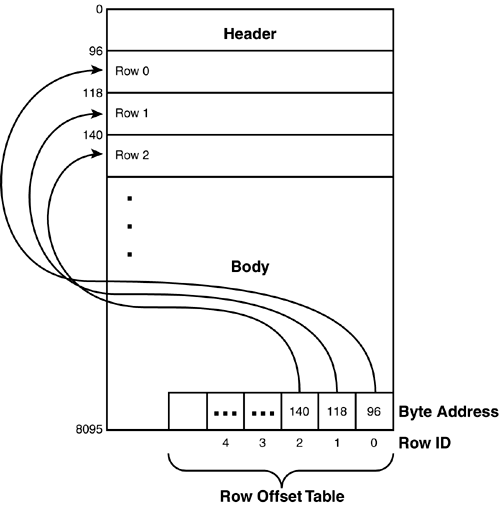
The location of a row within a page is identified by the row offset table, which is located at the end of the page. To find a specific row within a page, SQL Server looks up the starting byte address for a given row ID in the row offset table, which contains the offset of the row from the beginning of the page (refer to Figure 33.4). Each entry in the row offset table is 2 bytes in size, so for each row in a table, an additional 2 bytes of space is added in from the end of the page for the row offset entry.
Where a row goes when inserted into a table depends on whether there is a clustered index on the table. Without a clustered index, the table is a heap structure (clustered and heap tables are covered in more detail later in this chapter). When you insert a row into a heap table, the row goes at the end of the page as long as the page fits there. When you insert a row in to a clustered table, the clustering sort order must be maintained so that the row is inserted into its clustered position.
When you delete a row from a heap table, the byte address is set to 0, indicating that there is a "hole," or some available space, at that address. When you delete a row, the rows are not shuffled to keep the free space at the end of the page, as they were prior to SQL Server 7.0. If you insert data on a page where there is free space, but the free space is fragmented across the page because there have been deletions, the rows are compacted before the row is inserted. Figure 33.6 shows how the free space and the offset table are handled when you insert and delete data on a heap table. (Note that more rows would actually fit on the page than are drawn in Figure 33.6.)
Figure 33.6. Inserting and deleting rows on a heap table data page.
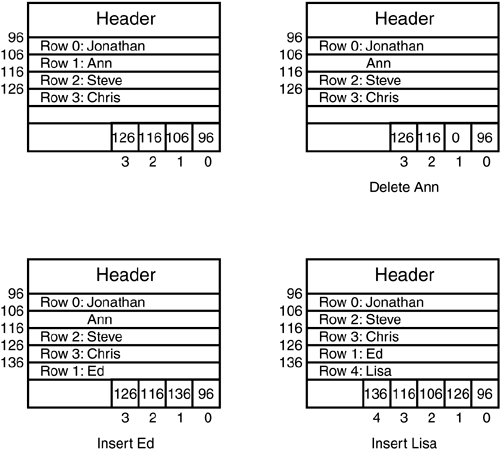
Note that deleting Ann does not remove the information physically stored on the page; the only modification is that the byte address for Row ID 1 is changed to 0 (unused). Row ID remains at its original offset (116) because the space is not compacted. When Ed is inserted, the row is added at the end of the used space on the page because space is available there. However, when Lisa is to be inserted, no space is available at the end of used space on the page, so the rows are compacted to make space available at the end of the page. Notice that while inserting and deleting rows, the Row IDs do not change for existing rows, so index entries for those rows do not have to be updated, reducing the index overhead for inserts and deletes.
The algorithm for managing the insertion and deletion of rows on a clustered table is similar to that for a heap table. The difference is that when a page is compacted to reclaim free space, the row offset table is adjusted to keep the rows in the clustered key order, by row number.
Index Pages
Index information is stored on index pages. An index page has the same layout as a data page. The difference is the type of information stored on the page. Generally, a row in an index page contains the index key and a pointer to the page or row at the next (lower) level.
The actual information stored in an index page depends on the index type and whether it is a leaf level page. A leaf level clustered index page is the data page itself, of which you've already seen the structure. The information stored on other index pages is as follows:
Clustered indexes, nonleaf pages?Each index row contains the index key and a pointer (the fileId and a page address) to a page in the index tree at the next lower level.
Nonclustered index, nonleaf pages?Each index row contains the index key and a page-down pointer (the file ID and a page address) to a page in the index tree at the next lower level. For nonunique indexes, the nonleaf row also contains the bookmark information for the corresponding data row.
Nonclustered index, leaf pages?Rows on this level contain an index key and a reference to a data row. For heap tables, this is the Row ID; for clustered tables, this is the clustered key for the corresponding data row.
The actual structure and content of index rows, as well as the structure of the index tree, are discussed in more detail later in this chapter.
Text and Image Data Pages
If you want to store large amounts of text or binary data, you can use the text, ntext, and image datatypes. (For information about how to use these datatypes, see Chapter 12, "Creating and Managing Tables in SQL Server," and Chapter 39, "Database Design and Performance.") Each column for a row of these datatypes can store up to 2GB (minus 2 bytes) of data. By default, the text and image values are not stored as part of the data row but as a collection of pages on their own. For each text or image column, the data page contains a 16-byte pointer, which points to the location of the initial page of the text or image data. A row with several text and image columns has one pointer for each column.
The pages that hold text and image data are 8KB in size, just like any other page in SQL Server. An individual text/image page can hold text, ntext, or image data for multiple columns and also from multiple rows. A text/image page can even contain a mix of text, ntext, and image data. This helps reduce the storage requirements for the text and image data, especially when smaller amounts of data are stored in these columns. For example, if SQL Server could only store data for a single column for a single row on a single text or image page and the data value consisted of only a single character, it would still use an entire 8KB data page to store it! Definitely not an efficient use of space.
A text or image page can only hold text or image data for a single table, however. A table with a text or image column has a single set of pages to hold all its text and image data. The information on the starting location of this collection of pages is stored in the sysindexes system table. The text/image collection always has an index ID (indid) of 255.
Text and image information is presented externally (to the user) as a long string of bytes. Internally, however, the information is stored within a set of pages. The pages are not necessarily organized sequentially but are logically organized as a B-tree structure. (B-tree structures will be covered in more detail later in this chapter.) If an operation addresses some information in the middle of the data, SQL Server can navigate through the B-tree to find the data. In previous versions, SQL Server had to follow the entire page chain from the beginning to find the desired information.
If the amount of the data in the text/image field is less than 32KB, then the 16-byte pointer in the data row points to an 84-byte root structure in the text/image B-tree. This root structure points to the pages and the location where the actual text or image data is stored (see Figure 33.7). The data itself can be placed anywhere within the text/image pages for the table. The root structure keeps track of the location of the information in a logical manner. If the data is less than 64 bytes, it is stored in the root structure itself.
Figure 33.7. Text data root structure pointing at the location of text data in the text B-tree.
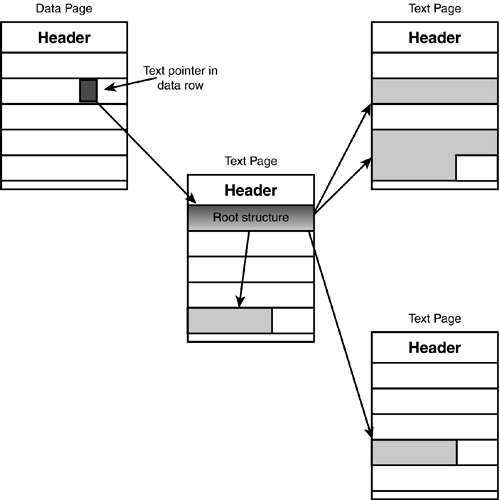
If the amount of text or image data exceeds 32KB, SQL Server allocates intermediate B-tree index nodes that point to the text and image pages. In this situation, the intermediate node pages are stored on pages not shared between different occurrences of text or image columns?the intermediate node pages store nodes for only one text or image column in a single data row.
Storing Text and Image Data in the Data Row
To further conserve space, and help minimize I/O, SQL Server 2000 supports storing the text or image data in the actual data row. When the text or image data is stored outside the data row pages, at a minimum, SQL Server needs to perform one additional page read per row to get the text of image data.
Why would you want to store text data in the row? Why not just store the data in a varchar(8000)? Well, primarily because there is an upper limit of 8KB if the data is stored within the data row (not counting the other columns). Using the text datatype, you can store more than 2 billion bytes of text. If you know most of your records will be small, but on occasion, some very large values will be stored, the text in row option provides optimum performance and better space efficiency for the majority of your text values, while providing the flexibility you need for the occasional large values. It also provides the benefit of keeping the data all in a single column instead of having to split it across multiple columns or rows when the data exceeds the size limit of a single row.
If you want to enable the text in row option for a table with a text or image column, use the sp_tableoption stored procedure:
exec sp_tableoption pub_info, 'text in row', 512
This example enables up to 512 bytes of text or image data in the pub_info table to be stored in the data row. The maximum amount of text or image data that can be stored in a data row is 7000 bytes. When a text or image value exceeds the specified size, rather than store the 16-byte pointer in the data row as it would normally, SQL Server stores the 24-byte root structure that contains the pointers to the separate chunks of text/image data for the row in the text or image column.
The second parameter to sp_tableoption can be just the option of ON. If no size is specified, the option is enabled with a default size of 256 bytes. To disable the text in row option, set its value to 0 or 'OFF' with sp_tableoption. When the option is turned off, all text and image data stored in the row will be moved off to text/image pages and replaced with the standard 16-byte pointer. This can be a time-consuming process for a large table.
Also, keep in mind that just because this option is enabled doesn't always mean that the text or image data will be stored in the row. All other data columns that are not text or image take priority over text and image data for storage in the data row. If a variable-length column grows and there is not enough space left in the row or page for the text or image data, the text/image data will be moved off the page.
Space Allocation
When a table or index needs more space in a database, SQL Server needs a way to determine where space is available in the database to be allocated. If the table or index is still less than eight pages in size, SQL Server must find a mixed extent with one or more pages available that can be allocated. If the table or index is eight pages or larger in size, SQL Server must find a free uniform extent that can be allocated to the table or index.
Extents
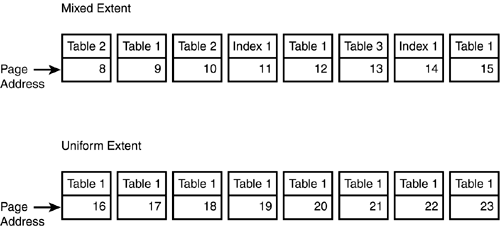
If SQL Server allocated space one page at a time as pages were needed for a table (or an index), SQL Server would be spending a good portion of its time just allocating pages, and the data would likely be scattered noncontiguously throughout the database. Scanning such a table would not be very efficient. For these reasons, pages for each object are grouped together and allocated in extents; an extent consists of eight logically contiguous pages.
Earlier versions of SQL Server reserved one extent for a table or index at the time of creation. No other objects could be stored on this extent. Even if the table had no rows in it, it was essentially using 16KB (8 * 2KB) of space in the database that couldn't be used by any other object. In version 7.0, with the increase of page sizes from 2KB to 8KB, this algorithm was changed a bit to more efficiently allocate space to new tables. The concept of the mixed extent was introduced.
When a table or index is created, it is initially allocated a page on a mixed extent. If no mixed extents are available in the database, a new mixed extent is allocated. A mixed extent can be shared by up to eight objects (each page in the extent can be assigned to a different table or index).
As the table grows to at least 8 pages in size, all future allocations to the table are done as uniform extents.
Figure 33.8 shows the use of mixed and uniform extents.
Figure 33.8. Mixed and uniform extents.
If SQL Server had to search throughout an entire database file to find free extents, it wouldn't be efficient. Instead, SQL Server uses two special types of pages to record which extents have been allocated to tables or indexes and whether it is a mixed or uniform extent:
Global Allocation Map Pages (GAMs)
Shared Global Allocation Map Pages (SGAMs)
Global Allocation Map Pages
The allocation map pages track whether extents have been allocated to objects and indexes and whether the allocation is for mixed extents or uniform extents. There are two types of GAMs:
Global Allocation Map (GAM)?The GAM keeps track of all allocated extents in a database, regardless of what it's allocated to. The structure of the GAM is straightforward: Each bit in the page outside the page header represents one extent in the file, where 1 means that the extent is not allocated, and 0 means that the extent is allocated. Nearly 8000 bytes (64,000 bits) are available in a GAM page after the header and other overhead bytes are taken into account. Therefore, a single GAM covers approximately 64,000 extents, or 4GB (64,000 * 64KB) of data.
Shared Global Allocation Map (SGAM)?The SGAM keeps track of mixed extents that have free space available. An SGAM has a structure similar to a GAM, with each bit representing an extent. A value of 1 means that the extent is a mixed extent and there is free space (at least one unused page) available on the extent. A value of 0 means that the extent is not currently allocated, that the extent is a uniform extent, or t







