SQL Server Naming Standards
What's in a name? The answer to this simple question often takes organizations months?or years?to define. Names should be chosen in a consistent manner across all SQL Server systems in your organization; for example, a word should not be abbreviated two different ways in two different places. Consistency with names is one of the building blocks of an infrastructure to which employees and users can become accustomed. Consistent naming enables employees to move from system to system (or software to software) and have basic expectations regarding names. This can help in the transition when learning a new environment.
NOTENaming standards are like filing standards. You have to think about the person who is storing the information and the person who will retrieve it. For the person defining the name, the choice should be automatic. For the person retrieving or accessing an object, the name should completely define its content without ambiguity. |
Naming standards can be broken into two areas: SQL Server names and operating system names. SQL Server names are the names that you specify in the SQL Server environment (databases, objects, and so forth). Operating system names are the names that you specify for files and directories.
SQL Server Names
In SQL Server, you are responsible for naming the server, each user database, each object in the database (tables and columns, indexes, views, stored procedures, and functions), and any integrity constraints (rules, defaults, user datatypes, triggers, and declarative constraints).
Capitalization standards must be defined for each type of name. (Should names be in all capital letters, all lowercase letters, or mixed case?) This decision can be different for different groups of names (for example, server names could be in all capital letters and object names could be in mixed case).
Consider also whether to use an indicator of the item being named. For example, does the word database or the abbreviation DB get included in a database name? In the end, your standard should identify whether a customer database will be named Customer, CUSTOMER, CustomerDB, or CUSTOMERDB. For most database objects, the structure of names is the personal preference of the person writing the standard.
NOTEA naming convention that is often debated within many shops is whether to use the underscore (_) character between descriptive words or indicators (for example, sales_detail) or mixed case (for example, SalesDetail). I prefer to use underscores, because that method is, in my opinion, more readable and easier to type. Others tend to prefer the latter because it saves one character per word, which can help to keep names shorter and within any standard enforced size limitations without having to abbreviate as often. It also saves them from having to search for the underscore key on their keyboards. (If only computer manufacturers would design a standard keyboard with an underscore character that doesn't requiring using the Shift key to type, life would be near bliss!) The method that you choose to use is entirely up to you or your organization's preference. Throughout this chapter, I will attempt to alternate between both alternatives in the examples provided to avoid alienating either camp in this ongoing battle, and provide you the opportunity to see both methods and decide for yourself which you prefer. |
Object Type Indicators
An indicator is a string of characters that is embedded in a name to indicate something about the object. In SQL Server, these characters are often used to indicate an object type. For example, CurrDate_Def could be used as a name for a default setting a column to the current date and time. There are two schools of thought on the use of indicators:
An indicator is not needed because the type of object can be retrieved from the system tables (the type column in the sysobjects table) or is indicated by the table from which you are selecting (sysdatabases, sysservers). Including an indicator in the name is redundant and a waste of valuable characters. Although names in SQL Server can be up to 128 characters long, naming conventions might often limit them further to be compatible with existing guidelines or other systems (for example, object names within a DB2 environment are limited to 18 characters). An indicator can easily take four or five characters (_tbl or _view, for example), which limits the number of available characters in an object name. Indicators can also propagate through to dependent objects (Customer_Tbl_CIdx), further reducing the number of available characters. When users need to use a name frequently, indicators also mean extra typing. If you decide to put an indicator in a name, it is best to make that indicator as short as possible.
An indicator is needed because it simplifies reporting. A DBA can tell the type of object from just a listing of object names. Application designers are cognizant of what type of objects they are accessing (for example, the name tells them whether they are selecting from a table or view). Indicators also enable you to use similar, meaningful names for two objects, once with each indicator (for example, price_check and price_default).
NOTEAll object names within a database must be unique for the owner. In other words, the dbo can own only one object of any name. If you have a rule named price_check, you cannot create a constraint named price_check. This restriction applies to tables and views, as well as rules, defaults, constraints, procedures, and triggers. To avoid being constrained by these names, consider using indicators, especially for objects with which users do not interact and whose names users will never type (rules, defaults, constraints, and triggers). |
Table 25.1 lists the most common indicators used by SQL Server installations throughout the world. Consider that many sites choose no indicators at all for referenced objects such as tables, views, and stored procedures, and use them only for internal objects such as indexes, triggers, and constraints.
| Item | Possible Indicators | Preferred |
|---|---|---|
| Database | Database, DATABASE, DB | DB |
| Table | Table, TABLE, T, TBL, tbl, t | None |
| Clustered index | ClusIdx, Cidx, clus, C, CI | CI |
| Non-clustered index | Idx[#],NCIdx[#], NCI[#], I[#] | NCI[#] |
| View | V, View, VIEW | None |
| Rule | Rul, rul, RUL, rule, RULE, R | Rul |
| Default | Def, def, DEF, default, DEFAULT, D, DF | DF |
| User-defined datatype | TYPE, Type, type, TYP, Typ, | type |
| Stored procedure | Proc, PROC, Pr, PR, pr, p, P | pr |
| Trigger | InsertTrigger, InsTrig, ITrg, Itrg, TR, TR_I | TR_I |
| Check constraint | Check, CK, Chk, CkCon, | CK |
| Primary key constraint | PK, Pk, Pk | PK |
| Unique constraint (alternate key) | Unique, Uniq, UN, UQ, AK | AK |
| Foreign key constraint | FK, RI | FK |
NOTEIt is probably not a good idea to use indicators in the names of tables or views. Many sites use the table name in the name of other objects. The inclusion of _tbl increases the number of redundant characters in the dependent object name (trigger, index, and so forth). In addition, views exist to give users the feeling that their queries are acting against a real table, although they actually are accessing a view. Therefore, table and view names should be identical in format, and should not contain anything that would distinguish one from the other (_tbl or _view, for example). |
Your standards likely will be different, but the important thing is to be consistent in your implementation of names. Knowing the standards up front can save you days or weeks of costly name conversion changes (with SQL code, administration activities, and so forth).
Prefix Versus Suffix
As with most standards, there are differing schools of thought as to where the indicators should go in the name: at the beginning or at the end.
One argument for using indicators as prefixes is that it makes it easier to identify the type of object when its name begins with the indicator. It's easier to scan the beginning of the names to see the type indicator than the end of the name. Also, if you are listing out all the objects in the database, sorting by name also results in sorting by type, as shown in the following example.
select name, type from sysobjects and type != 'S' order by name go name type ------------------------------ ---- CK_titles_type C FK_titles_publishers F PK_publishers K PK_titles K pr_publishers_delete P pr_publishers_update P pr_titles_select P pr_titles_update P publishers U titles U TR_DU_publishers TR TR_IU_titles TR
The main argument for using indicators as suffixes is that if the dependent objects for a table (indexes, triggers, stored procedures) begin with the table name, then the table and its dependent objects will be grouped together in an alphabetical listing of database objects, as in the following example:
select name, type from sysobjects and type != 'S' order by name go name type ------------------------------ ---- publishers U publishers_delete_proc P publishers_PK K publishers_TR_DU TR publishers_update_proc P titles U titles_PK K titles_publishers_FK F titles_select_proc P titles_TR_IU TR titles_type_ck C titles_update_proc P
Again, the method you choose is a matter of personal preference. No matter which method you choose, you can always list your objects by type in your SQL:
select name, type from sysobjects order by type
Naming Servers
In versions of SQL Server prior to SQL Server 2000, naming the SQL Server was easy. Because only one SQL Server could be running on the server machine, SQL Server for Windows NT took its name from the NT Server name by default. Changing this required editing registry values. Because hacking the registry can be dangerous, and a SQL Server with a different name from the NT Server name would probably lead to confusion, the SQL Server name was generally never modified. You simply hoped that the NT Server machine was named as you would want the SQL Server named. For example, you would much rather have a server named DEVELOPMENT than one named RSR8_AB100.
TIPSome companies like to name their servers according to cartoons or movies. There are Snow White servers (DOPEY, GRUMPY, DOC, and so forth), Batman servers (BATMAN, ROBIN, JOKER, PENGUIN), and Mickey Mouse servers (MICKEY, MINNIE, GOOFY, DONALD). Although these names are fun, they should be used only for development or general server names, because they don't convey information as to the purpose of the server. Servers intended to support applications should be named in a consistent manner across all applications. |
With SQL Server 2000's support for multiple named instances on a single server machine, meaningful names will need to be applied to the different named instances. Although the base of the named instance will still be the name of the server on which SQL Server is running, you can control what the instance name will be. The actual server name becomes less important.
If the instance supports a single application, the instance name should indicate both the system and environment name. The following is a good format:
\\SERVERNAME\SYSTEMNAME_ENVIRONMENTNAME
For the development of a customer service system, you might use instance names such as CUST_DEVEL, CUST_TEST, and CUST_PROD.
If the SQL Server instance supports multiple application databases, the instance name should be more generic, but still include an environment name if applicable. The first part of the instance name could reflect the company name, department name, or another meaningful designation. The following is a possible solution:
\\SERVERNAME\DEPARTMENTNAME_ENVIRONMENTNAME
For the marketing department's server, you might use instance names, such as MARKETING_DEVEL, MARKETING_TEST, and MARKETING_PROD.
Although the case of server names does not matter for client connectivity, server names are generally specified in uppercase.
Naming Databases
Databases should be named according to their contents?for example, the type of data (customer or product) or activity (security or administration). A database that contains security tables could be named SecurityDB, and a database that contains customer data could be called CustomerDB. The name selected should be intuitive. If documentation is required to relate a database's name to its contents, it probably is not intuitive. Would you rather have a database named B123 or ProductDB? Avoid nondescriptive database names!
Table and View Names
Table and view names should be unambiguous and representative of the underlying data. A customer table could be called Customer; a view of the California customers could be called CaliforniaCustomer. Some organizations like to use nondescriptive table names (TBL0001). Again, avoid nondescriptive table and view names. If names are not intuitive, a decode document might be required to relate the table name to its contents. This delays development and makes it harder to write SQL statements. Column names should indicate the data in the column. Name a column containing the age of a customer either Age or CustomerAge.
Although names should not be too long, it is best to avoid abbreviations, except for the indicators already discussed. If an abbreviation is required, one commonly accepted method of abbreviation is to simply remove the vowels.
CAUTIONBe careful not to use generic nouns for objects' names (such as page, time, share, country, and item). Although they are concise and might not be reserved keywords at this time, they might become reserved words in the future. |
Column Names
Column names should clearly indicate the domain of a column (such as FirstName or CustomerFirstName and SupplierFirstname). There are two schools of thought again on whether the column name should include the table name as well. Some people feel that including the table name is redundant?if the FirstName column is in the Customer table, would it not be the customer's first name? On the other hand, if you have to join between the two tables and display FirstName from both tables, how do you easily distinguish in the result set which is which? Both would have the same column heading of FirstName unless different column aliases were specified. It is recommended that for common attributes (name, ID, address), the object descriptor be used in the column name.
It can also be helpful to standardize suffixes for your columns to indicate the type of data that the columns contain. For example, for numeric and character keys, you could use the suffix ID consistently to indicate a numeric key and the suffix Code to indicate a character key (as in SupplierID and CountryCode). Additional suffixes can be used to indicate whether the column contains a name (CompanyName), a date (LastModifiedByDate), a user (LastModifiedByUserID or ChangedByUserName), an amount (LoanAmount), a flag (active_flag), and so on.
If you use descriptive suffixes, you might want to abbreviate them to save space, following a set of standards for abbreviation.
Column Abbreviation Standards
Because your naming standards might limit the length of column names and database object names, it might be necessary to abbreviate descriptive components of column and object names. It is recommended that abbreviation standards be included in your standards definitions so that all users and developers are using a consistent method of abbreviation to avoid confusion.
Some guidelines for applying abbreviations and keeping names shorter yet descriptive are as follows:
Avoid the use of prepositions in the name (for example, BIRTH_DT instead of Date_of_Birth).
Drop the least informative descriptors and abbreviate those that lend themselves most naturally to abbreviation (for example, social_security_number abbreviated as ssn, or document abbreviated as doc).
Remove all vowels from a word, similar to what you see on some vanity license plates (for example, customer would become cstmr).
Use abbreviations consistently for common identifiers as defined by a master list of common abbreviations, similar to the example provided in Table 25.2.
| Base Word | Abbreviation |
|---|---|
| NAME | NM |
| NUMBER | NUM |
| CODE | CD |
| COUNT | CNT |
| AMOUNT | AMT |
| DATE | DT |
| TEXT | TXT |
| ADDRESS | ADDR |
| FLAG | FL |
| PERCENT | PCT |
| TIMESTAMP | TS |
| IDENTIFIER | ID |
NOTEIn some cases, you might debate whether certain abbreviations really save you anything. I've seen some shops where code and date were abbreviated as cde and dte, respectively. Not only did these abbreviations only save a single letter, but most developers and DBAs (myself included) also found themselves constantly typing out the whole word anyway out of habit. The abbreviations were more frustrating than helpful. As a general rule, unless the abbreviation saves two or more characters, it's not worth abbreviating. |
Using Column Datatype Indicators
In addition to, or instead of, column type indicators, some organizations require the use of indicators to make the datatype apparent to developers (for example, mSaleAmount and vchAddress). Others consider it a waste of space, and a well-named column can indicate enough about the datatype. (A column named CustomerFirstName is obviously a character datatype and one called SaleAmount is obviously a numeric type.) The naming philosophy is something that must be determined by the individual organization. Sometimes, the tools most often used within that organization might impact the decision on naming conventions. For example, the way that a commonly used tool organizes and orders objects when displaying them might be a deciding factor. If an indicator is used, make it as short and concise as possible.
Using an indicator for the datatype on column and variable names can prevent errors that occur from datatype mismatches, as well as let you avoid constantly referencing a diagram or other document to determine the datatype. Table 25.3 lists some common indicators that normally preface a column or variable name.
| Item | Indicator |
|---|---|
| Bit | b |
| Char | ch |
| text | tx |
| Datetime | dt |
| Integer | int |
| Bigint | bi |
| Tinyint | ti |
| Float | f |
| Money | m |
| Smallmoney | sm |
| Numeric | num |
| Varchar | vch |
Index Names
Generally, index names contain only information about the table and the index type, with no information about what columns are included in the index. Including column names in an index can make the index name overly wordy without providing much value, especially for compound indexes. Some examples are CustomerCU (clustered unique index on Customer), CustomerIDX1, and CustomerIDX2 (general non-clustered indexes). However, like with all naming standards, people have differing opinions on index naming. The SQL Server 2000 optimizer has the capability to use multiple indexes for a single table in a query, which means that many administrators might select to create many single-column indexes to support this new feature. In this environment, you might want to include the use of the column name in the index name to make it easier to distinguish them when viewing execution plans or providing index hints.
Constraints
Constraint names vary based on the scope of the constraint. Constraints can be used to check for valid values, add unique or primary keys, and establish relationships between tables (foreign keys).
A check constraint checks for valid values in a single column or multiple columns. Its name should indicate the table, column(s) and possibly the type of check.
Unique and primary key constraints are based on a table and should contain the table name and an indicator of the type of constraint (PK or AK). If multiple unique keys exist, you can distinguish them with a number or add the column name to the constraint name.
A foreign key constraint implements referential integrity between two tables. Its name should contain the tables or columns involved in the relationship and an indicator (FK or RI).Table 25.4 shows a sample list of constraint indicators and names for the Customer table.
| Constraint Type | Indicator | Name Based On | Constraint Name |
|---|---|---|---|
| Check constraint | CK | Table and Column or columns | Customer_Age_CK |
| Primary key constraint | PK | Table | Customer_PK |
| Unique key constraint | AK | Table or table and column | Customer_AK |
| Foreign key constraint | FK | Related tables or columns | Customer_Purchase_FK |
TIPRemember that constraints are objects. For an owner, constraint names must be unique among all objects within the database. Qualifying the constraint name by including the table name helps to ensure uniqueness of the constraint names. (You won't have two primary key constraints that contain the same table name for the same user in a database.) Table-level constraints can evaluate many columns. Include in your naming standard a method of naming table-level constraints. For example, the constraint that requires an invoice amount to be greater than zero whenever the type is 'SALE' might look like this: constraint Invoice_AmtType_CK check ((amt > 0) or (type <> 'SALE')) If you plan to use table names in your constraint names, it helps to keep table and column names fairly short, yet descriptive. |
Stored Procedure Names
A stored procedure name should include a standardized verb to indicate the action performed. You should set a standard for where the verb should fall in the name (a prefix or a suffix). Some suffix examples are CustomerDataUpdate, CustomerDelete, CustomerSelect, and UserValidate.
SQL Server also allows the definition of customized system stored procedures. System stored procedures must be created in the master database and begin with sp_. User-defined system stored procedures, however, should be named in a way to avoid conflict with existing or future Microsoft-supplied system stored procedures. The naming convention used for user-defined system stored procedures should prevent confusion as to whether a system stored procedure was provided with SQL Server or was created by a local administrator. It is recommended that an additional prefix be added to the procedure name after the sp_ to distinguish it from standard system stored procedures. Often, this prefix is an abbreviation of the company name. For example, a custom system stored procedure to display locking information developed for use within the XYZ Company would be named sp_XYZ_lockinfo. The XYZ indicator identifies this system procedure as one created by the XYZ Company, and prevents it from conflicting with Microsoft-supplied stored procedures.
Trigger Names
Trigger names should consist of the table name and an indicator of the trigger action (insert, update, delete). A good format is TableName_TR_[IUD]:
| Object Type | Object Name |
|---|---|
| Table name | Customer |
| Insert trigger | Customer_TR_I |
| Delete trigger | Customer_TR_D |
| Update trigger | Customer_TR_U |
| Update and delete trigger | Customer_TR_UD |
With the introduction of INSTEAD OF triggers in SQL Server 2000, you might also want to devise a method to distinguish between INSTEAD OF and AFTER triggers. One approach would be to use a different indicator for INSTEAD OF triggers, such as ITR. For example, an INSTEAD OF insert trigger on Customer would be named Customer_ITR_I.
User-Defined Functions
Like stored procedures, user-defined function names should include a standardized verb to indicate the action performed. However, because functions are generally more generic than stored procedures and don't necessarily operate on specific tables, the names will usually be more generic as well. Try to use names that are descriptive of the action performed by the function. You might also want to use a prefix indicator, such as udf_, to differentiate user-defined functions from system-supplied functions. Some examples are udf_getdateonly, udf_compare_addresses, and udf_CheckJobStatus.
Rules and Defaults
Rules and defaults are implemented at the database level and can be used across tables. Their names should be based on the function that they are providing. A rule that checks for a valid age range could be called ValidAge_Rul; a default that places the current date in a field could be called CurrDate_Def.
User-Defined Datatypes
Following is an effective format for user-defined types:
contents_type
Because user-defined datatypes normally are targeted at certain types of columns, the name should contain the type of column for which it is to be used (ssn, price, address) followed by the indicator _type.
A SQL Server Naming Standards Example
Table 25.5 outlines a sample naming standard that uses the guidelines presented in this chapter. Note that in this example, prefixes are used for object indicators.
| Object Type | Object Name | Example |
|---|---|---|
| SQL Servers | DEPARTMENTn | MORTGAGE1 |
| Databases | Nnnnnnn[Nnnnnnnn] | Insurance, Payments |
| Columns | Nnnnnnn[Nnnnnnnn]Indicator | PolicyID, CustomerLastName |
| Check constraints | CK_TableName_ColumnName | CK_Loan_Amount |
| Default constraints | DF_TableName_ColumnName | DF_Loan_Amount |
| Foreign key constraints | FK_FkeyTablename_PkeyTablename | FK_Loan_Customer |
| Primary key constraints | PK_TableName | PK_Loan |
| Unique constraints | AK_TableName_ColumnName | AK_Loan_LoanNo |
| Indexes?clustered | CI_TableName | CI_Customer |
| Indexes?non-clustered | NC#_TableName | NC2_Customer |
| Stored procedures | pr_Verb[Tablename[Nnnnn]] | pr_GetCustomerInfo |
| User Defined Functions | udf_nnnnnnnnnn | udf_getdateonly |
| System stored procedures | sp_SSU_nnnnnnnnnnnnnnnnnn | sp_SSU_helplogin |
| Tables | nnnnnnnnn[Nnnnnnnn…] | LoanType |
| Triggers | tr_[d][i][u]_ Nnnnnnn[Nnnnnnnn] | tr_iu_Loan |
| Views | Nnnnnnn[Nnnnnnnn] | NewLoans |
| Rules | Nnnnnnn[Nnnnnnnn]_rule | ValidID_rule |
| Defaults | Nnnnnnn[Nnnnnnnn]_dflt | Country_dflt |
| User-defined datatypes | nnnnnnnn_type | ssn_type |
Operating System Naming Standards
You need to establish a naming standard for operating system files and directories. This standard normally is needed to organize DDL files. You need a DDL file for every important action and object that exists in SQL Server. This includes configuration changes (sp_configure), adding users and logins, creating and altering databases, setting database options, creating objects (tables, views, indexes, and so forth), and granting permissions. Place the files in directories that are organized in a way that enables you to easily re-create an entire environment from scratch.
Sometimes overlooked in standards creation is the criticality of scripting every database object at its lowest level and storing these scripts in a standard directory structure, under source control. This lets you build servers from scratch from tested common scripts, either in their entirety or in pieces. When a table has become corrupt and must be immediately dropped and re-created during production hours, a tested script that can run without editing is critical. Creating object scripts at their lowest levels means that there should be an object creation script and an object drop script that create and drop only that object. Therefore, a table would have a create-table script, a drop-table script, and a grant-permissions script.
Directory Naming Standards
Specifying and organizing directory names should be based on your environment. Create a directory structure that can handle multiple SQL Servers, multiple databases within a SQL Server, and individual creation files for each object within a database. The object scripts should be contained in separate object type directories. Although the hierarchy presented here might seem overly complex, it allows the most flexibility in a production environment.
Base Directory: Server Name
All DDL for a server/environment should be stored relative to a base directory named according to the server name. For example, if you have three SQL Servers named CUSTOMER_DEVEL, CUSTOMER_TEST, and CUSTOMER_PROD, the base directories would be \CUSTOMER_DEV, \CUSTOMER_TEST, and \CUSTOMER_PROD, respectively.
The base directory and all subdirectories should contain all necessary DDL statements to re-create the entire SQL Server. Separating the files from different SQL Server environments by directory enables different environments to contain different versions of the same file. This is helpful in regression testing.
The server-level directory would contain scripts or subdirectories for server-level configuration settings, custom error messages, scheduled tasks and operators, SQL Server logins, and user-defined system procedures.
First Level Subdirectory: Database Names
Under the base directory for the server are subdirectories for each of the databases supported by the server. Database-level scripts, such as database option and filegroup definition scripts, would be stored at this level.
Second Level Subdirectory: Database Object Types
Under the database subdirectory should be a directory for each object type. (If you have modified the model database, it should have a directory as well.) The actual scripts to drop and create the database objects would be stored in the appropriate subdirectories.
Figure 25.1 shows a sample directory hierarchy for storing DDL script files.
Figure 25.1. Suggested server and database object directory hierarchy.
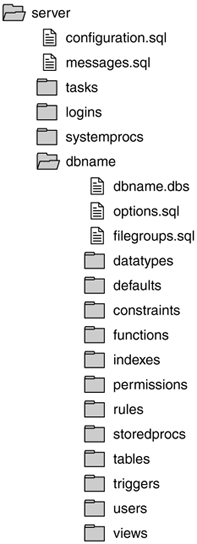
Object Files and File Extensions
Usually, the operating system filename should be the same as the object name. It is common in some organizations to name a file with an extension that indicates the type of object or activity (such as .trg for trigger scripts, .viw for view scripts, and .tbl for table scripts). The philosophy is similar to using indicators in SQL Server names.
Table 25.6 lists examples of extensions for the various object types. (Note that these extensions correspond with those generated by Enterprise Manager.)
| Object | Extension |
|---|---|
| Database | .dbs |
| Tables and indexes | .tbl |
| View | .viw |
| Rule | .rul |
| Default | .def |
| User-defined datatypes | .udt |
| Triggers | .trg |
| Stored procedures | .prc |
| User-defined functions | .udf |
| User-defined error messages | .err |
| Logins | .lgn |
| Users | .usr |
SQL Server Enterprise Manager uses these indicator extensions when it scripts database objects because all of the scripts are generally saved to one directory, requiring a distinguishing extension. However, if you maintain a standard object directory structure, you don't need object type filename extensions because the directory name identifies the object type. In addition to the redundancy of being in the subdirectory for the object type, the extension might also be redundant because the object name might contain a type indicator. For example, a rule called ValidPrice_Rul would have a filename of ValidPriceRul.rul. Notice the triple redundancy. The rule script would be created in the rules subdirectory with a filename of ValidPrice_Rul and a file extension of .rul.
If you are using an object-level database hierarchy, like the one recommended in Figure 25.1, you might find it more useful to use a filename extension of .sql. This is because most query or script management tools out there, Query Analyzer included, look for and save files with a .sql extension by default. Although you can set up associations between the other script file extensions and your query/script management tool of choice, it is a bit tedious to do so.








