SQL Server Lock Granularity
The values listed earlier in Table 38.1 represent all the various levels, or granularity, of locks from which the SQL Server Lock Manager can choose when processing queries and transactions.
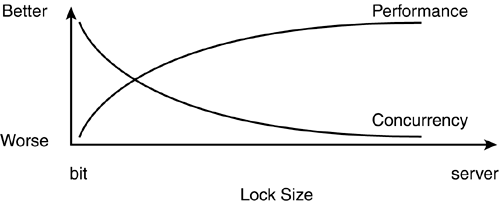
Lock granularity is essentially the minimum amount of data that is locked as part of a query or update to provide complete isolation and serialization for the transaction. The Lock Manager needs to balance the concurrent access to resources versus the overhead of maintaining a large number of lower-level locks. For example, the smaller the lock size, the greater the number of concurrent users who can access the same table at the same time, but the greater the overhead in maintaining those locks. The greater the lock size, the less overhead that is required to manage the locks, but concurrency is also less. Figure 38.8 demonstrates the tradeoffs between lock size and concurrency.
Figure 38.8. Tradeoffs between performance and concurrency depending on lock granularity.
Currently, SQL Server balances performance and concurrency by locking at the row level or higher. Based on a number of factors, such as key distribution, number of rows, row density, search arguments (SARGs), and so on, the query optimizer makes lock granularity decisions internally, and the programmer does not have to worry about such issues. SQL Server 2000 does provide a number of T-SQL extensions that give you better control over query behavior from a locking standpoint. These optimizer overrides are discussed in the "Table Hints for Locking" section later in this chapter.
The following list describes the locking levels in SQL Server 2000 in more detail:
Database?Whenever a SQL Server process is using a database other than Master, the Lock Manager grants a DB lock to the process. These are always shared locks, and they are used to keep track of when a database is in use to prevent another process from dropping the database, setting the database offline, and restoring the database. Note that because master and tempdb cannot be dropped or set offline, DB locks are not required on those databases.
Extent?Extent locks are used for locking extents, usually only during space allocation and deallocation. An extent consists of eight contiguous data or index pages. (See Chapter 33, "SQL Server Internals," for more information on extents.) Extent locks can be shared extent or exclusive extent locks.
Table?The entire table, inclusive of data and indexes, is locked. Examples of when table-level locks can be acquired include selecting all rows from a large table at the serializable level, performing an unqualified update or delete on a table, or creating a clustered index on a table.
Page?The entire page, consisting of 8KB of data or index information, is locked (for more information on pages, see Chapter 33). Page-level locks might be acquired when all rows on a page need to be read or when page level maintenance needs to be performed, such as updating page pointers after a page split.
Row?A single row within a page is locked. Row locks are acquired whenever efficient and possible to do so in an effort to provide maximum concurrent access to the resource.
Key?SQL Server uses two types of key locks. The one that is used depends on the locking isolation level of the current session. For transactions that run in Read Committed or Repeatable Read isolation modes, SQL Server locks the actual index keys that are associated with the rows being accessed. (If a clustered index is on the table, the data rows are the leaf level of the index. You will see key locks on those rows instead of row locks.) When in Serialized isolation mode, SQL Server prevents phantom rows by locking a range of key values so that no new rows can be inserted into the range. These are referred to as key-range locks. Key-range locks associated with a particular key value lock that key and the previous one in the index to indicate that all values between them are locked. Key-range locks are covered in more detail in the next section.
Application?SQL Server provides a new type of user-defined lock: the application lock. The application lock allows users to essentially define their own locks by specifying a name for the resource, a lock mode, an owner, and a timeout interval. Using application locks will be discussed in the "Using Application Locks" section.
Serialization and Key-Range Locking
As mentioned in the previous section, SQL Server provides serialization (isolation level 3) through the SET TRANSACTION ISOLATION SERIALIZABLE command. One of the isolations that is provided by this isolation level is the prevention against phantom reads. Preventing phantom reads means that the recordset that a query obtains within a transaction must return the same resultset when it is run multiple times within the same transaction. That is, while a transaction is active, another transaction should not be allowed to insert new rows that would appear in the recordset of a query that were not in the original recordset retrieved by the transaction. SQL Server 2000 provides this capability though key-range locking.
As described earlier, key-range locking within SQL Server provides isolation for a transaction from data modifications made by other transactions. This means that a transaction should return the same recordset each time. In this section, you will see how key-range locking works with various lock modes. Key-range locking covers the scenarios of a range search that returns a resultset as well as searches against nonexistent rows.
Key-Range Locking for Range Search
In this scenario, SQL Server places locks on the index pages for the range of data covered in the WHERE clause of the query. (For a clustered index, the rows would be the actual data rows in the table.) Because the range is locked, no other transaction will be able to insert new rows that fall within the range. In Figure 38.9, Transaction B tries to insert a row with a key value (stor_id = 7200) that falls within the range being used by Transaction A (stor_id between 6000 and 7500).
Figure 38.9. Key-range locking with range search.
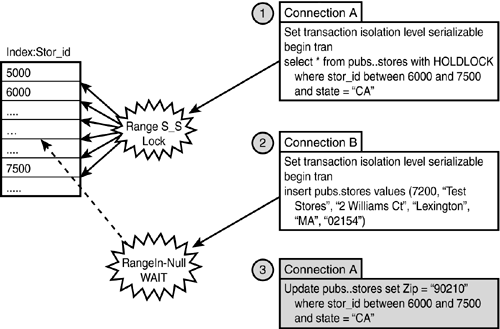
Now take a look at the locks acquired using the sp_lock stored procedure (in this sample output, spid 52 is executing the SELECT statement, and spid 54 is attempting the INSERT):
exec sp_lock
go
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- ---------------- -------- ------
52 5 117575457 1 KEY (36000050901c) RangeS-S GRANT
52 5 117575457 1 KEY (3700560a5b33) RangeS-S GRANT
52 5 117575457 1 KEY (ffffffffffff) RangeS-S GRANT
52 5 117575457 1 PAG 1:105 IS GRANT
52 5 117575457 1 KEY (3700f04c0158) RangeS-S GRANT
52 5 0 0 DB S GRANT
52 5 117575457 0 TAB IS GRANT
52 5 117575457 1 KEY (370087018ad1) RangeS-S GRANT
52 5 117575457 1 KEY (370011318da6) RangeS-S GRANT
52 5 117575457 1 KEY (38004ab7b2bc) RangeS-S GRANT
54 5 117575457 0 TAB IX GRANT
54 5 0 0 DB S GRANT
54 5 117575457 1 KEY (3700f04c0158) RangeIn- WAIT
54 5 117575457 1 PAG 1:105 IX GRANT
To provide key-range isolation, SQL Server places RangeS-S locks (shared lock on the key range and shared lock on the key at the end of the range) on the index keys for the rows with the matching values. It also places intent share (IS) locks on the page(s) and the table that contain the rows. The insert process acquires intent exclusive (IX) locks on the destination page(s) and the table. In this case, the insert process is waiting for a RangeIn-Null lock on the key range until the RangeS-S locks in the key range are released. As described earlier in this chapter, the RangeIn-Null lock is an exclusive lock on the range
between keys with no lock on the key. This is acquired because the insert process is attempting to insert a new store ID that has no associated key value.
Key-Range Locking When Searching Nonexistent Rows
In this scenario, if a transaction is trying to delete or retrieve a row that does not exist in the database, it still should not find any rows at a later stage in the same transaction with the same query. For example, in Figure 38.10, Transaction A is trying to fetch a nonexistent row with the key value 7200, and another concurrent transaction (Transaction B) is trying to insert a record with the same key value (stor_id = 7200).
Figure 38.10. Key-range locking with a nonexistent dataset.
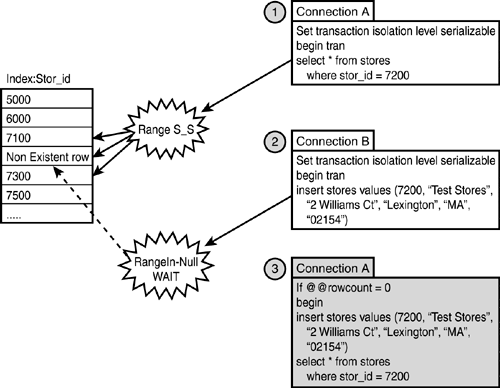
SQL Server in this mode will prevent Transaction B (spid 54) from inserting a new row by using a RangeS-S lock for Transaction A (spid 52). This lock is placed on the index key rows for the rows in the range between MAX(stor_id) < 7200 (key value 7100 in Figure 38.10) and MIN(stor_id) > 7200 (key value 7300 in Figure 38.10). Transaction B will hold a RangeIn-NULL lock and wait for the RangeS-S lock to be released.
Following is the sample output of the sp_lock command for these two transactions:
Exec sp_lock
Go
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- ---------------- -------- ------
52 5 117575457 1 KEY (36000050901c) RangeS-S GRANT
52 5 117575457 1 KEY (3700560a5b33) RangeS-S GRANT
52 5 117575457 1 KEY (ffffffffffff) RangeS-S GRANT
52 5 117575457 1 PAG 1:105 IS GRANT
52 5 117575457 1 KEY (3700f04c0158) RangeS-S GRANT
52 5 0 0 DB S GRANT
52 5 117575457 0 TAB IS GRANT
52 5 117575457 1 KEY (370087018ad1) RangeS-S GRANT
52 5 117575457 1 KEY (370011318da6) RangeS-S GRANT
52 5 117575457 1 KEY (38004ab7b2bc) RangeS-S GRANT
54 5 117575457 0 TAB IX GRANT
54 5 0 0 DB S GRANT
54 5 117575457 1 KEY (3700f04c0158) RangeIn- WAIT
54 5 117575457 1 PAG 1:105 IX GRANT
Using Application Locks
The SQL Server Lock Manager knows nothing about the object or the structure of the object it is locking. The actual resources are represented only as strings. (This information can be seen in the rsc_text field in syslockinfo.) The Lock Manager simply checks to see if two processes are trying to obtain incompatible locks on the same resource. If so, blocking will occur.
SQL Server 2000 allows you to extend the resources that can be locked beyond the ones automatically provided. You can define your own custom locking resources and let the Lock Manager control the access to those resources as it would for any resource in a database. This essentially allows you to choose to lock anything you want. These user-defined lock resources are called application locks. To define an application lock, you use the sp_getapplock stored procedure and specify a name for the resource you are locking, a mode, an optional lock owner, and an optional lock timeout interval. The syntax for sp_getapplock is as follows:
sp_getapplock [ @Resource = ] 'resource_name', [ @LockMode = ] 'lock_mode' [ , [ @LockOwner = ] { 'transaction' | 'session' } ] [ , [ @LockTimeout = ] 'value' ]
Two resources are considered to be the same resource and are subject to lock contention if they have the same name and the same lock owner in the same database. The resource name used in these procedures can be any identifier up to 255 characters long. The lock owner can be specified as either transaction or session. Multiple requests for locks on the same resource can be granted only if the locking modes of the requests are compatible. (See the "Lock Compatibility" section later in this chapter for a lock compatibility matrix.) The possible modes of the lock allowed are Shared, Update, Exclusive, IntentExclusive, and IntentShared.
For what purpose can you use application locks, and how do you use them? Suppose you have a table that contains a queue of items to be processed by the system. You need a way to serialize the retrieval of the next item from the queue so that the multiple concurrent processes do not grab the same item at the same time. In the past, one way this could be accomplished was by forcing an exclusive lock on the table. (The use of table hints to override default locking behavior is covered in the "Table Hints for Locking" section later in this chapter.) Only the first process to acquire the exclusive lock would be able to retrieve the next item from the queue. The other processes would have to wait until the exclusive lock was released. The problem with this approach is that the exclusive lock would also block other processes that might need to simply retrieve data from the table.
You could make use of application locks to avoid having to place an exclusive lock on the entire table. Using sp_getapplock, you can define and lock a custom lock resource for a transaction or session. Locks that are owned by the current transaction are released when the transaction commits or rolls back. Locks that are owned by the session are released when the session is closed. Locks can also be explicitly released at any time with the sp_releaseapplock stored procedure. The syntax for sp_releaseapplock is as follows:
sp_releaseapplock [ @Resource = ] 'resource_name'
[ , [ @LockOwner = ] { 'transaction' | 'session' }]
NOTEIf a process calls sp_getapplock multiple times for the same lock resource, sp_releaseapplock must be called the same number of times to fully release the lock. In addition, if sp_getapplock is called multiple times on the same lock resource, but it specifies different lock modes each time, the resulting lock on the resource is a union of the different lock modes. Generally, the lock mode ends up being promoted to the more restrictive level of the existing lock mode and the newly requested mode. The resulting lock mode is held until the last lock release call is made to fully release the lock. For example, assume a process initially called sp_getapplock requested a shared lock. If it subsequently called sp_getapplock again and requested an exclusive lock, an exclusive lock would be held on the resource until sp_releaseapplock were executed twice. |
In the following example, you first request an exclusive lock on an application lock called 'QueueLock' by using sp_getapplock. You then invoke the procedure to get the next item in the queue. After the procedure returns, you call sp_releaseapplock to release the application lock called 'QueueLock' to let another session acquire the application lock:
sp_getapplock 'QueueLock', 'Exclusive', 'session' exec get_next_item_from_queue sp_releaseapplock 'QueueLock', 'session'
As long as all processes that need to retrieve items from the queue execute this same sequence of statements, no other process can execute the get_next_item_from_queue process until the application lock is released. The other processes will block attempts to acquire the exclusive lock on the resource 'QueueLock'. For example, the following output from sp_lock shows one process (spid 55) holding an exclusive lock on QueueLock (the hash value generated internally for QueueLock is shown as Queu1e2eefa9 in the Resource field), while another process (spid 52) is waiting for an exclusive lock on QueueLock:
sp_lock
go
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- ---------------- -------- ------
51 4 0 0 DB S GRANT
52 8 0 0 DB S GRANT
52 8 0 0 APP Queu1e2eefa9 X WAIT
53 1 85575343 0 TAB IS GRANT
53 8 0 0 DB S GRANT
55 8 0 0 DB S GRANT
55 8 0 0 APP Queu1e2eefa9 X GRANT
CAUTIONThis method of using application locks to control access to the queue will work only as long as all processes that are attempting to retrieve the next item in the queue follow the same protocol. The get_next_item_from_queue procedure itself is not actually locked. If another process attempted to execute the get_next_item_from_queue process without attempting to acquire the application lock first, the Lock Manager in SQL Server would not prevent the sesssion from executing the stored procedure. |
Index Locking
Similar to locks on the data pages, SQL Server manages locks on index pages internally. Compared to data pages, there is the opportunity for greater locking contention in index pages. Contention at the root page of the index is the highest because the root is the starting point for all searches via the index. Contention usually decreases as you move down the various levels of the B-tree, but it is still higher than contention at the data page level due to the typically greater number of index rows per index page than data rows per data page.
If locking contention in the index becomes an issue, SQL Server provides a system-stored procedure called sp_indexoption that allows expert users to manage the locking behavior at the index level. The syntax of this stored procedure is as follows:
Exec sp_indexoption {[@IndexNamePattern = ] 'index_name'}[,
[@OptionName = ] 'option_name'] [,
[@OptionValue = ]'value']
The following describes the parameter values:
index_name is the name of the table or a specific index name on the table.
option_name can be one of the following four values:
AllowRowLocks? When set to false, this will prevent any row-level locking on the index pages. Only page- and table-level locks will be applied.
AllowPageLocks? When set to false, this will prevent page-level locks. Only row- or table-level locks will be applied.
DisAllowRowLocks? When set to true, this will prevent any row-level locking on the index pages. Only page- and table-level locks will be applied.
DisAllowPageLocks? When set to true, this will prevent page-level locks. Only row- or table-level locks will be applied.
value can be true or false for the specified option_name parameter.
SQL Server usually makes good choices for the index locks, but based on the distribution of data and nature of the application, you might want to force a specific locking option on a selective basis. For example, if you are experiencing a high level of locking contention on index pages of an index, you might want to force SQL Server to use row-level locks by turning off page locks. If you turn off both row and page locks, only table-level locks will be acquired.
The following example turns off page-level locking for index pages on an index named aunmind for the authors table:
Exec sp_indexoption 'authors.aunmind', 'AllowPageLocks', false
NOTENote that these options are available only for indexes. SQL Server provides no mechanism for globally controlling the locking on data pages for a table at the table level. However, if a table has a clustered index, the data pages are essentially the leaf level of the clustered index. The locking methods used on the data pages will be affected by the options set with sp_indexoption. |
Row-Level Versus Page-Level Locking
For years, it was often debated whether row-level locking was better than page-level locking. That debate still goes on in some circles. Many people will argue that if databases and applications are well designed and tuned, row-level locking is unnecessary. This can be borne out somewhat by the number of large and high-volume applications that were developed when row-level locking wasn't even an option. (Prior to version 7, the smallest unit of data that SQL Server could lock was at the page level.) However, at that time, the page size in SQL Server was only 2K. With page sizes expanded to 8K, a greater number of rows (four times as many) can be contained on a single page. Page-level locks on 8K pages could lead to greater page-level contention because the likelihood of the data rows being requested by different processes residing on the same page is greater. Using row-level locking increases the concurrent access to the data.
On the other hand, row-level locking consumes more resources (memory and CPU) than page-level locks, simply because there are a greater number of rows in a table than pages. If a process needed to access all rows on a page, it would be more efficient to lock the entire page than acquire a lock for each individual row. This would result in a reduction in the number of lock structures in memory that the Lock Manager would have to manage.
Which is better?greater concurrency or lower overhead? As shown earlier in Figure 38.8, it's a tradeoff. As lock size decreases, concurrency improves, but performance degrades due to the extra overhead. As the lock size increases, performance improves due to less overhead, but concurrency degrades. Depending on the application, the database design, and the data, either page-level or row-level locking can be shown to be better than the other in different circumstances.
SQL Server will make the determination at runtime?based on the nature of the query, the size of the table, and the estimated number of rows affected?of whether to initially lock rows, pages, or the entire table. In general, SQL Server attempts to first lock at the row level more often, than the page level, in an effort to provide the best concurrency. With the speed of today's CPUs and the large memory support, the overhead of managing row locks is not as expensive as in the past. However, as the query processes and the actual number resources locked exceed certain thresholds, SQL Server might attempt to escalate locks from a lower level to a higher level as appropriate.
Lock Escalation
When SQL Server detects that the locks acquired by a query are using too much memory and consuming too many system resources for the Lock Manager to manage the locks efficiently, it will automatically escalate row, key, or page locks to table-level locks. For example, as a query on a table continues to acquire row locks and every row in the table eventually will be accessed, it makes more sense for SQL Server to escalate the row locks to a table-level lock. After the table-level lock is acquired, the row-level locks are released. This helps reduce locking overhead and keeps the system from running out of available lock structures. Recall from earlier sections in this chapter that the potential need for lock escalation is reflected in the intent locks that are acquired on the table by the process locking at the row or page level.
NOTEIf another process is also holding locks at the page or row level on the same table (indicated by the presence of that process's intent lock on the table), lock escalation cannot take place if the lock types are not compatible until the lower-level locks by the other processes are released. In this case, SQL Server will continue acquiring locks at the row or page level until the table lock becomes available. |
What are the lock escalation thresholds? They are determined dynamically and do not require user configuration. When the number of locks acquired within a transaction exceeds 1,250, or when the number of locks acquired by an index or table scan exceeds 765, the Lock Manager examines how much memory is currently being used by all locks in the system. When more than 40 percent of the available memory is being used for locks, the Lock Manager attempts to escalate multiple page, key, or row locks to table locks. SQL Server attempts to identify all tables that are locking at the row or page level that are capable of escalation (that is, no other processes hold incompatible locks on other pages or rows in the table) for which escalation has not yet been performed. This will continue until all possible lock escalations have taken place, or the total memory used for locks drops to below 40 percent.
At times, SQL Server might choose to do both row and page locking for the same query. For example, if a query returns multiple rows, and enough contiguous keys in a nonclustered index page are selected to satisfy the query, SQL Server might place page locks on the index while using row locks on the data. This reduces the need for lock escalation.
The locks Configuration Setting
As mentioned previously, the total number of locks available in SQL Server is dependent on the amount of memory available for the lock structures. This is controlled by the locks configuration option for SQL Server. By default, this option is set to 0, which allows SQL Server to allocate and deallocate lock structures dynamically based on ongoing system requirements. Initially, SQL Server allocates 2 percent of the total memory allocated to SQL Server to the lock structure pool. Each lock structure consumes 64 bytes of memory, and each held or waiting lock on the resource requires an additional 32 bytes of memory.
As the pool of locks is exhausted, additional lock structures are allocated up to a maximum of 40 percent of the memory currently allocated to SQL Server. If more memory is required for locks than is currently available to SQL Server, and more server memory is available, SQL Server will allocate additional memory from the operating system dynamically. Doing so will satisfy the request for locks as long as the allocation of the additional memory does not cause paging at the operating system level. If paging were to occur, more lock space would not be allocated, and SQL Server would essentially run out of locks. In addition, the transaction would be aborted, and the user would see a message like the following:
Server: Msg 1204, Level 19, State 1, Line 1 The SQL Server cannot obtain a LOCK resource at this time. Rerun your statement when there are fewer active users or ask the system administrator to check the SQL Server lock and memory configuration.
It is recommended that you leave the locks configuration setting at 0 to allow SQL Server to allocate lock structures dynamically. If you repeatedly receive error messages that you have exceeded the number of available locks, you might want to override SQL Server's ability to allocate lock resources dynamically by setting the locks configuration option to a value large enough for the number of locks needed. Because each lock structure requires 96 bytes of memory, be aware that setting the locks option to a high value might result in an increase in the amount of memory dedicated to the server. For more information on changing SQL Server configuration options, see Chapter 40, "Configuring, Tuning, and Optimizing SQL Server Options."







