Database Files and Filegroups
Databases are divided into logical 8KB pages. Within each file allocated to a database, the pages are numbered contiguously from 0 to n. The actual number of pages in the database file depends on the size of the file. Pages in a database are uniquely referenced by specifying the database ID, the file ID for the file the page resides in, and the page number within the file. When you expand a database with ALTER DATABASE, the new space is added at the end of the file and the page numbers continue incrementing from the previous last page in the file. If you add a completely new file, its first page number will be 0. When you shrink a database, pages are removed from the end of the file only, starting at the highest page in the database and moving toward lower-numbered pages until the database reaches the specified size or a used page that cannot be removed. This ensures that page numbers within a file are always contiguous.
Databases in SQL Server 2000 span at least two, and optionally several, database files. There must always be at least one file for data and one file for the transaction log. These database files are normal operating system files created in a directory within the operating system. These files are created when the database is created or when a database is expanded. The maximum size allowed for a database or log file is 32TB.
Each database file has the following set of properties:
A logical filename?This is used for internal reference to the file.
A physical filename?This is the actual physical pathname of the file.
An initial size?If no size is specified for primary data file, its initial size by default is the minimum size required to hold the contents of the model database.
An optional maximum size.
A file growth increment specified in megabytes or as a percentage.
The information and properties about each file for a database are stored in the database system catalog table called sysfiles. This table exists in every database and contains information about each of the database files. Table 33.1 lists the columns in the sysfiles table.
| Column Name | Description |
|---|---|
| fileid | The file identification number that is unique within each database. |
| groupid | Identification of the filegroup to which the file belongs. |
| size | Size of the file (in pages). |
| maxsize | The maximum size that the file can auto-grow to. 0 means that the file does not auto-grow beyond its initial size; -1 means that the file can auto-grow until the disk is full. The auto-grow feature is described in the following section. |
| growth | Auto-growth increment in either pages or a percentage of the file size. |
| status | A bitmap field containing status information about the file. The values are described in Table 33.2. |
| perf | Reserved for future use. |
| name | The logical name of the file. |
| filename | The physical name of the file, including path. |
| Status Value | Description |
|---|---|
| 2 | Disk file. |
| 64 | Log device. |
| 128 | The file has had information written to it since the last backup of the file or database. |
| 16384 | The file was implicitly created when the database was created (that is, no explicit name or size was specified in the CREATE DATABASE statement). |
| 32768 | The file was created during the database creation. |
| 1048576 | The growth value specified is a percentage rather than the number of pages to grow when space is needed. |
Every database can have three types of files:
Primary data file
Secondary data files
Log files
Primary Data File
Every database has one and only one primary database file. The location of the primary database file is stored in the filename column in the sysdatabases table in the master database. When SQL Server starts up a database, it looks for this file and then reads from the file header the information on the other files defined for the database.
The primary database file contains the sysfiles system table, which stores information on all other database files for the database. The sysfiles table is a virtual table (exists in memory only) that gets its information from the primary file header and cannot be updated directly. This table contains the current information and status on the database files. There is also an undocumented system table called sysfiles1 that is a real table that also stores the logical and physical filename for all database files. This table can be modified (for instance, if you wanted to change the logical filename associated with a database file. Standard disclaimer: Modifying system tables directly is strongly discouraged!).
CAUTIONThere is some concern that if you lose the primary data file for a database, you cannot back up the transaction log because SQL Server will not be able to find the transaction log files because the transaction log file information stored in the primary data file is lost. Fortunately, it appears that Microsoft addresses this issue by storing the database file information in the sysaltfiles table in the master database. According to Books Online, this table only stores database file information under special circumstances. However, whenever I've examined the contents of this table, it has always contained file information for every database in the server. Conceivably, this information is there so that in the event you do lose your primary data file, SQL Server will be able to determine where the log file resides and be able to back it up so that you don't lose the transactions stored in it. I have tested the capability of SQL Server to back up the log when the primary data file was no longer accessible, and it was able to still back up the log using the NO_TRUNCATE option. |
The file extension for the primary database file defaults to .mdf. The primary database file always belongs to the default filegroup. It is often sufficient to have only one database file for storing your tables and indexes (the primary database file). The file can, of course, be created on a RAID partition to help spread I/O. However, if you need finer control over placement of your tables across disks or disk arrays, or if you want to have the ability to back up only a portion of your database via filegroups, you can create additional, secondary data files for a database.
Secondary Data Files
A database can have any number of secondary files (well, in reality, the maximum number of files per database is 32,767, but that should be sufficient for most implementations). You can put a secondary file in the default filegroup or in another filegroup defined for the database. Secondary data files have a file extension of .ndf by default.
Here are some situations in which the use of secondary database files might be beneficial:
Disk partition size?Suppose that you have to create a database with a size of 8GB (log excluded). You have two 4GB disks for this purpose. You can create the database with two database files, each 4GB in size.
Partial backup?A backup can be performed for the entire database or a subset of the database. The subset is specified as a set of files or filegroups (you can no longer back up individual tables in SQL Server). The partial backup feature is useful for large databases, where it is impractical to back up the entire database. When recovering with partial backups, a transaction log backup must also be available. For more information about backups, see Chapter 16, "Database Backup and Restore."
Control over placement of database objects?When you create a table or index, you can specify the filegroup in which the object is created. This could help you spread I/O by placing your most active tables or indexes on separate filegroups that are defined on separate disks or disk arrays.
Creating multiple files on a single disk provides no real performance benefit but could help in recovery?If you have a 9GB database in a single file and have to restore it, you need to have enough disk space available to create a new 9GB file. If you don't have 9GB of space available on a single disk, you cannot restore the database. On the other hand, if the database was created with three files each 3GB in size, you more likely will be able to find several 3GB chunks of space available on your server.
The Log File
Each database has at least one log file. The log file contains the transaction log records of all changes made in a database (for more information on what is contained in the transaction log, see Chapter 31). By default, log files have a file extension of .ldf.
A database can have several log files, and each log file can have a maximum size of 32TB. A log file cannot be part of a filegroup. No information other than transaction log records can be written to a log file.
Regardless of how many physical files have been defined for the transaction log, SQL Server treats it as one contiguous file. The transaction log for a database is actually managed as a set of virtual log files (VLFs). The size of the VLFs is determined by SQL Server based on the total size of all the log files and the growth increment specified for the log. The log can only grow in units of an entire VLF at a time and can only be shrunk to a VLF boundary (see Figure 33.1).
Figure 33.1. The structure of a physical log file showing virtual log files (VLF).
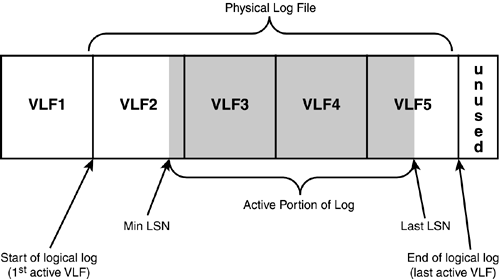
When the log file is shrunk, the unused VLFs at the end of the log file after the active portion of the log can be deleted and the size of the log file reduced. The virtual log files will be kept if they meet any of the following conditions:
If any part of the active portion of the log is contained in the VLF. The active portion of the log is the portion between the minimum Log Sequence Number (LSN) and the end of the log where the last LSN has been written (for more information on transaction logging and LSNs, see Chapter 31). These are considered active VLFs.
When the VLF contains records prior to the oldest active transaction that haven't been backed up yet and are needed for database recovery.
When log backups are not being maintained or the log has been backed up, the VLFs prior to the start of the logical log are kept to be reused when the log records reach the current end of the logical log. For example, VLF1 in Figure 33.1 is considered reusable. Figure 33.2 shows an example of the active portion of the log cycling around back to the reusable portion at the beginning of the log file.
Figure 33. Example of active portion of log cycling around to reusable VLF at beginning of log file.
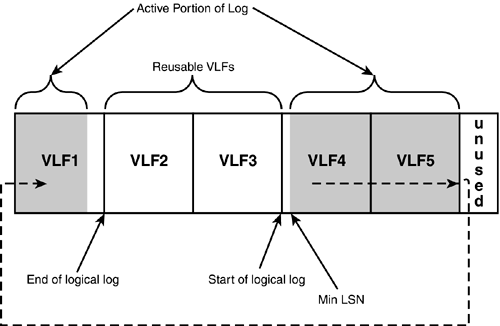
In environments where the log is not being maintained, SQL Server recycles the space at the beginning of the log file as soon as it reaches the end of the log file, as long as the records at the beginning of the log are before the start of the oldest active transaction. SQL Server assumes that the log is not being maintained when the log has been truncated, the database is in simple recovery mode (or the trunc. log on chkpt. option has been enabled), or you have never performed a full backup of the database.
If you have backed up the database and are keeping log backups, the reusable portion of the log prior to the LSN of the oldest active transaction cannot be overwritten or purged until it has actually been backed up.
If the log has not been backed up yet preventing the reusable portion from being overwritten, SQL Server grows the log file and adds more VLFs to it (as long as the log file is still configured to grow automatically). After the log has been backed up and the active portion of the log has wrapped around to the first VLF at the beginning of the log file, the VLFs at the end can be deleted and the log file can be shrunk back down.
Shrinking the Log File
Shrinking the log file in SQL Server 7.0 was often an exercise in frustration. Even after backing up or truncating the log, if any part of the active portion of the log was still on the last VLF in the file, the log file could not be shrunk until the active portion moved around to the front of the file. This is because physical shrinking of the log file can only take place from the end of the log file. To shrink the log file, you had to write a routine that would generate a bunch of dummy transactions that would eventually push the active portion of the log back around to the beginning of the file. At that point, you could truncate the log and shrink it to reduce it back down to its original size.
In SQL Server 2000, the log file can still only be shrunk from the end of the log file, but Microsoft addressed the problems that occurred in SQL Server 7.0. When you back up or truncate the log in SQL Server 2000, it automatically issues a series of NO-OP log records to force the active portion of the log back to the beginning of the log file. You can then run the DBCC SHRINKFILE or DBCC SHRINKDATABASE command to release the unused space in the log file.
If you want to determine how many VLFs are in the log file and which ones are active, you can use an undocumented DBCC command, DBCC LOGINFO. The syntax for DBCC LOGINFO is as follows:
DBCC LOGINFO [ ( dbname ) ]
Let's walk through an example to see how to use DBCC LOGINFO and at the same time see how log truncation and shrinking of the log file works.
NOTEThe following example, and others in this chapter, make use of the bigpubs2000 database. This database is available on the CD included with this book. Instructions on how to install the bipubs2000 database on your system are presented in the Introduction. |
First, create a test database to work with:
use master go create database logtest go The CREATE DATABASE process is allocating 0.63 MB on disk 'logtest'. The CREATE DATABASE process is allocating 0.49 MB on disk 'logtest_log'.
Next, configure the database for full recovery:
alter database logtest set recovery full go
Now, examine the log file with DBCC LOGINFO:
use logtest
go
DBCC LOGINFO
go
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN
------ -------- ----------- ------ ------ ------ ---------
2 253952 8192 43 2 64 0
2 253952 262144 0 0 0 0
(2 row(s) affected)
DBCC execution completed. If DBCC printed error messages,
contact your system administrator.
An active VLF is indicated by a status of 2. You can see at this point that there are two VLFs in the logtest database, each 253,952 bytes in size (the log file itself is .49MB), and only one of the VLFs is currently active. Now, create a table and populate it with some rows to generate some log records and examine the log again:
select top 10000 * into sales_test
from bigpubs2000..sales
go
dbcc loginfo
go
FileId FileSize StartOffset FseqNo Status Parity CreateLSN
------ ----------- ----------- ----------- ------ ------ -----------------
2 253952 8192 43 2 64 0
2 253952 262144 0 0 0 0
2 270336 516096 44 2 64 43000000047100002
2 262144 786432 45 2 64 44000000044500010
(4 row(s) affected)
DBCC execution completed. If DBCC printed error messages,
contact your system administrator.
You can see now that there are VLFs in the log and three of them are active (Status = 2). Now, try to shrink the log and re-examine:
dbcc shrinkfile (logtest_log)
dbcc loginfo
go
DbId FileId CurrentSize MinimumSize UsedPages EstimatedPages
------ ------ ----------- ----------- ----------- --------------
13 2 63 63 56 56
(1 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN
------ ----------- ----------- ----------- ------- ------ -----------
2 253952 8192 47 2 64 0
2 253952 262144 46 0 128 0
(2 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
Because you have not backed up the database yet, and there were no active transactions, SQL Server assumes that you do not need to keep the inactive portion of the log, removes it, and shrinks the file back down. Now, back up the database to indicate that you want to maintain the backups:
backup database logtest to disk='c:\winnt\temp\logtest.bak' go Processed 168 pages for database 'logtest', file 'logtest' on file 5. Processed 1 pages for database 'logtest', file 'logtest_log' on file 5. BACKUP DATABASE successfully processed 169 pages in 0.317 seconds (4.344MB/sec).
Run a command to generate some log records again and re-examine the log:
set rowcount 1000
go
begin tran
delete sales_test
rollback
go
set rowcount 0
go
dbcc loginfo
go
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN
------ ---------- ----------- ------ ------ ------ -------------------
2 253952 8192 47 2 128 0
2 253952 262144 46 0 64 0
2 270336 516096 48 2 64 47000000013600531
(4 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
Notice that there are now three VLFs, and two are marked as active (Status = 2). Now try to shrink the log:
dbcc shrinkfile (logtest_log)
go
Cannot shrink log file 2 (logtest_log) because all logical log files are in use
DbId FileId CurrentSize MinimumSize UsedPages EstimatedPages
------ ------ ----------- ----------- ----------- --------------
13 2 128 63 128 56
(1 row(s) affected)
DBCC execution completed. If DBCC printed error messages,
contact your system administrator.
It fails because the last VLF in the file is still active, and SQL Server cannot shrink from the end of the file. If we perform another transaction, the log continues to grow:
set rowcount 5000
go
begin tran
delete sales_test
rollback
go
set rowcount 0
go
dbcc loginfo
go
(5000 row(s) affected)
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN
------ --------------- -------------- ------ ------ ------ ------------------
2 253952 8192 47 2 128 0
2 253952 262144 46 0 64 0
2 270336 516096 48 2 64 47000000013600531
2 262144 786432 0 0 0 48000000013600531
2 262144 1048576 0 0 0 48000000025600533
2 262144 1310720 49 2 64 48000000037600533
2 262144 1572864 0 0 0 49000000001600391
2 262144 1835008 52 2 64 49000000010400531
2 262144 2097152 51 2 64 49000000022400533
2 262144 2359296 50 2 64 49000000034400533
(10 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
The log cannot be shrunk at this point because the VLFs are marked as needed for recovery. The space cannot be reclaimed until the log is backed up or truncated:
backup log logtest with truncate_only
dbcc loginfo
go
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN
------ --------------- ----------------- ------ ------ ------ -----------------
2 253952 8192 47 0 128 0
2 253952 262144 46 0 64 0
2 270336 516096 48 0 64 47000000013600531
2 262144 786432 0 0 0 48000000013600531
2 262144 1048576 0 0 0 48000000025600533
2 262144 1310720 49 0 64 48000000037600533
2 262144 1572864 0 0 0 49000000001600391
2 262144 1835008 52 2 64 49000000010400531
2 262144 2097152 51 0 64 49000000022400533
2 262144 2359296 50 0 64 49000000034400533
(10 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
Now that the VLFs have been marked as no longer needed (the log records have either been truncated or backed up to disk), the log file can be shrunk:
dbcc shrinkfile(logtest_log)
dbcc loginfo
go
DbId FileId CurrentSize MinimumSize UsedPages EstimatedPages
------ ------ ----------- ----------- ----------- --------------
13 2 63 63 56 56
(1 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN
------ -------------- ----------------- ------ ------ ------ -----------------
2 253952 8192 54 2 64 0
2 253952 262144 53 0 128 0
(2 row(s) affected)
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
SQL Server provides a database option, autoshrink, that can be enabled to automatically shrink the log and database files when space is available at the end of the file. If you are regularly backing up or truncating the log, the autoshrink option keeps the size of the log file in check. The auto-shrink process runs about every 30 minutes and determines whether the log file can be shrunk. The log manager keeps track of how much log space is used within the 30-minute interval. The auto-shrink process then shrinks the log to the larger of 125 percent of the maximum log space used or the minimum size of the log (the minimum size is the size the log was created with or the size it has been manually increased or decreased to).
CAUTIONThe auto-shrink feature has been reported to result in some performance degradation, likely due to the additional monitoring required. It is recommended that instead of using auto-shrink, you should shrink the database manually or create a scheduled task to shrink the database or log file periodically during off-peak times. |
Using Filegroups
All databases have a primary filegroup that contains the primary data file. There can be only one primary filegroup. If you don't create any other filegroups or change the default filegroup to a filegroup other than the primary filegroup, all files will be in the primary file group unless specifically placed in another filegroup.
In addition to the primary filegroup, you can add one or more filegroups to the database and a filegroup can contain one or more files. The main purpose of using filegroups is to provide more control over the placement of files and data on your server. When you create a table or index, you can map it a to a specific filegroup, thus controlling the placement of data. A typical SQL Server database installation generally uses a single RAID array to spread I/O across disks and create all files in the primary filegroup; more advanced installations or installations with very large databases spread across multiple array sets can benefit from the finer level of control of file and data placement afforded by additional filegroups.
For example, for a simple database such as pubs, you can create just one primary file that contains all data and objects and a log file that contains the transaction log information. For a larger and more complex database, such as a securities trading system where large data volumes and strict performance criteria are the norm, you might create the database with one primary file and four additional secondary files. You can then set up filegroups so you can place the data and objects within the database across all five files. If you have a table that itself needs to be spread across multiple disk arrays for performance reasons, you can place multiple files in a filegroup, each of which resides on a different disk, and create the table on that filegroup. For example, you can create three files (Data1.ndf, Data2.ndf, and Data3.ndf) on three disk arrays, respectively, and then assign them to the filegroup called spread_group. Your table can then be created specifically on the filegroup spread_group. Queries for data from the table will be spread across the three disk arrays, thereby improving I/O performance.
If a filegroup contains more than one file, when space is allocated to objects stored in that filegroup, the data is stored proportionally across the files. In other words, if you have one file in a filegroup with twice as much free space as another, the first file will have two extents allocated from it for each extent allocated from the second file (extents and space allocation will be discussed in more detail later in this chapter).
Listing 33.1 provides an example of using filegroups in a database to control the file placement of the customer_info table.
Listing 33.1 Using a Filegroup to Control Placement for a Table
CREATE DATABASE Customer
ON ( NAME='Customer_Data',
FILENAME='D:\SQL_data\Customer_Data1.mdf',
SIZE=50,
MAXSIZE=100,
FILEGROWTH=10)
LOG ON ( NAME='Customer_Log',
FILENAME='F:\SQL_data\Customer_Log.ldf',
SIZE=50,
FILEGROWTH=20%)
GO
ALTER DATABASE Customer
ADD FILEGROUP Cust_table
GO
ALTER DATABASE Customer
ADD FILE
( NAME='Customer_Data2',
FILENAME='E:\SQL_data\Customer_Data2.ndf',
SIZE=100,
FILEGROWTH=20)
TO FILEGROUP Cust_Table
GO
USE Customer
CREATE TABLE customer_info
(cust_no INT, cust_address NCHAR(200), info NVARCHAR(3000))
ON Cust_Table
GO
The CREATE DATABASE statement in Listing 33.1 creates a database with a primary database file and a log file. The first ALTER DATABASE statement adds a filegroup.
A secondary database file is added with the second ALTER DATABASE command. This file is added to the Cust_Table filegroup.
The CREATE TABLE statement creates a table; the ON Cust_Table clause places the table in the Cust_Table filegroup (the Customer_Data2 file on the E: disk partition).
The sysfilegroups database system table contains information about the database filegroups defined within a database, as shown in Table 33.3.
| Column Name | Description |
|---|---|
| groupid | The filegroup identification number. Unique within the database. |
| allocpolicy | Reserved for future use. |
| status | 0x8 indicates read-only; 0x10 indicates the default filegroup. |
| groupname | Name of the filegroup. |
The following statement returns the filename, size in MB (not including auto-grow), and the name of the filegroup to which each file belongs:
SELECT name, size/128, groupname
FROM sysfiles sf INNER JOIN sysfilegroups sfg
ON sf.groupid = sfg.groupid
go
name groupname
------------------ ----------- -----------------
Customer_Data 50 PRIMARY
Customer_Data2 100 Cust_table
On-Demand Disk Management
In SQL Server 2000, you can specify that a database file should grow automatically as space is needed. SQL Server can also shrink the size of the database if the space is not needed. You can control whether you use this feature along with the increment by which the file is to be expanded. The increment can be specified as a fixed number of megabytes or as a percentage of the current size of the file. You can also set a limit on the maximum size of the file, or allow it to grow until no more space is available on the disk.
Listing 33.2 provides an example of a database being created with a 10MB growth increment for the first database file, 20MB for the second, and 20 percent growth increment for the log file.
Listing 33.2 Creating a Database with Auto Growth
CREATE DATABASE Customer
ON ( NAME='Customer_Data',
FILENAME='D:\SQL_data\Customer_Data1.mdf',
SIZE=50,
MAXSIZE=100,
FILEGROWTH=10),
( NAME='Customer_Data2',
FILENAME='E:\SQL_data\Customer_Data2.ndf',
SIZE=100,
FILEGROWTH=20)
LOG ON ( NAME='Customer_Log',
FILENAME='F:\SQL_data\Customer_Log.ldf',
SIZE=50,
FILEGROWTH=20%)
GO
The Customer_Data file has an initial size of 50MB, a maximum size of 100MB, and a file increment of 10MB.
The Customer_Data2 file has an initial size of 100MB, a file growth increment of 20MB, and can grow until the E: disk partition is full.
The transaction log has an initial size of 50MB; the file increases by 20 percent with each file growth. The increment is based on the current file size, not the size originally specified.







