User Requirements Drive the Replication Design
As mentioned before, it is really the business requirements that will drive your replication configuration and method. You also will find that nailing down all the details to the business requirement is the hardest part of a data replication design process. After you have com-pleted the requirements gathering, the replication design usually just falls out from it easily. The requirements gathering is highly recommended to get a prototype up and running as quickly as possible to measure the effectiveness of one approach over the other. You must understand several key aspects to make the right design decisions. These include the following:
What is the number of sites and site autonomy in the scope [location]?
Which ones have the "master" data [data ownership]?
What is the data latency requirement [by site]?
What type of data accesses are being made [by site]?
Reads
Writes
Updates
Deletes
This needs to include exactly what data and data subsets that drive filtering are needed for the data accesses [by site].
What is the volume of activity/transactions, including the number of users [by site]?
How many machines do you have to work with [by site]?
What is the available processing power (CPU & Memory), and disk space on each of these machines [by site]?
What is the stability, speed, and saturation level of the network connections between machines [by site]?
What is the dial-in, Internet, or other access mechanism requirement for the data?
What are the potential subscriber or publisher database engines involved?
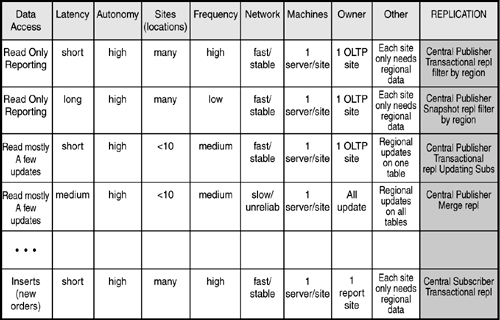
Figure 22.22 depicts the factors that contribute to replication designs and the possible data replication configuration that would best be used. It is only a partial table because of the numerous factors and the many replication configuration options that are available. However, it will give you a good idea of the general design approach described here. Perhaps 95 percent of user requirements can be classified fairly easily. It is those last 5 percent that might take some imagination in determining the best overall solution. Depending on the requirements that need to be supported, you might even end up with a solution using something like log shipping. We will discuss this limited alternative in a later section.
Figure 22.22. Replication design factors.
Data Characteristics
Additionally, you need to analyze the underlying data types and characteristics thoroughly. Issues such as collation or character set and data sorting come into play. You must be aware of what these are set to on all nodes of your replication configuration. MS SQL Server 2000 does not convert the replicated data and might even mistranslate the data as it is replicated because it is impossible to map all characters between character sets. It is best to look up the character set "mapping chart" for MS SQL Server replication to all other data target environments. Most are covered well, but problems arise with certain data types such as image, timestamp, and identity. Sometimes, using the Unicode data types at all sites is best for consistency. Following is a general list of things to watch out for in this regard:
Collation consistency across all nodes of replication.
Timestamp column data in replication. It might not be what you think.
Identity, Uniqueidentifier, and GUID column behavior with data replication.
Text or Image data types to heterogeneous subscribers.
Missing or nonsupported data types because of prior versions of SQL Server or Heterogeneous Subscribers as part of the replication configuration.
Maximum row size limitations between merge replication and transactional replication (6000 bytes versus 8000 bytes, respectively).
If you have triggers on your tables and you want them to be replicated along with your table, you might want to revisit them and add a line of code reading NOT FOR REPLICATION so that the trigger code isn't executed redundantly on the subscriber side.







