Transaction Logging and the Recovery Process
Every SQL Server database has its own transaction log that keeps a record of all data modifications in a database (insert, update, delete) in the order in which they occur. This information is stored in one or more log files associated with the database. The information stored in these log files cannot be modified or viewed effectively by any user process.
SQL Server uses a write-ahead log. The buffer manager guarantees that changes are written to the transaction log before the changes are written to the database. The buffer manager also ensures that the log pages are written out in sequence so that transactions can be recovered properly in the event of a system crash.
The following is an overview of the sequence of events that occurs when a transaction modifies data:
Write a BEGIN TRAN record to the transaction log in buffer memory.
Write data modification information to transaction log pages in buffer memory.
Write data modifications to the database in buffer memory.
Write a COMMIT TRAN record to the transaction log in buffer memory.
Write transaction log records to transaction log file(s) on disk.
Send a COMMIT acknowledgement to the client process.
The end of a typical transaction is indicated by a COMMIT record in the transaction log. The presence of the COMMIT record indicates that the transaction must be reflected in the data-base or be redone if necessary. A transaction that is aborted during processing by an explicit rollback or a system error will automatically undo the changes made by the transaction.
Notice that the data records are not written to disk when a COMMIT occurs. This is done to minimize disk I/O. All log writes are done synchronously to ensure that the log records are physically written to disk and written in the proper sequence. Because all modifications to the data can be recovered from the transaction log, it is not critical that data changes be written to disk right away. Even in the event of a system crash or power failure, the data can be recovered from the log if it hasn't been written to the database.
SQL Server ensures that the log records are written before the affected data pages by recording the Log Sequence Number (LSN) for the log record making the change on the modified data page(s). Modified, or "dirty," data pages can only be written to disk when the LSN recorded on the data page is less than the LSN of the last log page written to the transaction log.
When and how are the data changes written to disk? Obviously, they must be written out at some time, or it would take forever for SQL Server to start up if it had to redo all transactions in the log. Also, how does SQL Server know during recovery which transactions to reapply, or "roll forward," and which transactions to undo, or "roll back." The following section looks at the mechanisms involved in the recovery process.
The Checkpoint Process
During recovery, SQL Server examines the transaction log for each database and verifies whether the changes reflected in the log are also reflected in the database. In addition, it examines the log to determine if any data changes were written to the data that were caused by a transaction that didn't complete before the system failure.
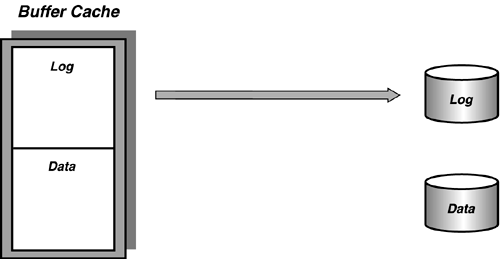
As discussed earlier, a COMMIT writes the log records for a transaction to the transaction log (see Figure 31.1). Dirty data pages are written out either by the Lazy Writer process or the checkpoint process. The Lazy Writer process runs periodically to check whether the number of free buffers has fallen below a certain threshold, reclaims any unused pages, and writes out any dirty pages that haven't been referenced recently. (For more information on the Lazy Writer process and SQL Servers I/O architecture, see Chapter 33, "SQL Server Internals.")
Figure 31.1. A commit writes all "dirty" log pages from cache to disk.
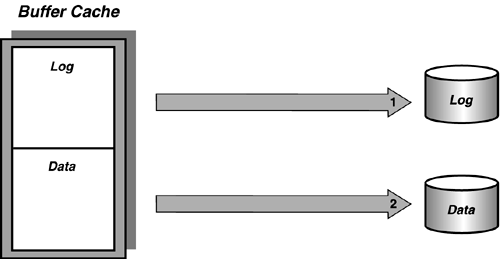
The checkpoint process also scans the buffer cache periodically and writes all dirty log pages and dirty data pages to disk (see Figure 31.2). The purpose of the checkpoint is to sync up on disk the data with the changes recorded in the transaction log. Typically, the checkpoint process finds little work to do because most dirty pages have been written out previously by the worker threads or lazywriter process.
Figure 31.2. A checkpoint writes log pages from cache to disk, and then writes all "dirty" data pages.
The following list outlines the steps that SQL Server performs during a checkpoint:
-
Writes a record to the log file to record the start of the checkpoint.
-
Writes the LSN of the start of the checkpoint log records to the database boot page. (This is so SQL Server can find the last checkpoint in the log during recovery.)
-
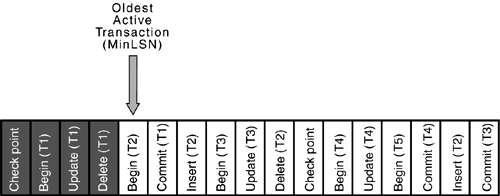
Records the Minimum Recovery LSN (MinLSN), which is the first log image that must be present for a successful database-wide rollback. The MinLSN is either the LSN of the start of the checkpoint, the LSN of the oldest active transaction, or the LSN of the oldest transaction marked for replication that hasn't yet been replicated to all subscribers.
-
Writes a list of all outstanding, active transactions to the checkpoint records.
-
Writes all modified log pages to the transaction log on disk.
-
Writes all dirty data pages to disk. (Data pages that have not been modified are not written back to disk to save I/O.)
-
Writes a record to the log file indicating the end of the checkpoint.
Figure 31.3 shows a simplified version of the contents of a transaction log after a checkpoint. (For simplicity, the checkpoint records are reflected as a single log entry.)
Figure 31.3. A simplified view of the end of the transaction log with various completed and active transactions, as well as the last checkpoint.
The primary purpose of a checkpoint is to reduce the amount of work the server needs to do at recovery time to redo or undo database changes. A checkpoint can occur under the following circumstances:
When a checkpoint statement is executed explicitly for the current database.
When ALTER DATABASE is used to change a database option. ALTER DATABASE automatically checkpoints the database when database options are changed.
When an instance of SQL Server is shut down gracefully by either executing the SHUTDOWN statement or by stopping the SQL Server service.
When SQL Server periodically generates automatic checkpoints in each database to reduce the amount of time the instance would take to recover the database.
Automatic Checkpoints
The frequency of automatic checkpoints is determined by the setting of the recovery interval for SQL Server. However, the decision to perform a checkpoint is based on the number of records in the log, not a period of time. The time interval between the occurrence of automatic checkpoints can be highly variable. If few modifications are made to the database, the time interval between automatic checkpoints could be quite long. Conversely, automatic checkpoints can occur quite frequently if the update activity on a database is high.
The recovery interval does not state how often an automatic checkpoint should occur. It is actually an estimate of the amount of time it would take SQL Server to recover the database by applying the number of transactions recorded since the last checkpoint. By default, the recovery interval is set to 0, which means SQL Server will determine the appropriate recovery interval for each database. It is recommended that you keep this setting unless you notice that checkpoints are occurring too frequently and are impairing performance. Try increasing the value in small increments until you find one that works well. Just be aware: The higher you set the recovery interval, the fewer checkpoints will occur, but the database will likely take longer to recover following a system crash.
If the database is using either the full or bulk-logged recovery model, an automatic checkpoint occurs whenever the number of log records reaches the number that SQL Server estimates it can process within the time specified by the recovery interval option.
If the database is using the simple recovery model or if the truncate log on checkpoint option is enabled, an automatic checkpoint occurs whenever the log becomes 70 percent full or the number of log records reaches the number that SQL Server estimates it can process within the time specified by the recovery interval option. If using the simple recovery model, the automatic checkpoint also truncates the unused portion of the transaction log prior to the oldest active transaction.
The Recovery Process
When SQL Server is started, it verifies that completed transactions recorded in the log are reflected in the data, and that incomplete transactions whose changes are reflected in the data are rolled back out of the database. This is the recovery process. Recovery is an automatic process performed on each database during SQL Server startup. Recovery must be completed before the database is made available for use.
The recovery process guarantees that all completed transactions recorded in the transaction log are reflected in the data, and all incomplete transactions reflected in the data are rolled back. During recovery, SQL Server looks for the last checkpoint record in the log. Only the changes that occurred or were still open since the last checkpoint need to be examined to determine the need to be redone (rolled forward) or undone (rolled back). After all the changes are rolled forward or rolled back as necessary, the database is checkpointed and recovery is complete.
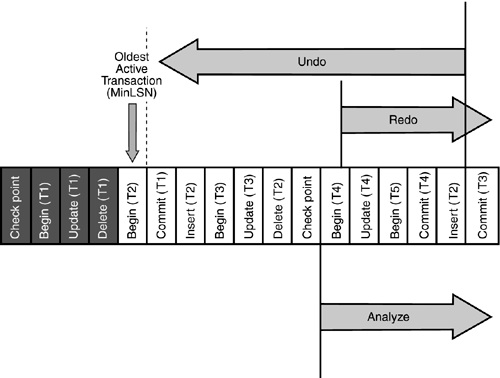
The recovery algorithm has three phases that are centered around the last checkpoint record in the transaction log, as shown in Figure 31.4.
Figure 31.4. The phases of the recovery process.
A description of these phases is as follows:
Analysis Phase?SQL Server reads forward from the last checkpoint record in the transaction log. This pass identifies a list of pages (the dirty page table, or DPT) that might have been dirty at the time of the system crash or when SQL Server was shut down, as well as a list of the uncommitted transactions at the time of the crash.
Redo (Roll Forward) Phase?During this phase, SQL Server rolls forward all the committed transactions recorded in the log since the last checkpoint. This phase returns the database to the state it was in at the time of the crash. The starting point for the redo pass is the LSN of the oldest committed transaction within the DPT, so that only changes that were not previously checkpointed (only the committed "dirty" pages) are reapplied.
Undo (Roll Back) Phase?This phase moves backward from the end of the log to the oldest active transaction at the time of the system crash or shutdown. All transactions that were not committed at the time of the crash but that had pages written to the database are undone so that none of their changes are actually reflected in the database.
Now examine the transactions in the log in Figure 31.4 and determine how they will be handled during the recovery process:
Transaction T1 is started and committed prior to the last checkpoint. No recovery is necessary.
Transaction T2 started before the last checkpoint, but had not completed at the time of the system crash. The changes written out by the checkpoint process for this transaction will have to be rolled back.
Transaction T3 started before the last checkpoint and committed after the checkpoint prior to the system crash. The changes made to the data after the checkpoint will need to be rolled forward.
Transaction T4 started and committed after the last checkpoint. This entire transaction will need to be rolled forward.
Transaction T5 started after the last checkpoint, but no changes to the data were recorded in the log, so no data changes were written to the data. (Remember: Changes must be written to the log before they can be written to the data.) No undo action is required for this transaction.
In a nutshell, this type of analysis is pretty much the same analysis the recovery process would do. To identify the number of transactions rolled forward or rolled back during recovery, you can examine the SQL Server error log and look at the recovery startup messages for each database:
2001-06-13 17:07:00.06 spid8 Starting up database 'pubs'. 2001-06-13 17:07:00.07 spid9 Starting up database 'Northwind'. 2001-06-13 17:07:00.07 spid10 Starting up database 'bigpubs2000'. 2001-06-13 17:07:01.85 spid5 Clearing tempdb database. 2001-06-13 17:07:02.07 server SQL server listening on 10.244.174.172: 1533. 2001-06-13 17:07:02.07 server SQL server listening on 127.0.0.1: 1533. 2001-06-13 17:07:04.86 spid8 48 transactions rolled forward in database 'pubs' (5). 2001-06-13 17:07:05.03 spid8 0 transactions rolled back in database 'pubs' (5). 2001-06-13 17:07:05.33 spid8 Recovery is checkpointing database 'pubs' (5) 2001-06-13 17:07:06.10 spid5 Starting up database 'tempdb'. 2001-06-13 17:07:06.96 spid3 Recovery complete.







