Tables
One cornerstone of the relational database model is that there is only one structure that actually stores information in a relational database: the table.
A table is defined as a set of columns with certain properties, such as the datatype, nullability, constraints, and so on. Information about datatypes, column properties, constraints, and other information related to defining and creating tables can be found in Chapter 12.
Size Limits for Rows and Columns
As discussed earlier in this chapter, the maximum row size for a table is 8060 bytes. The maximum size for character and binary datatypes is 8000 bytes. Note, however, that the new Unicode datatypes require 2 bytes per character and thus require twice the amount of storage space as non-Unicode datatypes. This limits the size of NCHAR and NVARCHAR columns to 4000 characters. The maximum number of columns per table is 1024.
Heap Tables
A table without a clustered index is a heap table. There is no imposed ordering of the data rows for a heap table. Additionally, there is no direct linkage between the pages in a heap table.
In pre-7.0 versions of SQL Server, the data pages were doubly linked in a manner similar to that of a clustered table. To scan the table, SQL Server would look up the first page in the sysindexes table and then scan from that point forward, following the page pointers until it reached the last page in the table (m_nextPage = 0). Table scanning a linked chain of pages is more efficient when they are contiguous so that it reads the pages in file order, without having to hop around within the file to read the pages in linked page order. Unfortunately, the table could become fragmented over time. As rows were deleted, a whole page could be deallocated and reused, and likely linked into a different part of the page chain. This meant that SQL Server might have to go back and forth within the physical file when scanning the pages in the table sequence.
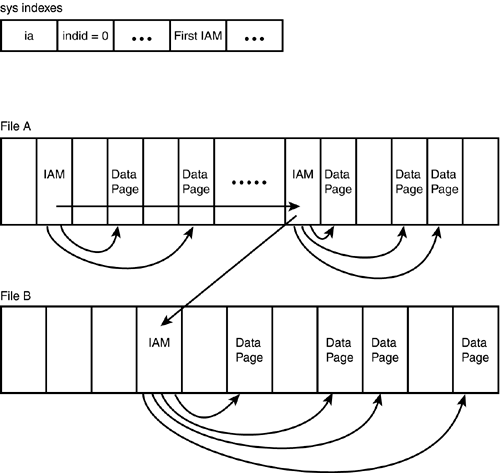
How, then, does SQL Server find all the data rows when it has to perform a table scan on a heap table? In SQL Server 2000, each heap table has at least one IAM (Index Allocation Map) page. The address of the first IAM page is stored in the sysindexes table (sysindexes.FirstIAM). The IAM page registers which extents are used by the table. SQL Server can then simply scan the allocated extents referenced by the IAM page, in physical order. This essentially avoids the problem of page chain fragmentation during reads because SQL Server will always be reading full extents in sequential order.
As discussed earlier, each IAM can map a maximum of 63,903 extents for a table. As a table uses extents beyond the range of those 63,903 extents, more IAM pages are created for the heap table as needed. A heap table also has at least one IAM page for each file on which the heap table has extents allocated. Figure 33.10 shows the structure of a heap table and how its contents are traversed using the IAM pages.
Figure 33.10. The structure of a heap table.
Clustered Tables
A clustered table is a table that has a clustered index defined on it. When you create a clustered index, the data rows in the table are physically sorted in the order of the columns in the index key. The data pages are chained together in a doubly linked list (each page points to the next page and to the previous page). Normally, data pages are not linked. Only index pages within a level are linked in this manner to allow for ordered scans of the data in an index level. Because the data pages of a clustered table constitute the leaf level of the clustered index, they are chained as well. This allows for an ordered table scan. The page pointers are stored in the page header in the m_nextPage and m_prevPage fields, as you've seen earlier with DBCC PAGE. Figure 33.11 shows an example of a clustered table. (Note that the figure shows only the data pages.)
Figure 33.11. A clustered table.








