Creating an OLAP Database
Remember: An OLAP database is made up of datasources, dimensions, and cubes. A datasource is simply a pointer to data somewhere, such as via a Jet OLE DB provider, an OLE DB provider, MSDataShape, MS Directory Services, and even DTS packages. Dimensions are constructed of columns from tables that you select that will be used to build and filter data cubes. Cubes are combinations of dimensions whose intersections contain strategically significant measures of business performance, such as quantities, units, and so on. Virtual cubes are joins of regular cubes, but they don't use storage space. (Virtual cubes are analogous to views in SQL Server.) You can join cubes this way with no more than one dimension in common. In addition, linked cubes are the way you include cube data from remotely defined OLAP cubes. You will need to identify any datasources on which your OLAP cube will now be based.
Adding a Datasource
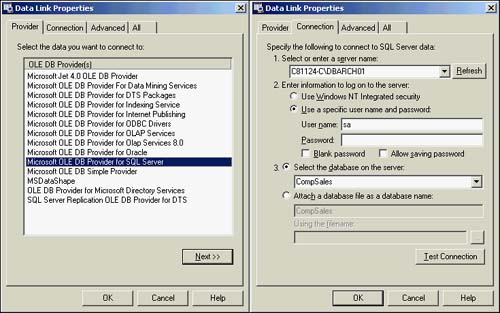
To add datasources for this database, expand the database you have created (CompSales in your example) and right-click the Data Sources subfolder. The Choose New Data Source dialog box opens. Again, you can get the same menu by highlighting Data Sources and clicking Action on the Management Console toolbar. Select the data provider you will be using for this datasource and click Next. Then specify all needed connection information for that datasource. In this example, you will be connecting to a database named CompSales using the sa user ID. Click the Test Connection button; it should report the message Test completed successfully. Figure 42.8 shows this Data Link Properties dialog box.
Figure 42.8. The Data Link Properties dialog box.
Adding Dimensions
You are now ready to start adding dimensions to your database. Dimensions are the building blocks for cubes in AS. Start by right-clicking Shared Dimensions in the CompSales database, right-click New Dimension, and select Wizard to open the Dimension Wizard. You will be welcomed to the Dimension Wizard, as shown in Figure 42.9. From there, you should probably just check the Skip This Screen in the Future box so that you are taken directly to the Dimension Creation screen the next time you come this way.
Figure 42.9. The Dimension Wizard welcome.
After you have reached the Dimension Creation screen, you will select the option Star Schema: A Single Dimension Table for the CompSales example. What you are saying is that you want to create a dimension and define its hierarchy from a single, star schema table. This is going to be from the CompSales star schema data mart that you are using as the basis of your cube. Many other options are available from which to choose, as shown in Figure 42.10. These other options can base the dimension and hierarchy from the following:
Snowflake schema?This contains multiple tables that are related to each other.
Parent-Child schema?This contains two related columns in a single table.
Virtual Dimension?This contains the member properties of other shared dimensions.
Mining Model?This contains the predictable column (node) of an OLAP mining model.
Figure 42.10. How to create the cube's dimension: Star Schema option.
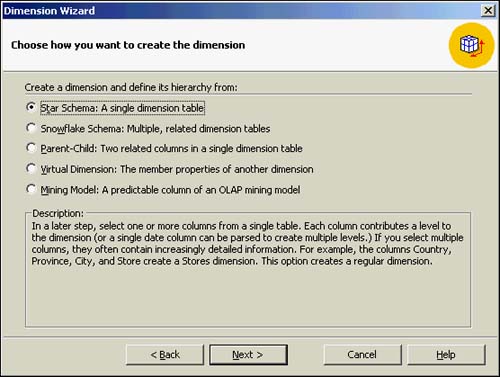
The CompSales requirement allows you to start from the Star Schema option.
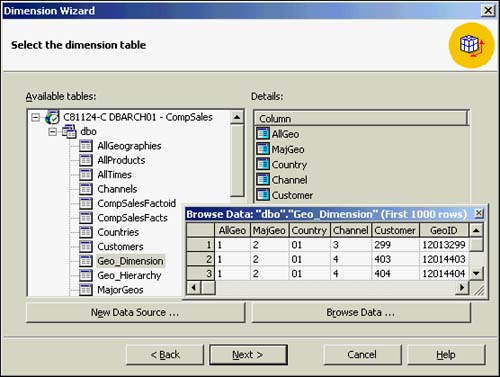
The wizard offers a Select the Dimension Table dialog box where you can add a new datasource and use its tables for this dimension or access existing datasources you have already defined. You will simply expand the CompSales datasource and select the Geo_Dimension table (of the CompSales data mart) as the basis of your current dimension. You can browse the first 1,000 rows of data here. Figure 42.11 shows this dialog box along with the data browsing of the current Geo_Dimension tables data.
Figure 42.11. Selecting the datasources for dimensions.
The next step is to select the dimension levels. In the CompSales example, you will select all levels of this data mart dimension table for this OLAP dimension hierarchy and in the order you want them to be based from top to bottom. Figure 42.12 shows this selection. Remember that each column will correspond to a level of this OLAP dimension.
Figure 42.12. Selecting the levels for a dimension.
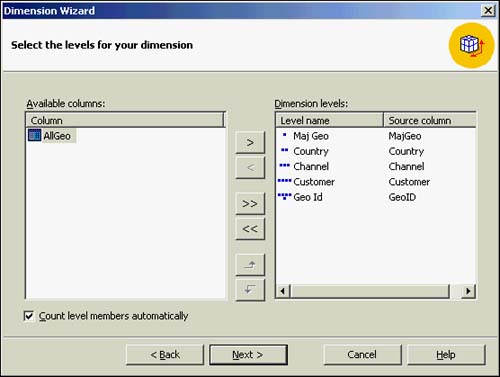
Next comes the Member Key Columns dialog box, as shown in Figure 42.13. Remember that members are the data values of the levels. In this example, the columns and the member name column are the same.
Figure 42.13. Specifying the keys for the level members.
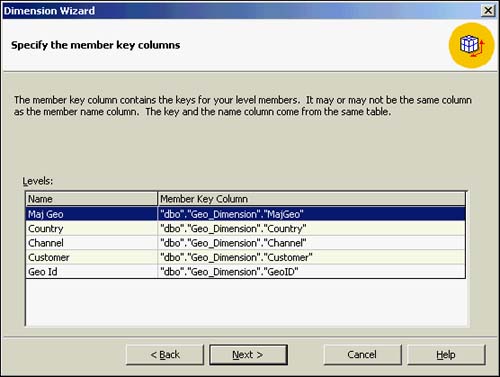
A few advanced options need to be specified for the dimension. Figure 42.14 shows the advanced options that might apply for this dimension definition. These options include the following:
Changing Dimension?This option allows members to change, update, or move without reprocessing the cube. This option is highly recommended.
Ordering and Uniqueness of Members?Ordering specifies member sorting (ascending, descending), and uniqueness specifies how unique the level keys and names are. This option is recommended.
Storage Mode and Member Groups?Storage mode determines the storage location for the dimension members. Member groups can be associated with a large level to facilitate navigation within a dimension. This method is optional.
Figure 42.14. Specifying advanced options for a dimension.
The Set Change Property dialog box should be set to Yes to indicate that you indeed want to allow additions, updates, and moves of members between levels without reprocessing the cube.
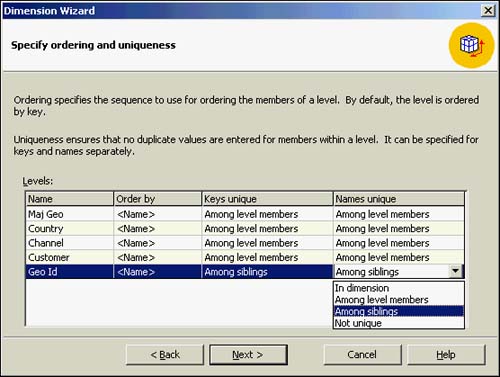
The Specify Ordering and Uniqueness dialog box (see Figure 42.15) allows you to specify, level-by-level, whether the following conditions occur:
The level keys are unique with the member level or within the entire dimension.
The names of the level members are unique among the level members, within the entire dimension, just among siblings, or not unique at all.
Whether you prefer to order the dimension levels by the names, keys, or based on the column. By default, the dimension levels will be ordered by keys.
Figure 42.15. Specifying ordering and uniqueness for dimensions.
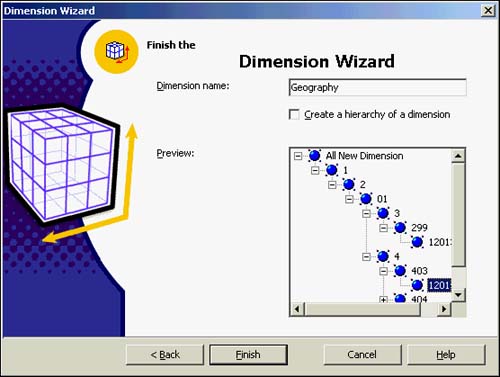
As you can see in Figure 42.16, the Dimension Wizard will display the final wizard dialog box allowing you to name the dimension and to preview the dimension levels. It also gives you a chance to create multiple-hierarchy dimensions if you need to provide similar, yet alternate views of the cube data. These hierarchies can be created for new or existing dimensions.
Figure 42.16. Finish the Dimension Wizard: Naming and Preview.
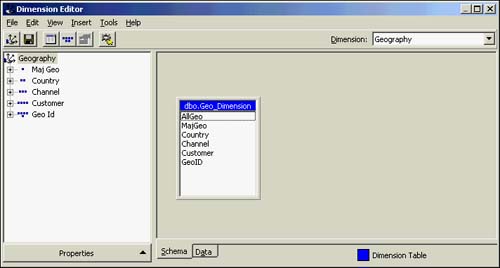
After this, you will be in the Dimension Editor, where you can create dimensions directly by adding tables, levels, and so on. You can also process the dimension here.
The upper-left pane of the Dimension Editor has the dimension structure hierarchy. Figure 42.17 shows the Dimension Editor with this dimension built. The right pane shows the tables that contribute to the dimension.
Figure 42.17. Dimension Editor showing the geography dimension.
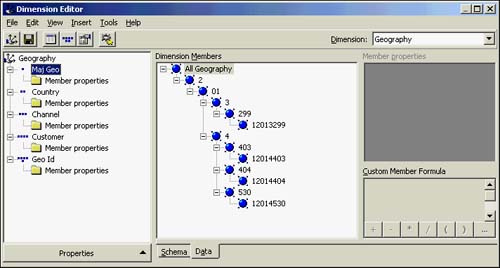
By going to the Data tab of the Dimension Editor, you can preview exactly what the dimension level's members will be. Before you can use this dimension, it must be processed and have real data populated from its datasource. Simply choose the Tools option pull-down menu and click on Process Dimension to execute this. Notice that you can also initiate a count of dimension members (which is stored as a property) and even do a dynamic validation of the dimension structure if you are editing it. Figure 42.18 shows the Data tab in the Dimension Editor of the processed dimension geography.
Figure 42.18. Data tab of the Dimension Editor.
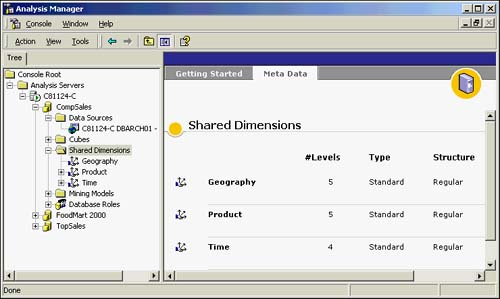
After closing all Dimension Editors, you can view all the shared dimensions from the main Analysis Manager console under the database in which you are working (CompSales in this example). Figure 42.19 shows that three shared dimensions have been created to reflect the requirements given to you (Geography, Product, and Time dimensions).
Figure 42.19. Meta Data view of Shared Dimensions: Geography, Product, and Time.
Building a Cube
Now that you have all of the dimensions that you need to fulfill your requirement, you can proceed to building the OLAP cube. This will entail defining the data measures you want in the cube along with the storage mode and aggregations you desire. As you can see from Figure 42.20, the Analysis Manager console shows no cubes defined for this database yet. The CompSales requirement will call for a regular cube that will be using the HOLAP storage mode to be created. To start the Cube Wizard, simply right-click the Cubes folder under a database (CompSales in your example) and select New Cube and Wizard.
Figure 42.20. AS console view of cubes: None created yet!
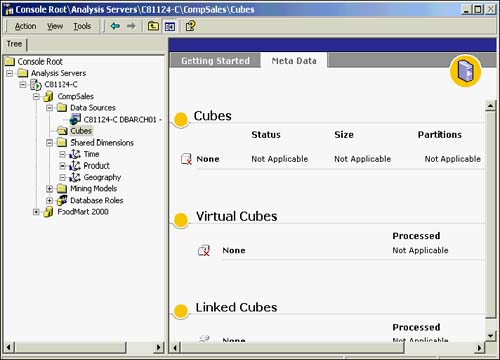
If it is your first time in the Cube Wizard, a Welcome dialog box will greet you. (You will want to check the box Skip This Screen in the Future so you won't have to see the Welcome dialog box on subsequent visits.) In creating a cube, you must have identified a "fact" table from which to base the measures. This fact table should correlate to each of the dimensions by which you intend to access the fact.
You must be able to get to this fact table via a datasource. If one is not yet defined, add it now. Figure 42.21 shows the Select a Fact Table From a Data Source dialog box. Your CompSales example calls for you to choose the CompSalesFactoid table as the basis of your fact (measure). For any table you choose, its data can be easily browsed here as well. Figure 42.21 also has the Browse Data window of this CompSalesFactoid table's data.
Figure 42.21. Selecting the datasource for a fact table and browsing data from that datasource.
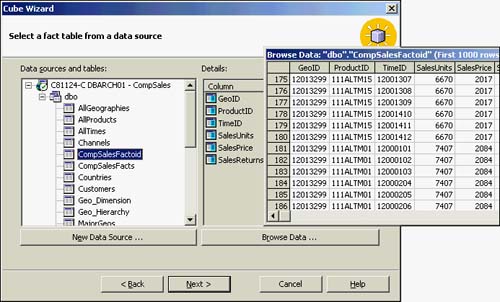
Measures
The Cube Wizard now prompts you to select the numeric columns that will define your data measures in this cube. The columns that meet the CompSales requirements are the Sales_units and Sales_returns columns of the CompSalesFactoid table. Figure 42.22 shows the cube measures as you have selected them and also shows a column that you did not choose (SalesPrice). SalesPrice was not in your requirements so it won't be selected here!
Figure 42.22. Identifying the numeric columns that define data measures.
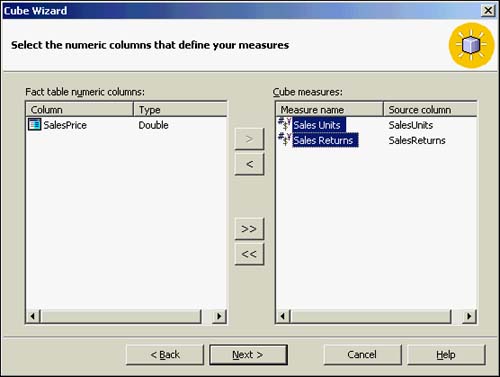
At this point, you must specify the dimensions that the cube will use for these data measures. Your CompSales requirement is calling for the measures to be accessed via all three of the dimensions you defined earlier. As you can see from Figure 42.23, you select these dimensions by making them the Cube dimensions. (From the Shared Dimensions list on the left, click on the > button to move them to the right side.)
Figure 42.23. Specifying all dimensions for the cube.
After you are finished, the Finish the Cube Wizard screen appears, which allows you to name the cube and shows you what you have defined (see Figure 42.24).
Figure 42.24. Finish the Cube: Cube name, Cube structure.
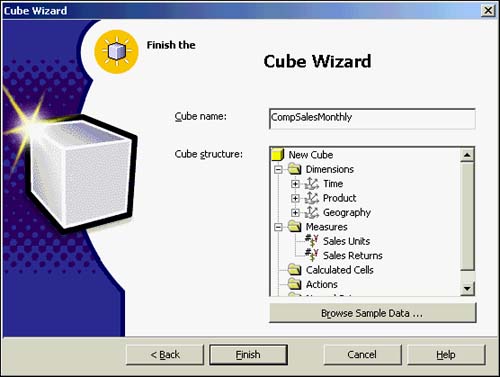
From the Finish the Cube Wizard dialog box, you can also browse sample data. Note that this is artificial data because the Cube has not been processed yet. Figure 42.25 illustrates this sample browsing in the Cube browser. Two out of the three dimensions are placed in the upper window pane of the Cube browser and can be manipulated easily for a particular level at which to view data. In addition, one dimension (the geography dimension in this example) has been chosen as the dimension in the lower (spreadsheet) portion of the Cube browser. The browser also displays the measures that you had defined in the Cube up to this point (sales units and sales returns). Again, remember that this data is artificial and does not reflect live data from your datasources yet. You have positioned the cube to look at product (SKU level) LTM01, for the time (year level) 1999. The geography dimension is positioned at the highest point (All Geography level).
Figure 42.25. Browsing sample data in a cube.
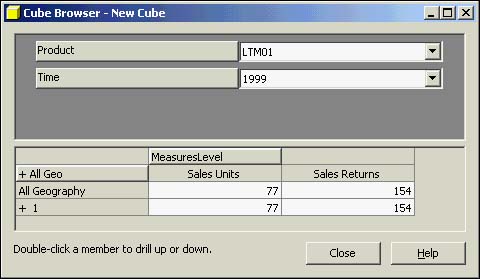
After the Cube Wizard finishes, it puts you automatically into the Cube Editor (see Figure 42.26). From here, you can see the physical schema on which this cube is based and also use the data browser to drill down into data. The schema diagram shows the relationships that are being used from the dimension tables to the fact table (the keys). This diagram is often the one I share with the end user and the programmers so that they understand how the facts in the cube are represented.
Figure 42.26. Cube Editor for CompSalesMonthly cube.
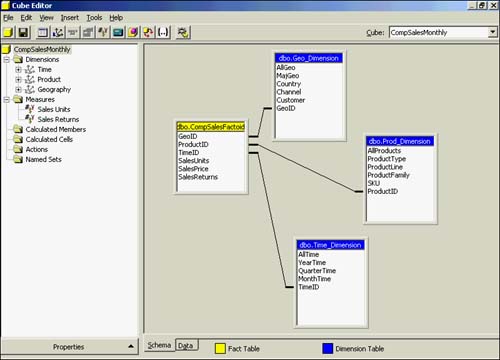
You must complete your requirements for this cube by adding a Calculated Member (measure) to this cube for net sales units. If you remember from the CompSales requirements, this value is the difference between sales units and sales returns (Sales_Units ? Sales_Returns). Calculated member definitions are automatically stored in the Measures parent dimension. These will behave just like a physical data measure except that they are just calculated from values or functions?including registered functions?that are physically stored for data measures or available for use for functions.
Calculated Members
To create a calculated member, right-click on the Calculated Member folder or choose it from the Tools option. This takes you into the Calculated Member Builder. To fulfill your CompSales requirement, you will need to create a value expression that reflects this difference calculation (Sales_Units ? Sales_Returns). Figure 42.27 illustrates how this is specified. You simply expand the Measures folder, choose the first measure you want as part of the calculation (double-clicking on it moves it into the Value Expression window). You then double-click on the minus sign (?) in the keypad for the difference calculation needed, followed by the other measure to complete the value expression. Many functions are available for use that should meet your individual calculation needs. Don't forget to name this new calculated member. (The new CompSales calculated member was named Net Sales Units.)
Figure 42.27. Calculated Member Builder.
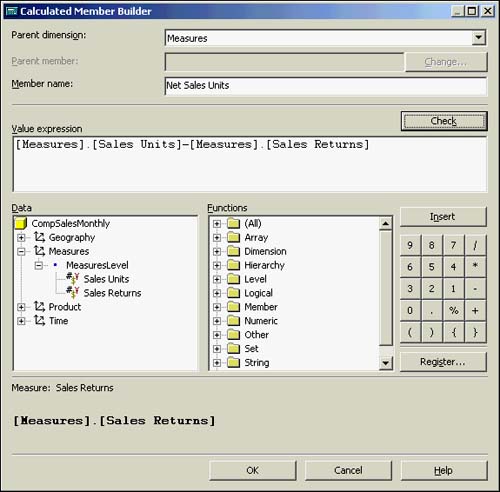
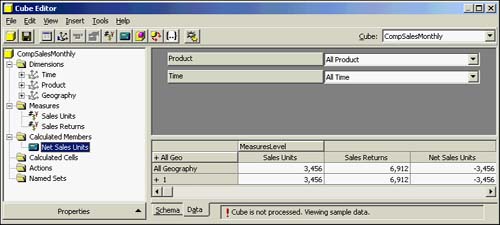
In the Cube Editor, choose the Data tab to see how this new calculated member will look. As you can see in Figure 42.28, the Net Sales Units reflects your calculation perfectly and appears as if it is just another data measure. This fulfills the data measure requirements of CompSales.
Figure 42.28. Cube Editor showing the newly created calculated member Net Sales Units.
All that is left to do is to design the storage for the cube and process the cube so others can use it. Here is where you decide on MOLAP, ROLAP, or HOLAP, and the degree of aggregation. The cube will physically be built differently based on these choices. If you choose to process the cube now, no storage decisions have been decided yet, so it will automatically force you to enter the Storage Design Wizard. So, why not go to this step directly?
Designing Storage
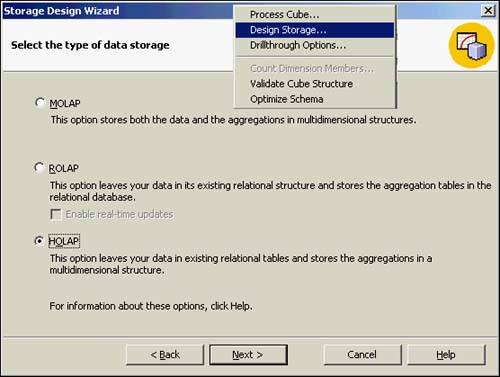
The initial Storage Design Wizard dialog box is where the primary storage method is decided. Your choices are MOLAP, ROLAP, or HOLAP storage. If you choose MOLAP, Analysis Services will build a complete multidimensional structure of detail facts, with the granularity based on the time dimension, other dimensions as you have defined them, and aggregations to the degree you select. ROLAP will use the fact table you identified in the source database and build new summary tables with dimension and fact data in the source database for aggregations. HOLAP will use the table you identified as the fact table in the source database for the detail facts and build and store the dimensions and aggregations on the Analysis Server. Figure 42.29 shows the initial Design Storage choice from the Tools menu, along with the three data storage options from which you can select. You had already decided that HOLAP made the most sense for this requirement so that you could leverage off of the existing relational fact table and also take advantage of the OLAP summary files generated by Analysis Services.
Figure 42.29. Storage Design Wizard: MOLAP, ROLAP, or HOLAP.
The next step is to specify the aggregation options. This determines how much data is to be aggregated and stored for use by the queries. The more you aggregate, the more disk space is required; however, you are also allowed to satisfy more queries from these aggregations. (Overall performance will be high, but disk usage will also be high.) The less aggregation you specify, the less disk space is needed; however, very few of the queries will be satisfied by the aggregations, and these will have to be performed online. (You will have less overall performance, but disk usage will be lower.) This decision is solely dependent on the following factors:
Available disk storage to this application
CPU power available to Analysis Services
Processing window of this aggregation
Additionally, the amount of memory available to AS is always a performance factor, but it is not considered during the aggregation storage options.
If your company has sales transaction data for the past 5 years and 250 stores that sell an average of 1,000 items per day, the fact table will have 456,500,000 rows. This is obviously a challenge in terms of disk space by itself without aggregation tables to go along with it. The control that Analysis Services provides here is important in balancing storage and retrieval speed (performance versus size). Aggregations are built to optimize rollup operations so that higher levels of aggregation are easily derived from the existing aggregations to satisfy broader queries. If a high degree of query optimization weren't possible because of limitations in storage space, Analysis Services might choose to build aggregates of monthly or quarterly data only. If a user queried the cube for yearly or multiyear data, those aggregations would be created dynamically from the highest level of pre-aggregated data. With disk storage becoming cheaper and servers becoming more powerful, the tendency here is to opt for meeting performance gains. A recommended approach is to specify between 80?90 percent performance gain here. Figure 42.30 shows the number of aggregations that will be built to support a 100 percent performance gain selection (seven aggregations designed for your cube).
Figure 42.30. Number of aggregation options that can be designed for this cube.
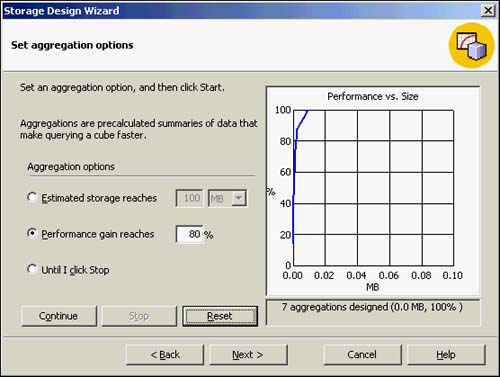
In the Set Aggregation Options dialog box (again, refer to Figure 42.30), you could also run the Aggregation Designer and watch the graph, stopping the aggregation level when you reach a point where you are comfortable. You will notice that the performance gain might begin to flatten out at a certain point. This relies on the accuracy of the Analysis Services data estimates; however, there is a point of diminishing returns in using disk space. Going beyond this point gets you increasingly less performance for the space used.Because you can tune individual queries, you might want to cut off aggregations at a point when optimization begins to flatten out, and then tune your queries based on observation as the cube is used.
You can choose to process these aggregations now or later depending on when the cube needs to be materialized. You will certainly be reprocessing it as the data changes over time.
Processing a Cube
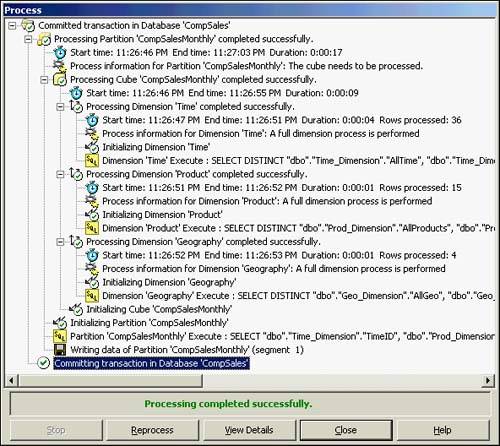
For the CompSales?CompSalesMonthly cube, you will choose to process now. You will be thrown into a Process dialog window and actually be able to follow the entire initialization process from start to finish. This includes the SQL statements executed against the datasources needed to generate your cube's dimensions. Depending on the amount of aggregation, this might actually take a while. At the end, all of the generated data will be committed and your cube will be processed. Figure 42.31 shows the CompSales Process dialog window.
Figure 42.31. Process cube information dialog window.
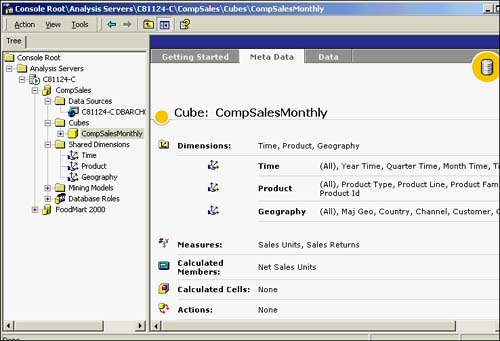
Now you have a data cube that can be browsed from the Analysis Manager's Cube Data browser with its built-in drill-down features. Of course, this can also be browsed via the Cube Editor, Data tab. Figure 42.32 shows the completed cube view from the Analysis Manager with all of its components in place.
Figure 42.32. Meta Data view of CompSalesMonthly cube.
Using the Pivot Table Service, you can write custom client applications using Multidimensional Extensions (MDX) with OLE DB for OLAP or ActiveX Data Objects Multidimensional (ADO MD). You can also use a number of third-party OLE DB for OLAP-compliant tools to access the cube.
Browsing a Data Cube from the Analysis Manager
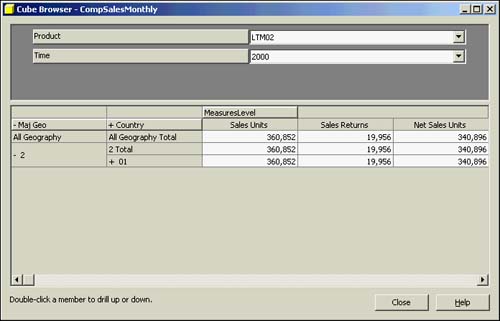
The Cube browser isn't a robust end user analysis tool, and it only exists on the server side. To browse data in your cube, right-click on your cube in the appropriate database (CompSales database, CompSalesMonthly cube in this example). The Cube browser opens and presents aggregated data. In Figure 42.33, the product and time dimension are in the top pane and the geography dimension and the measures (including the calculated member) are in the lower pane that looks like a spreadsheet. It is easy to move around the cube by simply drilling down deeper into each dimension to the place you want to view the data. The measure data will always reflect the data that is at the intersection of all the dimensions at the same time. In the CompSales example, it is showing measure data for Product (SKU) LTM02, for Time (year) 2000, and in Geography (MajGeo) 01.
Figure 42.33. Cube browser of CompSalesMonthly cube.
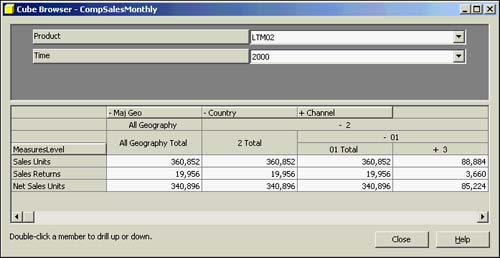
In the Cube browser, you can drag dimensions and measures around to change the column and row headings, depending on your preference. Double-clicking Dimension Data drills down into that dimension to lower levels of granularity. Figure 42.34 shows measures along the left side of the spreadsheet, with the geography dimension along the top (the columns).
Figure 42.34. Cube browser with data measures as rows in the spreadsheet.
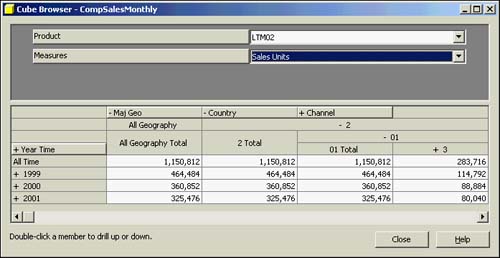
You can also drag and drop the dimension in the upper pane to become part of the lower pane spreadsheet. Figure 42.35 shows the geography and time dimensions in the spreadsheet, with measures as the selectable option in the top pane (showing Sales Units data only).
Figure 42.35. Cube browser with geography and time dimensions as the rows and columns of the spreadsheet.
The Cube browser shows you what your cube has in it, but also illustrates the utility of a dimensional database. Users can easily analyze data in meaningful ways. The data can also be "mined" by intelligent applications to find hidden relationships and patterns in the data that could have significant business implications.
Analysis Manager allows you to browse individual dimension data as well. Right-click the store dimension and select Browse Dimension. The Dimension browser opens with All. Expanding each level gets you to more detailed information as you move down the dimension hierarchy.
OLE DB for OLAP and ADO MD expose the interfaces to do this kind of data browsing, and many leading vendors have used these interfaces to build front-end analysis tools and ActiveX controls. These tools should prove useful for developers of user interfaces in data warehousing and data mart projects.
Query Analysis and Optimization
In the Analysis Manager, you can look at query utilization and performance in a cube. You can look at queries by user, frequency, and execution time to determine how to better optimize aggregations. If a slow-running query is used frequently by many users, or by the CEO, it might be a good candidate for individual tuning. The Analysis Manager allows you to adjust aggregations based on a query to reduce response time.
The Optimization dialog boxes will allow you to filter queries by user, frequency of execution, time frame, and execution time. You will see a record for each query you have run since the date you began, the number of times it was executed, and the average execution time in seconds. This is like a SQL trace analysis of your OLAP queries.
Because aggregations already exist, the wizard will ask whether you want to replace them or add new ones. If you replace the existing aggregations, the cube will be reprocessed with this particular query in mind.
Partitioning a Cube
Cube partitioning is another powerful feature of Microsoft Analysis Services. It allows you to deal with individual "slices" of a data cube separately, querying only the relevant datasources. If you partition by dimension, you can perform incremental updates to change that dimension independently of the rest of the cube. Consequently, you only have to reprocess aggregations affected by those changes. This is an excellent feature for scalability.
The ability to use multiple datasources is a key feature of Analysis Services because it allows you to access data on clusters of servers, retrieving only what you need from each server to satisfy the request for information. The storage methods can be different on each datasource; the only constraint is that the dimensions and facts are logically compatible in the different sources.
Separating the dimensions allows Analysis Services to query only the datasources that contain the slice of data that was requested.
In Advanced Options, you will get a dialog box that allows you to filter the data in the partition with a WHERE clause and to assign a prefix to the aggregation table names to distinguish them from existing aggregation tables if the ROLAP storage mode is used.
Merge combines the aggregations back into the original partition.
With well-designed partitions, a cube can be updated incrementally when it is reprocessed because the partition can be updated independently.
Creating a Virtual Cube
As mentioned previously, a virtual cube is a logical join of physical cubes; it doesn't store data. Virtual cubes are easy to build and provide great data visibility across multiple regular cubes. From within a database, invoke the New Virtual Cube Wizard from the Action menu option. Then perform the following:
-
Select the cubes to include in the virtual cube.
-
Select the measures for the virtual cube.
-
Select one or more dimensions for the virtual cube.
-
Name the virtual cube and choose when to process it. You can choose to process it now or later.
That's it. You will be able to change the virtual cube or view its data via the Virtual Cube Editor.








