Database Files
SQL Server needs to keep track of the allocated space in each data file; it does so by allocating special pages in the first extent of each file. As the data stored on these pages is dense and they are accessed often, they are usually found in memory; therefore, they are quickly retrieved.
The first page (page 0) in every file is the File Header Page. This page contains information about the file, such as the database to which the file belongs, the file group it is in, the minimum size, and its growth increment.
The second page (page 1) in each file is the Page Free Space (PFS) page. As its name implies, the PFS tracks free space available on the pages in a file. The PFS tracks whether a page has been allocated to an object, if it is on a mixed or uniform extent, and approximately how much free space remains. A single PFS can track 8,000 contiguous pages, and additional PFS pages are allocated as needed.
The third page (page 2) in each file is the Global Allocation Map, or GAM page. This page tracks allocated extents. Each GAM tracks 63,904 extents, and additional GAM pages are allocated as needed. The GAM contains a bit for each extent, which is set to 0 if the extent is allocated to an object, or 1 if it is free.
The fourth page (page 3) is the Secondary Global Allocation Map, or SGAM. The SGAM tracks allocated mixed extents. Each SGAM tracks 63,904 mixed extents, and additional SGAM pages are allocated as needed. A bit set to 1 for an extent indicates a mixed extent with pages available.
Primary Files
Every database will have a primary file. The primary file is the first file specified in the create database statement. It contains the system objects copied from the model database. These system objects are referred to as the database catalog. The primary file is generally identified by an .mdf file extension, although SQL Server does not enforce this.
The primary data file can, and often is, the only data file in the database. If this is the case, then all user objects will share the file with the database catalog or system tables.
Secondary Files
For performance, backup, and recovery purposes, additional data files can be created to store user objects separately from the database catalog. When additional files are created in the database, they are referred to as secondary data files. Secondary files, by default, are identified with an .ndf extension, but as with the primary file, this is not enforced. Additional files are added to accommodate storage needs greater than the size of the primary data file. By adding secondary data files, storage can be spread over multiple disks to improve IO and facilitate backing up large databases on a file-by-file basis. Allowing the database administrator to add files where and when needed to increase storage capacity also increases flexibility.
Using Filegroups
Filegroups provide for the logical grouping of files. The primary data file or files will always reside in the Primary filegroup. Additional filegroups can consist of one or more secondary files and are used to further delineate the storage of data, especially in large databases. When a filegroup consists of multiple files, SQL Server spreads the data inserts proportionally across all files in the filegroup so they are kept approximately the same percentage full. If your computer has multiple processors, it can also be advantageous to spread data across as many physical drives as possible in order to improve parallel data access throughput.
TIPIf too many outstanding I/Os are causing bottlenecks in the disk I/O subsystem, you might want to consider spreading the files across more disk drives. Performance Monitor can identify these by monitoring the PhysicalDisk object and Disk Queue Length counter. Consider spreading the files across multiple disk drives if the Disk Queue Length counter is greater than three. For more information on monitoring SQL Server performance, see Chapter 37, "Monitoring SQL Server Performance." |
For example, a filegroup called Data could be created, consisting of three files spread over three physical drives. Another filegroup could be created named Index, with a single file on a fourth drive. Now when tables are created, they can be specified to be stored on the Data filegroup, and indexes will be stored on the Index filegroup. This will reduce con-tention between tables because the data is spread over three disks and between data and indexes as well. If more storage is required in the future, additional files can easily be added to the Index or Data filegroup as appropriate.
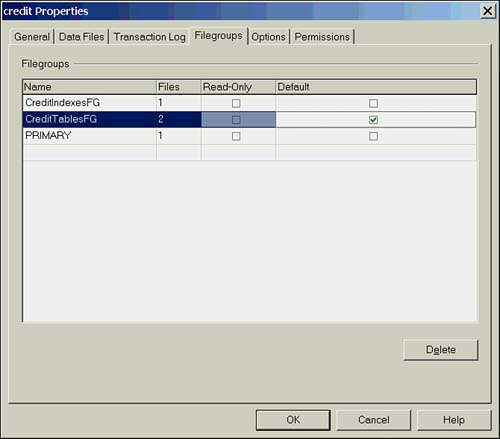
When using multiple filegroups, one filegroup will always be the default. This is not to be confused with the primary filegroup, although the primary filegroup is initially the default. If an object is created without a filegroup specified in the create statement, it will be stored on the default filegroup. If you are using two filegroups to separate the database catalog from the user objects, it would be appropriate to make the user object filegroup the default. If you have more than two filegroups, you will still have to specify where to store objects during creation because the choice for a "default" location might not be obvious. The default filegroup can be changed with the ALTER DATABASE command:
ALTER DATABASE Big_DB MODIFY FILEGROUP User_Data DEFAULT
Alternatively, it can be set from the database Properties page Filegroups tab, as illustrated in Figure 11.1.
Figure 11.1. Changing the default filegroup in Enterprise Manager.
Transaction Log File
Each database also requires a transaction log file. This log file typically has an extension of .ldf, but once again, this is not enforced. Multiple log files can be specified; however, this is rarely done because the files will always be accessed serially; as one file fills, it switches to the next. Therefore, no performance benefit is realized because multiple data files exist. Multiple log files simply extend the potential size of the log.
Unlike data files, the log file doesn't perform IO in 8KB pages; rather, SQL Server flushes individual records of transactions being processed to log changes to data on disk as quickly as possible. As it is essential that the transaction information be flushed to the log file as quickly as possible, the log can be contentious for disk resources and, if at all possible, should be located on a disk subsystem separate from other database and server activity.
The Function of the Transaction Log
SQL Server is what is known as a write-ahead database management system. This means that as changes are made to the data through transactions, these changes are written immediately to the transaction log file once the transaction is completed. By writing each change to the transaction log before it is written to the database, SQL Server can increase IO efficiency to the data files and ensure data integrity in case of system failure.
As SQL Server performs IO to the data files in 8KB pages, it would be inefficient to flush an entire 8KB page from memory to disk every time a change was made to the page, especially because a transaction could modify the data on a page multiple times. Instead, it records to the transaction log only the changes made to the data. Because the change information for the page is now safely written to the transaction log file on disk, SQL Server doesn't have to immediately write the data page back to disk to preserve the changes. Periodically, a process called checkpoint runs to ensure that changed pages in memory have actually been written back to the data files. This is more efficient because it can then piggyback several page writes, making the "trip" to the disk more efficient. When checkpoint has written all the changed or "dirty" pages to the data files, it makes a note in the transaction log that all changes made up to that point have actually been flushed to the data files. If the system fails, when it is restarted, an automatic recovery process can use this checkpoint marker as a starting point for recovery. SQL Server examines all transactions after the checkpoint. If they are committed transactions, they are "rolled forward"; if they are incomplete transactions, they are "rolled back," or undone.
For more detailed information on transaction management, transaction log internals, and the recovery process, see Chapter 31, "Transaction Management and the Transaction Log," and Chapter 33.







