Understanding the Analysis Services Environment and the 'Land of Wizards'
Welcome to the "land of wizards." This implementation of Analysis Services is heavily wizard oriented. AS has a Cube Wizard, Dimension Wizard, Partition Wizard, Incremental Update Wizard, Storage Design Wizard, Usage Analysis Wizard, Usage-Based Optimization Wizard, Calculated Cells Wizard, Action Wizard, Virtual Cube Wizard, Mining Model Wizard, and Security Roles Wizard. All are useful, and many of the capabilities are also available through editors of one kind or another. The wizard approach helps many who need to have a little structure in the definition process (and who want to rely on the default for much of what they need).
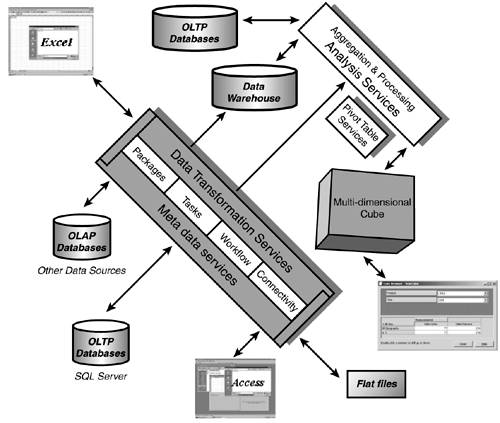
Figure 42.2 depicts how AS fits into the overall scheme of SQL Server 2000. AS has become a natural outgrowth of the baseline capabilities of SQL Server. Utilizing many different mechanisms, such as Data Transformation Services and direct datasource access capabilities, a vast amount of data can be funneled into the AS environment. Most of the cubes that you will build are read-only because they should be in support of DSS. A write-enabled capability is available in AS for situations that meet certain requirements.
Figure 42.2. Analysis Services as part of the MS SQL Server 2000 environment.
The basic components within AS are all focused around building and managing data cubes. AS consists of the Analysis Server and the Pivot Table Service.
Cubes are created by pre-processing aggregations (pre-calculated summary data) that reflect the desired levels within dimensions and support the type of querying that will be done. These aggregations provide the mechanism for rapid and uniform response times to queries. These aggregations are created before the user uses the cube. All queries are utilizing either these aggregations, the cube's source data, a copy of this data on the AS, a client cache, or a combination of these sources. A single Analysis Server can manage many cubes.
A cube is defined by the measures and dimensions that it contains. Each cube dimension can contain a hierarchy of levels to specify the natural categorical breakdown that users need to drill down into for more details. Look back at Figure 42.1 and you can see a product hierarchy, time hierarchy, and geography hierarchy representation.
The data values within the cube are represented by measures (the facts). Each measure data might utilize different aggregation options depending on the type of data. Unit data might require SUM (summarization), Date of Receipt data might require the MAX function, and so on. Members of a dimension are the actual level values, such as the particular product number, the particular month, and the particular country. A cube can contain up to 128 dimensions, each with millions of members, and up to 1,024 measures.In reality, you will probably not have more than a handful of dimensions. Remember: The dimensions are the paths to the interesting facts. Dimension members should be textual and are used as criteria for queries and as row and column headers in query results.
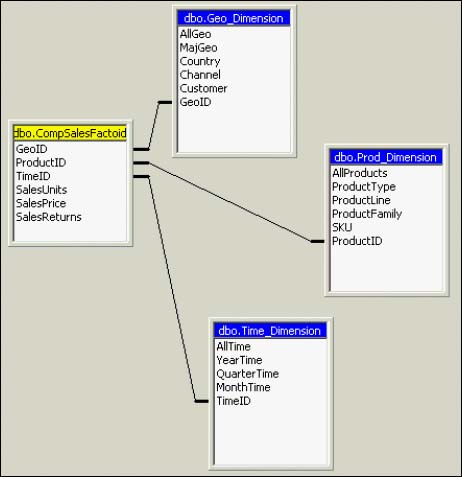
Every cube has a schema from which the cube draws its source data. The central table in this schema is the fact table that will yield the cube's data measures. The other tables in the schema are the dimension tables that are the source of the cube dimensions. A classic star-schema data warehouse design will have this central fact table along with multiple dimension tables. This is a great starting point for OLAP cube creation, as you can see in Figure 42.3.
Figure 42.3. Central Fact table and multiple dimensions of these facts.
AS allows you to build dimensions and cubes from heterogeneous datasources. It can access relational OLTP databases, multidimensional data databases, text data, and any other source that has an OLE DB provider available. You don't have to move all your data first, just connect to its source.
Essentially, cubes can be regular, virtual, or local cubes. Slight variations on this theme are linked cubes and real-time cubes. The following list explains these cubes in more detail:
Regular cubes?Regular cubes are based on real tables for their datasource, will have aggregations, and will occupy physical storage space of some kind. If a datasource that contributes to this cube changes, the cube must be reprocessed. Figure 42.4 shows cube representations.
Figure 42.4. The AS cube representations?regular OLAP cubes, partitions, and virtual cubes.
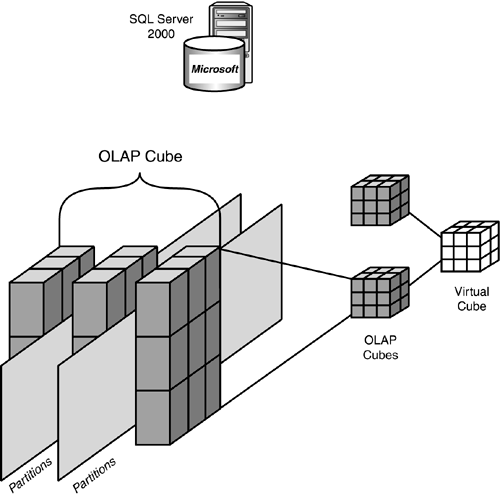
Virtual cubes?Virtual cubes are logical cubes based on one or more regular cubes (or linked cubes). Virtual cubes use the aggregations of their component regular cubes, in which case storage space is not needed.
Linked cubes?Linked cubes are based on regular cubes defined and stored on another Analysis Server. Linked cubes also use the aggregations (and storage) of the regular cube they reference.
Local cubes?Local cubes are entirely contained in portable files (tables) and can be browsed without a connection to an Analysis Server. They do not have aggregations. This is really like being in "disconnected" mode.
Real-time cubes?These are regular cubes that have dimensions or partitions that have been enabled for "real-time OLAP." In other words, real-time cubes receive updates dynamically from the datasources that are defined in their dimensions/ partitions.
Write-enabled cubes?These are cubes in which updates (writes) are allowed and can be shared back with the datasources.
Following is a quick summary of all the essential terms in AS:
Database?The logical container of one or more cubes. Cubes are defined within Analysis Server databases.
Cube?The multidimensional representation of the business facts. Types of cubes include regular, virtual, linked, and local.
Datasource?The origin of a cube's data.
Measure?The data fact representation. A measure is typically a data value fact such as price, unit, quantity, and so on. Up to 1,024 measures can exist per cube.
Cell?The part of a data measure that is at the intersection of the dimensions. The cell contains the data value. If an intersection (cell) has no value yet, it will not physically exist until it is populated.
Dimension?A cube's dimension is defined by the aggregation levels of the data that are needed to support your data requirements. A dimension can be shared with other cubes or private to a cube. A cube can have up to 128 dimensions. The structure of a dimension is directly related to the dimension table columns, member properties, or from the structure of OLAP data mining models. This structure becomes the hierarchy and should be organized with this in mind. You can also have strict parent-child dimensions in which two columns are identified as being parent and child, and the dimension is organized according to them. In a regular dimension, each column in the dimension contributes a hierarchy level. In a virtual dimension, each member property or column in the definition of the dimension contributes a hierarchy level.
Level?A level includes the nodes of the hierarchy or data mining model. Each level contains the members. Millions of members for each level are possible.
Partition?One or more partitions comprise the cube. A partition is a way to physically separate parts of a cube. This separation essentially lets you deal with individual "slices" of a data cube separately, querying only the relevant datasources. If you partition by dimension, you can perform incremental updates to change that dimension independently of the rest of the cube. Consequently, you only have to reprocess aggregations affected by those changes. This is an excellent feature for scalability.
Hierarchy?The set of members in a dimension and their position relative to each other. Hierarchies can either be balanced or unbalanced. Being balanced simply means that all branches of the hierarchy descend to the same level. An unbalanced hierarchy allows for branches to descend to different levels. It is also possible to define more than one hierarchy for a single dimension. A great example of this is for "fiscal calendar time" and "Gregorian calendar time" being defined in one dimension (time dimension: time.gregorian and time.fiscal).
As mentioned previously, AS has many wizards. Depending on exactly what you need to create, you will be using one set of wizards or another. Later, in the "Creating an OLAP Database" section, the order and path through these wizards will be outlined.
OLAP Versus OLTP
One of the primary goals of OLAP is to increase data retrieval speed. A multidimensional schema is not a typical normalized relational database; redundant data is stored to facilitate quick retrieval. The data in a multidimensional database should be relatively static; in fact, data is not useful for decision support if it changes constantly. The information in a data warehouse is built out of carefully chosen snapshots of business data from OLTP systems. If you capture data at the right times for transfer to the data warehouse, you can quickly make accurate comparisons of important business activities over time.
In an OLTP system, transaction speed is paramount. Data modification operations must be quick, must deal with concurrency, and must provide transactional consistency. An OLTP system is constantly changing; every snapshot of the system, even if taken only a few seconds apart, will be different. Although historical information is certainly available in an OLTP system, it might be impractical to use it for DSS-type analysis. Storing old data in an OLTP system becomes expensive, and you might need to reconstruct history dynamically from a series of transactions.
AS supports three OLAP storage methods, providing flexibility to the data warehousing solution and enabling powerful partitioning and aggregation optimization capabilities. These OLAP storage methods are MOLAP, ROLAP, and HOLAP. The following sections will take a closer look at these.
MOLAP
Multidimensional OLAP (MOLAP) is an approach in which cubes are built directly from OLTP datasources or from dimensional databases and downloaded to a persistent store.
In Microsoft Analysis Services, data is downloaded to the server, and these details and aggregations are stored in a native Microsoft OLAP format. No zero-activity records are stored.
The dimension keys in the fact tables are compressed, and bitmap indexing is used. A high-speed MOLAP query processor retrieves the data.
ROLAP
Relational OLAP (ROLAP) uses fact data in summary tables in the OLTP datasource to speed retrieval. The summary tables are populated by processes in the OLTP system and are not downloaded to AS. The summary tables are known as materialized views and contain various levels of aggregation, depending on the options you select when building data cubes with AS. AS builds the summary tables with a column for each dimension and each measure. It indexes each dimension column and creates an additional index on all the dimension columns.
HOLAP
AS also implements a combination of MOLAP and ROLAP called hybrid OLAP (HOLAP). Here, the facts are left in the OLTP datasource, and aggregations are stored in the AS server. You use AS to boost query performance. This approach helps avoid data duplication, but performance suffers a bit when you query fact data in the OLTP summary tables. The amount of performance degradation depends on the level of aggregation you selected.
ROLAP and HOLAP are useful in situations where an organization wants to leverage its investment in relational database technology and existing infrastructure. The summary tables of facts are also accessible in the OLTP system via normal data access methods. However, keep in mind that when using AS, both ROLAP and HOLAP require more storage space because they don't use the storage optimizations of the pure MOLAP-compressed implementation.








