What Is Replication?
Long before you ever start setting up and using SQL Server data replication, you need to have a solid grasp of what data replication is and how it can be used to meet your company's needs. In its classic definition, data replication is based on the "store and forward" data distribution model, as shown in Figure 22.1. In other words, data that is stored in one location (inserted) is automatically "forwarded" to one or more distributed locations.
Figure 22.1. Store and Forward distribution model.
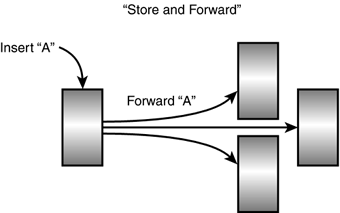
Of course, the more complete data distribution model addresses updates, deletes, data latency, autonomy, and so on. It is this data distribution model that Microsoft's data replication facility serves to implement. It has come a long way since the early days of Microsoft SQL Server replication (earlier than 6.5) and is now easily categorized as "production worthy." I have personal experience in implementing several worldwide data replication scenarios for some of the biggest companies in Silicon Valley without a hitch. These scenarios have fallen into three typical areas. The first is when you need to deliver data to different locations to eliminate network traffic and unnecessary loads on a single server. Another is when you need to move data off a single server onto several other servers to provide for high availability and decentralization of data (or partitioning of data). Finally, you could be replicating all data on a server to another server so that if the primary server crashes, users can switch to this other server quickly and continue to work with little downtime or data loss (fail-over server). Figure 22.2 illustrates the topology of some of these replication variations.
Figure 22.2. Data replication example scenarios.
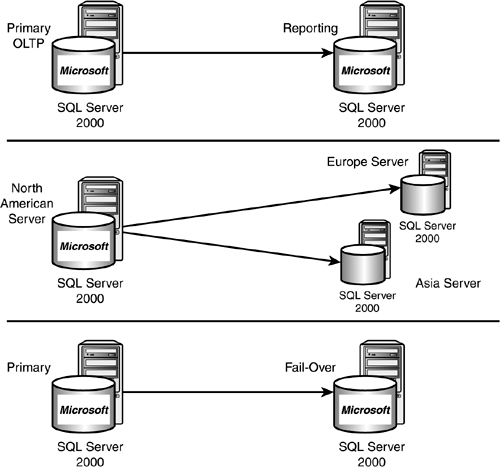
You can use data replication for many reasons. A few of these will be discussed later in this chapter. First, however, you need to understand some of the common terms and metaphors used by Microsoft in data replication.







