Constraints
Constraints are the primary method used to enforce integrity. The types of constraints are PRIMARY KEY, FOREIGN KEY, UNIQUE, CHECK, and DEFAULT. Defaults can be implemented as constraints or as objects in the database; these are covered in the "Defaults" section of this chapter.
PRIMARY KEY Constraints
To enforce entity integrity?in other words, to uniquely identify each row?you use a PRIMARY KEY constraint. Only one PRIMARY KEY is allowed per table, and it ensures that the column or columns that make up the key are unique and NOT NULL. When a PRIMARY KEY is created, it creates a unique index on the column(s). By default, it creates a CLUSTERED index.
When choosing a candidate for a PRIMARY KEY, try to keep it as short as possible. If you have to combine several columns to come up with a unique instance, you should consider creating a surrogate key. For example, perhaps in an employee table, you have to combine the lastname, firstname, and dept columns to come up with a unique identifier (and that combination is not necessarily guaranteed to be unique). It would be more efficient to add an Emp_no column and use the identity property to automatically generate a unique number for each employee. This would avoid having the PRIMARY KEY index cover all three columns. The following example defines a PRIMARY KEY on the Emp_no column of the employee table:
CREATE TABLE employee ( Emp_no int IDENTITY (100, 10)CONSTRAINT emp_pk_emp_no PRIMARY KEY NOT NULL, Lastname char(20) NOT NULL, Firstname char(20) NOT NULL, PayRoll char(10) NOT NULL, Phone char(13) NULL, Dept smallint )
UNIQUE Constraints
The UNIQUE constraint is functionally similar to the PRIMARY KEY. It also uses a unique index to enforce uniqueness, but unlike the primary key, it allows nulls. Actually, in practice, it allows NULL; if a column with a UNIQUE constraint contains a NULL value in one row, insertion of another row with a NULL in that column is blocked. It considers NULL to be a unique value. Because this behavior is unpredictable, especially if the constraint is a composite of columns, I recommend that columns with UNIQUE constraints be created as NOT NULL.
UNIQUE constraints are generally used when a column, outside of the PRIMARY KEY, must be guaranteed to be unique. A typical example would be the Social Security number or payroll number of an employee, in which an employee number was used as the PRIMARY KEY. The example that follows shows a CREATE TABLE script that defines a UNIQUE constraint on the Payroll column:
CREATE TABLE employee ( Emp_no int IDENTITY (100, 10)CONSTRAINT emp_pk_emp_no PRIMARY KEY NOT NULL, Lname char(20) NOT NULL, Fname char(20) NOT NULL, PayRoll char(10)CONSTRAINT emp_uk_payroll UNIQUE NOT NULL, Phone char(13) NULL, Dept smallint)
Referential Integrity Constraint: FOREIGN KEY
FOREIGN KEY constraints enforce referential integrity. They maintain the relations in a relational database. When a FOREIGN KEY constraint is created on a column, the column references another column in a different or even the same table. The referenced column must be a PRIMARY KEY or UNIQUE constraint. A FOREIGN KEY that references a column in the same table is said to be a self-referencing key. When changes (inserts, updates) are made to a column defined with a FOREIGN KEY, the FOREIGN KEY relationship checks if the new value matches a value in the referenced column. For example, an employee table with a Dept column could have a FOREIGN KEY referencing the Dept (PRIMARY KEY) column of the Department table. Any attempts to insert or update an employee's Dept column would be checked against the department table to ensure that the new entry was a valid department. The FOREIGN KEY constraint is also checked when deleting or updating records in the referenced table, preventing you from updating or deleting a primary key that would leave behind foreign keys with the old value in the referencing table. The following is an example of adding a FOREIGN KEY to the employee table:
ALTER TABLE employee ADD CONSTRAINT emp_dept_fk FOREIGN KEY (Dept) REFERENCES dept(dept_no)
When adding a FOREIGN KEY constraint, the table being referenced must already exist and the column being referenced must have a PRIMARY KEY constraint or a unique index defined via a UNIQUE constraint or CREATE INDEX statement. If you do not provide the referenced column names in a FOREIGN KEY constraint, a PRIMARY KEY constraint must be present on the appropriate columns in the referenced table. In addition, the datatypes of the referencing table columns must exactly match the datatypes of the referenced table columns.
If you need to reference a table you do not own, you will need to be granted references permission on that table by the table owner. A referenced table cannot be dropped until the referencing table or the FOREIGN KEY constraint that references the primary key table is dropped.
Cascading Referential Integrity
Cascading Referential Integrity, a feature conspicuously absent in earlier versions of SQL Server, has finally arrived in SQL Server 2000. Two new clauses, ON DELETE and ON UPDATE, have been added to the CREATE TABLE and ALTER TABLE commands to facilitate this. When CASCADE is specified for either or both of these clauses, actions against the parent table will "cascade" to the child table.
To illustrate the usefulness of this, consider the employee and department tables. If the employee table, which has a foreign key on the dept column that references the dept column of the department table, was created with ON UPDATE CASCADE, any changes to the dept column in the department table would cascade to the employee table. Therefore, if dept 20 has 5,000 employees, and you change the dept number to 200 to comply with a business rule, all 5,000 employee records are automatically updated as well. If ON DELETE CASCADE were specified for the table, then deleting dept 20 would result in the deletion of all 5,000 employees! This is a powerful, and dangerous feature, but don't let that discourage you from using it. Think of an orders/items scenario. When an order is deleted, all associated items are deleted as well. Following is the ALTER TABLE command to add a FOREIGN KEY constraint and enable cascading deletes and updates:
ALTER TABLE employee ADD CONSTRAINT emp_dept_fk FOREIGN KEY (Dept) REFERENCES dept(dept_no) ON DELETE CASCADE ON UPDATE CASCADE
You can disable the cascade feature with ON DELETE NO ACTION and ON UPDATE NO ACTION.
NOTEIf you plan to utilize the cascade feature, I recommend working closely with the application developers to ensure that checks and balances are in place to prevent accidental deletion of data. It is also important to note the potential overhead generated by Cascading Referential Integrity. As you saw in the preceding examples, an action on a single row was translated into an action on many rows. |
CHECK Constraints
CHECK constraints provide a way to restrict the values that can be entered into a column. A CHECK constraint is implemented as a Boolean expression, which must not evaluate to false, for the insert or update to proceed. CHECK constraints can be used to ensure that data meets a certain format, as in a telephone number being expressed as (613) [0?9][0?9][0?9]?[0?9][0?9][0?9][0?9], or that the data is in a list of acceptable values such as states (AK, AL, AR, AZ, CA, and so on). A CHECK constraint can also reference a column in the same table, or a function, provided that the function doesn't require input parameters. Following is an example of implementing CHECK constraints with CREATE TABLE:
CREATE TABLE inventory
(item_code char(4) not null
constraint CK_inventory_item_code
check (item_code like '[0-9][0-9][0-9][0-9]'),
high_volume int not null
constraint CK_inventory_high_volume
check (high_volume > 0),
low_volume int not null
constraint CK_inventory_low_volume
check (low_volume > 0),
constraint CK_inventory_hi_lo_check
check (high_volume >= low_volume
and high_volume - low_volume < 1000)
)
Creating Constraints
Constraints can be defined on a single column, which is referred to as a column-level constraint, or on multiple columns where it is considered a table-level constraint. Column-level constraints can be defined in the column definition, whereas table-level constraints must be created after the columns they reference have been defined.
When creating constraints, always provide intuitive names; if you don't, SQL Server generates a name for you. For example, a unique constraint on the Social_Security column of the employee table might be referenced as emp_ss_uk. The error Violates constraint emp_ss_uk is easier to troubleshoot than Violates constraint UK__emp__5165187F.
Although constraints are defined at the table or column level, constraint names must be unique within the current database.
Creating Constraints with T-SQL
Constraints can be created in the CREATE TABLE statement or after the table has been created using ALTER TABLE.
NOTEI recommend creating your tables first, and then using ALTER TABLE to create the constraints. This has the twofold effect of keeping your CREATE TABLE syntax simpler, and providing ALTER TABLE scripts that can be rerun or modified as the need arises. |
Listing 14.1 demonstrates creating constraints with the CREATE TABLE command. The script creates a PRIMARY KEY on both the employee and dept tables and creates a foreign key on the employee table that references the dept table.
Listing 14.1 Syntax for Creating Constraints with CREATE TABLE
CREATE TABLE dept ( Dept_no smallint IDENTITY (10, 10) CONSTRAINT DEPT_PK PRIMARY KEY NOT NULL, Name varchar(20) NOT NULL, Description varchar(80) NOT NULL, Loc_code char(2) NULL ) CREATE TABLE employee ( Emp_no int IDENTITY (100, 10)CONSTRAINT emp_pk_emp_no PRIMARY KEY NOT NULL, Lname char(20) NOT NULL, Fname char(20) NOT NULL, Phone char(13) NULL, Dept smallint CONSTRAINT emp_dept_fk REFERENCES dept(dept_no)NOT NULL, Photo image NULL, Salary int NULL ) go
In the following example, CREATE TABLE is run first, and then ALTER TABLE is run to add the constraints. Listing 14.2 shows that separating constraint creation from the table creation is easier to read and more flexible. This example creates the Product table, and then alters the Product table to add a PRIMARY KEY constraint on ProductId, a CHECK constraint on UnitPrice, and a FOREIGN KEY constraint on CategoryID that references the Categories table.
Listing 14.2 Syntax for Creating Constraints with ALTER TABLE
CREATE TABLE Product ( ProductID int IDENTITY (1, 1) NOT NULL , ProductName nvarchar (40) NOT NULL , SupplierID int NULL , CategoryID int NULL , QuantityPerUnit nvarchar (20) NULL , UnitPrice money NULL , UnitsInStock smallint NULL , UnitsOnOrder smallint NULL , ReorderLevel smallint NULL , Discontinued bit NOT NULL ) GO ALTER TABLE Product ADD CONSTRAINT PK_Product PRIMARY KEY (ProductID), CONSTRAINT CK_Product_UnitPrice CHECK (UnitPrice >= 0) GO ALTER TABLE Product ADD CONSTRAINT FK_Product_Categories FOREIGN KEY (CategoryID) REFERENCES dbo.Categories (CategoryID) GO
Creating Constraints in Enterprise Manager
Previous chapters looked at using Enterprise Manager to create tables and to add indexes to those tables. Constraints are no different, in that the Table Designer is used to create and manage constraints. To access Table Designer, right-click the table you want to manage and select Design Table from the pop-up menu. The rightmost icon, as shown in Figure 14.1, is the Manage Constraints icon.
Figure 14.1. Using Table Designer to manage constraints.
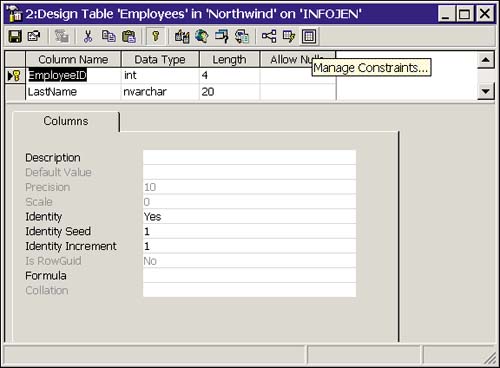
Selecting the Manage Constraints icon brings up the Properties dialog box, as shown in Figure 14.2.
Figure 14.2. The Table Designer Properties dialog box.
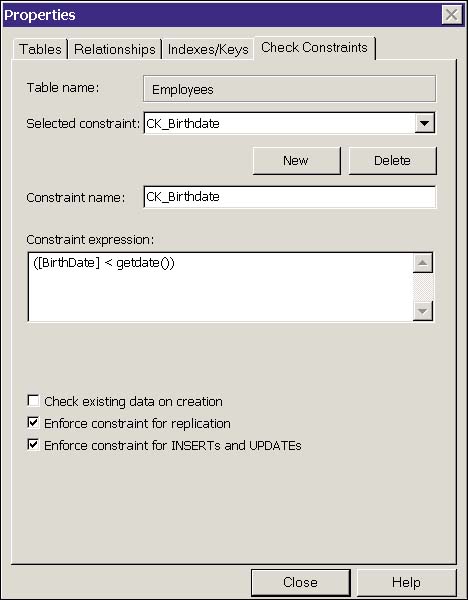
The Relationships tab manages FOREIGN KEYS. The Indexes/Keys tab manages PRIMARY KEY and UNIQUE constraints. The Check Constraint tab can be used to create, delete, and modify CHECK constraints. If you want to set DEFAULTS, you can do so from the Columns dialog box, as shown in Figure 14.3.
Figure 14.3. Adding a DEFAULT in the Table Designer Columns dialog box.
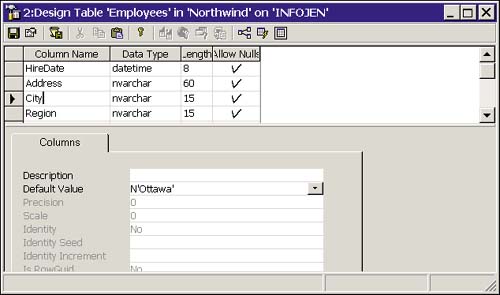
As with any changes made through Table Designer, changes to constraints are not saved until you exit the Designer. Before exiting the Designer, it is advisable to save your changes to a script using the Save Change Script icon (the third icon from the left).
TIPIf you plan to drop or modify constraints after business hours, perhaps to facilitate a data load, use Table Designer to generate a script for the changes. When you exit the Designer, select No when prompted to save your changes. Now you have a script you can schedule as a job, and the changes will be made when the job runs. |
Managing Constraints
Managing constraints consists of gathering information about constraints, disabling and re-enabling constraints, and dropping constraints.
Gathering Information About Constraints
To get information on constraints, you can query the information_schema views: check_constraints, referential_constraints, and table_constraints. The system-stored procedures, sp_help and sp_helpconstraint, can also be executed to obtain information. Figure 14.4 shows the sp_helpconstraint output in Query Analyzer.
Figure 14.4. Executing sp_helpconstraint on the employees table.
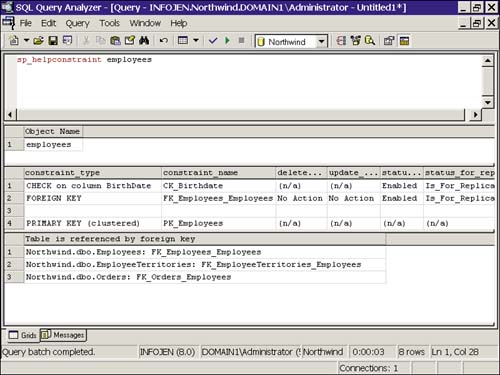
Dropping Constraints
Constraints are dropped using the ALTER TABLE command. For example, to drop a constraint from the employee table, use the following:
Alter table employee drop constraint Ck_Product
You can also drop constraints from the Table Designer by selecting the constraint to be dropped and clicking Delete.
Disabling Constraints
CHECK and FOREIGN KEY constraints can be disabled from checking existing data or from checking new data to be loaded.
When adding a constraint to a table with existing data, SQL Server checks the data to make sure it doesn't violate the constraint. If you want to enforce the constraint on new data but the existing data doesn't comply (perhaps all new ZIP codes must be six digits, but the existing five digit ones don't change), you can add the constraint WITH NOCHECK as in the following example:
ALTER TABLE employee WITH NOCHECK ADD CONSTRAINT CK_Product_UnitPrice CHECK (UnitPrice >= 0)
If possible, it is better to change the existing data to meet the constraint criteria rather than use the WITH NOCHECK. If the data in any column changes at a later date, the constraint will be violated and the transaction rolled back. This can be problematic when troubleshooting because the error returns a constraint violation on ColumnB, and the update is changing data only in ColumnC.
If you want to speed the loading of data that meets the constraint criteria, or if you must load data that does not, you can disable an existing constraint using NOCHECK. This is illustrated in this statement:
ALTER TABLE employee NOCHECK CONSTRAINT CK_Product_UnitPrice
The constraint is enabled using CHECK. Disabling constraint checking can vastly improve the speed of large data loads, but the constraint can't be enabled if the new data violates the constraint. Once more, if possible, it is better to fix the data to be loaded before the load. However, in a less-than-perfect world, disabling constraints can be a valid option.







