Replication Scenarios
In general, depending on your business requirements, one of several different data replication scenario models can be implemented. These include the following:
Central publisher
Central publisher with a remote distributor
Publishing subscriber
Central subscriber
Multiple publishers or multiple subscribers
Updating subscribers
Central Publisher
The central publisher replication model, as shown in Figure 22.10, is Microsoft's default scenario. In this scenario, one SQL Server performs the function of both publisher and distributor. The publisher/distributor can have any number of subscribers. These subscribers can come in many different varieties, such as SQL Server 2000, SQL Server 7.0, and Oracle.
Figure 22.10. The central publisher scenario is a simple and often used scenario.
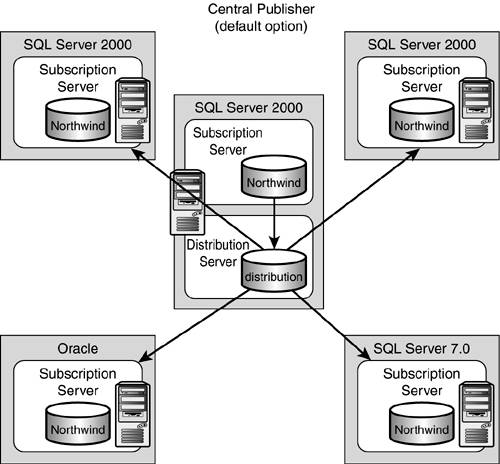
The central publisher scenario can be used in the following situations:
Creation of a copy of a database for ad hoc queries and report generation (classic use)
Publication of master lists to remote locations, such as master customer lists or master price lists
Maintenance of a remote copy of an online transaction processing database (OLTP) that could be used by the remote sites during communication outages
Maintenance of a "spare" copy of an online transaction processing database (OLTP) that could be used as a "hot spare" in case of server failure
However, it's important to consider the following for this scenario:
If your OLTP server's activity is substantial and affects greater than 10 percent of your total data per day, then this scenario is not for you. Other scenarios will better fit your need.
If your OLTP server is maximized on CPU, memory, and disk utilization, you also should consider another data replication scenario. This one is not for you either.
Central Publisher with Remote Distributor
The central publisher with remote distributor scenario, as shown in Figure 22.11, is similar to the central publisher scenario and would be used in the same general situations. The major difference in the two is that a second server is used to perform the role of distributor. This is highly desirable when you need to free the publishing server from having to perform the distribution task from a CPU, disk, and memory point of view. This also offers the best scenario from which to expand the number of publishers and subscribers. Also remember that a single distribution server can distribute changes for several publishers. The publisher and distributor must be connected to each other via a reliable, high-speed data link. This remote distributor scenario is proving to be one of the best data replication approaches due to minimal impact on the publication server and maximum distribution capability to any number of subscribers.
Figure 22.11. The central publisher with remote distributor is used when the role of distributor must be removed from the publishing server.
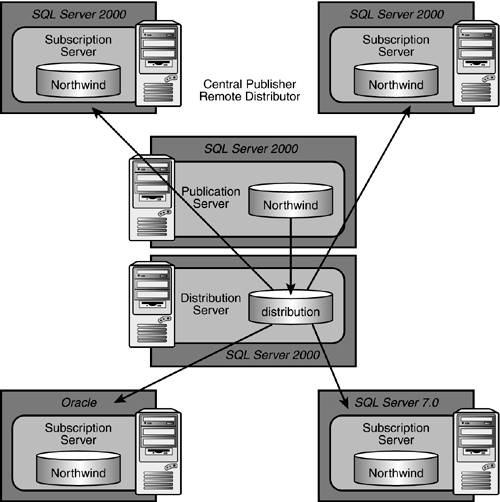
As mentioned previously, the central publisher remote distributor approach can be used for all of the same purposes as the central publisher scenario, but it also provides the added benefit of having minimal resource impact on your publication servers. If your OLTP server's activity affects greater than 10 percent of your total data per day, this scenario can usually handle it without much issue. If your OLTP server has overburdened its CPU, memory, and disk utilization, you easily have solved this issue as well.
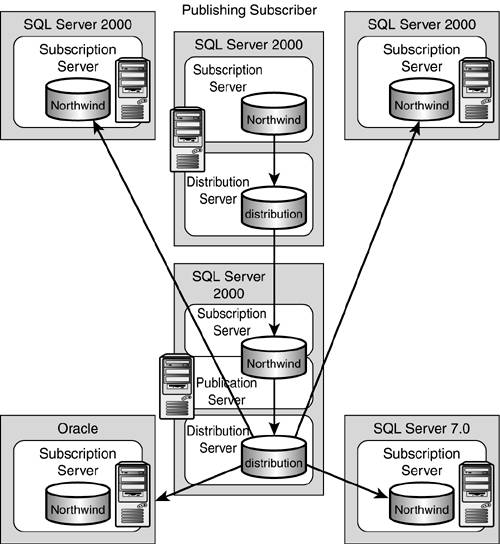
Publishing Subscriber
In the publishing subscriber scenario, as shown in Figure 22.12, the publication server also will have to act as a distribution server to one subscriber. This subscriber, in turn, will immediately publish this data to any number of other subscribers. The configuration depicted here is not using a remote distribution configuration option, but is serving the same distribution model purpose. This scenario is best used when a slow or expensive network link exists between the original publishing server and all of the other potential subscribers. This will allow the initial (critical) publication of the data to be distributed from the original publishing server to that single subscriber across that slow, unpredictable, or expensive network line. Then, each of the many other subscribers can subscribe to the data using faster, more predictable, "local" network lines that they will have with the publishing subscriber server. A classic example of this would be that of a company whose main office is in San Francisco and has several branch offices in Europe. Instead of replicating changes to all the branch offices in Europe, the updates are replicated to a single publishing subscriber server in Paris. This publishing subscriber server in Paris then replicates the updates to all other subscriber servers around Europe. Voila!
Figure 22.12. The publishing subscriber scenario works well when having to deal with slow, unpredictable, or expensive network links in diverse geographic situations.
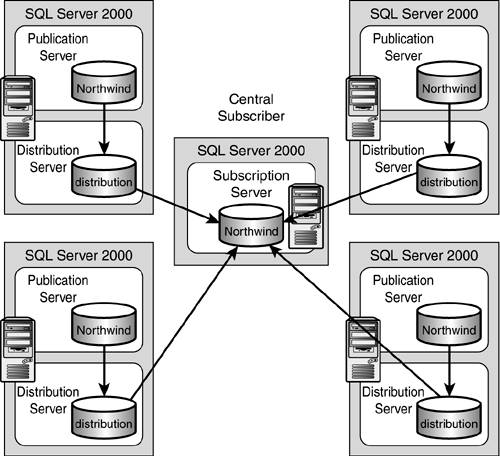
Central Subscriber
In the central subscriber scenario, as shown in Figure 22.13, several publishers replicate data to a single, central subscriber. Basically, this is supporting the concept of consolidating data at a central site. An example of this might be that of consolidating all new orders from regional sales offices to company headquarters. Remember, you now will have several publishers of the Orders table; you need to take some form of precaution, such as filtering by region. This would guarantee that no one publisher could be updating another region's orders.
Figure 22.13. When using the central subscriber scenario, several publishers send data to a single, central subscriber.
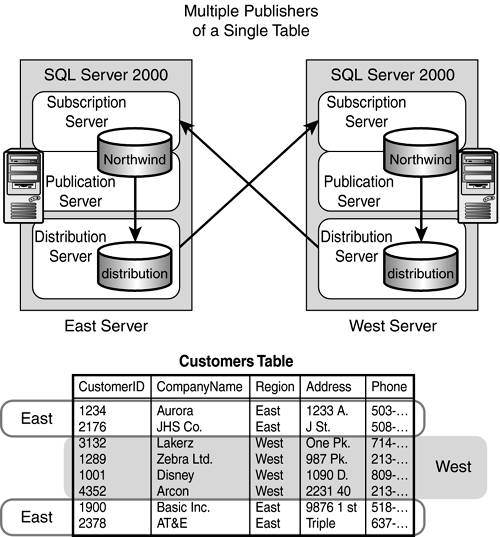
Multiple Publishers or Multiple Subscribers
In the multiple publishers or multiple subscribers scenario, as shown in Figure 22.14, a common table (like the Customers table) is maintained on every server participating in the scenario. Each server publishes a particular set of rows that pertain to it?usually via filtering on something that identifies that site to the data rows it owns?and subscribes to the rows that all the other servers are publishing. The result is that each server has all the data at all times, and can make changes to their data only. You must be careful when im-plementing this scenario to ensure that all sites remain synchronized. The most frequently used applications of this system are regional order processing systems and reservation tracking systems. When setting up this system, make sure that only local users update local data. This check can be implemented through the use of stored procedures, restrictive views, or a check constraint.
Figure 22.14. In the multiple publishers of a single table scenario, every server in the scenario maintains a common table.
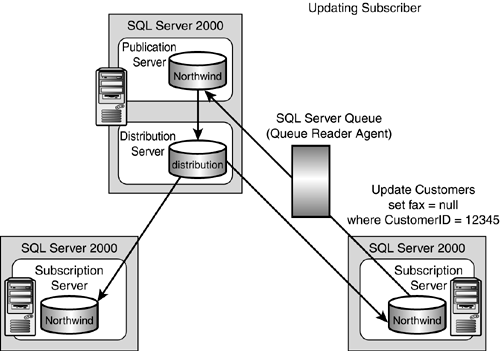
Updating Subscribers
SQL Server 2000 has built-in functionality that allows the subscriber to update data in a table to which it subscribes, and have those updates automatically made back to the publisher through either immediate or queued updates. This model, called "updating subscribers," utilizes a two-phase commit process to update the publishing server as the changes are made on the subscribing server. These updates then are replicated to any other subscribers, but not to the subscriber that made the update.
Immediate updating allows subscribers to update data only if the publisher will accept them immediately. If the changes are accepted at the publisher, they will be propagated to the other subscribers. The subscribers must be continuously and reliably connected to the publisher to make changes at the subscriber.
Queued updating allows subscribers to update data and then store those updates in a queue while disconnected from the publisher. When the subscriber reconnects to the publisher, the updates are propagated to the publisher. This functionality utilizes SQL Server 2000 queue and the Queue Reader Agent or Microsoft Message Queuing.
A combination of immediate updating with queued updating allows the subscriber to use immediate updating, but switch to queued updating if a connection cannot be maintained between the publisher and subscribers. After switching to queued updating, reconnecting to the publisher, and emptying the queue, the subscriber can switch back to immediate updating mode. An updating subscriber is shown in Figure 22.15.
Figure 22.15. Updating subscriber.
Subscriptions
A subscription is essentially a formal request and registration of that request for data that is being published. By definition, you will subscribe to all articles of a publication.
When this formal request (the subscription) is being set up, you will have the option of either having the data pushed to the subscriber server, or the option of pulling the data to the subscription server when it is needed. This is referred to as either a push subscription or a pull subscription.
As depicted in Figure 22.16, a pull subscription is set up and managed by the subscription server. The biggest advantage here is that pull subscriptions allow the system administrators of the subscription servers to choose what publications they will receive and when they receive it. With pull subscriptions, publishing and subscribing are separate acts and are not necessarily performed by the same user. In general, pull subscriptions are best when the publication does not require high security, or if subscribing is done intermittently when the subscriber's data needs to be periodically brought up to date.
Figure 22.16. Push and pull.
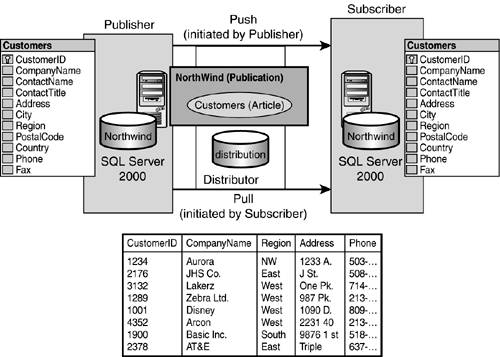
A push subscription is created and managed by the publication server. In effect, the publication server is pushing the publication to the subscription server. The advantage of using push subscriptions is that all of the administration takes place in a central location. In addition, publishing and subscribing happen at the same time, and many subscribers can be set up at once. This also is recommended when dealing with heterogeneous subscribers because of the lack of pull capability on the subscription server side.
Anonymous Subscriptions (Pull Subscriptions)
It is also possible to have what is called "anonymous" subscriptions. An anonymous sub-scription is a special type of pull subscription that can be used in the following circumstances:
You are publishing data to the Internet
You have a huge number of subscribers
You don't want the overhead of maintaining extra information at the publisher or distributor
All the rules of your pull subscriptions apply to all of your anonymous subscribers
Normally, information about all of the subscribers, including performance data, is stored on the distribution server. Therefore, if you have a large number of subscribers, or you do not want to track detailed information about the subscribers, you might want to allow anonymous subscriptions to a publication. Then little is kept at the distribution server, but it then becomes the responsibility of the subscriber to initiate the subscription and to keep synchronized.
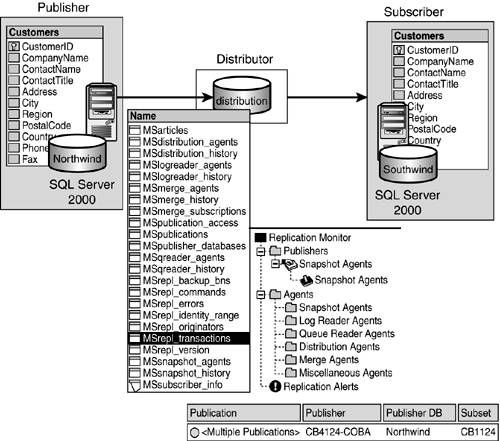
The Distribution Database
The distribution database is a special type of database installed on the distribution server. This database is known as a store-and-forward database and holds all transactions waiting to be distributed to any subscribers. This database receives transactions from any published databases that have designated it as their distributor. The transactions will be held here until they are sent to the subscribers successfully. After a period of time, these transactions will be purged from the distribution database. In some special situations, the transactions might not be purged for a longer period, enabling anonymous subscribers ample time in which to synchronize. The distribution database is the "heart" of the data replication facility. As you can see in Figure 22.17, the distribution database has several "MS" tables, such as MSarticles. These tables contain all necessary information for the distribution server to fulfill the distribution role. These tables include the following:
All the different publishers who will use it, such as MSpublisher_databases and MSpublication_access
The publications and articles that it will distribute, such as MSpublications, MSarticles
The complete information for all the agents to perform their tasks, such as MSdistribution_agents
The complete information of the executions of these agents, such as MSdistribution_history
The subscribers, such as MSsubscriber_info, MSsubscriptions, and so on
Any errors that occur during replication and synchronization states, such as MSrepl_errors, MSsync_state, and so on
The commands and transactions that are to be replicated, such as MSrepl_commands and MSrepl_transactions
Figure 22.17. Tables of the distribution database.