Discovering the World Wide Web
Discovering the World Wide Web
If you have used a network file server of any kind, you know the convenience of being able to access files that reside at a shared location. Using a word-processing application that runs on your computer, you can easily open a document that physically resides on the file server.
Now, imagine a word processor that enables you to open and view a document that resides on any computer on the Internet. You can view the document in its full glory, with formatted text and graphics. If the document makes a reference to another document (possibly one that resides on yet another computer), you can open that linked document by clicking the reference. That kind of easy access to distributed documents is essentially what the Web provides.
Of course, the documents have to be in a standard format, so that any computer (with appropriate Web software) can access and interpret them. In addition, a standard protocol is necessary for transferring Web documents from one system to another.
The standard Web document format is HyperText Markup Language (HTML), and the standard protocol for exchanging Web documents is HyperText Transfer Protocol (HTTP).
| Note |
A Web server is the software that sends HTML documents (and other files as well) to any client that makes the appropriate HTTP requests. Typically, a Web browser is the client software that actually downloads an HTML document from a Web server and displays the contents graphically. |
Observing Similarity to a Giant Spider Web
The World Wide Web is a combination of Web servers and HTML documents that contain a variety of information. Imagine the Web as a giant book whose pages are scattered throughout the Internet. You use a Web browser running on your computer to view the pages.
The Web pages-HTML documents-are linked by network connections that resemble a giant spider web, so you can see how the Web got its name. The 'World Wide' part refers to the fact that the Web pages are linked around the world.
Learning URLs
Like the pages of real books, Web pages contain text and graphics. Unlike the pages of real books, however, Web pages can contain multimedia information such as images, video clips, digitized sound, and cross-references, called links, that can actually take the user to the page referred to.
The links in a Web page are references to other Web pages. You follow (click) the links to go from one page to another. The Web browser typically displays these links as underlined text (in a different color) or as images. Each link is like an instruction to the reader-such as 'For more information, please consult Chapter 14'-that you might find in a real book. In a Web page, all you have to do is click the link, and the Web browser brings up the page referred to, even if it's on a different computer.
| Note |
The term hypertext refers to nonlinear organization of text (as opposed to the sequential, linear arrangement of text in most books or magazines). The links in a Web page are referred to as hypertext links; by clicking a link, you can jump to a different Web page, which is an example of nonlinear organization of text. |
This arrangement raises a question. In a real book, you might ask the reader to go to a specific chapter or page. How does a hypertext link indicate the location of the Web page in question? Each Web page has a special name, called a Uniform Resource Locator (URL). A URL uniquely specifies the location of a file on a computer, as shown in Figure 14-1.
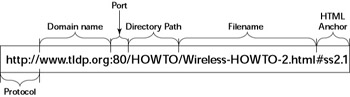
Figure 14-1: A Uniform Resource Locator (URL) Is Composed of Various Parts.
| Note |
The directory path in Figure 14-1 can contain several subdirectories as indicated by the slash. |
As Figure 14-1 illustrates, a URL has this sequence of components:
-
Protocol-This is the name of the protocol the Web browser uses to access the data that reside in the file the URL specifies. In Figure 14-1, the protocol is http://, which means that the URL specifies the location of a Web page. Following are the common protocol types and their meanings:
-
file:// specifies the name of a local file that is to be opened and displayed. You can use this URL to view HTML files without having to connect to the Internet. For example, file:///usr/share/doc/HTML/index.html opens the file /usr/share/doc/HTML/index.html from your Red Hat Linux system.
-
ftp:// specifies a file that is accessible through File Transfer Protocol (FTP). For example, ftp://ftp.purdue.edu/pub/uns/NASA/nasa.jpg refers to the image file nasa.jpg from the /pub/uns/NASA/ directory of the FTP server ftp.purdue.edu. (If you want to access a specific user account by FTP, use the URL of the form ftp://username:password@ftp.somesite .com/ with the user name and password embedded in the URL.)
-
http:// specifies a file that is accessible through the HyperText Transfer Protocol (HTTP). This is the well-known format of URLs for all websites, such as http://www.redhat.com/ for Red Hat's home page.
-
https:// specifies a file that is to be accessed through a Secure Sockets Layer (SSL) connection, which is a protocol designed by Netscape Communications for encrypted data transfers across the Internet. This form of URL is typically used when the Web browser sends sensitive information such as credit card number, user name, and password to a Web server. For example, a URL such as https://some.site.com/secure/takeorder.html might display an HTML form that requests credit card information and other personal information such as name, address, and phone number.
-
mailto:// specifies an email address you can use to send an email message. For example, mailto:webmaster@someplace.com refers to the Webmaster at the host someplace.com.
-
news:// specifies a newsgroup you can read by means of the Network News Transfer Protocol (NNTP). For example, news://news.psn.net/comp.infosystems. www.authoring.html accesses the comp.infosystems. www.authoring.html newsgroup at the news server news.psn.net. If you have a default news server configured for the Web browser, you can omit the news server's name and use the URL news:comp.infosystems. www.authoring.html to access the newsgroup.
-
telnet:// specifies a user name and a system name for remote login. For example, the URL telnet://guest:bemyguest@someplace.com/ logs in to the host someplace.com with the user name guest and password bemyguest.
-
-
Domain name-This contains the fully qualified domain name of the computer on which resides the file this URL specifies. You can also specify an IP address in this field (see Chapter 6 for more information on IP addresses). The domain name is not case sensitive.
-
Port address-This is the port address of the server that implements the protocol listed in the first part of the URL (see Chapter 6 for a discussion of port addresses). This part of the URL is optional; there are default ports for all protocols. The default port for HTTP, for example, is 80. Some sites, however, may configure the Web server to listen to a different port. In such a case, the URL must include the port address.
-
Directory path-This is the directory path of the file being referred to in the URL. For Web pages, this field is the directory path of the HTML file. The directory path is case sensitive.
-
Filename-This is the name of the file. For Web pages, the filename typically ends with .htm or .html. If you omit the filename, the Web server returns a default file (often named index.html). The filename is case sensitive.
-
HTML anchor-This optional part of the URL makes the Web browser jump to a specific location in the file. If this part starts with a question mark (?) instead of a hash mark (#), the browser takes the text following the question mark to be a query. The Web server returns information based on such queries.
Understanding HyperText Transfer Protocol (HTTP)
The HyperText Transfer Protocol-the protocol that underlies the Web-is called HyperText because Web pages include hypertext links. The Transfer Protocol part refers to the standard conventions for transferring a Web page across the network from one computer to another. Although you really do not have to understand HTTP to set up a Web server or use a Web browser, I think you'll find it instructive to know how the Web works.
Before I explain anything about HTTP, you should get some firsthand experience of it. On most systems, the Web server listens to port 80 and responds to any HTTP requests sent to that port. Therefore, you can use the Telnet program to connect to port 80 of a system (if it has a Web server) to try some HTTP commands.
To see an example of HTTP at work, follow these steps:
-
Make sure your Linux PC's connection to the Internet is up and running. (If you use SLIP or PPP, for example, make sure that you have established a connection.)
-
Type the following command:
telnet www.gao.gov 80
-
After you see the Connected... message, type the following HTTP command:
GET / HTTP/1.0
and press Enter twice. In response to this HTTP command, the Web server returns some useful information, followed by the contents of the default HTML file (usually called index.html).
The following is what I get when I try the GET command on the U.S. General Accounting Office's website:
telnet www.gao.gov 80 Trying 161.203.16.2... Connected to www.gao.gov. Escape character is '^]'. HTTP/1.1 200 OK Date: Sat, 15 Feb 2003 21:35:20 GMT Server: Apache/1.3.27 (Unix) PHP/4.2.3 mod_ssl/2.8.12 OpenSSL/0.9.6g X-Powered-By: PHP/4.2.3 Connection: close Content-Type: text/html <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org /TR/REC-html40/loose.dtd"> <HTML> <HEAD> <TITLE>The United States General Accounting Office</TITLE> ... (lines deleted) ... </HEAD> ... (lines deleted) ... </BODY> </html> Connection closed by foreign host.
When you try this example with Telnet, you see exactly what the Web server sends back to the Web browser. The first few lines are administrative information for the browser. The server returns this information:
-
A line that shows that the server uses HTTP protocol version 1.1 and a status code of 200 indicating success: HTTP/1.1 200 OK
-
The current date and time. A sample date and time string looks like this:
Date: Sat, 15 Feb 2003 21:35:20 GMT
-
The name and version of the Web-server software. For example, for a site running the Apache Web server version 1.3.27 with the PHP hypertext processor version 4.2.3, the server returns the following string:
Server: Apache/1.3.27 (Unix) PHP/4.2.3 mod_ssl/2.8.12 OpenSSL/0.9.6g
The mod_ssl phrase refers to the fact that the Apache server has loaded the mod_ssl module that supports secure data transfers through the Secure Sockets Layer (SSL) protocol.
-
The type of document the Web server returns. For HTML documents, the content type is reported as follows:
Content-type: text/html
The document itself follows the administrative information. An HTML document has the following general layout:
<title>Document's title goes here</title> <html> <body optional attributes go here > ... The rest of the document goes here. </body> </html>
You can identify this layout by looking through the listing that shows what the Web server returns in response to the GET command. Because the example uses a Telnet command to get the document, you see the HTML content as lines of text. If you were to access the same URL (http://www.gao.gov) with a Web browser (such as Mozilla), you would see the page in its graphical form, as shown in Figure 14-2.
Figure 14-2: The URL www.gao.gov Viewed with the Mozilla Web Browser.
The example of HTTP commands shows the result of the GET command. GET is the most common HTTP command; it causes the server to return a specified HTML document.
The other two HTTP commands are HEAD and POST. The HEAD command is almost like GET: it causes the server to return everything in the document except the body. The POST command sends information to the server; it's up to the server to decide how to act on the information.
Despite its widespread use on the Web since 1990, HTTP was not an Internet standard until recently. All Internet standards are distributed as Request for Comments (RFCs). The first HTTP-related RFC was RFC 1945, 'HyperText Transfer Protocol-HTTP/1.0' (T. Berners-Lee, R. Fielding, and H. Frystyk, May 1996). However, RFC 1945 is considered an informational document, not a standard.
RFC 2616, 'HyperText Transfer Protocol-HTTP/1.1' (R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee, June 1999) is the Draft Internet standard for HTTP.
To read these RFCs, point your Web browser to either http://www.rfc-editor .org/rfc.html or http://www.cis.ohio-state.edu/htbin/rfc/rfcindex .html.
To learn more about HTTP/1.1 and other Web-related standards, use a Web browser to access http://www.w3.org/pub/WWW/Protocols/.







