Routing Convergence Within an MPLS-enabled VPN Network
One issue that always requires attention within any network deployment is the convergence times within the network. Convergence can be defined as the time taken for routers in a routing domain to learn about changes within the network and to synchronize their view of the network with other devices within the same routing domain. Interior routing protocols, by definition, converge much faster than exterior routing protocols, and this is one of their main objectives. By contrast, exterior routing protocols such as BGP-4 are designed to provide a loop-free topology between autonomous systems. Their main objective is not fast convergence, but excellent scalability and the capability to carry a large number of routes.
This has implications that must be addressed when moving to an MPLS/VPN architecture, especially if the service provider currently carries customer routes within its IGP or if the customers run their own IGP over overlay links (for example, Frame Relay DLCIs) supplied by the service provider. If the service provider already carries customer routes within BGP-4, as most do, then the implications are less obvious, although convergence times between members of a VPN will be affected by the introduction of the MPLS/VPN architecture.
Two main areas must be assessed when looking at the convergence times. The first is the speed of convergence within the service provider backbone; the second is the speed of convergence between customer sites. Both are crucial for end-to-end convergence speed as perceived by MPLS/VPN customers. Figure 12-2 provides an example that shows these two independent processes at work.
Figure 12-2. VPN and Backbone Network Convergence
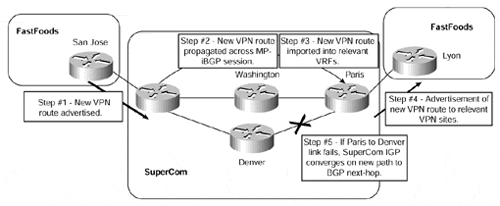
Figure 12-2 shows that the two convergence processes are completely independent. We can see in the figure that a new VPN route is advertised by the FastFoods San Jose site (Step 1). This route is propagated across the MPLS/VPN backbone (Step 2) and then is imported into the FastFoods VRF on the Paris PE-router (Step 3). The route is then advertised to the FastFoods Lyon site (Step 4). If a core link fails, such as the link between the Paris and Denver PE-routers (Step 5), then the service provider's IGP will find a new path toward the BGP next-hop (via the Washington P-router). This does not affect the convergence of the route between the two VPN sites, but it will interrupt traffic between the two VPN sites while the service provider IGP reconverges.
If a VPN site advertises a new route, or if some other change occurs within the VPN site, BGP will take care of the convergence, and the Service Provider IGP will not be affected.
Convergence Within the Service Provider Backbone
Within the service provider backbone, we are really concerned only with the convergence of the Interior Gateway Protocol and the time that it takes for any changes to be reflected in the forwarding component of MPLS. External routes are not an issue because the service provider does not hold these routes within the backbone (at least, not for the VPN service), and MPLS within the internal network is not affected by any external routing information.
Two typical designs are used by the majority of service providers for their high-speed backbones. The backbone may be built based on a pure router architecture, or it could be built on ATM technology using routers and IP-enabled ATM switches.
Note
The case of the backbone being built with routers connected via an ATM or Frame Relay virtual circuit is handled in the same way as the backbone built purely with routers from an MPLS convergence perspective. This is because the ATM or Frame Relay switches are not involved in IP routing, so MPLS does not see the underlying physical structure of the Layer 2 network.
We have already discussed the differences of how MPLS is deployed using these two types of technologies, and we should consider each one in turn when assessing the convergence impact that the introduction of MPLS will have.
Service Provider Backbone Convergence?Router-based Topology
The convergence times within the backbone should not be greatly affected by the introduction of MPLS if the infrastructure is based on a router-only topology. This is due to the way that allocation, retention, and distribution of MPLS labels are performed across the network. We already saw in Chapter 2, "Frame-mode MPLS Operation," how the MPLS label distribution is implemented within a router platform and non-ATM interfaces. This process can be summarized as follows:
Labels are distributed in unsolicited downstream mode? The router advertises bindings as soon as it has a route in its routing table.
Routers use liberal retention mode? When the router receives label bindings for the same FEC from different neighbors, all the bindings are retained. Only some of those label bindings will be used; this is based on the current next-hop for the FEC as found in the routing table of the LSR.
Note
Note If there is more than one neighbor for an FEC, and if one of these neighbors becomes the next-hop for the FEC after routing changes, no additional label distribution needs to take place. The LSR is ready to label switch packets immediately using the new next-hop.
Routers also can use independent control mode? Each router binds and advertises its labels, regardless of whether it has received any labels. In other words, as soon as a route is in the routing table, a label is bound to it, even if the router has not received a label for that prefix from its downstream neighbor.
Whenever a change occurs within the routing table of the LSR, the MPLS process is informed immediately, and convergence occurs based on the factors mentioned previously. This is the same mechanism that is used to instruct a routing protocol that a change has occurred within the forwarding table, so the effect on convergence should be minimal. Introduction of MPLS into the core service provider backbone thus does not increase the convergence time?the overall backbone convergence time is still dictated by the convergence speed of the routing protocol used in the backbone.
Service Provider Backbone Convergence?ATM-based Topology
The convergence times within the backbone will be affected by the introduction of MPLS if the infrastructure is based on an IP-enabled ATM topology and the routers within the topology use TC-ATM interfaces that use the VPI/VCI of ATM cells to carry MPLS label information. This type of architecture was fully described in Chapter 3, "Cell-mode MPLS Operation." Again, this is because of the way that allocation, retention, and distribution of MPLS labels are performed across the backbone network. The default behavior in this type of environment can be summarized as follows:
Labels are distributed in downstream on demand mode? The router will advertise label bindings only if it is specifically asked to do so by an upstream neighbor. This may have an effect on convergence because the LSR may not actually have a label binding for a requested FEC, so it will need to signal downstream to its neighbors to ask for this binding.
ATM-LSRs use conservative retention mode? When the router receives label bindings for the same FEC from several neighbors, it will keep only the label binding that is received from the next-hop neighbor (as controlled by the routing table) for the particular FEC. All other label bindings will be discarded. Therefore, if a change in the topology occurs, the LSR must go through the routing protocol convergence phase, request labels from its downstream neighbor, and wait for new label-binding information to be received from its downstream neighbors before it can continue to label switch traffic.
ATM-LSRs will use ordered control mode? The LSR will allocate a label for a particular FEC only if it is the egress LSR for that FEC, or if it has received a label binding for the FEC from its downstream LDP/TDP neighbors.
The overall convergence time for an ATM-based core backbone could be significantly larger than for the non-ATM core backbone because the convergence occurs in two steps:
The interior routing protocol used in the backbone detects a link or node failure and converges around the failure spot.
LDP/TDP must re-establish label mappings across the ATM backbone. In large ATM backbones with many ATM switches being connected in sequence (in other words, the number of hops across the ATM backbone is large), the LDP/TDP propagation time could be significant, more so if you're faced with a major trunk failure in which a large number of routers start asking for new labels all at once.
Convergence Between VPN Sites
The convergence time between VPN sites is of critical importance to the customers of the VPN service. In the traditional overlay VPN model, which we discussed in Chapter 7, "Virtual Private Network (VPN) Implementation Options," customers are capable of obtaining high-speed convergence through fine adjustment of their own Interior Gateway Protocol (IGP) timers across the virtual circuits provided by the service provider. Although high-speed convergence times are still possible through the MPLS/VPN service, it is important to understand that the responsibility of these convergence times is essentially handed over to the service provider when an MPLS-enabled VPN service is obtained.
Several factors must be considered when assessing the convergence times between VPN sites across the MPLS/VPN backbone. These factors will directly affect the convergence times between VPN customer sites and are not present within the overlay model. The end-to-end convergence delay has essentially four components:
The advertisement of routes from a site toward the backbone (including the import of these routes into the relevant routing tables)
The propagation of these routes across the backbone
The import process of these routes into all relevant VRFs
The advertisement of these routes to other sites
Each of these components can be seen in Figure 12-3.
Figure 12-3. End-to-end Convergence Delay Components
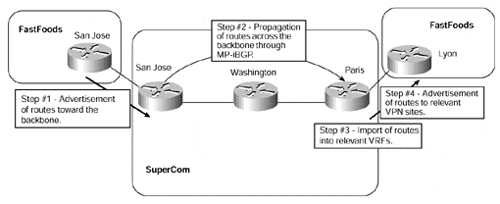
The convergence times between the CE-router and the PE-router in the ingress direction are not affected by the introduction of MPLS/VPN if the VPN service is provided through the peer model because MPLS is not run across the link. This means that whenever a CE-router advertises a route toward the PE, the time it takes for this route to be installed into the local routing table does not change. However, because most (if not all) customers will have been using the overlay model for VPN connectivity before the availability of the MPLS/VPN service, then a certain amount of impact will be felt. This is because the overlay model does not require the exchange of routing information directly between the service provider and VPN customer. With the introduction of MPLS/VPN and the resultant migration to a peer-based solution, these "ex-overlay" customers will see a change in convergence times, which will need to be addressed if they are to receive the same level of service as with their previous overlay solution.
The choice of routing protocol across the PE-to-CE link will obviously have an effect on convergence, but this is not specific to MPLS and will not be considered for discussion within this chapter. The propagation of routes across the backbone should also not be affected detrimentally by the introduction of MPLS if the customer routes were already carried within BGP. However, as already discussed, this is not the case with most customers because they will have propagated routing information across Frame Relay/ATM circuits provided by the service provider. In this case, the service provider may need to fine-tune the advertisement of VPN routing information between PE-routers so that the convergence times may be comparable with a customer's current VPN solution.
There will be a small delay incurred in getting the routes from the VRF into the BGP process, but this is no different than standard BGP, in which routes that are learned through a routing protocol other than BGP are redistributed into the BGP process.
Although there will always be a certain amount of convergence time across the backbone, this is the same whether the routes are standard IPv4 routes or VPN-IPv4 routes. This time is dictated by the interior BGP damping mechanisms?changes in the BGP tables are not propagated to BGP neighbors immediately, but they are batched and sent to the neighbors at regular intervals (the default is every five seconds). If you have deployed route reflectors in your network, a similar delay might be incurred on every route reflector. To improve the convergence of your iBGP sessions, use the neighbor advertisement-interval configuration command.
As each PE-router receives VPN-IPv4 routes from across the backbone, it needs to process them and place them into the relevant VRFs. This process will certainly have an effect on convergence. Whenever a BGP speaker receives an update from a BGP neighbor, it needs to correlate the update with all other updates received from other BGP neighbors. When this process is complete, the BGP router can select the best path to a given destination from all the paths available to it. This is achieved through the BGP selection process.
Note
A description of the BGP selection process can be found on the Cisco Systems web site, http://www.cisco.com, within the BGP configuration documentation.
The import process is an added phase after BGP has selected the best paths. A large number of routes, which have been learned from across the backbone, may be available for import into attached VRFs, and this can potentially be very CPU-intensive. Therefore, each BGP router uses a process known as the scanner process to deal with this task. This happens independently of the BGP router process, which is the standard mechanism used by the router to perform BGP-related tasks.
The actual import of the VPN-IPv4 routes into the relevant VRFs is performed every 15 seconds by default. This means that it can take up to a maximum of 15 seconds for a VPN-IPv4 route learned by a PE-router from a route reflector or from another PE-router to make it into local VRF routing tables. This may also be the case for any routes that are learned from any attached CE-devices. When a prefix is learned from a CE (either via eBGP or an IGP and then redistributed into BGP), the PE-router needs to
Attach the relevant export route target.
Calculate the BGP best path.
If there is a new best path, the BGP version number is increased by 1 and the new best path is advertised to other PE-routers.
If this prefix is to be imported to other local VRFs, the import is actioned at the next invocation of the import scanner process.
A further factor that can affect convergence is the invocation of the BGP scanner process to scan the BGP table and routing tables. This is a separate invocation of the process and does not occur at the same time as the importing of VPN-IPv4 routes. By default, BGP scans the BGP table and routing tables for all address families that are configured under the BGP process every 60 seconds.
This is invoked as a separate process to the BGP router process because of the potentially large amounts of information that must be scanned. Running debug on a PE-router will show this process being invoked every 60 seconds for each address family, and also every 15 seconds for the import of routes. An example of this, and a sample output that shows the BGP scanner process in action, can be seen in Example 12-1.
Example 12-1 Invocation of the BGP Scanner Process
San Jose# show processes cpu CPU utilization for five seconds: 0%/0%; one minute: 0%; five minutes: 0% PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process 107 67824 35013 1937 0.00% 0.00% 0.00% 0 BGP Scanner San Jose# debug ip bgp events BGP events debugging is on 11:08:32 GMT: BGP: Import timer expired. Walking from 8659 to 8659 11:08:47 GMT: BGP: Import timer expired. Walking from 8659 to 8659 11:09:02 GMT: BGP: Performing BGP general scanning 11:09:02 GMT: BGP(0): scanning IPv4 Unicast routing tables 11:09:02 GMT: BGP(IPv4 Unicast): Performing BGP Nexthop scanning for general scan 11:09:02 GMT: BGP(1): scanning VPNv4 Unicast routing tables 11:09:02 GMT: BGP(VPNv4 Unicast): Performing BGP Nexthop scanning for general scan
The scanning of the BGP table and routing tables is necessary to check for changes in the next-hop so that consistent and accurate information is reflected within the router and is passed to the BGP neighbors of the router. The same process also handles the network and redistribute commands so that any new routes that have to be originated are discovered. We will see that changes to attributes of existing routes or the addition of new routes learned from other BGP neighbors are processed using the advertisement interval.
Note
In theory, the scan time could cause a route to not be advertised to an external neighbor for up to 90 seconds. For example, it could take 60 seconds for the scanner process to run and thus discover a new prefix, or change to an existing prefix, and then 30 seconds for the next advertisement interval to an external neighbor.
The BGP scanner process can be tuned to help speed up the convergence times. The actual optimal settings of this process must be determined through monitoring the live implementation because each deployment and topology will be different. Tables 12-2 through 12-4 provide the commands necessary to perform this tuning. All values shown are in seconds.
Warning
Care should be taken when changing the scan time. A very large BGP table with a short BGP scanner timer may severely impact the CPU of the router.
|
Step |
Command |
Purpose |
|---|---|---|
|
1 |
router bgp autonomous-system |
Enable a BGP routing process, which places you in router configuration mode |
|
2 |
bgp scan-time {5-60} |
Set the next-hop validation interval for IPv4 unicast routes only |
|
Step |
Command |
Purpose |
|---|---|---|
|
1 |
router bgp autonomous-system |
Enable a BGP routing process, which places you in router configuration mode |
|
2 |
address-family vpnv4 unicast |
Enter address family configuration for VPNv4 unicast routes |
|
3 |
bgp scan-time {5-60} |
Set the next-hop validation interval for the specified address family on all VPN-IPv4 prefixes learned from both PE and CE-routers |
|
Step |
Command |
Purpose |
|---|---|---|
|
1 |
router bgp autonomous-system |
Enable a BGP routing process, which places you in router configuration mode |
|
2 |
address-family vpnv4 unicast |
Enter address family configuration for VPNv4 unicast routes |
|
3 |
bgp scan-time import {5-60} |
Set the import timer for VPN-IPv4 unicast routes only |
In addition to the scanning and importing of routes, each PE-router needs to advertise the best routes within each VRF to all its VRF neighbors. This process will occur both on ingress into the MPLS/VPN backbone, when routes are received from CE-routers, and on egress, when routes are advertised toward CE-routers. The advertisement of these routes is different depending on whether the neighbors are eBGP neighbors (VPN clients) or iBGP neighbors (other PE-routers). By default, BGP updates are sent to eBGP neighbors every 30 seconds and to iBGP neighbors every five seconds if any update/change is available for transmission. This behavior also has an effect on convergence and can be tuned. The actual update times are controlled by the command in Example 12-2, which is the number of seconds that the router will wait between BGP update transmissions.
Example 12-2 Tuning the Advertisement Interval of BGP Routes
neighbor x.x.x.x advertisement-interval {0-600}
Note
The advertisement interval and scan time need to be tuned on CE-routers as well as PE-routers if the customer runs eBGP across the PE-to-CE link. This may not be possible in some circumstances without an IOS upgrade because the capability to manipulate these timers is a relatively new feature and may not be available within the IOS level running on the CE-router.
Similar to the tuning performed for the BGP process, you might want to fine-tune other routing protocols running between PE- and CE-routers. For example, you might change RIP Version 2 timers to allow them to propagate updates received from the BGP backbone faster.








